
实体消歧中特征文本选取研究∗
2017-09-12 08:49庞焜元唐晋韬李莎莎王挺
计算机与数字工程 2017年8期
庞焜元唐晋韬李莎莎王挺
实体消歧中特征文本选取研究∗
庞焜元唐晋韬李莎莎王挺
(国防科技大学长沙410073)
在实体消歧问题中,特征文本是指输入实体消歧系统的用于表征实体指称和候选实体的文本,其质量对于实体消歧的性能有重要的影响。论文对特征文本的选取问题进行研究,针对网络文本的特点,综合考虑文本中的特殊字符、特征文本的位置、特征文本是否包含实体指称和特征文本的单句长度等因素,对文本进行筛选和处理,产生特征文本,以提高实体消歧的效果。论文在深度结构语义网(Deep Structured Semantic Model,DSSM)和向量相似度模型(Vector Similarity Mod⁃el,VSM)两个实体排序模型上验证了特征文本选取方法的效果。结果显示特征文本筛选提高了DSSM上排序准确性,在P@ 3、P@5和P@10上分别有12.2%、12.3%和12.2%的提高。其中特殊字符处理对VSM有5.5%的提高。实验结果表明,对特征文本进行合理的筛选及清洗,有助于提高实体消岐中候选实体排序步骤的效果。
实体消歧;特征文本;数据清洗
Class NumberTP391
1引言
随着网络数据的日渐丰富和日常生活与互联网的联系日益紧密,理解和处理互联网信息已经成为重要需求。其中一个重要的任务就是分析明确网络文本提及的的实体与客观事物的对应关系。互联网上用于描述这些客观事物的是知识库和知识图谱如Wikipedia、DBpedia、YAGO、Freebase、Pro⁃base等。实体消歧,又称实体链接(Entity Linking,EL)就是将文本中的命名实体的指称与知识库中对应的实体对应起来的过程[1]。
实体消歧过程的困难之处在于:同一实体的指称可能有所变化;同一指称所代表的实体也可能有多个。实体链接问题的研究主要分为三个方面:候选实体集生成,为待链接的实体指称生成知识库中可能链接的条目的集合;候选排序,在候选实体集中挑选最合适的候选;NIL聚类(Not in Library,不在实体库中),对不在实体库中的实体指称进行聚类。三项工作呈递进关系。候选实体集生成的研究相对成熟。
在现有的研究中,候选排序模型大多直接使用原始语料作为输入,再进行特征的提取。经过观察,原始语料、特别是网络环境中的文本语料,其内容成分复杂、噪音多、句子长短区别较大。例如:TAC-2010测试集中的源文档最大达到90,641个字符。而且,原始语料往往包含不能处理的噪音数据,如多语言、多编码的影响,在处理中文文本时面临源文档和知识库中的英文符号,处理英文文档时面临西班牙语字符、国际音标等非英文字符等。网络文本的这些特点使得特征提取受到影响。
本文针对网络文本的实体消歧特点,提出了一个对原始语料进行清洗、挑选合适文本产生特征的方法。该方法基于句子长度、文本内容、特殊字符等特征选择合适规模的特征文本,为实体排序模型提供更好的输入语料。为探究输入的特征文本对实体排序模型的影响,本文选取两个常用的模型深度结构语义网(Deep Structured Semantic Model,DSSM)和向量相似度模型(Vector Similarity Model,VSM)进行比较,前者未对输入文本进行任何预处理,后者通过实体识别等步骤对输入文本进行了初步清洗。通过对这两个模型增加特征文本选取算法构建一组对比实验,结果表明,特征文本的选取对于实体排序模型的准确率有较大影响,特别是对不包含输入文本预处理步骤的模型如DSSM影响更大。
2相关工作
现有的大部分实体链接系统选取上下文文本相似度、实体相容度这两个方面的特征进行候选排序。
