
基于支持向量机回归的NDVI组合预测模型
2017-09-21 02:03:25张满囤黄春萌米娜王小芳曲寒冰
河北工业大学学报 2017年4期
张满囤,黄春萌,米娜,王小芳,曲寒冰
(1.河北工业大学计算机科学与软件学院,天津300401;2.华北理工大学图书馆,河北唐山063210)
基于支持向量机回归的NDVI组合预测模型
张满囤1,黄春萌2,米娜1,王小芳1,曲寒冰1
(1.河北工业大学计算机科学与软件学院,天津300401;2.华北理工大学图书馆,河北唐山063210)
对2004年到2015年3~10月的MODIS NDVI数据建立时间序列,并利用同期的温度、降水数据做回归因子,采用支持向量机回归模型建立NDVI短期预测模型.首先用网格搜索法,遗传算法,粒子群算法对模型参数进行优化选择,然后用得到的最佳参数分别训练支持向量机,拟合结果显示网格搜索法是本实验数据的最佳优化算法.使用基于网格搜索法的支持向量机回归模型从2个角度建立了NDVI的单项预测模型,对2个单项模型做线性组合并计算最优权重系数,实验结果表明组合模型可以有效预测NDVI.
支持向量机;NDVI;核函数;组合预测模型
0 引言
植被的生长变化既受气候的影响又可以为气候的变化起到提示作用.对植被覆盖变化进行动态模拟预测,有利于开展生态建设工作.遥感观测为研究地表的植被覆盖变化提供了可靠的实时数据源[1].归一化植被指数(Normalized Difference Vegetation Index,NDVI)对绿色植被表现敏感,可以有效的反映植被生长变化,常被用来研究植被状态.目前植被覆盖变化预测研究只是对未来一定时间范围内,植被覆盖变化方向的预测,主要依靠的模型有马尔科夫模型,广义加法模型等,其中马尔科夫模型的应用最为广泛.例如徐大勇等[2]根据马尔可夫链模型对滨海新区植被覆盖进行预测,得出若不进行人工干预,滨海新区植被覆盖将继续恶化;程先富等[3]用CA-Markov模型对霍山县植被覆盖度分布格局进行预测,得出9年后,低覆盖等级的植被面积减少,高覆盖等级的植被面积增加.目前植被覆盖变化预测尚未存在一个短期定量预测模型.另外植被生长变化对气候因子的响应过程具有复杂性,单一的预测模型很难准确预测植被覆盖变化.所以本文利用天津市2004年到2015年3~10月的NDVI遥感数据,结合同期的温度、降水数据共同建立回归模型,针对响应过程复杂性从不同角度建立单项模型,再对单项模型线性组合,最终建立了天津市NDVI月均值组合预测模型.支持向量机(Support Vector Machine,SVM)相比其他统计学习模型而言,在解决小样本、非线性回归问题中具有独特的优势,以结构风险最小化为原则,取代传统学习机所采用的经验风险最小化原则,可以有效防止过拟合情况.支持向量机具有最小化VC维数上界的能力,这使得支持向量机具备了较强的泛化能力[4].基于以上原因,本文采用了支持向量机回归算法对NDVI时间序列进行建模并预测.
1 数据来源及数据处理方法
1.1 实验数据及来源
归一化植被指数在众多植被指数当中应用十分广泛,NDVI的变化在一定程度上能代表地表植被变化[5]. NDVI的定义为

其中:dntr是近红外波段的地表反射率;dr是可见光红光波段的地表反射率.NDVI的取值范围是-1到+1,0表示没有植被,值越大,表示植被越茂盛,负值表示有水的地面.
本文采用的遥感数据为中科院地理空间数据云发布的MODIS(中分辨率成像光谱仪)中国500 M NDVI月合成产品,时间范围覆盖2004年1月~2015年12月,时间间隔为1个月,空间分辨率为500 m,本文选取3~10月份的图像.研究中使用气象数据来源于美国国家海洋和大气管理局(NOAA)提供的天津地区的2004~2015年各月的月平均气温和月降水量.
