
基于Deep Speech的语音识别系统的实现与改进∗
2017-09-12 08:49李灿孙浩李开
计算机与数字工程 2017年8期
李灿孙浩李开
基于Deep Speech的语音识别系统的实现与改进∗
李灿1孙浩2李开2
(1.昆明长水国际机场动力能源部昆明650211)(2.华中科技大学计算机科学与技术学院武汉430074)
Deep Speech是一个端到端的语音识别系统,该系统使用深度学习的方法取代了传统的特征提取方法,直接从根据波形文件产生的频谱图中提取特征生成对应的文字信息。该系统使用门限循环单元构建的循环神经网络能够对具有时间序列相关性的语音信息进行学习,还使用了CTC进行输入到输出的映射以及网络模型参数的更新。将这种方法与语言模型相结合之后,对单词的拼写错误进行修正,能够得到更好的识别效果,使用方法也更加简单。
语音识别;深度学习;循环神经网络;CTC;门限循环单元;随机梯度下降;语言模型
Class NumberTP391
1引言
单向的神经网络声学模型在20多年前被探索,循环神经网络和卷积神经网络也在同一时间用于语音识别[1]。最近DNN已经成为ASR中的一个重要部分,几乎所有最先进的语音工作都包含某种形式的深层神经网络[2]。卷积网络也被发现有益于声学模型[3~4]。循环神经网络,尤其是LSTM[5],一开始只是应用在经典的语音识别器上,并与卷积层的特征提取相结合取得不错的效果[6]。
端对端语音识别是一个很活跃的研究领域,在对DNN-HMM的结果进行处理之后能够得到很好的识别效果[7~8]。目前有两种方法将可变长度音频序列直接映射到可变长度的文字序列。
第一种是RNN编码器解码器,首先编码器将输入序列映射到固定长度向量,然后解码器将固定长度向量扩展为输出预测序列。解码器使用的注意机制极大地提高了系统的性能,特别是对于很长输入或输出序列。在语音识别任务中,带有注意力机制的编码器解码器RNN在预测音素和字素两个方面都有不错的效果[9~10]。
另一种常用的将可变长度的音频输入映射到可变长度输出的技术是使用CTC损失函数对RNN模型的时序信息进行处理。CTC-RNN模型在端到端语音识别中预测字母输出时表现良好。CTC-RNN模型也已被证明能够有效预测音素,但是在这种情况下仍然需要词典进行处理[11]。此外,使用从GMM-HMM进行逐帧对齐的DNN交叉熵网络对CTC-RNN网络进行预训练是非常必要的。在本文中,Deep Speech提出了一种从零开始训练CTC-RNN网络的方法,不需要用于预训练的帧对齐。
2系统实现及改进
2.1数据预处理
深度神经网络能否有良好的学习效果的决定性因素之一就是训练集的大小。如果训练集的规模太小,达不到网络模型参数的要求,那么神经网络将难以从训练集中提取足够的特征进行学习,在实际应用时也达不到很好的效果[12~13]。在训练Deep Speech时,论文使用了LibriSpeech语料库,该语料库包含了不同时间长度的阅读语音的波形文件和对应的文本信息,其中最短的语音有2s,最长的语音达20s,两万六千多条不同的语音总共时间有960小时[14]。