上下文文本相似度特征是度量包含指称的文本与实体相关联的文本的相似度的方法。在指称方面的特征,文献[2~3]使用了整篇文本,而文献[4~5]使用的是指称附近的一个区域。在候选实体方面,文献[4]使用的是维基百科页面全文,文献[5]使用了维基百科第一段的信息,文献[6]使用了候选实体在维基文本中的出现附近区域。文献[11]使用WebLink数据集,选取自然标注的网页语料中实体出现的上下文表示该实体。以上研究均使用词袋模型表示相应的文本。文献[7~9]等研究提取关键字、分类、描述标签、Infobox等信息为文本构建了概念向量来表示文本。
对于构建的词袋模型或其他向量模型,以上文献选用的方法是多为余弦相似度。文献[9]提出了使用KL距离度量字符串间的相似度。文献[10]提出了神经语言模型用于计算候选实体与上下文文本词袋模型的相似度。
实体相容是假设文本一篇文档中的实体应当属于一个或几个主题,或相同的实体上下文中的其他实体应更加相似。文献[12]描述了WLM(Wikipedia Link-based Measure)用于度量实体间的相关程度。主要思想是包含两个实体的文章越多则两个实体间的联系就越强。文献[7]训练了有限状态自动机用于计算两个实体指称字符串的相似性,从而度量两个实体间的相似性,或两个字符串多之乡的是同一实体的概率。文献[2,9]等分类系统均使用了此特征。
以上研究的着眼点在于:选用何种来源的文本来表示候选实体(实体在维基百科中的描述?在维基百科里的上下文?自然标注数据里的上下文?);从指称上下文和代表候选实体的文本中提取什么样的特征(文本浅层特征?提取实体?使用结构化信息的特征?)以及如何度量二者在选定特征下的相似度。
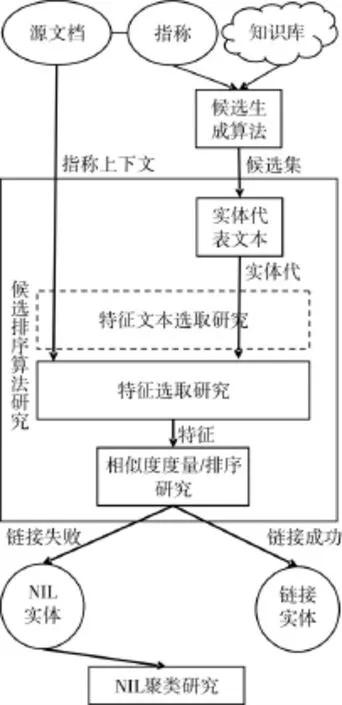
图1实体链接系统相关研究关系图
图1 阐释了实体消歧问题的研究重点关系,方框中为数据的处理过程。在选取文本来源和从文本中提取特征之间,现有的研究对于特征文本的选择问题并未给予重视。目标文档、维基百科和自然标注网页都是互联网上的原始文本。直接用于特征的提取可能存在问题:例如:针对英语的特征提取器在遇到非英语噪音文本时,通常进入异常处理,一定程度上忽略杂质,但也丢失了邻近的语料,带来信息抽取的误差。又如:相当一部分算法实现在编程中受制于性能因素的要求,对输入文本的长度进行限制。超过长度的文本被直接截断。这一截断过程也会带来信息的浪费。
下面将选取DSSM和VSM两个模型,研究特征文本的选择对实体排序系统的影响。
3研究模型
本文选取两个模型作为候选实体排序模型。即以指称所在文档和候选集中每个候选的维基百科文本作为输入,输出每个候选与指称匹配程度的模型。
3.1 DSSM模型
DSSM[16]是微软研究院研究的深度结构语义网(Deep Structured Semantic Model),或深度语义相似模型(Deep Semantic Similarity Model)。它使用多层全连接神经网络或卷积网络,以字符串为输入,输出在语义空间上的向量表示,然后计算语义空间上的相似度。已经用于搜索引擎、问答系统、知识推理、图片描述、机器翻译等任务。接下来自下而上地介绍所使用DSSM的处理过程。
本文基于文献[17]中介绍的DSSM,分为WordHash,词袋统计,神经网络,相似度计算三个步骤。在WordHash阶段,为了减少神经网络的输入维数,单词表示从one-hot表示变为三元组的形式,即:将输入按空格分开,变为全小写单词。在单词前后加入结束符号‘#’,然后统计其中的三元组,例如“Word hashing”将变为“#wo,wor,ord,rd#,#ha,……”。训练集中未出现的三元组将被忽略,进一步地缩小了输入的维度。在词袋统计阶段,将统计的三元组进行了词袋统计,使用三元组词袋表示了输入的句子。使用神经网络对两个句子的词袋表示的相似度进行度量。