1.2 数据预处理
下载的MODIS NDVI遥感图像为HDF格式的文件,HDF是用于存储和分发科学数据的一种自我描述、多对象文件格式.首先利用HEG tools软件将HDF文件转换为R可以使用的GeoTIFF文件.由于实验用的遥感图像为全国范围的NDVI月合成数据,需再用空间统计分析软件R对TIFF格式的图像进行裁剪、提取研究区域的NDVI数值,图1为裁剪得到的天津区域的遥感图像,是NDVI时间序列中随机选取的一个月的图像.对每幅图像的NDVI数据取平均,得到天津地区的NDVI月均值时间序列数据,后文中所提到的NDVI都是指天津地区月均值.
对气象数据删除不合理的值.气象数据的单位不一样,值的变化范围比较大,这样就对模型的性能造成影响,另外支持向量回归模型的核函数值通常依赖特征向量的内积,对[0,1]间的数据最敏感,需要对实验数据进行归一化处理.归一化公式为

图1 天津地区NDVI遥感图像Fig.1 NDVI remote sensing images in tianjin region
式中:xi表示真实数据;Xi′表示归一化后的数据;xmax,xmin分别表示每一个变量的上界与下界.
2 支持向量机回归建模
植被生长受温度与降水量影响最为显著,把能够反映植被生长变化的NDVI指数做因变量,用温度与降水做回归条件,建立NDVI预测模型.具体的温度、降水又分为:当月的月降水量(x1)、月均温(x2),2个月滑动平均(上月与本月)的月降水量(x3)、月均温(x4)和3个月滑动平均(前2个月与本月)月降水量(x5)、月均温(x6).根据选用的回归条件不同,从两个角度对NDVI建立了2个单项模型.第1个模型用当月月均温,月降水量作为整个生长季NDVI的回归条件,是从整个生长季的气候相关性建立的模型,叫做生长季各月统一预测模型.第2个模型是对生长季的8个月份各自建模,每个月分独立选择最佳回归条件,是从月份间气候相关性的差异角度对NDVI建模,叫做生长季各月份独立预测模型.用支持向量机回归算法建立NDVI单项预测模型的流程如图2所示.
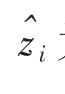

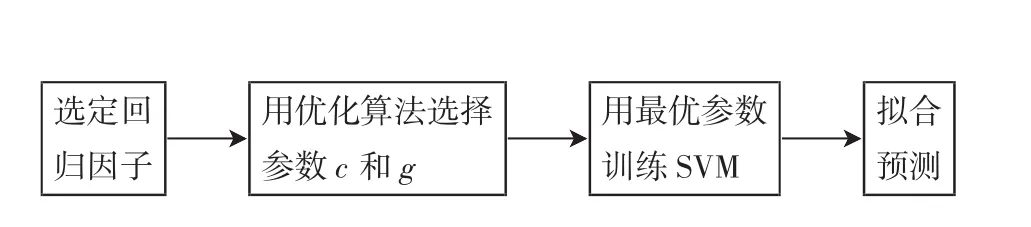
图2 模型流程图Fig.2 The flow chart of the model
2.1 建立生长季各月统一预测模型
2.1.1 选择回归因子
首先利用实验数据对当月的月降水量(x1)月均温(x2)对NDVI的相关性进行显著性验证,用统计分析软件R进行相关性分析结果如图3所示.天津地区12年逐月NDVI与同期月均温,月降水量相关性统计分析表明,NDVI与当月月均和月降水量均有很好的正相关关系(P<0.05),且NDVI对温度和降水反应敏感性是非线性的.根据相关系数分析结果可知,所选月均温、月降水量两个因子对预测对象的相关程度均大于0.05,表明本文选择的影响NDVI变化的气象因子是正确和有效的,符合NDVI生态学特性.
