
基于数据挖掘技术的移动互联网业务研究∗
2017-09-12 08:49陈鸿俊
计算机与数字工程 2017年8期
陈鸿俊
基于数据挖掘技术的移动互联网业务研究∗
陈鸿俊
(四川水利职业技术学院信息工程系成都611231)
信息时代的来临使得数据量大幅度提高,对于信息的处理变得炙手可热,数据挖掘能够从庞大的、复杂的、不完整的、有噪声的数据库中提取潜在有用的信息。论文提出了一个基于关联规则和Apriori算法的数据挖掘模式,针对移动互联网时代所储藏的大量数据进行处理和分析,在数据挖掘的关联性规则和Apriori算法的基础上进行了改进,利用SQL对算法进行了优化,处理大量的数据时可以节省算法运行的时间,提高准确性,确保数据的质量,最后对算法进行流程评估,证明该算法方法可行有效,能够节约时间,提高效率,从而帮助决策者做出合理的判断。
数据挖掘;Apriori算法;网络优化;关联规则
Class NumberTP274
1引言
随着信息技术时代的来临和快速的发展,各个行业和企业部门都要进行计算机和信息技术来管理和决策,但是数据量与日俱增,大数据生成、采样、储存、对于计算机的处理能力提出了更高的要求[1~2]。人们已经越来越意识到数据的重要性。数据信息的挖掘是在数据仓库的基础上对数据进行处理[3]。数据挖掘技术进行的决策支持过程,包括机器学习,AI和统计学等手段来处理数据,分析原始的数据从而得出一个决策性的推理,挖掘数据潜在的价值,判断客户需求,帮助决策者调整做出减少风险的合理方案。那么数据挖掘技术,数据挖掘算法就是我们进行数据挖掘的工具[4~5],对于数据挖掘的研究很早就开始了,在研究搜索引擎日志方面,国外起步较早,并有了较多的研究成果。Hos⁃seiniM和Abolhassani H等在查询字符串与搜索结果内容进行了聚类分析[6],用来评价Web页面的内容结构。Jansen BJ等对移动业务日志做了一个全面的分析,包括定义、使用等[7]。Silverstein C、Marais H等对大型的商务搜索引擎做了分析,了解了用户的搜索关键字长度的规律[8]。
本文提出了新的算法,算法的执行步骤是在Apriori算法的基础上进行改进的[9~10],在Apriori算法的核心部分结合了SQL[11],并且对算法步骤流程进行了优化,可以在执行中大大的减少运行时间,程序的运行效率变高。运用新的算法操作,与之前的相比要快。另外,本文对经典Apriori算法进行预先筛减[12],节省了处理的数据集合,因此算法的效率提升。
2关联分析规则
移动互联网业务优化指的是针对运行的网络进行数据采集、数据分析,进行高效的数据处理,数据分析就是互联网优化的重点,信息化的时代数据量非常巨大,而有效的、有益的数据却被海量的数据所隐藏,我们要解决的就是找到我们所要的数据,并且找出数据之间的关系,为决策者做出决定,从而得到想要的效果。数据挖掘过程如图1,数据挖掘技术就是庞大的数据库中进行数据处理和搜索,能够迅速高效的找到所要的数据。
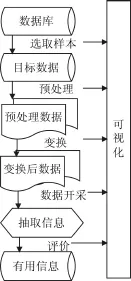
图1 数据挖掘过程
2.1关联定义
数据挖掘中关联规则模式是十分重要的一种知识模式,也叫作“购物篮技术”,它是无监督学习系统中最常见的知识发现形式,关联规则由Agraw⁃al等于1993年首先提出的,它表达的是数据库中一组对象间的关联的规则,而且更能建立不同属性域之间的数据联系。它的优势表现在两个方面,其中一方面是关联规则为决策者提供高效的规律和模式识别,探索和发现已经拥有和新的规律,为做研究和决策提供帮助;另一方面表现在它可以有效地和其他好的决策方案融合,因此可以提供一个更好地解决问题的决策方案。
设I={i1,i2,…,iM}为项数集,ij为正项其中(1≤j≤M),对应的iˉ为负项,D={T1,T2,…,TN}是交易集,Ti为交易,则关联规则如下
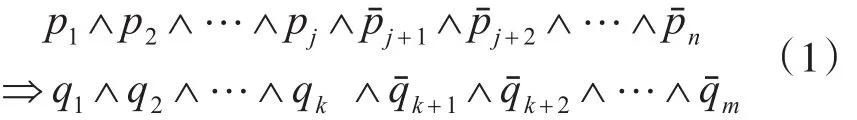