3.2 VSM模型
Vector Similarity Model[18]分成实体识别,相似度计算两个部分。在实体识别部分,使用Stanford NER工具进行实体识别和分类。形成三个实体集合:ORG,PER和GPE。再计算基于集合的相似度:
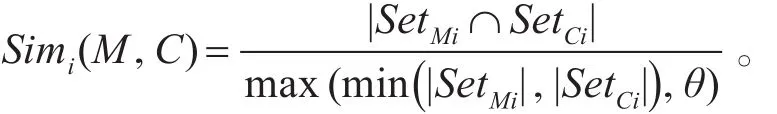
三个集合的相似度使用MaxPooling进行融合,即:
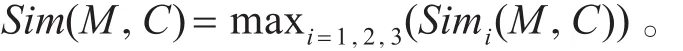
4特征文本选取
对于以上两种模型,文献描述和代码分析表明输入的原始文本直接用于模型的输入。下面考虑语言杂质和文本长度两方面的问题。在噪音语料方面,DSSM只接受英文字母和数字作为输入,特殊字符所在三元组被忽略。
在文本长度方面,用于实验的源文档最长达90641字符。DSSM程序默认忽略1000字符之后的部分;VSM未对字符进行显式的要求,但在处理到大文档时出现了明显的性能下降(从每秒数条记录下降到数分钟一条记录)。为模拟对文本的截断需求,假设两个模型处理的特征文本不能超过1000字符。对长文本进行简单的截断处理可能带来的问题有:正文前嵌套的格式符号、作者信息、时间戳等与实体肯定无关的文本被选中;源文档中指称出现在最后时,与开头文字在语义上无关;截取到了过长的句子,信息稀薄等。
为此本文设计了以下的处理策略:特殊字符处理策略,源文本内容位置处理策略,句子长度处理策略。
4.1处理特殊字符
在单词中出现的特殊的字符,可能会导致词袋统计的错误和实体识别的误差。例如:‘(word)’一词,代表语义的部分应为word,但受到括号的干扰,在DSSM中实际统计的元组是:“#(w,(wo,wor,ord,rd),d)#。”由于括号不计入统计,实际统计的元组是“wor,ord”两个,不能代表这个单词。而badínez这样中间包含特殊字符的单词,由于元组的省略,实际输入神经网络的单词更接近“baez”,与原单词截然不同。
对特殊字符的类型进行分类考虑。对于<>和()类的括号型字符,通常是起到内容注释和结构注释的作用。结构注释如“<br>、<POSTDATE>”与语义无关,可以直接去掉。内容注释的部分如:“Emi⁃ly Dickenson(1830-1886)was a greatpoetin Ameri⁃can literature。”即使去掉也不会对句子完整造成损失,反而会留下简洁的句子。因此括号类的特殊字符连同括号内的部分替换成一个单空格。
对于非英文字符,通常表现为外来语言,如汉字,西班牙语名词等。按照英文书写规范,汉字与单词不能混写,在WordHash步骤和NER步骤都会直接忽略,实验中可以不予考虑。外来语名词,如:Badínez。只将特殊字符去掉,保留单词Badnez。一方面可以最大程度利用神经网络对于拼写错误的鲁棒性,另一方面在NER实体识别中也有望识别成相同的实体。
此步骤的输出为纯英文,可能略带拼写错误的语料。去掉了语言杂质,也一定程度上减少了截取文本中的语义无关成分。
4.2内容和位置
在源文档中并不是所有的句子都与指称同等相关。文本的局部性说明,与指称所在句子的文本与指称的关系最为紧密。距离过远的文本与指称在语义上可能毫无联系。
在实体的表示方面,本测试集使用维基百科描述的全文文本作为实体的表示,这与大多数研究是相同的。按照维基百科的写作风格,第一段通常为摘要,是对实体的全面概要的描述。已经包含了实体的完整信息。后面的描述相对不那么重要。
在有限长度的文本截取中,优先选取源文档中包含指称的句子和实体描述文档中摘要部分的句子,有望保留更丰富的语义。