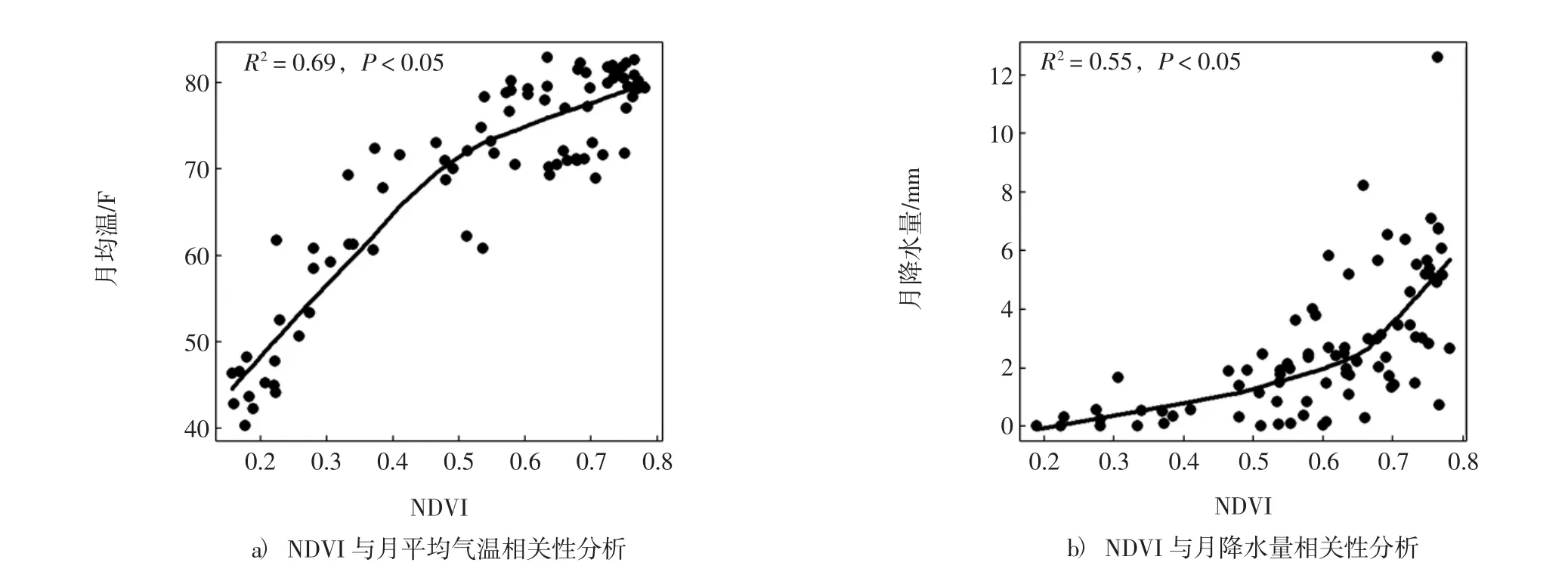
图3 天津12年逐月NDVI与月平均气温及月降水量的关系Fig.3 The relationship monthly NDVI and monthly average temperature with the monthly rainfall about tianjin 12 years
2.1.2 参数的优化选择
已有研究成果表明不同核函数对支持向量机预测性能影响不是很大,但核函数参数的选择却严重的影响支持向量机的泛化能力[7].最常用的核函数——高斯核函数在大多数情况下都能获得很好的预测效果[9],所以本文采用高斯核函数作为研究对象,利用网格捜索法、遗传算法和粒子群算法对高斯核函数参数和惩罚参数C进行了优化选择.
首先利用网格搜索法对支持向量机参数寻优,调用网格搜索优化函SVMcgforRegress,设定网格搜索的变量(C,g)的范围以及搜索步距.设cmin=-5,cmax=5,gmin=-5,gmax=5,即C的取值范围为,cstep=1,gstep=1.利用网格搜索法对支持向量机参数寻优,得到最佳参数:bestC=0.5;bestg=2.然后调用遗传算法优化函数gaSVMcgforRegress,寻优得到最佳参数:bestC=86.341;bestg=0.523 6.最后调用粒子群参数优化函数posSVMcgforRegress,得到的最佳参数为:bestC=100;bestg=0.01.
