
一种图像感兴趣区域提取方法研究
2017-09-01 15:54:44范向阳
计算机技术与发展 2017年8期
王 诚,范向阳
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
一种图像感兴趣区域提取方法研究
王 诚,范向阳
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
关于图像感兴趣区域(ROI)提取,改进的Stentiford视觉模型方法与传统的Stentiford视觉模型方法以及其他视觉模型方法相比,具有提取的图像区域清晰、边缘明显、效率高等优点,但在图像背景较为复杂时,会提取到目标区域以外的区域。鉴于实际研究中对准确度的要求,需要从已提取区域中挑选出目标区域。为此,在所涉及的图像处理过程中,提出了多种图像新特征的提取方法,并引入数据挖掘领域中的经典FP-Growth算法,在改进的Stentiford视觉模型方法对训练集图像处理后,提取图像显著熵、显著熵密度等众多图像特征,并应用FP-Growth算法挖掘图像特征和目标区域的关联规则,同时将获取到的规则应用于测试集的大量实验验证之中。实验结果表明,采用了所提出的方法后,提取到的图像区域准确度有显著提高,表明该方法是可行有效的。
图像感兴趣区域;Stentiford视觉模型;FP-Growth算法;图像特征
0 引 言
基于人眼视觉模型的人眼感兴趣区域提取有多种经典方法,例如Itti视觉模型[1]、GBVS视觉模型[2]、谱剩余模型[3]、Stentiford模型[4-5]等。通过对比,Stentiford模型提取的效果最为清晰和准确。但是Stentiford模型有提取结果随机性过大,对图片细节过于敏感,计算量大造成耗时等问题。为此,对Stentiford方法加以改进。
虽然改进的Stentiford方法明显提高了图像提取的质量和效率,使得提取的图像区域清晰,边缘明显,但同时也带来了新的问题。当图像背景不单一、不均匀时,会得到众多的与目标无关的区域,这些区域大小不一,分布无规律,简单的去噪操作达不到要求。因此,在以上方法得到提取区域的基础上,需要挑选出目标区域,即区域选择的过程,来进一步精确提取。主要步骤如下:
(1)将训练集图像通过改进Stentiford方法生成显著图,作为特征提取的研究对象。
(2)将显著图进行分割,得到独立的分割区域。这里选用了经典的图像分割算法—Otsu算法[6]进行处理。
(3)为了解决噪声,在微小无关细节区域干扰的前提下,提取位置等相关特征,提取分割图像骨架,生成骨架图像,作为特征提取研究对象。
(4)生成的骨架图像结合输入的训练集图像和分割的显著图大量提取图像特征,包括首次引入的显著度熵、显著度熵密度的特征。
(5)通过FP-Growth算法挖掘频繁项集。
(6)将提取的频繁项集应用到测试集中,与其他方法进行对比。
1 理论基础
1.1 改进的Stentiford模型
(1)通过灰度变换将输入的彩色图像转变成灰度图像。
(2)对灰度图像的像素点进行双线性插值,得到像素点八邻域值。
(3)计算图像的Uniform LBP[7-9]矩阵:根据像素点八邻域值,对比Uniform LBP的59模式,从而得到Uniform LBP矩阵。
(4)对得到的矩阵进行直方图统计:以等级、像素值、坐标点作为参数,构建三维数组。
(5)计算显著度矩阵,根据统计的个数比例生成显著度矩阵。
(6)生成显著图。将显著度矩阵按比例转换到灰度空间,以取得较好的视觉效果。
1.2 Otsu算法二值化
假设一幅图像共有K个灰度级(0,1,…,K-1),用N(m)表示灰度值为m的像素点数。
则图像总的像素数为:
N=N0+N1+…+NK-1
(1)
灰度值为m的点的概率为:

(2)