为了便于神经网络的处理,论文将波形文件转换成对应的频谱图输入到神经网络中。首先将20ms长度的hanning窗口作为一帧,每一帧内使用快速傅里叶变换计算各个频率的能量值,多个能量值叠加即可获得该帧所对应的频谱图。然后以10ms为步长滑动hanning窗口,分别产生每个窗口的频谱图。最后多个频谱图按时间顺序拼接起来就可生成一段语音对应的频谱图[8]。
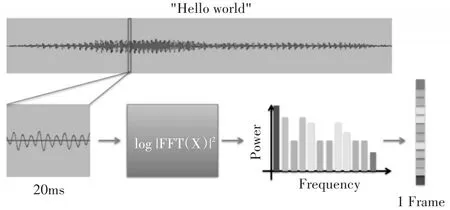
图1 语音频谱生成过程图
2.2 GRU
门限循环单元(Gated Recurrent Unit,GRU)可以看成是LSTM的变种,GRU使用Update Gate来替代LSTM中的Forget Gate和Input Gate[15~16]。把Cell State和隐状态ht进行合并,在计算当前时刻新信息的方法和LSTM有所不同。下图是GRU更新ht的过程:
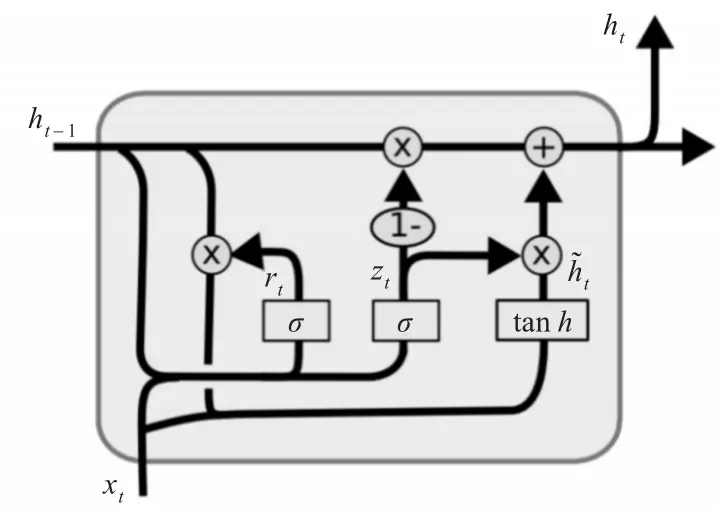
图2 GRU更新ht图
GRU具体更新过程如下[17]:
首先GRU中控制数据流方向的两个门,分别是rt(Reset Gate)和zt(Update Gate),计算方法和LSTM中门的计算方法一致:
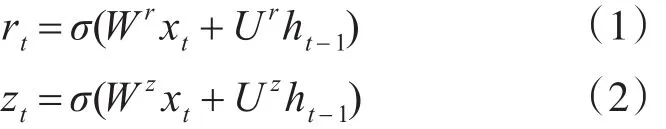
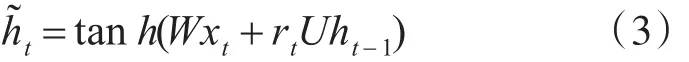
最后zt控制需要从前一时刻的隐藏层ht-1中遗忘多少信息,需要加入多少当前时刻的隐藏层信息h~t,最后得到ht,直接得到最后输出的隐藏层信息,这里与LSTM的区别是GRU中没有OutputGate:
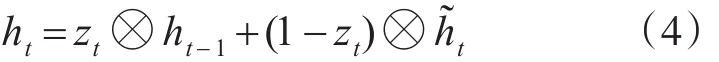
如果Reset Gate接近0,那么之前的隐藏层信息就会丢弃,允许模型丢弃一些和未来无关的信息;Update Gate控制当前时刻的隐藏层输出ht需要保留多少之前的隐藏层信息,若zt接近1相当于把之前的隐藏层信息拷贝到当前时刻,可以学习长距离依赖。一般来说那些具有短距离依赖的单元Reset Gate比较活跃,如果rt为1,而zt为0那么相当于变成了一个标准的RNN,能处理短距离依赖,具有长距离依赖的单元Update Gate比较活跃。
2.3 CTC
许多现实世界的序列学习任务是从有噪声的、未分段的输入数据中预测其标签序列。例如,在语音识别领域,声学信号被转录为单词或字单位。递归神经网络(RNN)是非常适合这样的任务的具有很强的学习能力的神经网络。然而,由于RNN需要预分段的训练数据,并且要做后处理将其输出转换成标签序列,其适用性一直受到限制。CTC(Connectionist Temporal Classification)提出了一个用于训练RNN来直接标记未分段的输入序列的方法,从而解决以上两个问题。
一个CTC网络具有SoftMax输出层,该层比la⁃bel集合L多出一个unit。对于||L个units的触发被解释为在特定的时刻观察到对应的label的概率,对于多余的unit的触发被看作是观察到空格或者no label的概率。总的来说,这些输出定义了将label序列对齐到输入序列的全部可能方法的概率。任何一个label序列的总概率,可以看作是它的不同对齐形式对应的全部概率累加。
