
电子资源海量访问行为的采集优化研究
2017-08-12 12:22:06宋惠莺姚思勤章民融
计算机应用与软件 2017年8期
宋惠莺 姚思勤 章民融
1(上海复旦光华信息科技股份有限公司 上海 200433) 2(上海市计算技术研究所 上海 200040)
电子资源海量访问行为的采集优化研究
宋惠莺1姚思勤1章民融2
1(上海复旦光华信息科技股份有限公司 上海 200433)2(上海市计算技术研究所 上海 200040)
随着电子资源在高校图书馆中的普及,复杂多样的电子资源数据给访问跟踪和数据挖掘带来了日益严峻的挑战。为了从海量的电子资源访问数据中更快和更好地进行行为分析和数据挖掘,基于复旦光华的ERU系统和其在复旦大学图书馆的历年运行结果,重点阐述了在海量数据采集分析中的各个优化步骤和手段,特别是原始数据清洗或过滤和数据库优化。通过介绍的优化方案,复旦大学现场实现了高性价比的采集分析方案。该方法不但可以应用在图书馆中电子资源,而且对其他的海量数据处理有着较好的借鉴性。
电子资源 用户信息行为 ERU 大学图书馆
0 引 言
近年来随着信息技术在图书馆中应用规模持续扩大,特别是电子资源访问的爆炸性增长,校园网传输的数字资源信息呈现总量剧增、种类繁杂、并发加大和突发性操作频繁等特征。面对如此大数据规模,对现有电子资源访问行为追踪系统提出了极高的要求。
如图1所示,国内各高校在2009年-2015年中,在电子资源方面的投入逐年提高。图中数量代表各校平均采购量。国内各高校的纸质资源采购已出现逐年下降趋势,而相应的电子资源采购金额在2015年已经和传统纸质采购基本持平。可以预计在未来的几年中,电子资源采购必然会超过传统纸质采购。

图1 电子资源于纸质书本采购量
而随着互联网的普及,人民阅读习惯的改变,对应的电子资源的访问量也在逐年增长。如图2所示,某高校电子资源的访问量呈几何级的增长。
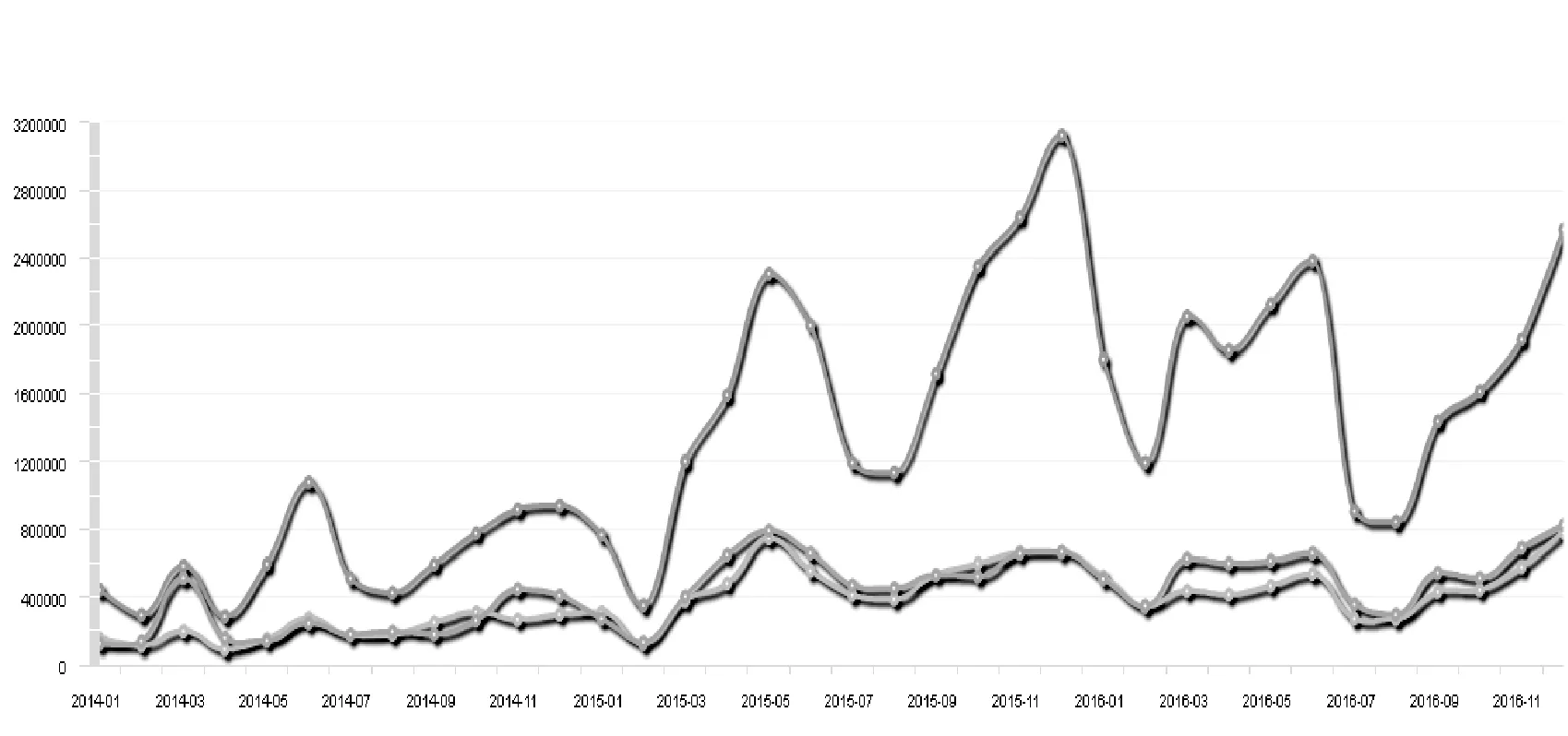
图2 高校电子资源访问量
随着访问量的逐年提高,原有的系统也需要进行更新,以应对更大的数据采集量后的处理,以备后期的统计和分析。
1 研究目的
通过网络中获取到访问电子资源的方式,是最为客观和准确的采集方式。但是由此带来的问题是,每个学校每天产生的网络数据达到T级,如果要从这海量的数据中精准获取到访问电子资源的数据,并且做到不遗漏以保证统计分析的准确性,是需要做大量的技术攻关研究的。本文采用大量的压力测试和集成测试,模拟海量数据流的测试方式,验证了几种优化手段集合使用的效果。
2 计算方式
本文以高校图书馆为例,阐述在校园网内电子资源访问的采集优化研究。
现有电子资源访问系统分为两类:旁路采集和集中代理两种方式。无论哪种方式,依靠单一高性能计算机不是一种可行的、性价比较好的方案。所以采用分布式计算方式将是一个效用可行的方案,并且保持良好的扩展性