其中pj,qk∈I(1≤j≤n , 1≤k≤m),令{p1,…,pj,pˉj+1,…,pˉn}∩{q1…,qk,qˉk+1,…,qˉm}=Φ。我们令X={p1,…,pj,pˉj+1,…,pˉn},Y={q1,…,qk,qˉk+1,…,qˉm}。关联的支持度表示为s=s up port(X⇒Y)= |X Y|/|D|,可信度为c=confidence (X⇒Y)=|X Y|/ |X|。交易集D表示其中交易的总个数,记作|D|,而交易集D中的X子项所包含的交易总数,记作|X|,若交易集中D其中的X子项和Y子项中两个交易总数为|X Y|。决策者可以依据解决实际问题的需要,从数据挖掘出发,可以人为定义最小的支持度(mi n s upport)和最小可信度(m in confidence),若要两者满足X⇒Y:s up port(X⇒Y)≥mi n s upport,并且满足con fidence (X⇒Y)≥mi n con fid ence,则称X⇒Y称为关联规则,其中X、Y分别称为X⇒Y关联规则的前提和结论。
2.2频繁项目集
s(X)表示交易集X发生的频率,那么可以得到s(X)=||X/||D,如果s(X)大于决策者预定的最小支持度,称X是频繁项目集;如果s(X)不大于决策者预定的最小支持度则称X为非频繁项目集。
若s(X∪Y)=||XY/||D=s upport(X⇒Y),则有X∪Y是频繁项目集且等价的关系式为
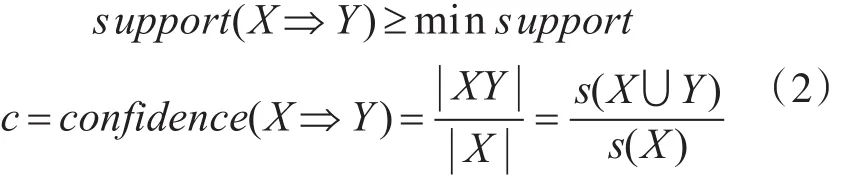
关联规则在数据挖掘中的作用就是发现交易集D中的关联规则。根据上面的关联定义与频繁项目集的概念,因此可以将关联规则挖掘分为两个小问题去解决,第一个是依据最小支持度发现数据集D中的全部频繁项目集;第二个依据频繁项目集以及最小可信度生成数据之间的关联规则。第一个问题的目标是快捷准确地发现D中全部频繁项目集,同时这也是关联规则数据挖掘的最主要的问题,它是评价关联规则数据挖掘算法的依据;而第二问题问题可以依据问题一得出的结论来解决。
3 Apriori算法改进
数据关联规则研究之后,专家们都致力于数据的生成算法。在众多的生成算法中最常用,也是最有效率的是Apriori算法。Apriori算法是由R. Agrawal等提出的关于数据快速挖掘的算法,是现在绝大多数关联规则算法都是依据Apriori算法而提出的。Apriori算法是数据的宽度优先的算法,运用了大项集集合的封闭性,对数据库D进行多次搜索从而发现全部的大项集。在搜索中只研究相同长度即数据中个数相同的全部项集。
3.1 Apriori算法改进
Apriori算法有一定的缺陷,不能够克服越来越庞大的数据库,所以本文依经典的Apriori算法为依据,通过改进算法,提高算法的高效性,结合SQL优化。本文算法的高效性是因为它运用了大项集的封闭性原则,快速缩小了目标数据的项集数量,能够克服和避免运行那些不需要的大项集的候选项集。改进的Apriori算法如下:
Apriori改进算法
Step1 For每一个频发k-项集fk,k≥2
Step2 do H1={i|i∈fk}//规则的后项1-规则件
Step3 call ap-genrules(fk,H1)
Step4 End for
其中Apriori改进算法中的ap-genrules如下
子算法ap-genrules(fk,H1)
初始化k=||fk,m=||Hm
Step1 If k>m+1
Step2 then Hm+1=apriori-gen(Hm)
Step3 for每个hm+1∈Hm+1
Step4 do con f=σ(fk)/σ(fk-hm+1)
Step5 If con f≥min conf
Step6 then(fk-hm+1)→hm+1
Step7 else hm+1
Step8 End
3.2 SQL语言