对于一个给定的输入序列x,长度为T,定义一个RNN网络,m个输入,n个输出,权重向量w作为一种映射关系NW:(Rm)T→(Rn)T。设y= Nw(x)为网络的输出序列,ytk表示神经单元k在t时刻的输出值,其含义是在t时刻观察到labelk的概率,这个输出值表示长度为T的序列集合L′T在字母集合L′T=L∪{blank}上的概率分布:
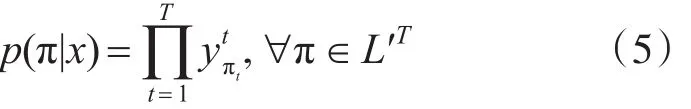
现在,把L′T中的元素看作路径paths并且用π表示。公式的假设是,给定网络的中间状态(inter⁃nalstate),在不同时刻的网络输出是条件独立的。这保证了输出层不存在到它自身或者网络的反馈链接。
下一步是定义一个多对一的映射β:L′T→L≤T,其中后者是可能的label序列的集合。可以简单通过删除全部的blank和重复路径path中的label来实现,例如β(a-ab-)=β(-aa--ab b)=abb。直观来说,这等价于输出一个新的label,从预测no label变为预测a label,或者从预测a label到预测另外一个label。
最终,用映射β来定义一个给定的label序列l∈L≤T的条件概率作为与它对应的全部paths的概率和:
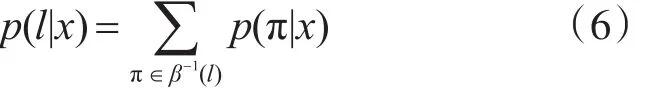
得到多个label序列的概率之后使用一个分类器选择出对于输入序列x最可能的label序列h(x):
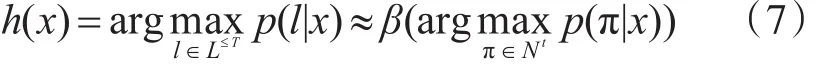
在CTC中使用了最大似然的方法来更新神经网络模型的参数:
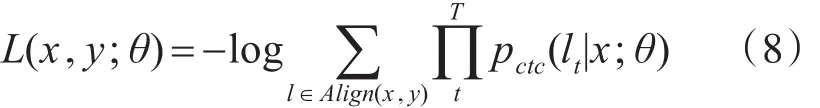
其中Align(x,y)表示输入x通过CTC得到的输出y的所有可能性的集合。
2.4系统结构
基于Deep Speech的语音识别的系统网络结构如图3所示。
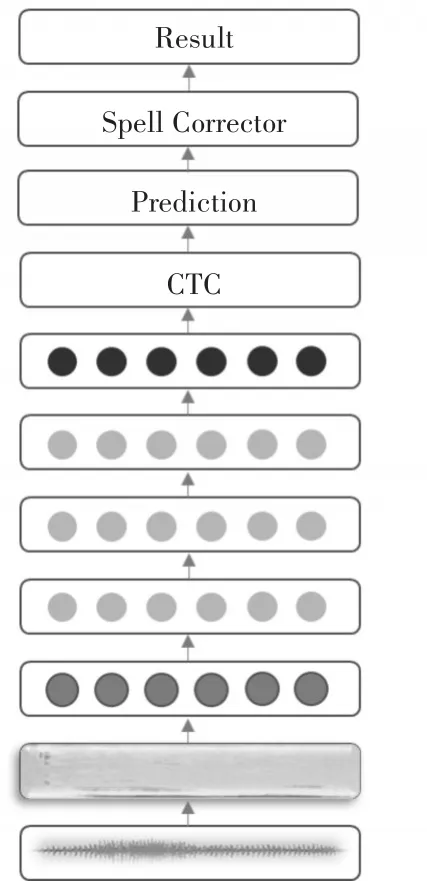
图3 基于Deep Speech的语音识别的系统网络结构图
首先将语音的波形文件转换成频谱图,然后使用一个一维卷积层进行语音信号的领域滤波;接下来的三层隐含层由GRU构成,每层包含1000个GRU单元;然后使用全连接层进行全连接操作;将全连接的输出值作为CTC的输入,经由CTC计算得到预测的文字信息。由于整个网络是以音素为预测单位,即通过语音某一帧预测其对应的字母,所以预测结果并不能保证其单词词法上的准确性,为了提高最终结果的准确性,在Deep Speech的基础上加上Spell Corrector对预测的文本进行单词拼写纠正。
3实验过程及结果
3.1数据集
训练该神经网络模型的数据集来自LibriSp⁃eech Corpus,数据集内容为文章阅读录音,语言为英语,语音的时间长度范围是从0s~20s,采样频率为16kHz,声道数为单声道。我们将该数据集分为三个部分:训练集、验证集、测试集。训练集中的数据由大约28000条录音片段构成,总共时长大约800小时;验证集中的数据由2800多条录音片段构成,总共时长大约90小时;测试集中的数据由2700多条录音片段构成,总共时长大约90小时。
