
基于深度特征K-平均字典的场景识别*
2017-08-09 01:34余良琨黄立勤
网络安全与数据管理 2017年13期
余良琨,黄立勤
(福州大学 物理与信息工程学院,福建 福州 350000)
基于深度特征K-平均字典的场景识别*
余良琨,黄立勤
(福州大学 物理与信息工程学院,福建 福州 350000)
计算机视觉中的中级词袋模型广泛采用滑动窗口作为图片的分割方法。然而由滑动窗口产生的图块充满随机性,部分图块并没有明显的语义含义,会给后续的聚类带来困难。针对这个问题,提出采用似物检测取代滑动窗口。同时,根据词袋模型字典设计中关于字典词区别性和代表性的思路,对K-平均算法进行了改进,并在MIT-67室内场景数据库中进行了测试,该方法取得了良好的效果,最好的结果为76.31。
场景识别;K-平均算法;深度学习;词袋模型;似物检测
0 引言
场景分类早已作为计算机视觉中的一项特别工作有着自己独到的处理。不同于一般的在图片中检测或识别一项典型的物体,诸如行人检测和人脸识别,场景分类注重于理解高级的语义信息,如旅馆、海滩。这些信息往往并不能由图片中的某个物体或某块场景单独决定,而是由多个物体和多个图块的联合关系来表征。应用场景分类的知识能够帮助解决很多计算机视觉其他领域的问题,包括语义标记[1]、事件监测[2-3],以及图片信息获取[4]。
对于场景识别而言,图片的特征描述方式起着十分关键的作用。在早期的工作中[5],图片的描述是基于边缘检测或者是角点检测的局部特征。然而,这类的局部特征描述往往缺乏必要的语义信息而且缺乏鲁棒性。因此,这种特征无法良好地表达整幅图片的信息;用于分类时,这样的数据往往表达含糊。而且,采用这种特征描述时,所有的图块都具有相同的权重。然而事实上,在许多案例中,图片中往往有许多的图块对最终的场景分类并没有任何的贡献,就比如室内场景中的白墙图块,几乎会出现在所有的室内场景中。参考文献[6]提出了使用物体检测算法监测到的物体作为场景特征来表征场景。这是一个十分有效的场景描述方式。然而,在实际中,有太多种类的物体需要手工标记并且去训练各自的物体检测算法。这无疑会给人们带来沉重的手工劳动。为了平衡这种块描述的优异特性与沉重手工标记之间的矛盾,研究者们提出了基于区域特征的描述[7],然后,再将词袋模型(BoW)应用于各种归一化后的区域特征[8-9]。这样,给定的图片就可以表示为这些视觉词分布的统计,而且,视觉上相似的图片也会有着相似的特征词分布。尽管基于图块的BoW方法图片特征描述相比于基于像素点的低级特征图像描述要丰富得多,并且相较于使用单独物体检测作为场景特征的方法更有效,但是它仍然面临一些图块对于场景最终分类无意义的问题。
从以上的回顾中不难发现,选择合适的图块/区并用这些基本元素来构建图片的表达是非常重要的一环。同样,对于BoW模型而言,还需要一个能够良好构建视觉字典的方法。Singh[10]提出好的视觉词典应该能够在刻画不同类时有足够的区分度,刻画相同类时又要能够充分表达,又可称之为图块的区别性和代表性。Juneja[11]提出了使用熵-排序的方法来选取有用的图块。最近,一些学者都将场景图片用滑动窗口分割成多个图块[9,12],然后将图块通过预先训练好的Caffe深度学习中的VGG-VD模型[13],并在全连接层的第一层取出4 096维的非负特征再进行后续的字典构建的处理。最后进行支持向量机(Support Vector Machine,SVM)分类。尽管这些方法提出了不同的图块或是视觉词的聚类选取方式,但在最初的步骤中却仍是依赖于一种毫无目的性的图片分割方式。通过一定间隔相互叠加的滑动窗口或者是基于空间金字塔模型(Spatial Pyramid Model,SPM)的层级式的分割。本文提出采用似物检测(Object Proposal)的方式进行场景图片分割。似物检测方法已经广泛地用于物体检测、目标定位、目标跟踪,可以用于发现潜在的物体区域,即能够有效地发现可能是物体的图块,从而在最开始的图片分割中就能够准确地发现可以更好表达场景含义的区域。