门限t将整幅图像分为暗区S1和亮区S2,类间方差σ是t的函数:
σ=A1×A2(U1-U2)2
(3)
其中,Aj(j∈[1,2])为类Sj的面积与图像总面积之比。
A1=SUM(P(m))m→t
(4)
A2=1-A1
(5)
Uj为类Sj的均值。
(6)
(7)
取σ最大值时t的值,令U=U1-U2,有:
σ=max{A1(t)×A2(t)U2}
(8)
1.3 显著度熵、显著度熵密度、显著度熵和
引入显著度熵的概念,并将其值作为图像众多特征之一。由于显著度矩阵代表着感兴趣度,点值在区间(0,1)内,数值与兴趣度成反比,也就是说数值越小表示兴趣度越高,数值越大兴趣度越低,这是将其计算熵的前提,也符合熵的概念。因此,为了定量分析兴趣度与显著度的关系,通过式(9)获得显著度熵。由于要解决图像区域选择的问题,在此基础上,为了表征分割后的区域兴趣度的和及平均兴趣度,分别按式(10)、式(11)计算。
H(x,y)=log2p(x,y)
(9)
其中,p(x,y)为ImageB的点值;(x,y)为坐标;H(x,y)为ImageD的点值。
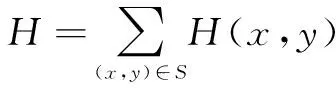
(10)
(11)
其中,S为对应图像各个分割后的区域。
1.4 频繁项目集
频繁项集的相关概念出自于数据挖掘中的关联规则算法[10-11],而关联规则[12]相关概念如下:
设D是事务数据库,n个不同的项目元素组成集合I={i1,i2,…,in},I中项目的集合构成具体的每一个事务T,即T⊆I,记为TID{T}。事务TID{Ti}组成事务数据库D={T1,T2,…,Tn}。对于项目集X∈I,若X∈T,则称T支持X。如果X中有k个项目,X可以称为k-项目集。
项集X⊆T的支持度表示为:
(12)
关联规则表示数据间的隐含关系。例如,X→Y,X⊆I,Y⊆I,X∩Y≠∅,则X→Y的支持度为:
(13)
X→Y的置信度为:
(14)
根据实际需要,人为设定最小支持度Minsup和最小置信度Minconf两个阈值。若Sup(X)≥Minsup,则称项集X是频繁项集。对于任意Y⊃X,Sup(Y)≥Minsup恒成立,则此时的X可称为最大频繁项集。
1.5 FP-Growth算法
FP-Growth算法[13-15]描述如下:
(1)扫描数据库,对1项项目集次数降序排列,删除小于最小支持度的项。
(2)分别对新构建的FP-tree重复此过程,直到新构造的FP-tree只包含一条路径,或者为空。
(3)若构造的FP-tree为空,其前缀即为频繁模式;若FP-tree只包含单一路径,枚举所有可能组合并与此树的前缀。
2 算法应用
2.1 改进模型
设原图像为ImageA,通过改进的Stentiford模型进行计算处理:
(1)将输入的彩色图像灰度变换为灰度图像,对灰度图像的像素点进行双线性插值,得到像素点八邻域值;
(2)计算图像的Uniform LBP矩阵;
(3)对得到的矩阵进行直方图统计;
(4)计算显著度矩阵,根据统计的个数比例生成显著度矩阵ImageB;
(5)生成显著图ImageC。
2.2 图像分割
针对ImageC,通过Otsu算法获取阈值,对于大于阈值的区域为白色,对于小于阈值的区域变为黑色,最终图像被分割成多个黑白相间区域。也就是黑色区域较白色有较高的兴趣度,接下来就是实现从众多分割后的黑色区域中挑选出目标区域。
2.3 图像骨架提取
在图像ImageE的起始处,适当大小矩形模块(长l,宽w)表示如下:
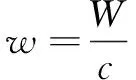
(15)
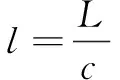
(16)
其中,L、W分别为ImageE的长和宽的像素点数;理论上c取值没有严格限制,但取值过小,使得图像骨架提取过于粗糙,过大会使骨架过于敏感,没有较好回避噪声点干扰。