4.3句子长度
在人工进行实体链接工作时能够提供有效信息的句子通常为结构完整的陈述句。完整的句子结构使得这些句子的长度一般较长。原始语料中剩余的部分可能包含表格、标题,新闻语料中注释、时间作者等附加信息和网站的格式标记。聊天室语料还可能包括文字表情和惯用语、回帖标记等。分句系统通常会将这些内容划分成短句子。另一方面,一个句子只能描述实体的一个侧面,但实体链接系统希望能够采集代表实体的多方面信息的特征。在有限的字符限制下,选取过长的句子也不合理。
截取的文本中优先选择长度适中的句子有望获取更丰富的语义,同时排除非语言信息的干扰。
以上三种方法都是结合特征的提取,窗口的限制等模型需求,“浓缩”输入文本,使得输入实体排序模型的文本最能全方位地代表实体的各方面信息。
5实验
评估本文特征文本提取对于实体链接的影响,本文选取TAC-2010 Evaluation集合进行英文实体链接实验。该测试集共有测试样本3922个,其中1020个样本有知识库中的连接。每一个样本包含一篇文档和文档中的一个子串作为指称。知识库为从维基百科中摘取的约3000000条词条。使用文献[19]中介绍的候选生成算法,生成了其中的928个测试样本的候选集合。本实验研究在这928个样本上的候选排序问题。
实验过程如下:其中Baseline组直接输入原始文档的前1000字符。
实验①对特殊符号进行处理,即去掉括号及其中和其他特殊字符。
实验②考虑了句子的内容和位置。实验中对源文档中的句子是否包含指称和维基百科文本是否是前10句话进行了标记。优先带标记的句前5个句子作为输入,不足则由前几个句子递补。
实验③考虑了句子的长度。先使用LingPipe进行句子划分,选取80-120这个窗口作为标准长度,计算每个句子的长度偏差。最后选用偏差最小的5个句子作为实体的特征文本。
实验①+②+③综合筛选的优先级是:先进行①的特殊字符处理。②阶段的标记权值为30,③阶段的标记权值为每字符为①。即优先选择符合②要求的长度80-120的句子。次优先选择符合②要求的长度50-150的句子。再次选择长度接近80-120的句子。
评价指标选取TAC2010的Micro-Average,即以样本为单位进行统计。分别统计了每种配置下将正确的候选实体排在前1,3,5,10名以内的准确度。
实验结果如表1和表2所示。
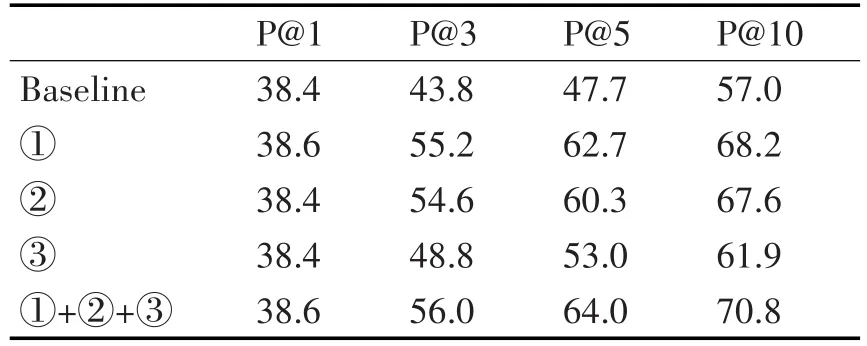
表1 DSSM特征文本选取实验结果
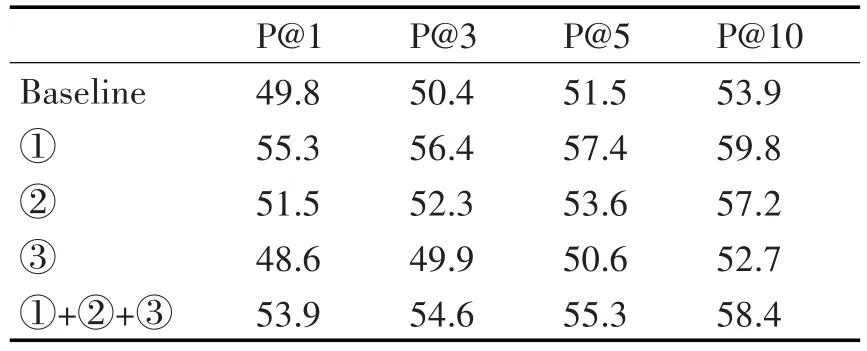
表2 VSM特征文本选取实验结果
从实验结果可以看出,DSSM对于实体链接系统的实体排序工作能力大约为38%,这与文献[19]报道的搜索排序工作能力相当(P@1=36.2,P@3= 42.5,P@10=49.8),这也是DSSM在求两个字符串的语义相似度方面的能力极限。
特征文本的筛选对于DSSM的P@1的提高不显著。但对于P@3-P@10提升逐渐更加明显。说明特征文本筛选对于DSSM等深度语义理解系统存在帮助。深度语义理解系统作为实体链接系统的可提升空间还十分巨大。
在VSM模型中①特殊字符的处理过程对排序系统的提升最为显著,说明对文本进行恰当的清洗会带来性能的提升。句子位置对系统影响不显著,仅进行句子长度的筛选反而对排序系统有害。分析中间结果发现,VSM系统通过实体识别步骤对句子进行了初步清洗,仅保留实体使得该方法不会受到句子长度过长的负面影响,而再次叠加句子筛选步骤②和③会导致实体识别结果集合变小,这可能影响后续的相似度计算的原因。
6结语