ERU将数据采集处理分在两个计算单元:采集工控机和数据分析服务器上,采集工控机主要针对数据清洗和过滤,而数据分析服务器主要处理特征匹配。将电子资源采集处理中的高CPU消耗和高内存消耗放在了两个不同的计算单元中,提供了较好的整体系统效能。
3 硬件性能
对于海量数据的处理,硬件性能是个绕不开的问题。CPU的核数、单核主频、内存读写速度、内存大小、I/O总线背宽、磁盘读写速度都会成为制约大数据处理的瓶颈。但由于数据量的指数增加远远领先于硬件性能的更新和事实上的成本要求,所以追求较好性价比成为了唯一的选择。
由于图书馆用户访问行为大多以文本方式存在,所以应将性能提高的优先次序定为内存>高速I/O存储>CPU。
内存对于关系型数据库的影响超过任何其他硬件因素。保持一定的内存空余率是至关重要的,否则会进而严重影响I/O性能而造成系统性能急剧下降。当然要防止软件内存溢出、查询方式不好等引起内存不足问题。在文中会仔细阐述SQL查询的优化问题。
磁盘I/O实际上是数据处理上效率最慢的一环。所以在数据库设计的一开始,就必须考虑海量数据存储的结构问题。在数据量达到一定规模后,必须使用分区分表方式将数据分成若干个物理或逻辑块文件。用稍微提升软件复杂度的方法,减少索引存放空间和磁盘频繁访问次数。
系统中总有一些性能敏感模块,不能完全使用多进程或者多线程方法进行优化。这时候适当提高CPU主频是一个简单方法。
4 多级过滤
电子资源访问处理过程中的最大数据量是来自于网络背景,其中还有大量“脏数据”[1]。主要是无关行为分析和信息提取的无用背景。基于现有软硬件条件下,不做清理直接进行特征值提取是件不可能完成的任务。所以依据一般大数据处理流程,先进行数据清洗或过滤,也称之为“数据预处理”[3]。数据量级降低通常是最佳优化的第一步。
4.1 过滤模型
为了提高数据库cache基于电子资源的访问特性,将数据过滤分成多级,每一级大量过滤无用信息,最后达到数量级大幅度下降。ERU实施六级过滤,然后将结果提供给后端分析具体访问行为。
ERU六级过滤逻辑如图3所示。

图3 ERU的多级过滤
通过对数据包的层层过滤,一来可以降低对硬件的性能消耗,二来对不同层的数据流可以扩展解析能力。
(1) 协议过滤
通常学校网络背景都还有多种协议,例如TCP、UDP、ARP、ICMP等基础协议。而电子资源访问基本上都是基于HTTP或HTTPS协议,所以一般只需分析TCP即可。从实际情况来说,UDP通信包占整个背景相当大比例,所以去除UDP等其他协议是优化的第一步。
(2) IP过滤