这里c=20,逐行扫描,处理ImageE,按式(17)计算:

(17)
其中,N为模块大小,单位像素点;K为当前模块下像素点为0的个数。
设定阈值t=0.5:
Ifλ>t记为0
Else记为1
得到矩阵ImageF。对ImageF分两次进行四邻域分块处理,最终得到分割矩阵ImageG。
2.4 图像特征提取
I1:ImageA目标区域颜色x1,x1由{红、橙、黄、绿、青、蓝、紫}组成;
I2:图像结构(通过计算ImageG中目标区域、背景区域的面积、位置关系分为四类,对于图像主要目标区域和单一背景组成的可分为三类:包含,半包含,上下左右,记为I2a、I2b、I2c。背景不均匀单一的图像,统计为I2d);
I3:ImageA背景区域颜色(这里将除目标以外的图像所有部分认作背景区域);
I4:ImageA目标区域Red颜色分量总和占整幅图像比例区间,将区间等分为3段 [0,1/3),[1/3,2/3),[2/3,1],标记为I4a、I4b、I4c;
I5:ImageA目标区域Green颜色分量总和占整幅图像比例,将区间等分为3段 [0,1/3),[1/3,2/3),[2/3,1],标记为I5a、I5b、I5c;
I6:ImageA目标区域Blue颜色分量总和占整幅图像比例,将区间等分3段 [0,1/3),[1/3,2/3),[2/3,1],标记为I6a、I6b、I6c;
I7:三个颜色分量占比最大值,区间等分为3段 [0,1/3),[1/3,2/3),[2/3,1],标记为I7a、I7b、I7c;
I8:图像的一阶颜色矩:
(18)
其中,i代表颜色通道数,由于是彩色图像所以i∈[1,3],依次对应(Red,Green,Blue);pij代表第j个点,第i个颜色通道的颜色值;N代表图像总像素点数。
i=1,将区间(0,255)等分为3段,(0,85),(85,170),(170,255),标记为I8a、I8b、I8c;
I9:图像的一阶颜色矩i=2,将区间(0,255)等分为3段,(0,85),(85,170),(170,255),标记为I9a、I9b、I9c;
I10:图像的一阶颜色矩i=3,将区间(0,255)等分为3段,(0,85),(85,170),(170,255),标记为I10a、I10b、I10c;
I11:图像的一阶颜色矩最大值,将区间(0,255)等分为3段,(0,85),(85,170),(170,255),标记为I11a、I11b、I11c;
I12:图像的二阶颜色矩[16]:
(19)
i=1,将取值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I12a、I12b、I12c;
I13:图像的二阶颜色矩i=2,将取值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I13a、I13b、I13c;
I14:图像的二阶颜色矩i=3,将取值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I14a、I14b、I14c;
I15:图像的二阶颜色矩最大值,将取值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I15a、I15b、I15c;
I16:图像的三阶颜色矩:
(20)
i=1,将取值绝对值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I16a、I16b、I16c;
I17:图像的三阶颜色矩i=2,将取值绝对值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I17a、I17b、I17c;
