
基于MapReduce的关系数据库关键词查询技术
2017-09-11 13:43周鹏程施欢欢
苏州科技大学学报(自然科学版) 2017年3期
周鹏程,施欢欢,钱 钢
(南京财经大学 信息工程学院,江苏 南京210046)
基于MapReduce的关系数据库关键词查询技术
周鹏程,施欢欢,钱 钢*
(南京财经大学 信息工程学院,江苏 南京210046)
为了解决关系数据库关键词查询算法存在的问题,根据图搜索算法,将关系数据转换成数据图,再将数据图物化成key/value形式存于分布式文件系统中。Map函数对数据图中每个节点计算其可达关键词,Reduce函数判断一个节点是否可达所有查询关键词,若满足条件则输出以该节点为根的结果树。在深入研究传统的查询算法基础上,提出了基于MapReduce的分布式并行数据图搜索算法。在用普通PC搭建的Hadoop集群上的实验表明:该方法明显提升了查询结果树生成速度,并且具有较好的可扩展性。
数据图;关键词查询;MapReduce;云计算;分布式计算
关系数据库是目前主流的信息存储机制,如何从海量数据库中以一种高效的方式获取有用的信息是人们亟需解决的问题。如果要利用结构化查询语言从目标数据库中获得精确的结果,就需要用户熟悉数据库专业知识。然而普通用户通常不具备复杂的查询语言(如SQL、SPARQL、XQuery)和底层数据库模式等知识。另一方面,发展得如火如荼的互联网搜索引擎(如Google、百度)为广大用户提供了一种简单易用的信息获取方式,即关键词查询。在搜索引擎中用户只要提交一个关键词集合,就能获取到相关的查询结果。比常规的信息检索更具挑战性的是,由于关系数据库的规范化,原本一条完整的信息可能存储在不同的表中,那么基于关系数据库的关键词查询,目标就不只是找到包含所给关键词的相关文档或文档片段,更重要的是发现关键词之间的语义关系[1]。
目前绝大多数对于关系数据库关键词查询的研究按照对数据库建模的方法来分可以分为两大类:一类是基于数据图的方法[2-4];一类是基于模式图的方法[5-6]。因为,图中的节点和边都可以关联文本内容,所以,图就成了关系数据(节点代表元组,边表示主外键约束关系)、半结构化数据(如XML,节点表示元素,边表示XML元素间的包含关系或引用关系)、Web数据(节点表示网页或者DOM元素,边表示网页间的链接关系或者DOM元素间的包含关系)的一种较好的公共表达形式[3]。因此,关键词查询的问题自然地被转化为图搜索问题,核心就是要从图中高效地搜索到少量的与用户查询高度相关的结果树。作为对传统数据库查询的一种补充方式,关键词查询和应用受到了数据库研究领域越来越多的关注[7-10],但由于其巨大的搜索空间,使得其查询效率难以满足实际应用需求,尤其面对大规模海量数据时更是如此。例如,国家电网数据采集系统实时收集网点中的时序数据,由于其数据规模按时间呈递增趋势,传统的存储、查询技术效率低下,扩展性差,无法支撑调度自动化、配电自动化、海量历史/实时数据管理平台、发电等涉及多个智能电网环节的应用系统。另一方面,大数据与云计算技术带来的信息风暴正在变革人们的生活、工作和思维,大量传统的数据处理技术和数据挖掘技术正被移植到云计算平台。尽管国内外对云计算技术已经开展了很多相关研究,但是如何将它应用于数据库的关键词查询的研究并不多。文献[11]研究了基于MapReduce[12]的分布式索引构建以实现对大规模图数据的搜索优化,但是其只是用MapReduce并行构建索引,而没有把搜索算法MapReduce化。笔者在传统数据图搜索算法的基础上,研究提出基于MapReduce的分布式数据图搜索算法。MapReduce模型处理的是key-value型数据,而关系数据库存储的是表数据,针对MR模型的特征研究了合适的数据分布策略以及相应的搜索方法。实验表明,在大规模数据集中笔者提出的并行算法能够提高数据图搜索效率。
1 相关工作