本文实验表明,特征文本的选取对于实体排序模型的准确率有显著影响。对于不包含输入文本预处理步骤的模型如DSSM影响更大。因此,本文提出的对特征文本进行选择的思路可能对实体排序有一定帮助。在接下来的工作中,计划继续研究文本筛选对DSSM性能提升的机理,使这种提升能够迁移到P@1,即用户关心的实体链接系统最终结果上来。
[1]Wei Shen,Wang Jianyong,Han Jiawei.Entity linking with a knowledge base:Issues,techniques,and solutions[J]. IEEE Transactions on Knowledge and Data Engineering,2015,27(2):443-460.
[2]Stephen Guo,Chang Ming-Wei,Kiciman Emre.To Link or Not to Link?A Study on End-to-End Tweet Entity Linking[C]//HLT-NAACL,2013:1020-1030.
[3]Wei Zhang,Sim Yan Chuan,Su Jian,et al.Nus-i2r:Learning a combined system for entity linking[C]//Proc TAC 2010 Workshop,2010.
[4]Thomas Lin,Mausam,Etzioni Oren.Entity linking atweb scale[C]//Proceedings of the Joint Workshop on Automat⁃ic Knowledge Base Construction and Web-scale Knowl⁃edge Extraction.Montreal,Canada;Association for Com⁃putational Linguistics,2012:84-88.
[5]Sayali Kulkarni,Singh Amit,Ramakrishnan Ganesh,et al. Collective annotation of Wikipedia entities in web text[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining,ACM2009:457-466.
[6]Wei Shen,Wang Jianyong,Luo Ping,etal.Linking named entities in tweets with knowledge base via user interest modeling[C]//Proceedings of the 19th ACM SIGKDD in⁃ternational conference on Knowledge discovery and data mining,2013:68-76.
[7]Mark Dredze,McNamee Paul,Rao Delip,et al.Entity dis⁃ambiguation for knowledge base population[C]//Proceed⁃ings of the 23rd International Conference on Computation⁃al Linguistics,2010:277-285.
[8]Xianpei Han,Zhao Jun.Nlpr_kbp in tac 2009 kbp track:a two-stage method to entity linking[C]//Proceedings of TestAnalysis Conference 2009(TAC 09),2009.