I18:图像的三阶颜色矩i=3,将取值绝对值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I18a、I18b、I18c;
I19:图像的三阶颜色矩最大值,将取值区间(0,125)等分为3段(0,42),(42,84),(84,125),标记为I19a、I19b、I19c;
I20:由于ImageD是ImageB的骨架,也是一种映射,而ImageD是已分割的图像,所以,对ImageD已分割的块,通过式(21)计算各个块对应在ImageB区域的熵,求取全局平均熵密度。
H(x,y)=log2p(x,y)
(21)
由于概率范围[0,1]对应熵1区间[0,+∞],所以等分概率区间[0,1/3],[1/3,2/3],[2/3,1],从而得到熵密度区间(0,log23),(log21.5,log23),(log23,+∞)。
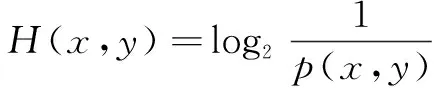
(22)
(23)
其中,S为对应在ImageB区域的区域;N为S的点数。
I21:ImageD图像,分割得到的区域块数x21,x21∈N*;
I22:求取各个块平均的熵密度,目标熵密度的排名x22,x22∈N*:
I23:目标区域熵密度;
I24:目标区域熵密度,平均熵密度两者的大小关系,大于、小于、等于分别标记为I24a、I24b、I24c;
I25:目标区域熵密度,在大于平均熵密度的熵和的排名x25,x25∈N*;
I26:目标区域熵密度,在小于平均熵密度的熵和的排名x26i,i∈N*;
I27:目标区域熵和的排名,x27,x27∈N*。
对图片填入数据库,以图1为例。

图1 示例图
I1:a:黄、青;b:黄
I2:a:包含,记为I2a;b:背景复杂,记为I2d
I3:a:绿;b:蓝、白
I4:a:0.36,0.36∈(1/3,2/3)记I4b;b:0.285,0.285∈(0,1/3)记I4a
I5:a:0.65,0.65∈(1/3,2/3)记I5b;b:0.67,0.67∈(2/3,1)记I5c
I6:a:0.347,0.347∈(1/3,2/3)记I6b;b:0.57,0.57∈(1/3,2/3)记I6b
I7:a:0.65,0.65∈(1/3,2/3)记I7b;b:0.67,0.67∈(2/3,1)记I7c
I8:a:98,98∈(85,170)记I8b;b:107,107∈(85,170)记I8b
I9:a:160,160∈(85,170)记I9b;b:98,98∈(85,170)记I9b
I10:a:108,108∈(85,170)记I10b;b:227,227∈(170,255)记I10c
I11:a:160,160∈(85,170)记I11b;b:227,227∈(170,255)记I11c
I12:a:90.5,90.5∈(84,125)记I12c;b:115.9,115.9∈(84,125)记I12c
I13:a:36,36∈(0,42)记I13a;b:87,87∈(84,125)记I13c
I14:a:37.3,37.3∈(0,42)记I14a;b:34.8,34.8∈(0,42)记I14a
I15:a:90.5,90.5∈(84,125)记I15c;b:115.9,115.9∈(84,125)记I15c
I16:a:95.2,95.2∈(84,125)记为I16c;b:88.4,88.4∈(84,125)记I16c
I17:a:40.5,40.5∈(0,42)记I17a;b:-34,34∈(0,42)记I17a
I18:a:36.6,36.6∈(0,42)记I18a;b:34.1,34.1∈(0,42)记I18a
I19:a:95.2,95.2∈(84,125)记为I19c;b:88.4,88.4∈(84,125)记I19c
