
语谱图傅里叶变换的二字汉语词汇语音识别
2017-09-07 17:45潘迪梁士利魏莹许廷发王双维
现代电子技术 2017年16期
潘迪 梁士利 魏莹 许廷发 王双维
摘 要: 以语音信号的语谱图作为处理对象,提出一种基于宽窄带语谱图傅里叶变换频域图像二进宽度分带投影特征融合的二字汉语词汇语音识别算法。首先,对宽窄语谱图傅里叶变换频域图的图像意义以及相应的语音特性进行分析;然后,分别对宽窄带语谱图频域图像进行二进宽度分带列投影和行投影,将投影值作为语音识别的第一个特征参数集合和第二个特征参数集合,将以上两个特征集进行特征融合作为二字词汇语音识别的特征量,以支持向量机为分类器实现二字汉语词汇语音识别。实验结果表明,该方法对特定人二字汉语词汇语音的识别率可达96.8%,对非特定人二字汉语词汇语音的识别率可达98.8%,为解决汉语词汇整体语音识别提供了一种新的思路。
关键词: 傅里叶变换; 语谱图; 特征融合; 支持向量机
中图分类号: TN912?34 文献标识码: A 文章编号: 1004?373X(2017)16?0013?06
Abstract: A speech recognition algorithm of two?word Chinese vocabulary is proposed, which takes the spectrogram of speech signals as a processed object, and is based on binary width zoning?band projection feature fusion of the broad?band and narrow?band spectrogram images in Fourier transform domain. First, the image significance of Fourier transform domain image in the broad?band and narrow?band spectrogram and their corresponding speech characteristics are analyzed. Then, the binary width zoning?band column projection and line projection of the broad?band and narrow?band spectrogram frequency domain image are carried out respectively. The projected value is taken as the first and second feature parameter sets for speech recognition. The above two feature sets are fuzed according their features as the