2.1.3 利用SVM模型作拟合预测
利用以上3种方法得到的最优参数,分别训练支持向量机模型,再由得到的模型对原始数据进行拟合预测.
第1步利用网格搜索法得到的最优参数C和训练支持向量机模型.调用支持向量机函数svm,核函数选择高斯核,惩罚参数设置为0.5,高斯核函数参数设置为2,训练数据为12年的全部数据,用数据框的数据结构表示,第1列为NDVI月均值,第2列为当月月降水量(x1),第3列为当月月均温(x2),因变量设置为NDVI.R在运行svm函数的时候根据训练数据和因变量的设置自动识别算法类别为回归或者分类,svm函数的返回值是支持向量机模型model,model是用12年的实验数据训练得到的生长季各月统一预测模型.第2步用model对测试集进行拟合预测,把全部原始数据做为测试数据.调用支持向量机预测函数predict,函数输入为model和测试集,输出为模型拟合结果F.拟合数据和原始数据如图4所示.整个生长季平均拟合精度为87.74%,平均绝对误差(MAPE)为12.26%.
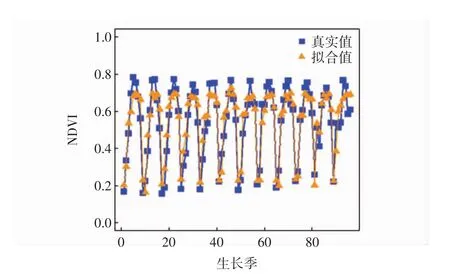
图4 网格搜索法拟合结果Fig.4 The grid search Method fitting results
再次调用支持向量机函数svm,利用遗传算法得到的最优参数C和训练支持向量机模型.整个生长季平均拟合精度为86.63%,平均绝对误差(MAPE)为13.37%.遗传优化算法对应的拟合结果如图5所示.
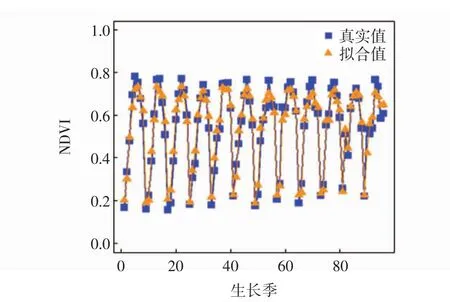
图5 遗传算法拟合结果Fig.5 Genetic algorithm fitting results
最后利用粒子群算法得到的最优参数C和g训练支持向量机模型.整个生长季平均拟合精度为87.38%,平均绝对误差(MAPE)为12.62%.拟合结果如图6所示.
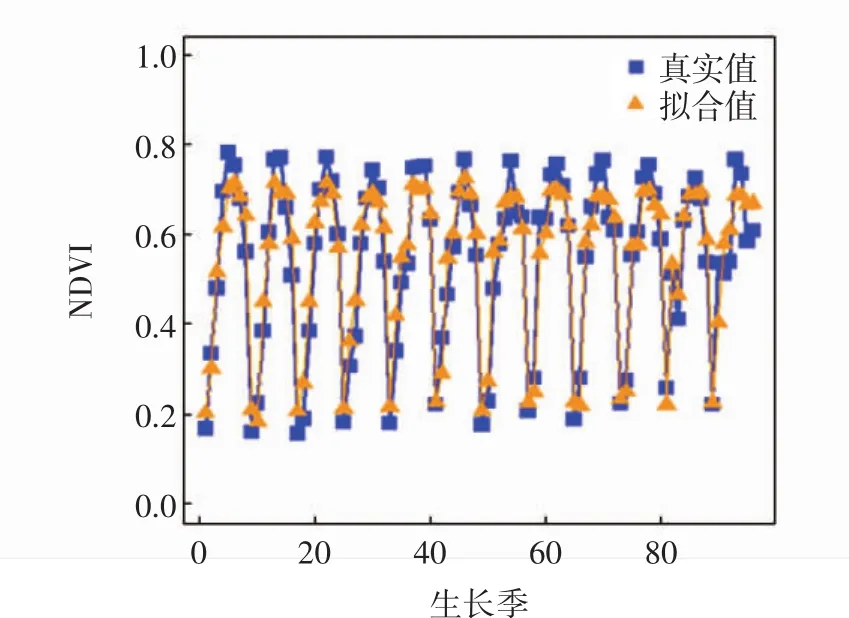
图6 粒子群算法拟合结果Fig.6 Particle swarm algorithm fitting results
3种算法优化的比较结果如表1所示.综合准确率与训练速度来看,网格搜索法的精确度最高,且速度最快,所以把网格搜索算法作为模型参数的优化算法,对应的预测模型作为生长季各月统一预测模型.