I20:a:0.76,0.76∈(log21.5,log23)记I20b;b:0.79,0.79∈(log21.5,log23)记I20b
I22:a:12,记I2212;b:3,记I223
I23:a:1.92,1.92∈(log23,log250)记I21c;b:1.81,1.81∈(log23,log250)记I21c
I24:a:大于,记I24a;b:大于,记I24a
I25:a:1,记I251;b:1,记I251
I26:a:null,记I26φ;b:null,记I26φ
I27:a:2,记I272;b:1,记I271
2.5 FP-Growth应用
按照FP-Growth[17-18]算法步骤,依次将200幅测试集图像存入数据库D,构造FP树阶段:
扫描数据库D,获取1项频繁项目集L,并对L降序排列。
部分数据见表1。

表1 降序排列表 次
创建FP-tree树的根节点,记为“null”,按照获取的L中的排序,对每个事务进行插入FP-tree操作,从而完成FP-tree构建过程。
FP-Growth通过对FP-tree的搜索遍历,实现函数FP_Growth(FP_tree,null)的详细过程如下:
FP_Growth(FP_tree,α),α为条件基,初始为空。
if FP-tree含有单个路径为P
then{
for路径中节点的所有组合(记作β)
可以产生的模式是m=β∪α,支持度计数等于用β中节点最小支持度计数supmin=20,如果其超过最小阈值,将其输出到集合M={m0…mk},k表示个数
}
else{
for FP_tree的头表中每个αi{
产生模式β=αi∪α,αi的支持数为其支持数
然后,建立β的条件模式基,构造β的条件FP-treeβ;
ifFP-treeβ≠∅ then
FP_Growth(FP-treeβ,α)
}
对M={m0…mk}集合每个元素计算
conf(X→Y)=supp(X∪Y)/supp(X)=P(Y|X)
(24)
其中,Y:I251;X:条件模式基βk。
mk=βk∪I251
(25)
取阈值conf=70%
输出到集合H。
满足条件的项集见表2。
表2 满足条件的项集

频繁模式支持度置信度I2d、I7c、I15c、I24a、I251、I26φ480.83I2b、I24a、I251、I26φ360.89I2a、I24a、I251、I26φ320.88I2c、I24a、I251、I26φ320.88
按照以上规则:
(1)规则I2d、I7c、I15c、I24a、I251、I26φ,可以理解为:对图像结构比较复杂,背景不单一,不均匀,其I7、I15比值较高,表明目标区域在图像中有足够大小,图像中某种颜色集中在目标区域,I24a、I251说明目标区域显著熵密度大于平均,并在大于平均的分类中熵和最大。
(2)规则I2a、I24a、I251、I26φ理解为:对于结构为半包围的背景单一、均匀图像,目标区域显著熵密度大于平均,并在大于平均的分类中熵和最大。
(3)规则I2b、I24a、I251、I26φ理解为:对于结构为半包围的背景单一、均匀图像,目标区域显著熵密度大于平均,并在大于平均的分类中熵和最大。
(4)规则I2c、I24a、I251、I26φ理解为:对于结构为半包围的背景单一、均匀图像,目标区域显著熵密度大于平均,并在大于平均的分类中熵和最大。
根据上述频繁项集制定下述规则:
(1)若I2d、I15c成立,图像某一区域满足I7c、I24a、I251,则将该块区域作为目标区域;
(3)若I2a成立,图像某一区域满足I24a、I251,则将该块区域作为目标区域;
(3)若I2b成立,图像某一区域满足I24a、I251,则将该块区域作为目标区域;