feature value of two?word vocabulary speech recognition. Taking the support vector machine (SVM) as a classifier to realize the speech recognition of two?word Chinese vocabulary. The experiment results show that the recognition rate of this method can reach to 96.8% for specific persons and 98.8% for non?specific persons. The proposed method provides a new way for vocabulary recognition.
Keywords: Fourier transform; spectrogram; feature fusion; support vector machine
0 引 言
语音识别技术就是让相应的设备通过识别和理解两个过程把语音信号转变为相应的命令或文件的高科技技术。近几年来,语音识别技术的理论研究得到了飞速的发展,相应的应用实现也越来越贴近人们的生活,从而大大提高了相应的工作效率和生活品质[1]。
一般来说,语音识别的方法有四种:基于声道模型和语音知识的方法、模板匹配的方法、随机模型的方法和利用人工神经网络的方法。2002年,孙光民研究了基于神经网络的中文孤立词语音识别技术,将时间规整算法与神经网络相结合,组成一个混合级联神经网络语音识别系统。利用该方法对小词表汉语孤立词进行语音识别实验,获得了98.25%的正确识别率[2]。2005年,林遂芳等人提出一种基于动态时间规整(DTW)和学习矢量量化(LVQ)神经网络的语音识别方法。该方法用动态时间规整算法先对语音信号进行时间规整,然后通过学习矢量量化神经网络进行语音的分类识别。大量实验表明,采用DTW/LVQ混合模型的识别的正确率[3]为97.9%。2009年,张军等人针对动态时间规整(DTW)对孤立词端点检测准确性过度依赖的问题,采用放宽端点和限定动态规整计算范围结合的算法解决此问题,该算法不仅更准确地放松前后端点降低端点检测的敏感度,而且结合对动态规整计算范围的限定,减少计算量,提高执行效率。实验结果发现采用改进后的DTW算法,平均识别率[4]达到91.8%。同年,吴金南等人针对传统LVQ算法计算量大,泛化能力不强的缺点,采用改进的LVQ算法(LoPLVQ),以缩短训练时间,提高识别率,增强分类器的泛化能力,并且DTW的时间规整能力强,综合了两者的优点,使得新系统在语音识别方面效果显著。实验结果表明,常用汉字发音识别率[5]最高可达99.1%。2010年,肖利君提出了整体路径约束DTW算法(ADTW),并用Matlab语言将改进的语音识别算法编程,仿真表明该算法能有效地提高识别率并有着极好的鲁棒性。