本文通过结合新的图片似物检测的分割方式和基于物体描述的鲁棒的深度卷积神经网络(Deep Convolution Neural Networks,DCNN)特征来解决场景分类中的问题。这种结合可以提升最初场景图片分割步骤中图块的语义信息的明确性。如果这个步骤中各个图块没有明确的语义信息,无疑会给后续的字典聚类带来很大的含糊性。受文献[9]的启发,每个似物检测分割出来的图片都采用DCNN进行特征提取,保证了高质量的特征。同时根据Singh关于聚类区别性和代表性的思路,本文提出了K-平均法(K-Means)的聚类选取方式。因此本文的主要贡献:(1)通过结合具有语义分割方式和特征表达丰富的DCNN图块描述方式,提出了一种新型的场景图片的描述方式;(2)提出了一种同时具有同类代表性和类间区别性的K-Means聚类字典产生方式,生成了更加具有区别度的视觉字典。
1 相关工作
1.1 似物检测
似物检测是用基于边界框或者是图块分割的方式生成与类别无关的潜在物体区域的方法。每个边界框或是图块都包含着可能的物体对象。在最早的图块物体属性的研究中,每个图片框都是被一系列特征进行联合表达的。这些特征会被送入训练好的,诸如朴素贝叶斯分类器[14]或是线性SVM分类器[15]来判别该区域是否是一个物体区域。为了更好地定位具有物体属性的区域,Ristin[16]等人证明了随机抽样的局部区块可以提供上下文信息以估计物体位置的先验分布。还有另一种方式是通过合并输入图像经过过分割产生的超像素。本文选用了似物检测中的选择性搜索(Selective Search)[17]方法来实现场景图片分割。选择性搜索结合了穷举搜索和物体分割的特点。图像本质上是分层的,并且各个区域形成物体存在各种各样的原因。因此,单个自下而上分组算法不能捕获所有可能的物体位置。为了解决这个问题,选择性搜索使用一组不同的完备且分层分组策略。这使得选择性搜索能够稳定、鲁棒,并且独立于对象类进行似物检测。
1.2 K-Means
K-Means是一种聚类算法。其目的是将一组向量分成围绕公共均值向量聚集的K组。组内的数据表达都可以近似为该组公共均值,因此聚类过程也就是寻找能够最佳量化这些数据的建立字典或者是码表的过程。
已知观测集{x1,xn,…,xn},其中每个观测都是一个d维实向量,K-Means聚类要把这n个观测划分到k个集合中(k≤n),使得组内平方和(Within-Cluster Sum of Squares, WCSS)最小。换句话说,它的目标是找到使得下式满足的聚类Si:
(1)
其中μi是Si中所有点的均值。
2 算法流程
本文算法中主要的3个部分是:似物检测;K-Means聚类并选取生成字典;场景图片表达。如图1所示。

图1 算法流程图
2.1 似物检测
不同于之前工作中采用的滑动窗口,本文采用了似物检测中的选择性搜索。由选择性搜索产生的图块因为原方法中注重物体属性的选取,而使其相比于滑动窗口在语义信息上的表达更加明确。采用选择性搜索还带来了另一个优点,可以很明确地限制图块的数量,这样无疑可以减少后续处理的复杂度。当使用滑动窗口时,因为给定的图片的长宽比例不一,却又有着相同的图块分割大小、步进,因此每个图片可能产生不同数量的图块。例如,假定从给定图片的短边可以提取出5个图块,长边按比例采样,则可能产生5×6、5×7、5×8的图块数量。因此每个图片的图块数根据图片自身的长宽比例而不定。如果采用了选择性搜索,则可以避免这个问题。选择性搜索固定每个图片产生的图块。这样不但避免了后续处理的复杂性,而且保证了每幅图片对于K-Means聚类时具有相同的权重。
2.2 K-Means字典生成
2.2.1 K-Means聚类
将选择性搜索得到的图块,输入caffe深度网络的VGG-VD模型,该模型在ImageNet[18]进行了预训练并在ILSVRC-2014[19]上取得了极好的效果。接着在线性修正单元(Rectified Linear Unit,ReLU)的第六层fc6(全连接层的第一层)获得非负4 096维度的深度特征,然后将这些特征进行K-Means聚类。