(4)若I2c成立,图像某一区域满足I24a、I251,则将该块区域作为目标区域(关于I2的特征取值研究对象为ImageG)。
将上述规则应用到测试集上。
3 实验结果及其分析
算法在Matlab仿真实现,机器处理器为I3,RAM=2 G。
选取Corel数据库中花、牛、蝴蝶、车等20类形色各异的图像,每类20幅,共计400幅进行测试。其中图像(b)是通过人工的方法,把图像目标区域手工设置为1,将背景手工设置为0的二值图像。为了对比各算法的视觉效果,分别在改进的Itti视觉模型[19]、GBVS视觉模型[2]、谱剩余模型[3]得到的显著图基础上,将显著图像灰度区间由[0,1]按比例转换到[0,255],并将得到的图像进行如下变换:
S=255-S*
(26)
从而最终显著图是[0,255]区间的灰度图像,目标区域为黑色,区域越深表示显著度越高。结果图分别对应(e)、(f)、(g)。最终各类对比图如图2所示。

图2 效果对比图
通过观察效果图可知,图(c)方法效果整体显著优于其他方法。与图(d)的效果对比,表明改进方法较好地实现了区域选择的问题。为了定量对比各类算法的处理效果,参照文献[20]进行计算。
(1)计算图像Precision、Recall和F-measure(简单起见分别记为P,R,F)。
P=∑((1-S)×B)/∑(1-S)
(27)
R=∑((1-S)×B)/∑B
(28)
F=2×P×R/(P+R)
(29)
其中,S为各类算法生成的(0,255)灰度显著图按比例转换到(0,1)区间的显著图;B为人工分割图;∑代表所有像素点灰度值求和;(1-S)×B为两图像像素点值相乘得到的灰度图。
可以理解为F值越大,显著图显示目标效果越理想。各类算法通过计算数据库每幅图像的Precision、Recall、F-measure,统计并求平均值,具体结果见图3。
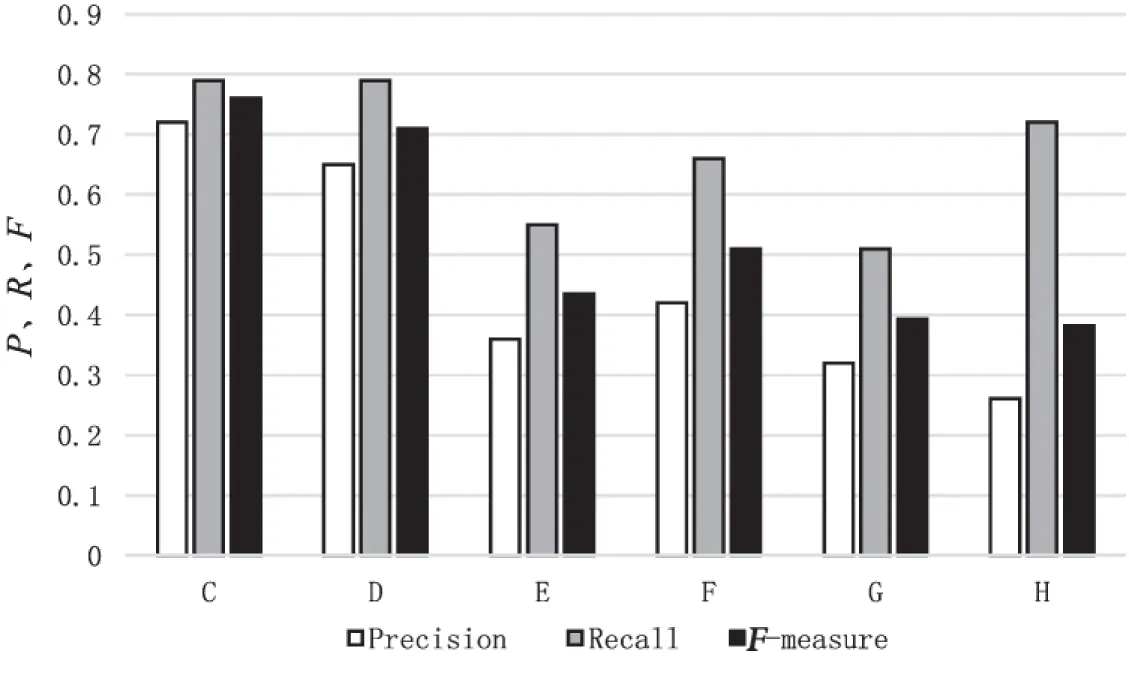
图3 结果对比图
4 结束语
为了解决图像背景较复杂时改进Stentiford方法提取图像多个非目标区域中存在的问题,提出了一种感兴趣区域提取方法。该方法从图像中提取一些新的特征和大量常见的特征,并应用FP-Growth算法数据挖掘特征与目标区域的关联规则。将得到的规则应用在测试集上,同时与多种经典的视觉模型方法分别进行定性和定量的对比实验。实验结果表明:该方法的视觉效果和性能数据指标都优于其他方法,实现了多区域中选取目标区域,提高图像提取准确度的目标。未来,可以提取更多的图像特征、增大数据库样本容量、细化相关数据指标分段来增加提取规则,研究具有广阔的前景。
[1] 黄传波,金 忠.基于视觉注意的彩色图像检索方法[J].光子学报,2011,40(7):1025-1030.
[2] 王 星,邵振峰.基于视觉显著点特征的遥感影像检索方法[J].测绘科学,2014,39(4):34-38.
[3] 尹春霞,徐 德,李成荣,等.基于显著图的SIFT特征检测与匹配[J].计算机工程,2012,38(16):189-191.
[4] Stentiford F W M. An estimator for visual attention through competitive novelty with application to image compression[C]//Picture coding symposium.[s.l.]:[s.n.],2001:1-4.
[5] Stentifold F W M.Automatic identification of interest with application to the quantification of DNA damage in cell[C]//Proceeding of SPIE.[s.l.]:[s.n.],2002:244-253.