[9]Johannes Hoffart,Yosef Mohamed Amir,Bordino Ilaria,et al.Robust disambiguation of named entities in text[C]// Proceedings of the Conference on Empirical Methods in NaturalLanguage Processing,2011:782-792.
[10]Zhengyan He,Liu Shujie,Li Mu,et al.Learning Entity Representation for Entity Disambiguation[C]//ACL(2),2013:30-34.
[11]Andrew Chisholm,Hachey Ben.Entity disambiguation with web links[J].Transactions of the Association for Computational Linguistics,2015,3:145-156.
[12]David Milne,Witten Ian H.Learning to link with wikipe⁃dia[C]//Proceedings of the 17th ACM conference on In⁃formation and knowledge management,2008:509-518.
[13]TadejŠtajner,MladenićDunja.Entity resolution in texts using statistical learning and ontologies[C]//Asian Se⁃mantic Web Conference,Springer,2009:91-104.
[14]John Lehmann,Monahan Sean,Nezda Luke,et al.LCC approaches to knowledge base population at TAC 2010[C]//Proc TAC 2010 Workshop,2010.
[15]Sean Monahan,Lehmann John,Nyberg Timothy,et al. Cross-lingual cross-document coreference with entity linking[C]//Proceedings of the Text Analysis Confer⁃ence,2011.
[16]Xiaodong He,Gao Jianfeng,Deng,et al.Deep Learning for Natural Language Processing:Theory and Practice(Tutorial)[C]//CIKM,2014.
[17]Po-Sen Huang,He Xiaodong,Gao Jianfeng,et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Conference on informa⁃tion&knowledge management,ACM,2013:2333-2338.
[18]Zheng Chen,Ji Heng.Collaborative ranking:a case study on entity linking[C]//Conference on Empirical Methods in Natural Language Processing,EMNLP 2011,27-31 July 2011,John Mcintyre Conference Centre,Edin⁃burgh,UK,A Meeting of Sigdat,A Special Interest Group ofthe ACL,2011:771-781.
[19]Silviu Cucerzan.Large-Scale Named Entity Disambigua⁃tion Based on Wikipedia Data[C]//EMNLP-CoNLL 2007,Proceedings of the 2007 Joint Conference on Em⁃pirical Methods in Natural Language Processing and Computational Natural Language Learning,June 28-30,2007,Prague,Czech Republic,2007:708-716.
Feature Text Selection in Entity Disambiguation
PANG Kunyuan TANG Jintao LI Shasha WANG Ting
(NationalUniversity of Defense Technology,Changsha 410073)
In an entity disambiguation task,feature text is the input of entity disambiguation system to represent the men⁃tioned entity and the candidate entity.Quality offeature textaffects entity disambiguation performance.Feature textselection regard⁃ing web textis studied in three aspects,including specialtokens,textlocation and whether itcontains the mention and length ofsen⁃tences.Experiments are conducted on DSSM(Deep Structured Semantic Model)and VSM(Vector Similarity Model).Results in DSSM show but increases of 12.2%,12.3%and 12.2%on P@3,P@5 and P@10 respectively.Special token preprocess increased VSM precision by 5.5%.Feature textselection helps in semantic understanding in entity disambiguation.
entity disambiguation,feature text,data cleaning
TP391
10.3969/j.issn.1672-9722.2017.08.018
2017年2月7日,
2017年3月19日
国家自然科学基金项目(编号:61472436,61532001,61303190)资助。
庞焜元,男,硕士研究生,研究方向:自然语言处理。唐晋韬,男,助理研究员,研究方向:自然语言处理和社会网络分析。李莎莎,女,助理研究员,研究方向:自然需要理解和社交网络分析。王挺,男,教授,研究方向:自然语言处理和信息检索。
猜你喜欢
英语文摘(2021年8期)2021-11-02
厦门大学学报(自然科学版)(2021年4期)2021-06-22
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
计算机应用与软件(2018年9期)2018-09-26
读者·原创版(2015年11期)2015-03-01
外语教学理论与实践(2014年2期)2014-06-21
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