3.2 实验过程
实验过程中使用的是百度研究所的Deep Speech开源代码,该代码使用的深度学习框架是Keras框架,编程语言为python。
在进行一维卷积操作时,卷积核大小为11,移动步长为2,激活函数使用的是ReLu。在每一个隐含层设置不同的神经单元个数进行了多次试验,设置不同的学习率来加快网络收敛的速度。每一次训练的Batch Size大小为16,迭代次数为1780,epoch为20。
利用该神经网络做出了一个C/S模式的小应用。在客户端有两种提交数据的方式:录音提交和选择音频文件提交。服务器端将客户端提交来的音频文件输入到Deep Speech中进行处理并产生预测的文本信息返回给客户端,客户端接收信息后显示在界面上。为了对比识别效果,音频文件同时会提交给百度语音识别API并返回结果然后显示。
3.3实验结果
每一个epoch耗时大约1.5个小时,整个训练过程耗时30小时。由于受到数据集规模的限制,训练出来的模型在实际测试中的效果并不好。但是通过调整学习率、神经元个数、加单词拼写修正等方法,识别准确性有一定的提高。

表1 测试准确率
从表1中可以看出,神经单元个数相同时,学习率较小的网络有更好的准确性,这是因为在相同的epoch下,学习率大的网络收敛速度更快,预测值与实际值的差距更小,从而能得到更好的模型参数。在学习率系统的情况下,神经元个数多的网络模型准确率反而更小,可能是数据集太小的缘故,数据集的规模达不到网络模型参数的规模,神经网络不能从数据集中学习到足够的特征来更新网络模型参数。
4结语
本文通过对Deep Speech的实现和改进,结果表明深度学习的特征提取方法比传统的手工特征提取方法更加简单,效果也更好,但是深度学习方法对数据集的依赖性太大。只有数据集的规模达到神经网络模型的参数的规模才能提取足够多的特征供神经网络学习。在处理具有时间序列上相关性的数据时可以使用由GRU或者LSTM构成的循环神经网络,循环神经网络能够很好的保持长期依赖。例如在语音识别任务中,“I”后面接“am”的概率要远大于接“was”的概率,这样就可以通过循环神经网络来维持“Iam”这种依赖关系。
[1]LeCun,Yann,YoshuaBengio,and Geoffrey Hinton.Deep⁃learning[J].Nature,2015,521(7553):436-444.
[2]Szegedy,C.,Liu,W.,Jia,Y.,Sermanet,et.A.Going deeper with convolutions[J].CoRR,2014,abs/1409.4842.
[3]Simonyan,K.,&Zisserman,A.Very deep convolutional networks for large-scale image recognition[J].CoRR,2014,abs/1409.1556.