由于评价一个预测模型的好坏,主要考察其预测能力而非回代拟合结果[8],因此需对建立的模型进行独立预测,以便获得实际NDVI建模精度与预测能力的评定.为避免单个样本预测的偶然性,对连续3年的数据进行独立预测.把数据分两部分,2004到2012年的数据作为训练集,2013到2015年的数据作为测试集.3年的平均预测精度为89.42%,最大值为98.64%,最小值为60.51%,预测精度达到80%的月份占87.5%,基本满足NDVI建模要求,但准确率还有待提高.
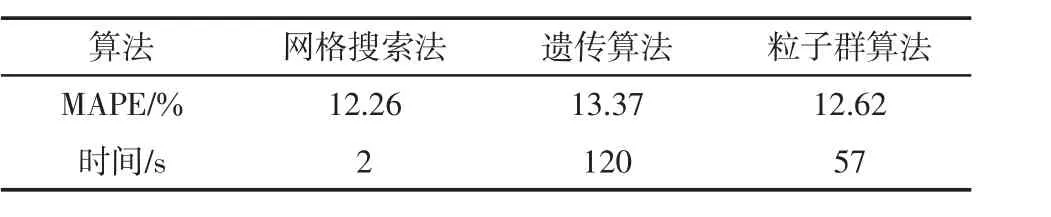
表1 3种优化算法拟合结果比较Tab.1 Three kinds of the comparison of optimization algorithm fitting results
2.2 建立生长季各月独立预测模型
2.2.1 选择回归因子
气候因子对植被的影响有个累积过程,影响植被生长状况的因素除了当时的气候条件以外,还与前期的气候状况有关[10],即存在滞后性,气候因子对NDVI的影响在各个月份存在差异[10].在R软件上使用实验数据对当月的月降水量(x1)月均温(x2),2个月滑动平均的月降水量(x3)、月均温(x4)和3个月滑动平均月降水量(x5)、月均温(x6)对NDVI的相关性进行显著性验证.
通过计算生长季各月份植被变化对气候因子的相关性(见表2),分别选出各个月份最显著的回归因子.各个月份选用的回归条件如表3所示.