经过协议过滤后,背景中虽然只含有TCP包,但确包含了访问所有各类网站的背景和某些应用内部通信包。去除这些无用内容的最简单的方法是进行IP筛选。先获取一份需要跟踪的电子资源网站归属的IP列表,然后根据这张列表筛选出有意义的内容背景。这里需要注意的是有些网站采用多镜像存放,根据客户端的路由情况动态分配镜像。这种情况需要获取IP列表时遍历所有的镜像IP地址。
(3) 端口过滤
电子资源纷繁复杂,有国际有名的大平台,也有只服务于特殊领域的小网站。这些电子资源的提供商所采用的网站技术千奇百怪,有些网站会采用特殊端口,或者不同端口代表不同的网站内容,所以非电子资源相关的数据端口背景是无用的,因此必须在IP过滤后加入端口过滤。
同时进行端口过滤也是排除某些网站TCP内部通信包,而这些内部通信包有可能占整个网站流量的大多数。
(4) 域名过滤
现在大多数电子资源平台,除了一些自己构建网站资源存储,大多都是托管在IDC(Internet Data Center 互联网数据中心)上。现今为了加速跨地域访问速度的问题,许多IDC提供了CDN服务。 CDN全称为Content Delivery Network,即内容分发网络。通过代理缓冲大大减轻服务器的压力。但同时大型IDC使用同一个IP池来服务不同内容商成为常态。举个例子:IDC有一个IP,周一代表是ACS资源网站,周三变成微软补丁地址,而下周又变成苹果广告内容。为了应对上述情况,ERU在IP和端口过滤后,特别加入了域名,来屏蔽这类问题。主要是侦测HTTP包头中HOST来判断内容的归属。
(5) 类型过滤
一般网站背景是有HTML、XML、JS、GIF/JPG/PNG、JSON等类型数据构成,其中电子资源下载还牵涉了一些特殊的内容类型。从行为分析的角度出发,并不是所有内容类型都是必要的。
一般意义上,图片文件(包括JPG、GIF、PNG)都是与行为无关。当然不排除有些多媒体资源网站以图片作为行为依据。当然还有些网站会自动生成文献首页图片做预览,给行为分析带来难度。
进行类型过滤的另外一个原因是关于下载行为。下载行为在所有行为总数内并不占多数,但其占据的流量有时却占大多数。下载本身的内容体对行为判定无意义,而且全部内容体又有隐含的版权问题。因此对于这类背景只需分析整个会话开始部分即可。而且这样还可以节省原始数据储存大小。
(6) 特征值预过滤
最后经过以上步骤过滤后的背景还是包含了和行为判断无关的内容,例如首页。ERU有一套较为完善的特征值模板库,利用该库进行再次过滤,结果背景就基本和行为直接相关。
4.2 多级过滤的实验结果
ERU采用以上多级过滤后,其数据量急剧下降2个数量等级,如图4所示。某大学超过5 TB的日背景数据缩减到1.2 GB(压缩后)有效行为相关背景。

图4 多级过滤数据量对比