对于关系数据库的关键词查询,国内外已经出现了一批具有重要意义的研究成果。其中比较有影响的系统有Agrawal等人研发的DBXplorer[5],Hristidis等人提出的DISCOVER[6],Bhalotia等人实现的BANKS[2]。这些研究以及后续一些研究工作[13-14]虽然各有侧重点,但是它们的核心思想是一致的,即将存储在关系数据库中的结构化数据看成图,其中数据库中的元组构成图的顶点,元组间的主外键关系构成图中的边。当用户提出一个关键词查询时,则从图中搜索出含全部或部分关键词的最小子图作为查询结果。对于给定的数据库和查询,DBXplorer、DISCOVER都会生成所有的可能包含关键词的连接树。如果数据库模式结构复杂,那么生成所有的连接树将会十分低效。BANKS首次提出一种叫做逆向搜索(backward search)的图搜索算法。该算法利用了Dijkstra单源点最短路径算法,逆向搜索的路径是由树中的叶子节点到根节点的最短路径构成。如果数据图规模很大,包含某个关键词的节点很多,或者当算法遭遇一个入度非常大的节点时,逆向搜索算法的性能就显得比较差。文献[14]研究提出了一种融合了超节点图和缓存细节图的表示技术以减少查询时的I/O开销,但其应用场景局限于单机系统,不具备可扩展性。
在云计算方面,Google提出的并行计算框架MapReduce[12]给超大规模数据集的处理开辟了思路。不少研究者将MapReduce思想运用到自己的研究领域中,改进传统算法,以提高执行效率。文献[15]提出了一种基于MapReduce的并行混合混沌加密方案,有效解决了云环境中大数据量加密速度慢的问题。文献[16]设计了一个高效的基于MapReduce的大规模图挖掘框架,并在十亿级的数据上验证了其性能。但是把MapReduce应用到数据库关键词查询算法上的研究工作还相对较少。
2 背景知识和问题描述
文中对数据库建模的方式采用数据图,即直接将数据库的实例数据构建成数据图,并转换为key-value对的形式交给MapReduce进行处理,从中枚举简化子图,最终以key-value的形式输出结果。下面给出MapReduce计算模型以及数据图、关键词查询等相关定义。
2.1 MapReduce计算模型
MapReduce[12]是Google提出的一个用于处理大规模数据集的可扩展的分布式编程模型,它既是一个并行计算模型,也是一种并行计算框架。MapReduce框架简化了用户设计并行程序的难度,使得用户只需要考虑算法本身的实现逻辑,而无须关心不同计算机之间的通信、容错等问题。利用该模型,用户可以自定义两个函数Map和Reduce来实现分布式算法。输入数据文件首先被计算框架切分成一个个数据分片,并解析成<keyin,valuein>的形式传入Map函数。Map函数返回一个基于这个处理的中间结果集,即一系列新的<keyout,valueintermediate>,如式(1);MapReduce框架会把从一个或多个 Map任务处理得到的结果集按 keyout值进行分类、汇聚,并分配给相应的Reduce函数进行汇总处理生成最终的valueout值,如式(2)。
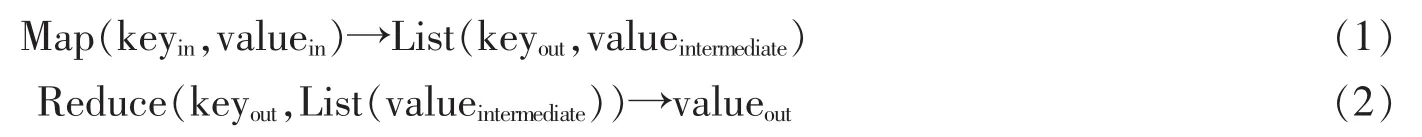
Map和Reduce函数会并行运行,即计算框架会在不同的机器上同时运行多个Map和Reduce任务。许多现实世界中的数据处理任务可以表达成该模型,便于实现并行化的计算。Apache的Hadoop是Google MapReduce的一个开源实现,它提供了与Google GFS类似的分布式数据存储系统HDFS。Hadoop以其简单易用的特性推动了MapReduce的广泛应用,方便了研究人员部署分布式算法。目前,Hadoop已经成为大数据存储与处理的新范式。
2.2 数据图和查询模型定义
定义1 数据图[13]。一个数据图G由一个节点集合V(G)和一个边集E(G)构成。数据图中有两类节点,即结构化数据实例节点S(G)和关键词节点K(G)。关键词节点只有入射边,而实例节点既有入射边也有出射边,因此,一条边不能同时连接两个关键词。数据图的边可以有权重,权重函数wG给每一条边e∈E(G)分配一个正的权重wG(e)。数据图G的权重w(G)是图G中所有边的权重之和,即w(G)=Σe∈E(G)wG(e)。一个数据图是有根的,如果它包含某个节点r,并且对于图中任意节点都可以从节点r通过一条有向路径到达,这个节点r就被称作图G的根。
定义2 关键词查询[1,13]。一个关键词查询就是给定一个有限的关键词集合K。一个关键词查询的结果就是目标数据图G的一棵子树T,T是关于给定的关键词集合K的简化,即T包含了K,并且不再会有T的子树包含K。