[6] 陈文达,白瑞林,吉 峰,等.基于机器视觉的轴承防尘盖表面缺陷检测[J].计算机工程与应用,2014,50(6):250-254.
[7] Arasteh S,Hung C C.Color and texture image segmentation using uniform local binary patterns[J].International Journal of Machine Graphics & Vision,2006,15(3):265-274.
[8] Fehr J.Rotational invariant uniform local binary patterns for full 3D volume texture analysis[C]//Finnish signal processing symposium.[s.l.]:[s.n.],2007.
[9] Lahdenoja O,Poikonen J,Laiho M.Towards understanding the formation of uniform local binary patterns[J].Machine Vision,2013,2013:1-20.
[10] 钟 晓,马少平,张 钹,等.数据挖掘综述[J].模式识别与人工智能,2001,14(1):48-55.
[11] 王光宏,蒋 平.数据挖掘综述[J].同济大学学报:自然科学版,2004,32(2):246-252.
[12] 文 拯.关联规则算法的研究[D].长沙:中南大学,2009.
[13] 张 健.基于频繁模式挖掘的不良消息文本检测方法研究与实现[D].上海:复旦大学,2012.
[14] 李晓卿.数据流中闭频繁项集挖掘算法的研究[D].沈阳:东北大学,2009.
[15] 李仁泽.基于数据挖掘方法的综合症—药物关系挖掘[D].南京:南京大学,2013.
[16] 张少博,全书海,石 英,等.基于颜色矩的图像检索算法研究[J].计算机工程,2014,40(6):252-255.
[17] 彭佳红.一种新的多层关联规则算法[J].计算机工程,2006,32(9):70-71.
[18] 徐 龙.基于约束的最大频繁项目集挖掘算法与实现[D].西安:西安科技大学,2008.
[19] 宋 侃.基于改进视觉注意模型的显著区域区检测[J].计算机技术与发展,2015,25(7):234-236.
[20] 马儒宁,涂小坡,丁军娣,等.视觉显著性凸显目标的评价[J].自动化学报,2012,38(5):870-876.
Investigation on Extraction of Interests Region in Image
WANG Cheng,FAN Xiang-yang
(College of Telecommunications & Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Concerning extraction of Region Of Interest (ROI) for image,the enhanced Stentiford visual modeling method has the advantages of clear image regions,obvious edges,and high efficiency compared with traditional Stentiford or other visual modeling methods.However,when the image background is relatively complex,regions outside the target would be extracted.Because of requirements on accuracy in actual research,it is necessary to pick out target regions from extracted regions.For this reason,during image processing,an extraction method with multiple new image features has been proposed and the classic FP-Growth algorithm in data mining has been introduced.After the training set have been processed by the enhanced Stentiford visual modeling method,image features such as significant entropy and significant entropy density are extracted and the FP-Growth algorithm is employed to find the association rules between image features and target regions.The obtained rules have been applied to a lot of experimental for verifications.The experimental results show that after the enhanced method,the accuracy of the extracted image regions have been improved significantly which indicates its feasibility and effectiveness.
ROI;Stentiford visual model;FP-Growth algorithm;image features
2016-06-16
2016-09-29 网络出版时间:2017-06-05
国家自然科学基金资助项目(61071167)
王 诚(1970-),男,硕士,副教授,硕导,研究方向为数据挖掘、嵌入式技术;范向阳(1991-),男,硕士研究生,研究方向为图像处理与多媒体通信。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170605.1506.030.html
TP391
A
1673-629X(2017)08-0030-07
10.3969/j.issn.1673-629X.2017.08.007
猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40
中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48
北京航空航天大学学报(2022年6期)2022-07-02 02:00:02
高技术通讯(2021年3期)2021-06-09 06:57:48
电脑知识与技术(2018年35期)2018-02-27 13:29:44
自动化学报(2017年5期)2017-05-14 06:20:56
自动化学报(2017年11期)2017-04-04 02:52:44
光学精密工程(2016年1期)2016-11-07 09:01:59
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
电视技术(2014年11期)2014-12-02 02:43:28