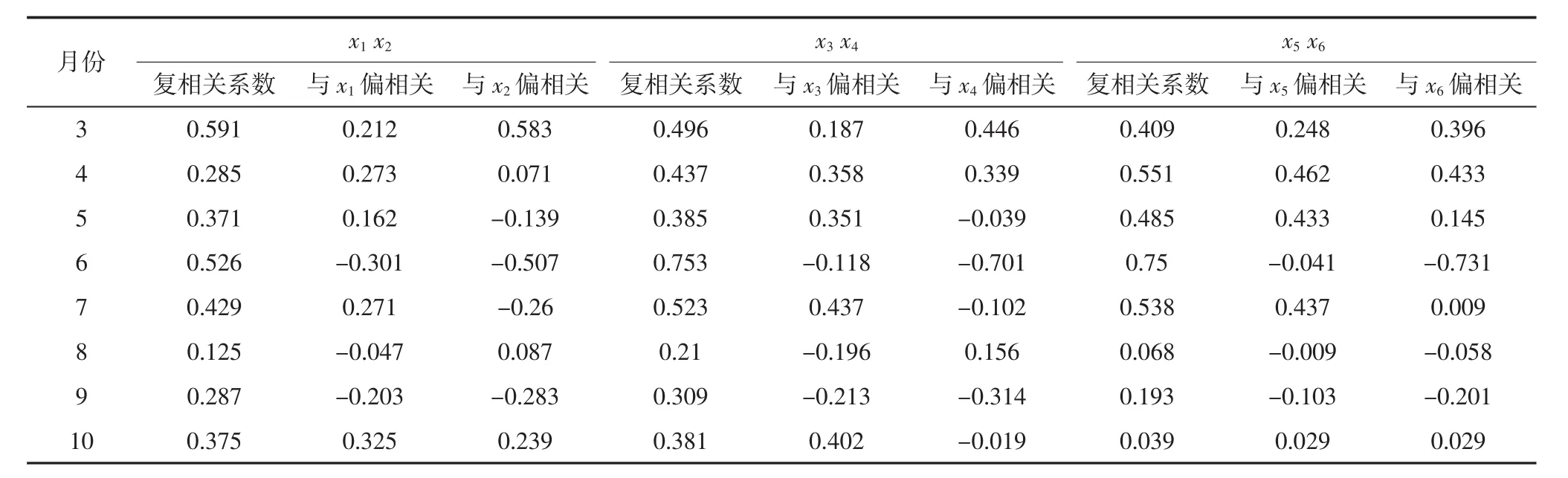
表2 生长季各月NDVI与气温和降水的相关关系Tab.2 The relationship growing season months NDVI with temperature and precipitation
2.2.2 参数的优化选择
需要对各个月份独立建模,核函数依然选取高斯核函数,对核参数g和惩罚参数C的优化选择算法采用准确率和时间效率都好的网格捜索法,利用各月的最佳回归条件分别对生长季每个月份选择最优参数.
利用SVMcgForRegress函数对支持向量机参数寻优,cmin=-6,cmax=6,gmin=-6,gmax=6,即C的取值范围为,g的取值范围为cstep=1,gstep=1.3~10月份参数寻优结果见表4.
2.2.3 利用SVM模型作拟合预测
根据表3选用的各月回归条件,用svm函数对各月数据进行8次训练,得到每个月的支持向量机模型,再分别用各月的支持向量机模型和测试集做predict函数的输入,得到8个月的NDVI拟合结果.以3月份为例,训练SVM模型并拟合预测:

实验过程中得到的model3到model10为3到10月份各月独立模型,f3到f10为生长季各月独立预测模型的拟合结果.由于篇幅限制,拟合结果不在文中展示了.整个生长季各月独立预测模型的平均拟合精度为89.49%,最大值为99.85%,最小值为56.01%,拟合精度达到80%的月份占91.49%.

表3 生长季各月NDVI与气温和降水的相关关系Tab.3 The relationship growing season months NDVI with temperature and precipitation
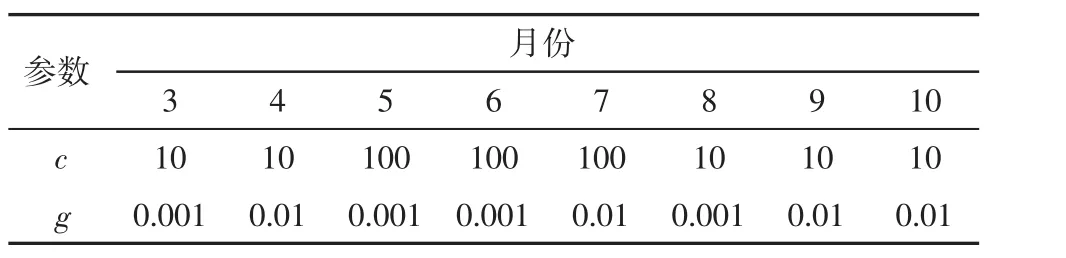
表4 3-10月份参数寻优结果Tab.4 Parameter optimization results from March to October
3 组合预测模型
3.1 建立组合预测模型
为了综合利用各模型的信息,采用组合预测模型[11].将2个模型(生长季各月统一预测模型与生长季各月独立预测模型)进行线性组合,寻求最优权重系数,使用最优权重系数组合模型对NDVI进行回归预测.