2.2.2 选取聚类结果生成字典
字典视觉词希望能够同时满足两个要求,即区别性和代表性。区别性能够准确地分别不同类别。代表性又希望该词有足够的出现频率。普通的K-Means聚类可以直接构建字典,但是无法实现这两个要求,因此要加入这个步骤构建更加有效的视觉字典。
聚类的结果中也往往存在对各个类的偏向。即某个聚类结果中,大多数样本都是来自同一个类中的图块。因此这个聚类中心点就具有与别的类中图块深度特征的区别性。同时,定义同一聚类结果中满足一定的同一场景的个数要求的样本量,才可以视为对该场景具有代表性的字典词。先限制聚类的代表性,再考虑聚类的区别性,最后排序取出前X个作为各类的字典数。
2.3 场景图片表达
在这个环节中,需考虑如何有效地进行图片表达。给定单张场景图片l,通过选择性搜索产生G个图块和深度特征,将其表达为li={l1,l2,…,lG},作为矩阵H。此时H的表达具有G行,4 096列。通过K-Means聚类生成T个聚类空间/词,并且在聚类选择环节每类选择了最具有区别性和代表性的X个词。字典最终可以表示为矩阵M的形式,具有X×Y行(X是每一类场景的字典数,Y是数据库的场景数)和4 096列。将原始表达矩阵H向字典空间M投射,其结果是最终表达矩阵K=H×MT。此时,矩阵K具有G行,X×Y列。为了最后分类的方便,这个环节还会在矩阵K的行上采用最大值池化(max pooling)的方式降低维度,因此最后的表达维度为X×Y。
3 实验
在MIT Indoor-67[20]数据库上测试算法。MIT Indoor-67包含了67类的室内场景。其中一个显著的特点是:独特的物体往往会出现在特定的场景中。每类场景图片都包含大致80张训练图片和20张测试图片。最终,MIT Indoor-67的平均分类准确率将作为算法评价标准。
给定一幅图片后,将用选择性搜索来获取前36个最具有物体属性的图块,然后将这些图块调整到224×224的尺寸大小来适应使用VGG-VD模型的Caffe的输入要求。之所以选择36个图块是为了与大致相同数量的滑动窗口图块数的方法进行对比,同时测试了选择性搜索产生32个图块的情形。在K-Means的聚类中生成1 000个聚类区域,并在此基础上进行聚类结果的筛选。先甄选聚类区域的代表性,满足每聚类区域平均个数两倍以上的认定为具有代表性的区域。实际实验中共有192 960个图块、1 000个聚类区域,即,如果聚类区域A中超过386个样本来自B类场景图片,则认定该聚类区域A具有B类的代表性。再对满足代表性聚类区域的区别性进行排序,即按照各聚类区域中B类样本所占比例进行排序。选取前X个聚类中心作为B类场景的字典。试验中分别进行了每类20、40、60个字典词的测试。以32个选择性搜索图块+K-Means每类40字典为例。单一图片最终表达的维度为40×67=2 680。最后,采用了一个5折的一对多的SVM分类器进行分类。
4 结论
表1为算法准确率的比较。从表1中不难发现,不同数量的选择性搜索的效果均好于滑动窗口,36个选择性搜索图块好于32个的。同时也可发现,采用了K-Means字典的与没有采用字典的具有显著差异。其中最好的结果出现在36个选择性搜索窗口和每类40个K-Means字典组合中,其结果为76.31。
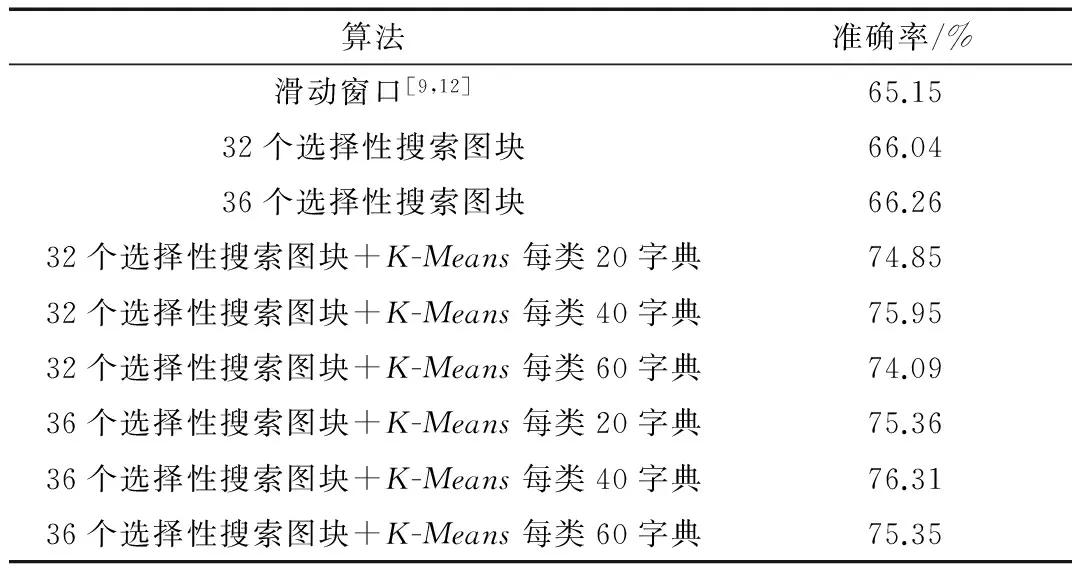
表1 算法准确率比较
注:前三行数据是将深度特征直接经图片表达,SVM分类得到。
因此,可以认为在场景识别中,选择性搜索相比于滑动窗口更适用于场景图片分割。同时具有代表性和区别性的K-Means字典能够使得场景图片的表达在线性空间中更加具有区分度。
[1] BOIX X, GONFAUS J M, VAN DE WEIJER J, et al. Harmony potentials [J]. International Journal of Computer Vision, 2012, 96(1): 83-102.