对于一定的孤立词汇,整体路径约束DTW算法的识别率[6]达到97.5%。2014年,陈孟元在提取MFCC的基础上,整合差分倒谱参数作为语音的特征参数,并对现有的DTW算法加以改进,节省了系统匹配的计算时间,使其具有一定的鲁棒性。分别对普通话语音、湖北话语音、安徽语音和闽南语音进行测试,每种语音有5个测试模板组,每个模板组将0~9这10个数字语音重复10遍,包括100个测试语音,系统对所有测试模板组的平均识别率[7]为94.55%。endprint
以往基于语谱图的语音识别工作,仅在语谱图本身的空域结构中直接寻找特征,并没有充分利用语谱图作为可视化图像的性质。考虑到语谱图表征语音特性体现在纹络结构上,而图像纹络结构更容易由图像的频域描述。因此,本文对语谱图进行再次傅里叶变换,将其图像空域转换至图像频域,分别对宽窄带语谱图频域图像进行二进宽度分带列投影和行投影,将投影值进行融合作为语音识别的特征量,以支持向量机为分类器。实验表明:本方法对特定人二字汉语词汇语音的识别率可达96.8%以及对非特定人二字汉语词汇语音的识别率可达98.8%,为解决汉语词汇整体语音识别提供了一种新的思路。
1 宽窄带语谱图意义
语谱图(Spectrogram)是表示语音频谱随时间变化的图形,它采用二维平面来表达三维信息,其纵轴为频率,横轴为时间,任一给定频率成分在给定时刻的强弱用相应点的灰度或色调的浓淡来表示。语谱图中显示了大量的与语音的特性有关的信息,它综合了频谱图和时域波形的特性,明显地显示出语音频谱随时间的变化情况。所以,语谱图所承载的信息量远远大于单纯时域和单纯频域承载信息量的总和[8]。
窄带语谱图有较高的频率分辨率,在谱图上能显示出两个纯音,但其时间分辨率较差,看不出两个纯音所产生的拍音[9]。因此,作为词汇的窄带语谱图,可以反映词汇整体的基频及各次谐波的时间变化。窄带语谱图中基频及各次谐波体现为等间隔的横杠,从图像角度,这些等间隔的横杠反映了图像竖直方向上的周期特征。如果将语谱图进行傅里叶变换,即由语谱图的空域转换到语谱图的频域,则上述横杠的周期性表现为语谱图频域竖直方向上的基频。
宽带语谱图有较高的时间分辨率,在谱图上能显示两个纯音所产生的拍音,但其频率分辨率较差,看不出两个纯音。因此作为词汇的宽带语谱图,可以观察频谱包络,以便确定共振峰,同时也可以给出精确的时间结构。从图像角度,这些等间隔的竖条反映了图像水平方向上的周期特征。如果将语谱图进行傅里叶变换,即由语谱图的空域转换到语谱图的频域,则上述竖条的周期性表现为语谱图频域水平方向上的基频。
本文以宽窄带语谱图作为研究对象,语音的频率特征和时间特征都得到深入体现。所以,更好地反映语音信号的整体特性,为解决汉语词汇整体语音识别提供了一种新的思路。
2 特征级图像融合
特征级图像融合是指从各个信源图像中提取特征信息,并将其进行综合分析和处理的过程[10]。特征级图像融合主要包含两个步骤:
(1) 提取特征,提取的特征信息应是像素信息的充分表示量或充分统计量,如边缘、形状、轮廓、角、纹理、相似亮度区域、相似景深区域等;