再对六级过滤进行优化率比较,发现六级过滤中以IP过滤、类型过滤和特征值过滤最为有效。其主要原因是:① 学校背景不管是否经过分流器过滤,但是由于网络设备的过滤局限,结果中还是含有大量的无关IP数据;② 一般HTTP访问都是图形化和交互化的,所以背景中有大量的图片、脚本;③ 图书馆主要关注访问各电子资源平台的行为,其下载行为中主要以PDF或其他文本存储格式为主。而行为分析中一般不分析PDF内部内容,所以只需提取一部分文件头信息即可。由于各级数据的多样性,造成每级过滤效率不同,见图5效率对比。
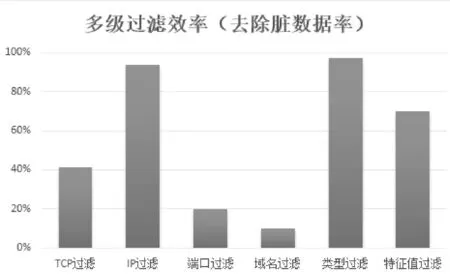
图5 多级过滤效率对比
当然以上分析并不代表TCP过滤、端口过滤、域名过滤不重要,实际上过滤的每一步都是依赖上一步过滤的结果,多级过滤的最终目标一直是减少无效数据的数据处理量。
5 数据库优化
5.1 调整数据库内存配置
为了提高数据库cache中的命中率,配置适当的内存是数据库优化的首要条件。关系型数据库在服务器内存分配占首要地位,应于优先满足。否则数据库查询重复命中率较低,从而造成I/O瓶颈,进而导致操作系统页交换频繁,最后系统进入类似假死状态。
5.2 调整数据设计
首先我们应该了解一下存储的特性,一般意义上的存储是指掉电不丢失数据的电子设备。长久以来计算机主要采用磁介质作为存储,但现今的采用FLASH芯片或DRAM芯片的固态硬盘或U盘都已不采用磁介质,但本文以磁盘为上述固定存储的统称。
磁盘分为机械磁盘、固态硬盘和磁盘阵列。一般机械磁盘速度为50~200 Mbit/s,固态硬盘可达到768 Mbit/s(背带6 Gbit/s)。而磁盘阵列则依靠阵列卡同时读写多个磁盘,从而达到背带10~20 Gbit/s或以上。
磁盘读写的速度是不一样的,一般上面提到的理论速度都是指读取速度,而写入速度通常只有读取速度的一半甚至四分之一。
另外磁盘速度分顺序读写和随机读写,以上的读写速度都是建立在顺序读写上。如果是随机读写,速度有可能下降到原有的十分之一。
虽然内存具有读写速度快(是磁盘的30~50倍)、读和写速度差距小和随机读写速度快的特点,但内存是掉电丢失数据的介质,而且成本相比磁盘过高,不可能无限制采用内存。
(1) 避免高频磁盘读写
磁盘I/O是整个处理过程中的速度瓶颈,就算是采用磁盘阵列在应付大数据时依然如此。由于现有数据存储硬件上一般使用磁盘控制卡(阵列卡)控制,而实际系统实施上一般软件并不直接控制访问某个磁盘或磁盘阵列,所以本文不将调整I/O硬件访问[5]作为重点。从软件上说,避免对磁盘的高频读写则成为优化的重点方向。由于现有磁盘速度远落后于内存,同时存在着读写速度差距大的缺点,在必须采用高速数据缓冲的地方,应尽量避免使用磁盘,而改用内存作为缓冲。
(2) 数据尽量压缩存放
在图书馆电子资源访问的原始背景避不开海量的大数据块存放。如果按原样存放,不但需要非常大的存储磁盘,而且读写需要的时间较长。ERU采用压缩存放,从而避免不必要的大量磁盘读写。当然这种方案对CPU有一定要求,但在如此海量的数据中,这点代价完全可以接受。