数据处理时结合SQL语句,它的累加函数是运用了标准SQL语句中的集合统计函数,因此比经典的Apriori算法中所约束的规则数量少很多,而且生成的规则数也变得比之前要少,但是数据代表的信息是几乎真实接近的,所以算法运行处理速度是很快的。
SQL算法语言
Step1 For(K=2 :LK-1≠空集;K++)
Step2 do CK=aprior-gen(LK-1)
Step3 then Ct=subset(CK, t)
Step4 do{c∈CK|c.count≥min S}
Step4 End
4算法实例
数据处理的采集服务器(MSS)使数据采集具有很强兼容性。采集服务器(MSS)支持SNMP、WMI、ODBC等多种数据采集方式,以便适应数据采集对象的不同数据接口类型。测试环境分服务器端与客户端。服务器端部是一台系统为Win⁃dows Server 2003联想台式机。其中,CPU:AMD Trinity APU A8频率为3.2GHz,内存是16GB DDR3a。
4.1实例分析
本文数值实验采用的是真实的某互联网平台,客户对于网页浏览内容的数据处理与分类,包括客户对于衣服、食品、首饰、家电等数据进行收集分析,对于客户的需要作出判断,并能够为客户提供更好地,更符合实际的产品信息,信息数据如图2。Y轴表示对应商品的客户浏览量。
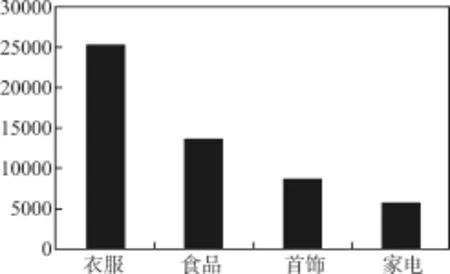
图2 商品客户浏览量
通过改进的Apriori算法得出客户对于商品的关注度,算法得出的结论,我们令衣服为D1,D2,D3,D4,每一个D都是项目集,将关注度定为1,那么每个商品的关注度范围为0≤s<1,所有数据的关注度之和为1,数据如表1。

表1 商品对应的关注度
我们得到客户对于衣服的需求明显大于其他商品的需求量,再根据改进的Apriori算法对衣服中的种类,例如夹克,衬衫,牛仔裤,棉衣进行数据处理,最后得出客户需要的商品,并根据算法结果,不仅为客户提供信息,也能为商家提供商品输出渠道。
4.2算法比较
除了改进的Apriori算法,对于庞大数据处理的算法常见的还有聚类算法,PAM算法,STING算法,对于同类数据进行处理,通过Matlab进行数据模拟,数据处理之后,分别计算并比较各自算法的数据处理的速度。
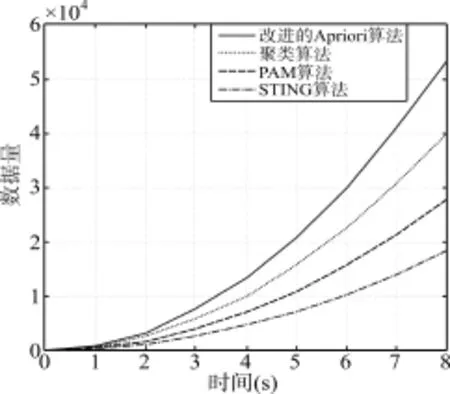
图3 不同算法的处理速度
通过算法比较,发现与传统的数据处理算法相比,本文的算法在数据处理上具有明显的优势,比其他算法在时间上有很大的改观,能够为决策者做出更快更好地判断。所以该算法有很好的利用价值和实用意义。
5结语
本文在依据数据挖掘技术中的关联规则并结合标准的SQL语句对算法进行优化整合,在数据处理上,能够做到迅速从庞大的数据库中挖掘出潜在的、有意义的关联规则。另外,本文算法减少了数据集合处理的计算复杂程度,同时它还可以运用到连续数值型的庞大数据库中进行数据挖掘。算法实例表明,该算法的处理速度比传统的算法更快,且处理的准确度更高,所以该算法有实用意义。
[1]何苗,刘芃成,周延泉,等.基于数据挖掘的移动互联网数据包安全检测[J].警察技术,2015(4):58-61.
HE Miao,LIU Pengcheng,ZHOU Yanquan,et al.Security Detection of Mobile Internet Packet Based on Data Mining[J].Police Technology,2015(4):58-61.
[2]徐敏,蒋伟梁.数据挖掘技术在网络入侵检测中的应用研究[J].网络安全技术与应用,2016(6):68-69.
XU Min,JIANG Weiliang.Application of Data Mining Technology in Network Intrusion Detection[J].Network Security Technology and Application,2016(6):68-69.
