
基于Tag-Tree模板的结构化论坛信息提取
2017-09-08 06:54程倩楠
电子技术与软件工程 2017年14期
文/程倩楠
基于Tag-Tree模板的结构化论坛信息提取
文/程倩楠
结构化的论坛网站多采用动态网页生成技术,将后台数据库的记录信息加入HTML模板,以动态地显示在网页上。与此过程对称,本文首先将不同BBS网站的大量网页解析为Tag-Tree,然后计算树的相似度与构建代价生成多类Tag-Tree模板,同时得到每个模板所对应的网页,寻找模板的重复模式确定记录边界。最后,利用模板解析相应网页得到非模板内容,进而采用启发式规则提取结构信息与记录内容。
相似度 构建代价 Tag-Tree模板记录边界 启发式规则
当今网页信息提取大多采用人工编制的Tag-Tree模板程序对网页进行解析,提取过程过于繁琐。本文针对传统方式的弊端,提出一种基于Tag-Tree模板的结构化论坛信息提取方法。
1 将网页解析为Tag-Tree
网页Tag-Tree包括标签、文本、注释三类结点。其中,文本只能作为Tag-Tree的叶子结点,而标签作为普通结点拥有子节点和属性集。一对标签内的文本与标签作为此标签的子结点,且这类标签具有结束标签。当网页中一个标签以“/>”结束时,我们认为该标签是自结束的。基于以上构造规则,我们将网页解析为Tag-Tree。
2 Tag-Tree模板的生成
定义Tag-Tree B,根节点为J,J的属性集为S,其子节点为X,表示为B(J,X,S)。
2.1 定义Tag-Tree模板
树B与模板B'的根节点相同,属性集S'为S的子集,子节点X'为X的子集,以X'中节点为根节点的树也是其对应X中节点为根节点的树的模板。Tag-Tree模板的集合表示如下:
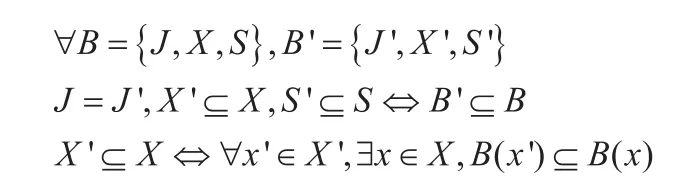
2.2 提取两个Tag-Tree的模板
算法1:提取两个Tag-Tree的公共子树作为模板
输入:两个Tag-Tree
输出:公共子树
(1)将两个Tag-Tree根节点作为公共子树根节点。
(2)若两个Tag-Tree对应节点的子节点存在多对相同结点,进行步骤3-4,否则进行步骤4。
(3)验证哪对相同结点才是相对应的,可以通过计算每对结点树的相似度,选择最大相似度的子节点作为公共结点。
(4)将相同结点插入模板。
(5)重复上述1-4过程,直到所有结点判断完毕,生成模板。
2.3 计算Tag-Tree相似度
为了得到Tag-Tree的构建代价,首先计算Tag-Tree结点构建代价T,其中默认叶子结点构建代价为1,父节点构建代价为自身代价1加上子节点代价的加权和,即

设Tag-tree D与Tag-Tree E提 取 的 模板为B,则D与E的相似度L为B的构建代价在D和E中构建代价的比例相乘,即提取模板的算法需要计算树的相似度,而相似度的计算也要利用公共模板,这是一种迭代关系。
2.4 从不同网站提取多类模板
本文定义了模板提取过程中所需要的一种度量Minimal Template Portion简记做MTP。如图1所示。
提取多个网站不同网页的各类公共模板我们的思路是,首先,将网页解析为Tag-Tree,分别与模板集合中存在的各模板提取公共模板,计算新模板的MTP,选取具有最大MTP值的新模板代替原模板,加入模板集合中,并将Tag-Tree对应到此模板中。如果最大MTP小于临界值ε,则创建新模板类,将此Tag-Tree置为模板及模板对应的第一个标签树。采用上述方法,得到最终的Tag-Tree模板集合及各模板所对应的网页。

图1
3 确定记录边界提取各类信息
Tag-Tree模板为多个网页共有的部分,于此我们认为每个网页所独有的信息隐藏在Tag-Tree的非模板内容中。由于BBS网页中可能存在多个帖子,我们首先需要在模板上寻找子树的重复模式,来确定记录边界。然后,利用生成的模板解析Tag-Tree,从而得到模板之外的非模板内容。最后,利用启发式规则及信息表达规则发现记录内不同字段的描述,进而得到不同的记录信息。
4 结语
基于Tag-Tree模板的结构化论坛信息提取方法,通过解析网页得到Tag-Tree并计算树的相似度,采用聚类思想完成不同类型BBS网站Tag-Tree模板的自动提取,用于解析HTML的非模板内容,过滤了网页中的广告等噪音信息,较准确提取非模板内的各种记录信息。
[1]王璟琦.基于内容单元的网页解析与内容提取[D].黑龙江:哈尔滨工业大学,2008(12).
[2]吉向文.标签树模板在网页关键信息抽取及话题识别中的应用[D].上海:复旦大学,2009(04).
作者单位 山东师范大学信息科学与工程学院 山东省济南市 250000
程倩楠(1997-),女,山东省泰安市人。山东师范大学信息科学与工程学院本科在读。主要研究方向为计算机信息技术。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
数学物理学报(2018年1期)2018-03-26
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
计算机工程(2015年8期)2015-07-03
中学生(2015年12期)2015-03-01
华东理工大学学报(自然科学版)(2014年5期)2014-02-27
电子设计工程(2014年12期)2014-02-27
苏州市职业大学学报(2010年1期)2010-01-29