(2) 对提取的特征进行融合,在进行融合处理时,所关心的主要特征信息的具体形式和内容与多源图像融合的应用目的和场合密切相关。
本文将宽带语谱图频域图像进行二进宽度分带列投影得到的特征量与窄带语谱图频域图像进行二进宽度分带行投影得到的特征量进行融合,以此对二字汉语词汇进行语音识别。
3 语谱图频域图像矩阵的特征提取
3.1 语谱图样本构成
使用Cool Edit Pro 2.0软件进行语音录制,采样率为44.1 kHz ,使得语谱图频域表达范围为0~22 kHz,单声道,16 b量化。共10人(男、女各5人)10个词汇的读音样本,10个词汇均为二字词汇,重复10遍,即每个词汇有10个样本。一个词汇的语音时长约为1.2 s,10人的10个词汇共为1 000个语音样本文件。所有语音样本文件转化为Matlab数据文件,即语音样本序列。
3.1.1 窄带语谱图样本构成
窄带语谱图样本构成是通过对每个样本序列进行分帧,帧长1 024点,为了保持其连续性,采用重叠率为25%的帧移量;另外,为了移去直流分量和加权高频分量,采用汉明窗(Hamming)对信号进行加权,每个样本分为54帧,构造出1 024行54列时域分帧矩阵。对时域分帧矩阵做FFT,生成1 024行54列时频分析矩阵,频域分辨率为43 Hz。时频分析矩阵的模矩阵即为样本所对应的语谱图矩阵。由于傅里葉变换具有对称性,取该矩阵的上半部或下半部作为语谱图即可,因此,每一幅语谱图的矩阵为512行54列,共1 000幅灰度图像。
3.1.2 宽带语谱图样本构成
宽带语谱图样本构成是通过对每个样本序列进行分帧,帧长128点,窗函数采用汉明窗,每个样本分为410帧,构造出128行410列时域分帧矩阵。对时域分帧矩阵做FFT,生成128行410列时频分析矩阵,频域分辨率为344 Hz。时频分析矩阵的模矩阵即为样本所对应的语谱图矩阵。由于傅里叶变换具有对称性,取该矩阵的上半部或下半部作为语谱图即可,因此,每一幅语谱图的矩阵为64行410列,共1 000幅灰度图像。以上过程本文形成了参数可调的Matlab语谱图生成程序,以备随时调用。为了消除由于音量不同造成的各个样本幅度差异,对每个图像矩阵均进行归一化处理。
3.2 语谱图特征提取
语谱图图像中像素的灰度值代表了信号在相应频率、相应时刻的幅度比重。基于图像处理思路,对其进行频谱分析,将语谱图图像进行再次傅里叶变换,形成语谱图图像频域特性矩阵,并将频谱低频部分移到中心处。通过分析其幅频特性,可发现图像的频域矩阵是转置对称矩阵,其可完全描述图像幅频特征的独立子阵是上半子阵,或下半子阵,或左半子阵,或右半子阵,这里选择对窄带语谱图上半子阵进行二进宽度分带行投影,宽带语谱图左半子阵进行二进宽度分带列投影方法提取特征量。这种投影反映了词汇发音全过程中语音基频及其谐波关系的总体特性,同时还反映了语图条纹边缘梯度的整体特性。实验表明,不同词汇其相应的上述总体特性具有显著性差异。
4 实验仿真与结果分析
4.1 系统设置endprint