[3]骆焦煌.数据挖掘技术在入侵检测系统中的应用研究[J].吉林师范大学学报(自然科学版),2016,37(2):131-135.
LUO Jiaohuang.Research on Application of Data Mining Technology in Intrusion Detection System[J].Journalof Ji⁃lin Normal University(Natural Sciences),2016,37(2):131-135.
[4]凌昊,谢冬青.基于数据挖掘的网络入侵检测系统模型的研究[J].科学技术与工程,2007,7(19):5170-5172.
LING Hao,XIE Dongqing.Research on Network Intrusion Detection System Model Based on Data Mining[J].Sci⁃ence Technology and Engineering,2007,7(19):5170-5172.
[5]蔡传亮.数据挖掘技术在移动网络优化中的应用分析[J].硅谷,2014(8):79-79.
CAI Chuanliang.Application and Analysis of Data Mining Technology in Mobile Network Optimization[J].Silicon Valley,2014(8):79-79.
[6]孙伟.移动通信网络优化中数据挖掘技术的应用[J].中国科技博览,2014(16):232-232.
SUN Wei.The Application of Data Mining Technology in Mobile Communication Network Optimization[J].China Science and Technology Expo,2014(16):232-232.
[7]陈慰旺,张艳芬.移动通信网络优化中数据挖掘技术的运用[J].信息通信,2016(6):201-202.
CHENG Weiwang,ZHANG Yanfen.Application of Data Mining Technology in Mobile Communication Network Op⁃timization[J].Information communication,2016(6):201-202.
[8]刘军.数据挖掘技术在网络入侵检测中的应用[J].南京工业大学学报(自科版),2006,28(2):79-84. LIU Jun.Application of Data Mining Technology in Net⁃work Intrusion Detection[J].Journalof Nanjing University of Technology(Natural Science Edition),2006,28(2):79-84.
[9]胡勇.数据挖掘技术在移动通信网络优化中的应用[J].电子制作,2013(24):147-147.
HU Yong.Application of Data Mining Technology in Mo⁃bile Communication Network Optimization[J].Electronic production,2013(24):147-147.
[10]贾松江.关于数据挖掘在移动网络优化中的应用探讨[J].中国新技术新产品,2011(24):33-33.
JIA Songjian.The Application of Data Mining in Mobile Network Optimization[J].China New Technology and New Products,2011(24):33-33.
[11]张小军,任帅,申丹丹.浅析4G环境下数据挖掘在移动通信网络优化中的运用[J].电子技术与软件工程,2014(8):208-209.
ZHANG Xiaojun,REN Shuai,SHEN Dandan.Applica⁃tion of Data Mining in Optimization of Mobile Communi⁃cation Network in 4G Environment[J].Electronic Tech⁃nology and Software Engineering,2014(8):208-209.
[12]王磊,王国治,王西点.数据挖掘技术在网络质量优化体系中的应用[J].电信工程技术与标准化,2012(11):57-61.
WANG Lei,WANG Guozhi,WANG Xidian.Application of Data Mining Technology in Network Quality Optimiza⁃tion System[J].Telecommunications Engineering Tech⁃nology and Standardization,2012(11):57-61.
Research on Mobile Internet Service Based on Data Mining Technology
CHEN Hongjun
(Departmentof Information Engineering,Sichuan Water Conservancy Vocational College,Chengdu 611231)
The adventofthe information age has led to a significantincrease in the amountofdata,and the processing ofinfor⁃mation has become hot,and data mining can extractpotentially usefulinformation from large,complex,incomplete,and noisy data⁃bases.This paper presents a data mining modelbased on association rules and Apriorialgorithm.A large number ofdata stored in the mobile Internetera are processed and analyzed.Based on the association rules of data mining and Apriorialgorithm,SQL is used to optimize the algorithm.Dealing with a large amount of data can save the algorithm running time,improve accuracy,to ensure data quality,Finally,the algorithm is evaluated by the process,which proves thatthe algorithm is feasible and effective,which can save time and improve the efficiency,so as to help decision makers make reasonable judgments.
data mining,Apriorialgorithm,network optimization,association rule
TP274
10.3969/j.issn.1672-9722.2017.08.029
2017年2月7日,
2017年3月23日
四川省教育厅2016年度科研项目(编号:16ZB0431)资助。
陈鸿俊,男,硕士,讲师,研究方向:移动互联、云计算数。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
新世纪智能(数学备考)(2021年9期)2021-11-24
建材发展导向(2021年12期)2021-07-22
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
当代陕西(2019年15期)2019-09-02
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