[4]Jonathan Long,Evan Shelhamer,etal.Fully Convolutional Networks for Semantic Segmentation[J].IEEE Int.Conf. Comput.Vis.Pattern Recognit.,2015:3431-3440.
[5]Lin T,Horne B G,etal.How embedded memory in recur⁃rentneural network architectures helps learning long-term temporal dependencies[J].Neural Networks,1998,11(5):861-868.
[6]Hochreiter,S.,Schmidhuber,J.Long short-term memory[J].Neuralcomputation,1997,9(8):1735-1780.
[7]Amodei,Dario,et al.Deep speech 2:End-to-end speech recognition in english and mandarin[J].arXiv preprint arXiv:1512.02595(2015).
[8]K.Yao,B.Peng,etal.Recurrentconditional random field for language understanding[J].in IEEE Int.Conf.Speech and Signal Processing,2014.
[9]Cho,K.,van Merrienboer,B,et al.Learning phrase rep⁃resentations using RNN encoder-decoder for statistical machine translation[J].In Proc.Empiricial Methods in NaturalLanguage Processing,2014.
[10]Razavian A,AzizpourH,et al.CNN features off-the-shelf:an astounding baseline for recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops,2014:806-813.
[11]Graves,Alex,et al.Connectionist temporal classifica⁃tion:labellingunsegmented sequence data with recurrent neuralnetworks[C]//Proceedings ofthe 23rd internation⁃alconference on Machine learning.ACM,2006.
[12]L.Deng,D.Yu.Deep Learning:Methods and Applica⁃tions[J].Foundations and Trends in Signal Processing,2013,7(3):198-199.
[13]Hori,Takaaki,Atsushi Nakamura.Speech recognition al⁃gorithms using weighted finite-state transducers,Synthe⁃sis Lectures on Speech and Audio Processing[J],2013,9(1):1-162.
[14]Panayotov,Vassil,et al.Librispeech:an ASR corpus based on public domain audio books[C]//IEEE Interna⁃tional Conference on Acoustics,Speech and Signal Pro⁃cessing(ICASSP),IEEE,2015.
[15]Chung,Junyoung,etal.Empiricalevaluation ofgated re⁃current neural networks on sequence modeling[J].arXiv preprintarXiv:1412.3555(2014).
[16]Hannun,Awni,et al.Deep speech:Scaling up end-to-end speech recognition[J].arXiv preprintarXiv:1412.5567(2014).
[17]Schuster,Mike,and Kuldip K.Paliwal.Bidirectional re⁃current neuralnetworks[J].IEEE Transactions on Signal Processing,1997,5(11):2673-2681.
Implementation and Improvement of Speech Recognition System Based on Deep Speech
LI Can1SUN Hao2LI Kai2
(1.Power and Energy Department,Kunming ChangshuiInternational Airport,Kunming 650211)
(2.SchoolofComputerof Science and Technology,Huazhong University of Science and Technology,Wuhan 430074)
Deep Speech is an end-to-end speech recognition system that uses adepth-of-learning method instead of a tradi⁃tional feature extraction method to generate the corresponding textual information directly from the spectral map generated from the waveform file.The cyclic neural network constructed by the threshold cycle unit can be used to study the speech information with time series correlation.It also uses the CTC to perform the input to output mapping and the updating of the network model parame⁃ters.Combining this method with the language model,itcan correct the misspelling of the word and get a better recognition result,and the method is more simple.
speech recognition,deep learning,recurrent neural network,CTC,gated recurrent unit,random gradient de⁃scent,language model
TP391
10.3969/j.issn.1672-9722.2017.08.034
2017年2月8日,
2017年3月25日
李灿,男,硕士研究生,研究方向:机场相关动力能源、节能减排、弱电及信息系统管理开发。
猜你喜欢
小学生学习指导(低年级)(2020年10期)2020-11-26
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信产业报(2018年40期)2018-01-22
作文大王·低年级(2017年11期)2017-12-05
移动通信(2017年3期)2017-03-13
学苑创造·A版(2017年1期)2017-01-19
西南学林(2013年2期)2013-11-12