定义3 top-k关键词查询[1]。一个top-k关键词查询Q是一个关键词集合K。而相应的查询结果则是一个由k个元组连接树组成的列表T,并且对于查询Q而言,这k个元组连接树的最终评分Score(T,Q)是最高的。当存在评分平局时,可以采用任意的方式打破平局。T中的元组连接树按照评分降序排列。
总的来说,对于给定的关键词集合,基于数据图的查询过程主要包含两个步骤:首先,查找倒排表形式的关键词索引,获得节点ID,这些节点都包含了至少一个查询关键词;然后,运行图搜索算法寻找连接了上述关键词节点的有根树,并且对结果进行排序。
3 基于MapReduce的数据图搜索算法
对于MapReduce来说输入数据就是一系列的<key,value>对,处理逻辑是Map和Reduce函数,因此,并行的数据图搜索算法的关键是定义合适的<key,value>存储结构,以及相应的Map、Reduce函数来表达对数据图的搜索。笔者先介绍传统的单机串行方式数据图搜索算法,然后介绍基于MapReduce的方法。
3.1 传统的数据图搜索算法
逆向搜索(backward search)算法是寻找数据图中最小连接子图的一个经典算法,它在BANKS系统中首先被提出,之后很多研究(如BANKS-II[4]和BLINKS[10]等)都是基于该算法的改进。逆向搜索从每个与关键词匹配的叶节点开始,朝着汇合的根节点向上搜索,每当标记到一个被每个关键词所到达的节点v时,就输出一棵以v为根节点的结果树。逆向搜索算法的具体步骤如下[4]:
(1)在逆向搜索的任意时刻,令Ei表示当前已知的可以到达关键词节点ki的节点集,Ei称作关于ki的簇。(2)在最初始阶段,Ei被定义为直接包含ki的节点集。称这个集合为“原始簇”,它的成员节点即为关键词节点。(3)在搜索过程的每一步,都从先前访问过的节点(比如节点v)开始,选择一条入射边,沿着这条边反向访问它的父节点(比如节点u)。此时任何包含节点v的Ei都被扩展到节点u。一旦一个节点已经被访问,那么搜索算法就可以获得它的所有入射边信息,并且在下一个搜索过程中访问这些边。(4)如果对于每一个簇Ei,都有或者节点x∈Ei,或者存在一条从x到Ei中某个节点的边,则意味着已经发现了一个答案的根节点x。
假设有如图1所示的数据图片段(为描述简便,假设图中每个节点内的数字代表数据库元组的ID,节点旁边的小写字母a,b,c,…表示该元组包含的关键词集合)。以该图为例,来分析逆向搜索算法的执行过程。
假设用户输入的关键词是 b、c,不难发现节点 3、4、5、10、12 都直接包含关键词项,算法会对这5个节点进行反向搜索。节点3可以反向到达节点1,所以标记节点1、3可达关键词c。同理,对节点4进行逆向搜索,可以访问到节点1,所以标记1、4可达关键词b。所以当搜索到节点1时,发现它已经可达关键词b,c,即包含了所有关键词,因此,以节点1为根节点的一棵结果树就生成了,如图2中的结果树I所示。同样的,对节点5、10、12进行逆向搜索将会得到如图2所示的结果树 II、III。

图1 一个数据图片段
从逆向搜索算法模型中可以看到该算法的核心是从原始簇开始进行多次迭代搜索以扩充每个关键词的簇,直到每条搜索路径都已到达图的根节点截止。在迭代搜索的过程中一旦发现某个节点符合要求(对所有关键词可达)就输出以该节点为根的一棵结果树。整个查询过程中图搜索的过程是最耗时的,尤其是当数据图的规模非常大,节点间的联系比较复杂时更是如此。因此,文中考虑基于MapReduce的思想研究并行化的算法把搜索元组连接树的过程MapReduce化。
3.2 基于MapReduce的逆向搜索算法
3.2.1 基于MapReduce的逆向搜索算法的key-value结构和流程
MapReduce计算框架下的输入是key-value数据,其中value可以是简单类型,比如数值或字符串,也可以是复杂的结构,比如列表、记录等。对于数据图来说,其内部表示方式以邻接表为宜,文中设计了式(3)那样的key-value结构。输入数据的key为图中节点ID,对应的value为复杂记录,其中记载了key节点当前可达关键词、key节点的父节点ID等信息。MapReduce内部计算过程中的Shuffle和Sort操作起到类似于通过图中节点出边进行消息传播的效果。