[2] MANDUCHI R, CASTANO A, TALUKDER A, et al. Obstacle detection and terrain classification for autonomous off-road navigation [J]. Autonomous Robots, 2005, 18(1): 81-102.
[3] Yao Bangpeng, Li Feifei. Modeling mutual context of object and human pose in human-object interaction activities[C]. Proceedings of the Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, 2010: 17-24.
[4] BERRETTI S, BIMBO A D, VICARIO E. Efficient matching and indexing of graph models in content-based retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(10): 1089-1105.
[5] RUSSELL B C, FREEMAN W T, EFROS A A, et al. Using multiple segmentations to discover objects and their extent in image collections[C]. Proceedings of the Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on, 2006: 1605-1614.
[6] LI L J, SU H, XING E P, et al. Object bank: a high-level image representation for scene classification & semantic feature sparsification[C]. Proceedings of the Advances in Neural Information Processing Systems, 2010: 1378-1386.
[7] LI F F, PERONA P. A bayesian hierarchical model for learning natural scene categories[C]. Proceedings of the Computer Vision and Pattern Recognition, 2005 IEEE Computer Society Conference on, 2005: 524-531.
[8] FERNANDO B, FROMONT E, TUYTELAARS T. Mining mid-level features for image classification [J]. International Journal of Computer Vision, 2014, 108(3): 186-203.
[9] LI Y, LIU L, SHEN C, et al. Mid-level deep pattern mining[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 971-980.
[10] SINGH S, GUPTA A, EFROS A A. Unsupervised discovery of mid-level discriminative patches [M]. Computer Vision-ECCV 2012. Springer, 2012: 73-86.
[11] JUNEJA M, VEDALDI A, JAWAHAR C, et al. Blocks that shout: distinctive parts for scene classification[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013: 923-930.
[12] GONG Y, WANG L, GUO R, et al. Multi-scale orderless pooling of deep convolutional activation features[C]. Proceedings of the European Conference on Computer Vision, 2014: 392-407.
[13] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. Computer Science, 2004.
[14] ALEXE B, DESELAERS T, FERRARI V. What is an object?[C]. Proceedings of the Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, 2010.
[15] CHENG M M, ZHANG Z, LIN W Y, et al. Bing: Binarized normed gradients for objectness estimation at 300 fps[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014.
[16] RISTIN M, GALL J, VAN GOOL L. Local context priors for object proposal generation[C]. Proceedings of the Asian Conference on Computer Vision, 2012.
[17] UIJLINGS J R, VAN DE SANDE K E, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-71.
[18] SHRIVASTAVA A, MALISIEWICZ T, GUPTA A, et al. Data-driven visual similarity for cross-domain image matching[C]. Proceedings of the ACM Transactions on Graphics (TOG), 2011.
[19] RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge [J]. International Journal of Computer Vision, 2015, 115(3): 211-252.
[20] QUATTONI A, TORRALBA A. Recognizing indoor scenes[C]. Proceedings of the Computer Vision and Pattern Recognition, 2009 IEEE Conference on, 2009.
Scene classification based on deep feature K-Means dictionary
Yu Liangkun, Huang Liqin
(School of Physics and Information Engineering, Fuzhou University, Fuzhou 350000, China)
Sliding window is a very popular segmentation method for mid-level Bag-of-Word (BoW) model, which is used widely in scene recognition. However, the patches produced by sliding window is full of randomness, some of them do not have clear semantic information, that may bring difficulties to subsequent clustering. To deal with it, object proposal is adopted to replace sliding window. At the same time, based on the idea of discriminativeness and representativeness of dictionary of BoW, K-means is improved and tested in MIT-67 indoor scenes dataset. The method gets best result of 76.31.
scene classification; K-Means; deep learning; Bag-of-Word; object proposal
国家自然科学基金(61471124,61473090)
TP391.4
A
10.19358/j.issn.1674- 7720.2017.13.009
余良琨,黄立勤.基于深度特征K-平均字典的场景识别[J].微型机与应用,2017,36(13):26-28,33.
2017-02-09)
余良琨(1992-),男,硕士研究生,主要研究方向:计算机视觉、场景分类。
黄立勤(1973-),男,博士,教授,主要研究方向:图像处理与通信、计算机网络通信。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
第一财经(2019年8期)2019-08-26
小学阅读指南·低年级版(2019年11期)2019-07-01
中南民族大学学报(自然科学版)(2019年1期)2019-04-04
小天使·一年级语数英综合(2017年11期)2017-12-05
雷达学报(2017年6期)2017-03-26
读者(2016年14期)2016-06-29
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
安徽医科大学学报(2015年9期)2015-12-16