以ERU在复旦大学实施结果来看,2015年开始采用数据压缩存放,相比2014的非压缩存放,节省了近百分之六十的空间。如果再算上复旦大学2015年新增的14个电子资源平台的话,数据存储的节省更加明显。见图6,在优化前后的存储量对比。
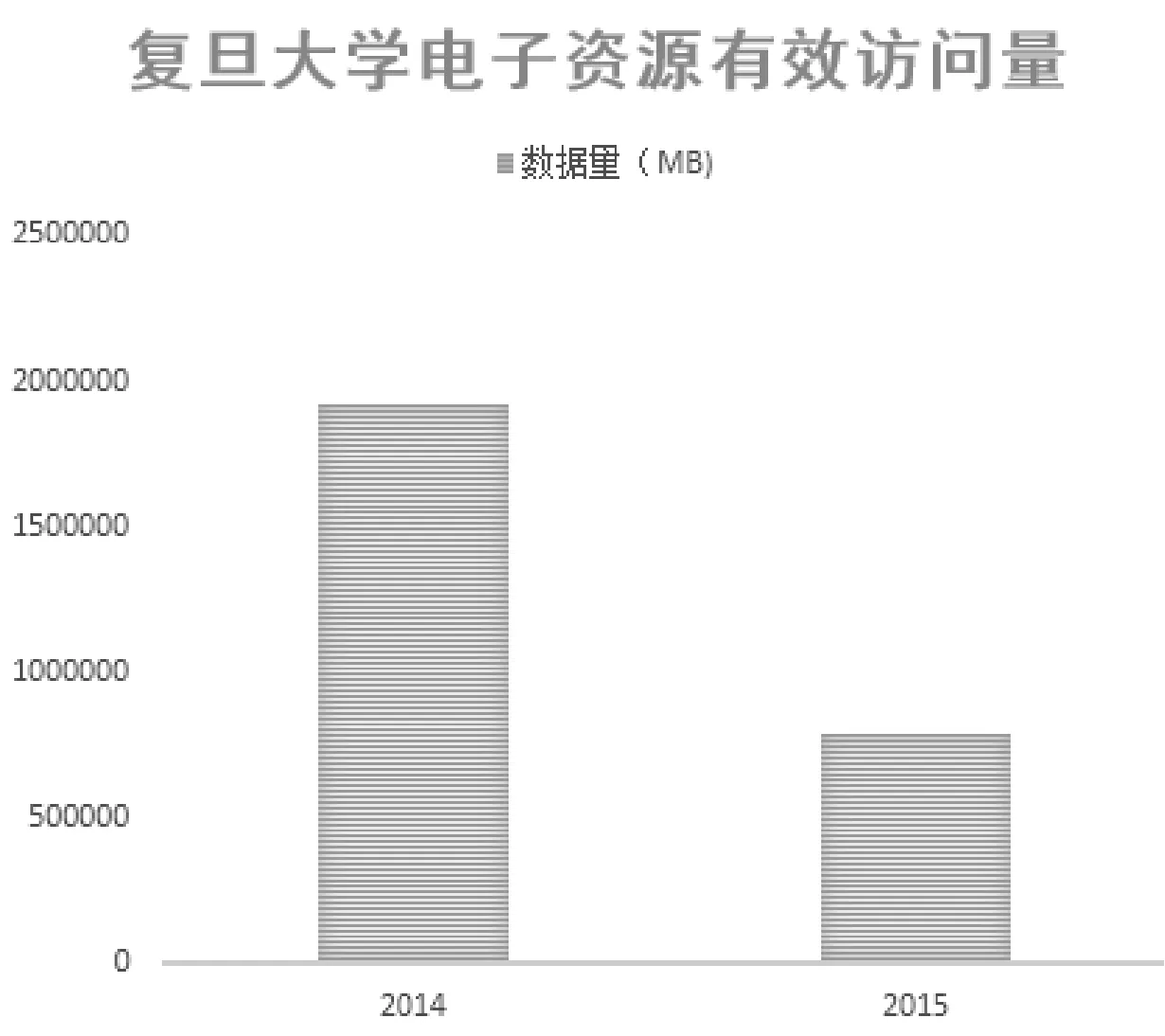
图6 优化前后存储量比较
同时数据压缩后容量变小,也可以从另一方面加速数据的读取速度,从而帮助总体行为分析的效率。
(3) 正确使用索引
索引是加快数据库查询的好方法,但是同时如果数据过多索引本身也会成为瓶颈。不应过多地建立索引,特别应谨慎考虑单字段索引和复合索引的组合,力求精简有效。
(4) 分区分表
图书馆电子资源访问的数据大多是行式数据,如果不加处理入表,一方面大大增加索引的负荷,而且将来索引的读取也会成为数据读取的一个限制;另一方面造成操作系统中文件系统处理过大、过多文件的困扰。
对于一般的关系型数据库,海量行数的存放应采用分区分表,使之存放到不同有限的物理文件中。一方面使读写效率不受文件系统的制约;同时另一方面可以优化索引,不至于由于数据过多时索引拖累效率的问题。
以复旦大学现场五千万条数据查询为例,简单查询速度从分钟级降到了秒级。见图7,优化前后,访问速度发生了显著的提高,大幅度改善了用户的使用感受。
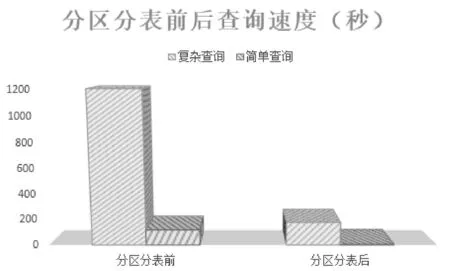
图7 优化前后的查询速度对比
5.3 优化SQL语句
(1) 谨慎使用嵌套查询
嵌套查询牵涉了多个查询。但如果主查询和子查询有相关联的字段,例如主查询的字段值变化会引起子查询重新执行,这样就不是一个好的查询语句。应尽量避免这种情况。
(2) 尽量避免通配符匹配
通配符查询不能直接使用索引进行查询。以SQL Server为例,只能采用Full-Text Filter Daemon Launcher进行全文搜索优化,其效率远远不及索引的效率。
(3) 减少全表查询
一般全表查询或者锁表操作都会降低系统效率,有时需要数十分钟才能完成。例如不带条件的直接查询实际上如无必要,尽量慎用。
(4) 合理使用临时表
有时使用临时表,可以加快多表复杂查询,特别是那些类似查询的相同中间数据。
(5) 合理使用视图
在单表查询中,可以考虑使用视图。利用数据库后台事务并行完成查询。
5.4 优化数据录入
通常的数据入库SQL命令(INSERT)在海量数据入库中基本力不从心。一般的方法是将命令变成存储过程,以事务方式执行,可以获得十几倍提升的效率。当然在某些特殊情况下可能有更好的办法。例如微软提供CSharp处理SQL Servers的入库上的特别函数可以到达数十倍到上百倍的提升。