假定一个经济预测问题采用m个单项模型进行预测.设y(t)为预测对象t时刻的属性值,t=1,2,…,n,yi(t)为第i个预测模型在第t时刻的预测值,i=1,2,…,m.若w=(w1,w2,…,wm)T为m个预测模型线性组合的加权系数,则线性组合模型形式为
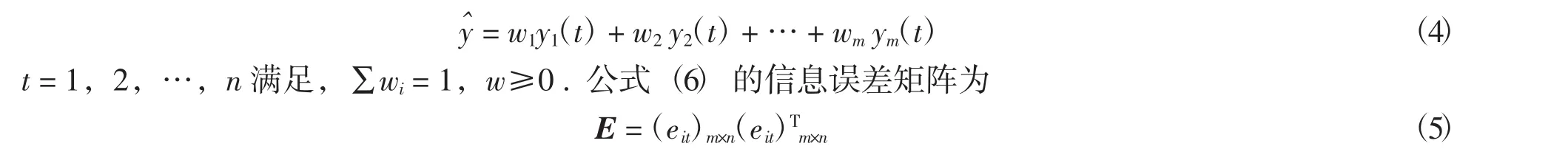
其中,eit为第i个预测模型在第t时刻的预测误差.

用SSE表示组合项模型的误差平方和.文献[12]提出根据“过去一段时间内组合预测误差平方和最小”的方法(式(7))来求取各个单项预测方法的最优权系数.该方法所求的最优权系数为式(4)的解.

若记生长季各月统一预测模型为y1,生长季各月独立预测模型为y2,组合模型为G,G为2个模型的线性组合:

其中:w1,w2分别为y1,y2模型的权重系数;y(t)为t时刻NDVI的实际值.根据误差矩阵E的定义,用y1(t),y2(t)以及y(t)计算得到E,再由公式(7)解得w=(0.737 2,0.262 8)>0,所以线性组合模型为
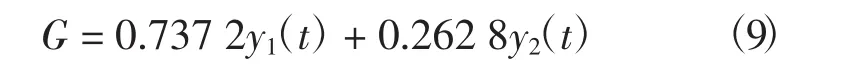
利用模型G对12年的NDVI数据进行拟合,拟合结果如图7所示,平均拟合精度96.713%,最大值为99.327%,最小值为85.222%,拟合精度达到90%的月份占92.433%.

图7 组合模型拟合结果Fig.7 Portfolio model fitting results
最后还需要考察组合模型G的预测能力.把2004~2012年的数据作为训练集,2013~2015年的数据作为测试集,预测结果如图8所示.3年的平均预测精度为95.633%,最大值99.239%,最小值为87.224%,预测精度达到90%的月份占90.031%,组合模型的预测准确率满足NDVI的预测要求.

图8 组合模型对连续3年NDVI预测结果Fig.8 Combination model for prediction of NDVI for three consecutive years
3.2 实验结果分析
生长季各月统一预测模型,是从整个生长季NDVI对气候因子的响应关系建模,没有考虑气候因子对各个月份NDVI影响的差异;而生长季各月独立预测模型是针对这种差异建模,没有考虑到各月份之间的内在联系.组合模型综合的考虑了生长季各月份之间的联系和月份之间的差异性,计算两个单项模型的最优权重系数对提高组合模型预测精度至关重要.