通过将数据图表达成式(3)这样的键值对作为算法输入(即作为Map函数的初始输入),并行执行一系列Map函数和Reduce函数对原始键值对处理,得到包含所有关键词的连接树键值对<key,valueout>,每一个输出键值对代表一棵结果树,其中key表示结果树的根节点ID,valueout表示连接树的路径信息。基于MapReduce的逆向搜索算法的流程如图3。
在图 1 的例子当中,根据数据图生成的初始键值对是:<1,<<a>,<null>>>、<2,<<f>,<1>>>、<3,<<c,d>,<1>>>、<4,<<b>,<1>>>、<5,<<b>,<2>>>、<6,<<e>,<2,3>>>、<7,<<g>,<3>>>、<8,<<f>,<3>>>、<9,<<g>,<5>>>、<10,<<c>,<5>>>、<11,<<a>,<6>>>、<12,<<c>,<6>>>。
3.2.2 逆向搜索算法的Map函数
Map函数根据每个节点 (key-value形式)的父节点列表扩充其可达关键词列表。Map函数伪代码如下:
输入:数据图对应的初始键值对KVPair
输出:新生成的键值对集newKVPair



图2 一个查询的结果树

图3 基于MapReduce的搜索算法流程
以图1所示的数据图(查询关键词为b,c)为例分析Map函数的执行过程。
输入数据文件首先会被分布式文件系统 (HDFS)切分成若干个数据块存储于计算机集群的不同节点。MapReduce计算框架从分布式文件系统中获得输入数据分片并解析出初始键值对交给Map任务处理,Map函数对该键值对进行重组、扩展。例如对于键值对<3,<<c,d>,<1>>>,因为,节点 3 可达关键词 c、d,那么认为节点 3 的父节点 1 也可达该关键词,算法生成若干新的键值对<3,<c,d>>、<1,<c(3)>>、<1,<d(3)>>,分别表示节点3可达关键词c、d,节点1途经节点3可达关键词c,节点1途经节点3可达关键词d。同理,对于其余键值对进行Map操作输出结果如下:
<1,<a>>,<2,<f>>、<1,<f(2)>>,<4,<b>>、<1,<b(4)>>,<5,<b>>、<2,<b(5)>>,<6,<e>>、<2,<e(6)>>、<3,<e(6)>>,<7,<g>>、<3,<g(7)>>,<8,<f>>、<3,<f(8)>>,<9,<g>>、<5,<g(9)>>,<10,<c>>、<5,<c(10)>>,<11,<a>>、<6,<a(11)>>,<12,<c>>、<6,<c(12)>>。
所有的Map任务都是并行工作的,Map的输出结果经过shuffle阶段处理后作为Reduce函数的输入。
3.2.3 逆向搜索算法的Reduce函数
通过MapReduce框架的shuffle过程,具有相同key值的键值对合并,values为它们所有的value值叠加。算法的Reduce函数伪代码如下:
输入:经过shuffle处理过的键值对KVPair
输出:结果树键值对resKVPair和进入下一轮迭代的键值对newKVPair

同样以上面的例子接着分析算法Reduce函数的执行过程。经过shuffle处理后,具有相同key值的键值对归并到一起交给 Reduce 处理。 例如键值对<1,<a>>、<1,<f(2)>>、<1,<c(3)>>、<1,<d(3)>>、<1,<b(4)>>在 shuffle 阶段归并成<1,<a,f(2),c(3),d(3),b(4)>>,表示节点 1 直接可达关键词 a,并且可以通过节点 2到达关键词f,通过节点3到达关键词c、d,通过节点4到达关键词b。Reduce函数会对输入键值对的values列表值进行判断,如果 values中包含所有的查询关键词,就输出结果键值对。 例如键值对<1,<a,f(2),c(3),d(3),b(4)>>同时包含了查询关键词 b 和 c,就可以输出结果树对<1,<c(3),b(4)>>,表示一棵以节点 1 为根节点,节点 3、4 为叶节点的连接树。 同理,键值对<5,<b>>、<5,<g(9)>>、<5,<c(10)>>归并后得到<5,<b,g(9),c(10)>>也能得到一个满足查询要求的结果对<5,<b,c(10)>>,表示一棵以节点 5 为根节点,节点10为叶节点的连接树。同时将节点1、5标记为已输出,即不再寻找以节点1、5为根节点的结果树,降低搜索范围。再把其余键值对重新组装成式(3)那样的形式进入下一轮迭代,直到每个键值对的可达关键词列表不再变化,说明此时整个数据图已经搜索完毕,算法结束。 最终输出的结果对如下:<1,(c(3),b(4))>,<5,(b,c(10))>,<2,(b(5),c(12)(6))>。其中<2,(b(5),c(12)(6))>表示根节点 2 通过节点 5 可达关键词 b,通过节点6、节点12可达关键词c。该结果恰好对应图2的结果树,由此可知基于MapReduce的逆向搜索算法与传统逆向搜索算法的输出结果是一致的。