6 结 语
优化电子资源数据处理是一个系统工程,牵涉到软硬件、数据设计、应用编写、流程改进等方面。本质上电子资源处理是一种大规模文本数据处理,过滤和压缩是优化处理的核心。当然其中有些优化方向都是互相制约的,整个优化过程中只能在平衡原则上达到折中,获取整个系统的高效率。
本研究,从计算机硬件、计算机软件、数据库三方面同时进行性能调优,日处理量可达10 TB,基本满足全国所有高校的吞吐量,而该应用也在清华大学、北京大学、复旦大学、上海交通大学、南京大学、东南大学、四川大学等高校部署使用。
[1] Hernández M A,Stolfo S J.Real-world data is dirty:data cleaning and the merge/purge problem[J].Data Mining and Knowledge Discovery,1998,2(1):9-37.
[2] 陈世敏.大数据分析与高速数据更新[J].计算机研究与发展,2015(2):333-342.
[3] 米允龙,米春桥,刘文奇.海量数据挖掘过程相关技术研究进展[J].计算机科学与探索,2015(6):641-659.
[4] 程学旗,靳小龙,王元卓,等.大数据系统和分析技术综述[J].软件学报,2014(9):1889-1908.
[5] 李动周.大型关系型数据库优化探讨[J].办公自动化,2007(2):32-34.
[6] 岑巍.数据库优化在海量数据下的研究与应用[J].计算机时代,2015(2):33-35.
[7] 李振国,郑惠中.网络流量采集方法研究综述[J].吉林大学学报(信息科学版),2014(1):70-75.
[8] 袁梅宇.高效率多线程网络流量采集算法研究及实践[J].昆明理工大学学报(理工版),2006(1):32-36.
[9] 王冬梅,张素青,王硕.IP城域网网络安全分析及流量过滤技术[J].信息通信,2014(10):253-254.
[10] 窦衍旭.高速网络流量内容还原系统的设计与实现[D].兰州大学,2014:1-65.
OPTIMIZATIONONTHEUSERBEHAVIORSINFORMATIONACQUISITIONOFMASSELECTRONICRESOURCES
Song Huiying1Yao Siqin1Zhang Minrong2
1(FudanGrandHorizonInformationTechnologyCo.,Ltd.,Shanghai200433,China)2(ShanghaiInstituteofComputingTechology,Shanghai200040,China)
During electric resources become more popular in university libraries, the behavior of accessing electric resources is too complex and diversified for analysis and data mining, facing increasingly severe challenges. In order to optimize the access to mass electronic resources, we present the optimization solutions at all steps of collecting the electric resource behaviors in library, based on ERU system and Fudan university library, especially cleaning up raw data and optimize current database. As a result of deploying ERU at Fudan university library, those huge raw data are processing very well at a good cost performance. This resolution could not only apply to electric resource at the school library, but also apply to deal with other areas huge data.
E-resources User information behaviour ERU Library of university
2017-03-06。宋惠莺,工程师,主研领域:计算机软件,信息安全,数据库,大数据分析挖掘。姚思勤,本科。章民融,教授级高工。
TP3
A
10.3969/j.issn.1000-386x.2017.08.058
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
电脑爱好者(2019年2期)2019-10-30 03:45:31
当代陕西(2019年14期)2019-08-26 09:42:00
当代陕西(2019年13期)2019-08-20 03:54:22
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
测绘科学与工程(2014年5期)2014-02-27 07:06:14
测绘科学与工程(2014年2期)2014-02-27 07:05:49