本次语音样本采用10人的10个二字词汇进行录制而成,采样频率为44.1 kHz,单声道,16 b量化,其中每个词汇10段重复录音,一共是1 000个语音数据样本。为了采样数据的准确性和可说服性,将每个人的10个二字词汇的每前5遍作为训练集,后5遍作为测试集,即前500个语音数据作为训练集,后500个语音数据作为测试集。在训练阶段,为了后面的数据处理的方便和保证程序运行时收敛加快而进行了归一化处理,将前500个语音训练样本特征数据存入数据库,作为支持向量机的训练模板,对其进行训练。在检测阶段,将后500个语音样本中提取出的特征数据放入到训练好的网络中,对相应的二字词汇进行语音检测。
4.2 仿真结果
4.2.1 特定人二字汉语词汇语音识别的仿真结果
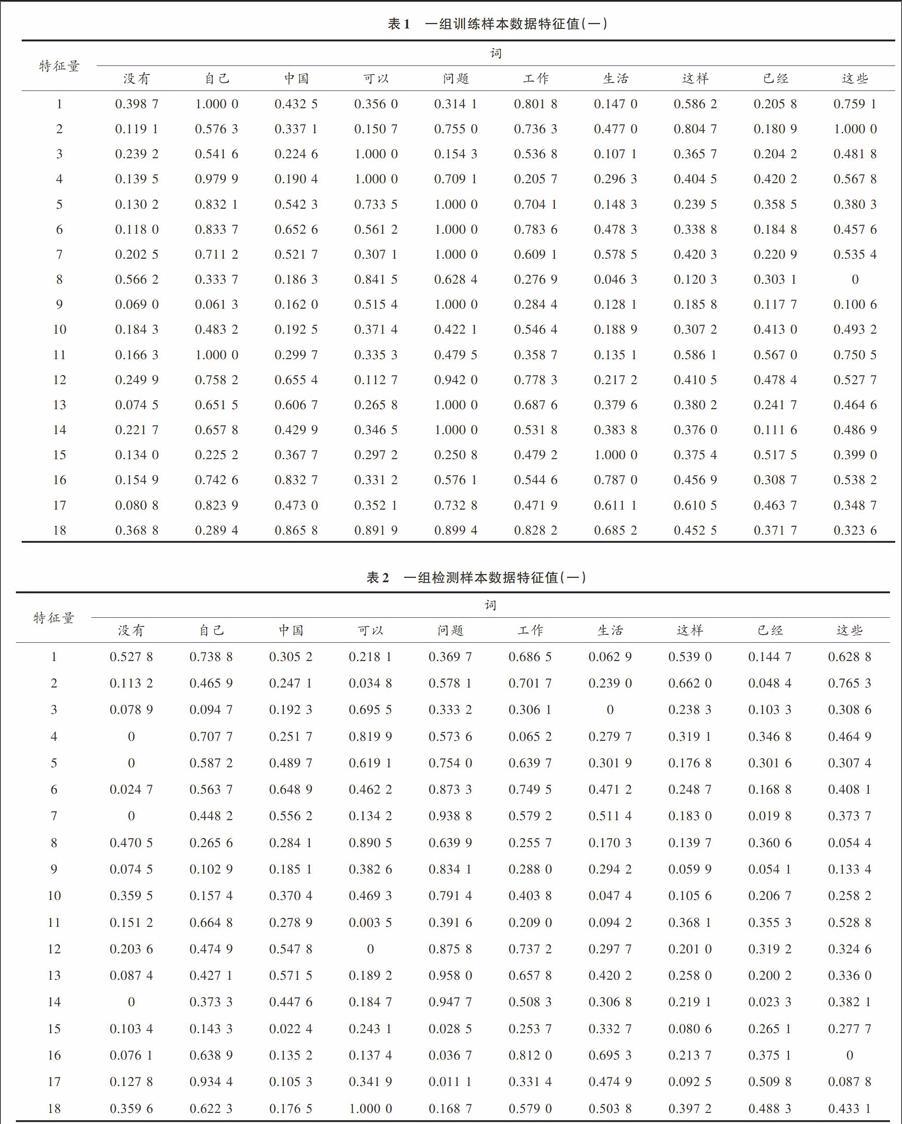
对窄语谱图矩阵进行二次傅里叶变换之后,构造每个词汇的上半子阵的左半部分7行10列二进宽度分带投影矩阵和每个词汇的上半子阵的右半部分7行10列二进宽度分带投影矩阵。将上半子阵的左半部分小矩阵和上半子阵的右半部分小矩阵合在一起形成一个14行10列的大矩阵。同时,对宽带语谱图矩阵进行二次傅里叶变换之后,构造每个词汇的右半子阵的上半部分10行2列二进宽度分带投影矩阵和每个词汇的右半子阵的下半部分10行2列二进宽度分带投影矩阵。将右半子阵的上半部分小矩阵和右半子阵的下半部分小矩阵分别转置后合在一起形成一个4行10列的大矩阵,将两个大矩阵合成一个18行10列的矩阵,作为特定人二字词汇语音识别特征量。一个人的10个词汇10遍得到10组数据,10个人即可得到100组数据,分别相应地将每个人的10个词汇前5遍作为训练样本数据,后5遍作为检测样本数据。本文只选择一组训练样本数据和检测样本数据给予显示,训练样本数据见表1,检测样本数据见表2。支持向量机的参数是:通过支持向量机来实现10人的10个词汇的语音识别,由于特征向量的维数是18维,因此输入维度是18维,中间层内积核函数维度是18维,本文是对10人的10個词汇的语音识别,所以采用基数词1~10的编码方式,即1维十进制输出。通过前50组数据对支持向量机进行反复训练,得到最佳适用模板,将后50组数据放入训练好的模板中,对10个特定人的二字词汇的语音识别正确率达到96.8%。
4.2.2 非特定人二字汉语词汇语音识别的仿真结果
对窄语谱图矩阵进行二次傅里叶变换之后,构造每个词汇的上半子阵的左半部分6行10列二进宽度分带投影矩阵和每个词汇的上半子阵的右半部分6行10列二进宽度分带投影矩阵。
将上半子阵的左半部分小矩阵和上半子阵的右半部分小矩阵合在一起形成一个12行10列的大矩阵。同时,对宽带语谱图矩阵进行二次傅里叶变换之后,构造每个词汇的右半子阵的上半部分10行3列二进宽度分带投影矩阵和每个词汇的右半子阵的下半部分10行3列二进宽度分带投影矩阵。将右半子阵的上半部分小矩阵和右半子阵的下半部分小矩阵分别转置后合在一起形成一个6行10列的大矩阵,将两个大矩阵合成一个18行10列的矩阵,作为非特定人二字词汇语音识别特征量。一个人的10个词汇10遍得到10组数据,10个人即可得到100组数据,分别相应的将每个人的10个词汇前5遍作为训练样本数据,后5遍作为检测样本数据。