4 实验分析
4.1 实验环境与设置
文中从执行效率、可扩展性两个方面评估算法的性能。分别在单机上运行串行的数据图搜索算法和在集群上运行基于MapReduce的搜索算法来输出查询结果树。采用的实验集群由1个主控节点Master(同时运行NameNode和ResourceManager进程)、6个计算节点Slave(同时运行DataNode和NodeManager进程)组成,集群的节点配置为 CPU(4 核 Intel Core i5 3.30 GHz),Memory(4GB),Disk(500G STAT),Network Bandwidth(1Gbps),OS(CentOS6.4),JVM Version(JDK1.7),Hadoop Version(Hadoop2.4)。
实验所用数据集是计算机科学文献库DBLP数据集,它提供了计算机领域科学文献的检索服务,但只储存这些文献的相关元数据,如标题、作者、发表日期等。将DBLP网站提供的XML数据分解成4个关系:Author(Aid,Name)、Write(Aid,Pid)、Paper(Pid,Title,Year,Type)、Cite(Pid1,Pid2)。每个 Author和 Paper实例对应于数据图中的一个节点,若实例之间存在Write或者Cite关系则建立相应的边。由于MapReduce的输入是键值对形式,所以预先将数据图映射成key-value数据存储在HDFS上作为MapReduce的输入源,数据集的大小根据不同的实验需求确定。
4.2 执行性能测试
对5组不同规模的数据用传统的单机串行算法和基于MapReduce的并行算法分别进行了5次测试,最后取算法从接收关键词到输出查询结果树的平均时间作为运行耗时,实验所用关键词数量为2,并且都是从DBLP数据中选出来的。实验结果见表1。
由实验结果可见,与传统的方式相比,基于MapReduce的并行方式在处理速度上有明显优势,特别是随着数据集大小的增长,分布式的算法就更能发挥优势。同时发现,基于MapReduce的算法耗时并未随着数据集大小的线性增长而线性上升,这一方面是由于MapReduce框架每次并行运行的Map任务数是根据输入数据大小自动优化的,每次任务运行都有一定的通信开销。另一方面,数据图中节点之间联系的复杂度并不是随着数据量的增长而线性增长的。
4.3 可扩展性测试
为了观察集群的规模增大时算法的性能变化情况,实验中还进行了算法可扩展性测试。实验中,将同一个数据集文件分别在从1个节点(local模式)增长到7个节点(1个主节点+6个从节点)的集群上进行实验,每组实验也进行5次取平均值,实验结果如图4所示。
图4显示了计算节点数目变化时算法的运行时间变化曲线。其中横坐标为集群中在线节点数目,纵坐标为算法执行时间。从图中曲线可见,刚开始时算法的运行时间随着集群内节点数目的增加呈接近于线性下降,之后曲线表现得比较平缓,这主要是由于并行算法的通信调度等开销造成的,特别是在数据规模远小于集群处理能力的情况下这种开销显示出的代价越大。但总的来说,从图4中可以发现随着计算节点的增加,并行执行的耗时下降显著,即算法有比较好的可扩展性。

表1 查询执行时间

图4 集群节点数变化时算法运行时间对比
5 结语
文中针对关系数据库关键词查询中大规模数据图搜索效率低下的问题,以经典的连接树生成算法作为基础,提出了基于MapReduce的分布式并行搜索算法。分析和实验结果表明,并行算法充分利用计算资源减少了时间开销,并且具有较好的可扩展性。进一步的工作包括考虑有意义的结果评分和数据可视化机制,用以将查询结果树按照相关顺序和良好的展现方式返回给用户。
参考文献:
[1]林子雨,杨冬青,王腾蛟,等.基于关系数据库的关键词查询[J].软件学报,2010,21(10):2454-2476.