4 结论
本文利用天津地区12年的遥感及气候数据,用支持向量机回归模型对天津地区NDVI时间序列建模.通过实验对3种模型参数优化算法进行了分析比较,最后选用精确度和速度都最佳的网格搜索法训练支持向量机.从2个角度对NDVI建立了2个单项模型,采用组合预测模型对NDVI预测.实验结果表明组合预测模型可以有效预测NDVI.影响植被生长变化的因素还有很多,其中人为因素对实验结果影响不能被忽视.另外核函数的选择以及其参数的选择还有很多内容需要研究,未来要争取建立一个更好的模型,为研究植被的生长变化做参考.
[1]郭军,李明财,刘德义.天津地区归一化植被指数时间动态及其与气候因子的关系[J].生态学杂志,2009,28(6):1055-1059.
[2]徐大勇,张涛.基于NDVI的天津市滨海新区植被覆盖度变化及预测研究[J].生态经济,2010,12:45-50.
[3]程先富,张方方,邓良.安徽省霍山县植被覆盖度动态变化及预测[J].水土保持通报,2014,34(4):104-109.
[4]张永生.支持向量机在害虫预测预报中的应用[J].现代农业科技,2009,14:147-148.
[5]刘德义,傅宁,范锦龙.近20年天津地区植被变化及其对气候变化的响应[J].生态环境学报,2008,17(2):798-801.
[6]CHANG C C,LIN C J.LIBSVM:a library for support vector machines[DB/OL].[2011-10-07].http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[7]向昌盛,周子英,张林峰.支持向量机在害虫发生量预测中的应用[J].生物信息学,2011,9(1):28-31.
[8]张凤廷.基于支持向量机的中国股指期货回归预测研究[D].济南:山东财经大学,2013.
[9]王定成,方廷健,高理富,等.支持向量机回归在线建模及应用[J].控制与决策,2003,18(1):89-91.
[10]Schmidt H,Karnieli A.Remot sensing of the seasonal variability of vegetation in a semi-arid environment[J].Journal of Arid Environments,2000,45(1):43-59.
[11]王明涛.非线性规划在确定组合预侧权系数中的应用[J].预测,1994,13(3):60-61.
[12]唐小我.最优组合预测方法及应用[J].数理统计与管理,1992(1):31-35.
[责任编辑 田丰 夏红梅]
Combination forecast model of NDVI based on support vector machine regression
ZHANG Mandun1,HUANG Chunmeng2,MI Na1,WANG Xiaofang1,QU Hanbing1
(1.School of Computer Science and Engineering,Hebei University of Technology,Tianjin 300401,China;2.Library,North China University of science and Technology,Hebei Tangshan 063210,China)
The MODIS NDVI data from 2004 to 2015 are used to make a time sequence.By using the temperature and precipitation data during this period as regression factor,support vector machine regression model is used to establish the NDVI short-term prediction model.First,grid search method,genetic algorithm,particle swarm optimization are used to optimize model parameters respectively.Then use the best parameters to train support vector machine respectively.The results show that the grid search method is the best parameter optimization algorithm.Build two single prediction model of NDVI from different angle using support vector machine regression model based on the grid search method.Do a linear combination with the two single prediction model and calculate the optimal weight coefficient.The results show that the combined model can predict NDVI effectively.
support vector machine;NDVI;kernel function;combined forecasting model
Q948
A
1007-2373(2017)04-0039-07
10.14081/j.cnki.hgdxb.2017.04.007
2016-10-08
北京市科学技术研究院创新团队计划(IG201506C2)
张满囤(1971-),男,副教授,博士,zhangmandun@scse.hebut.edu.cn.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11 03:18:56
河北地质(2022年2期)2022-08-22 06:24:04
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:40
现代园艺(2017年23期)2018-01-18 06:58:12
北京航空航天大学学报(2017年6期)2017-11-23 05:57:36
浙江大学学报(工学版)(2016年10期)2016-06-05 09:20:56
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