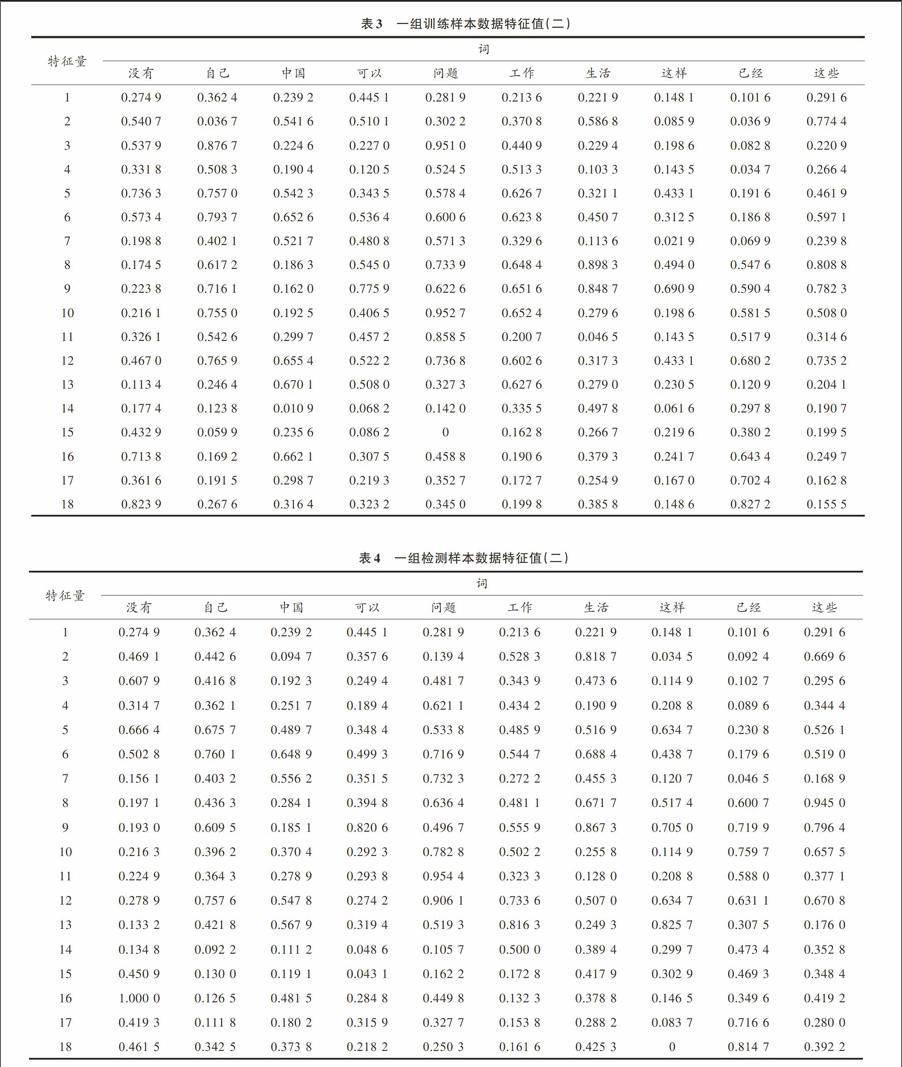
本文只选择一组训练样本数据和检测样本数据给予显示,训练样本数据如表3所示,检测样本数据如表4所示。
支持向量机的参数是:通过支持向量机来实现10人的10个词汇的语音识别,由于特征向量的维数是18维,因此输入维度是18维,中间层内积核函数维度是18维。本文是对10人的10个词汇的语音识别,所以采用基数词1~10的编码方式,即1维十进制输出。通过前50组数据对支持向量机进行反复训练,得到最佳适用模板,将后50组数据放入训练好的模板中,对10个非特定人的二字词汇的语音识别正确率达到98.8%。
5 结 论
本文提出了一种基于宽窄带语谱图傅里叶变换特征融合的二字汉语词汇识别算法。以宽窄带语谱图作为研究对象,语音的频率特征和时间特征都得到深入体现,所以,更好地反映了语音信号的整体特性。实验结果表明,采用宽窄带语谱图融合得到的特征值对特定人二字词汇语音的识别率可达96.8%,而采用宽窄带语谱图融合得到的特征值对非特定人二字词汇语音的识别率可达98.8%,为解决汉语词汇整体语音识别提供了一种新的思路。
参考文献
[1] 何湘智.语音识别的研究与发展[J].计算机与现代化,2002(3):3?6.
[2] 李永健.基于DTW和HMM的语音识别算法仿真及软件设计[D].哈尔滨:哈尔滨工程大学,2009.
[3] 陈立伟.基于HMM和ANN汉语语音识别[D].哈尔滨:哈尔滨工程大学,2005.
[4] 王伟臻.基于神经网络的语音识别研究[D].杭州:浙江大学,2008.
[5] 王山海,景新幸,杨海燕.基于深度学习神经网络的孤立词语音识别的研究[J].计算机应用研究,2015,32(8):2289?2291.
[6] 田岚,陆小珊,白树忠.基于快速神经网络算法的非特定人语音识别[J].控制与决策,2002(1):65?68.
[7] 孙光民,董笑盈.基于神经网络的汉语孤立词语音识别[J].北京工业大学学报,2002,28(3):289?292.
[8] 赵力.语音信号处理[M].2版.北京:机械工业出版社,2009.
[9] 张家騄.汉语人机语音通信基础[M].上海:上海科学技术出版社,2010.
[10] 何友,王国宏,关欣.信息融合理论及应用[M].北京:电子工业出版社,2010.endprint
猜你喜欢
科技资讯(2017年11期)2017-06-09
电子技术与软件工程(2017年5期)2017-04-23
亚太教育(2016年34期)2016-12-26
亚太教育(2016年34期)2016-12-26
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
光学仪器(2015年1期)2015-07-30
分析化学(2014年9期)2014-09-26