[2]BHALOTIA G,HULGERI A,NAKHE C,et al.Keyword Searching and Browsing in Databases using BANKS[C]//Data Engineering,2002.Proceedings.18th International Conference on Data Engineering.IEEE,2002:431-440.
[3]KACHOLIA V,PANDIT S,CHAKRABARTI S,et al.Bidirectional Expansion for Keyword Search on Graph Databases[C]//Proceedings of the 31st International Conference on Very Large Data Bases.VLDB Endowment,2005:505-516.
[4]HE H,WANG H,YANG J,et al.BLINKS:Ranked Keyword Searches on Graphs[C]//Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data.ACM,2007:305-316.
[5]AGRAWAL S,CHAUDHURI S,DAS G.DBXplorer:Enabling Keyword Search over Relational Databases[C]//Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data.ACM,2002:627-627.
[6]HRISTIDIS V,PAPAKONSTANTINOU Y.Discover:Keyword Search in Relational Databases[C]//Proceedings of the 28th international conference on Very Large Data Bases.VLDB Endowment,2002:670-681.
[7]MOTTIN D,LISSANDRINI M,VELEGRAKIS Y,et al.Exemplar queries:Give me an example of what you need[J].Proceedings of the VLDB Endowment,2014,7(5):365-376.
[8]ZENG Z,BAO Z,LE T N,et al.ExpressQ:Identifying Keyword Context and Search Target in Relational Keyword Queries[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management.ACM,2014:31-40.
[9]杨书新,徐丽萍,夏小云,等.图数据关键词查询研究进展[J].电子学报,2014,42(11):2260-2267.
[10]王新军,闫实,彭朝晖,等.Extractor:支持查询重构的高效数据库关键词检索系统[J].电子学报,2014,42(2):209-216.
[11]桑雷,钟鸣,陈柳,等.FindGrape:一个高效的图数据库关键词搜索引擎[C]//第29届中国数据库学术会议论文集.合肥:中国计算机学会,2012.
[12]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[13]KIMELFELD B,SAGIV Y.Efficiently enumerating results of keyword search over data graphs[J].Information Systems,2008,33(4):335-359.
[14]DALVI B B,KSHIRSAGAR M,SUDARSHAN S.Keyword search on external memory data graphs[J].Proceedings of the VLDB Endowment,2008,1(1):1189-1204.
[15]王欣宇,杨庚,闵兆娥,等.基于 MapReduce的并行混合混沌加密方案[J].计算机应用研究,2015,32(6):1757-1760.
[16]LAI H C,LI C T,LO Y C,et al.Exploiting and Evaluating MapReduce for Large-Scale Graph Mining[C]//Advances in Social Networks Analysis and Mining(ASONAM),2012 IEEE/ACM International Conference on.IEEE,2012:434-441.
Keyword query over relational databases based on MapReduce
ZHOU Pengcheng, SHI Huanhuan, QIAN Gang*
(College of Information Engineering,Nanjing University of Finance and Economics,Nanjing 210046,China)
In order to solve the problems of memory capacity and CPU processing speed in the traditional search algorithm,we proposed a parallel search algorithm based on MapReduce.In this algorithm,relational data were transformed into graph data which were then stored into HDFS in the form of key-value pairs.Map function calculated all the keywords that one node could reach;Reduce function judged if a node was reachable for all the query keywords.If this condition was satisfied,an answer root was discovered.According to the experiments on Hadoop cluster set up by ordinary PCs,the algorithm speeds up the query process and takes high expansibility.
data graphs;keyword search;MapReduce;cloud computing;distributed computing
TP311
A
2096-3289(2017)03-0064-07
责任编辑:艾淑艳
2015-11-30
江苏省产学研合作项目(BY2015010-05);南京财经大学研究生创新研究基金资助项目(YJS14102)
周鹏程(1990-),男,江苏泰州人,硕士研究生,研究方向:数据库与信息系统。
*通信作者:钱 钢(1975-),男,博士,副教授,硕士生导师,E-mail:zpcandzhj@163.com。
猜你喜欢
软件导刊(2016年11期)2016-12-22
科学与财富(2016年15期)2016-11-24
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
系统工程与电子技术(2016年2期)2016-04-16
