
基于计量经济学模型的武汉市汽车保有量预测
2017-08-08 22:07王明锐
汽车科技 2017年4期
王明锐

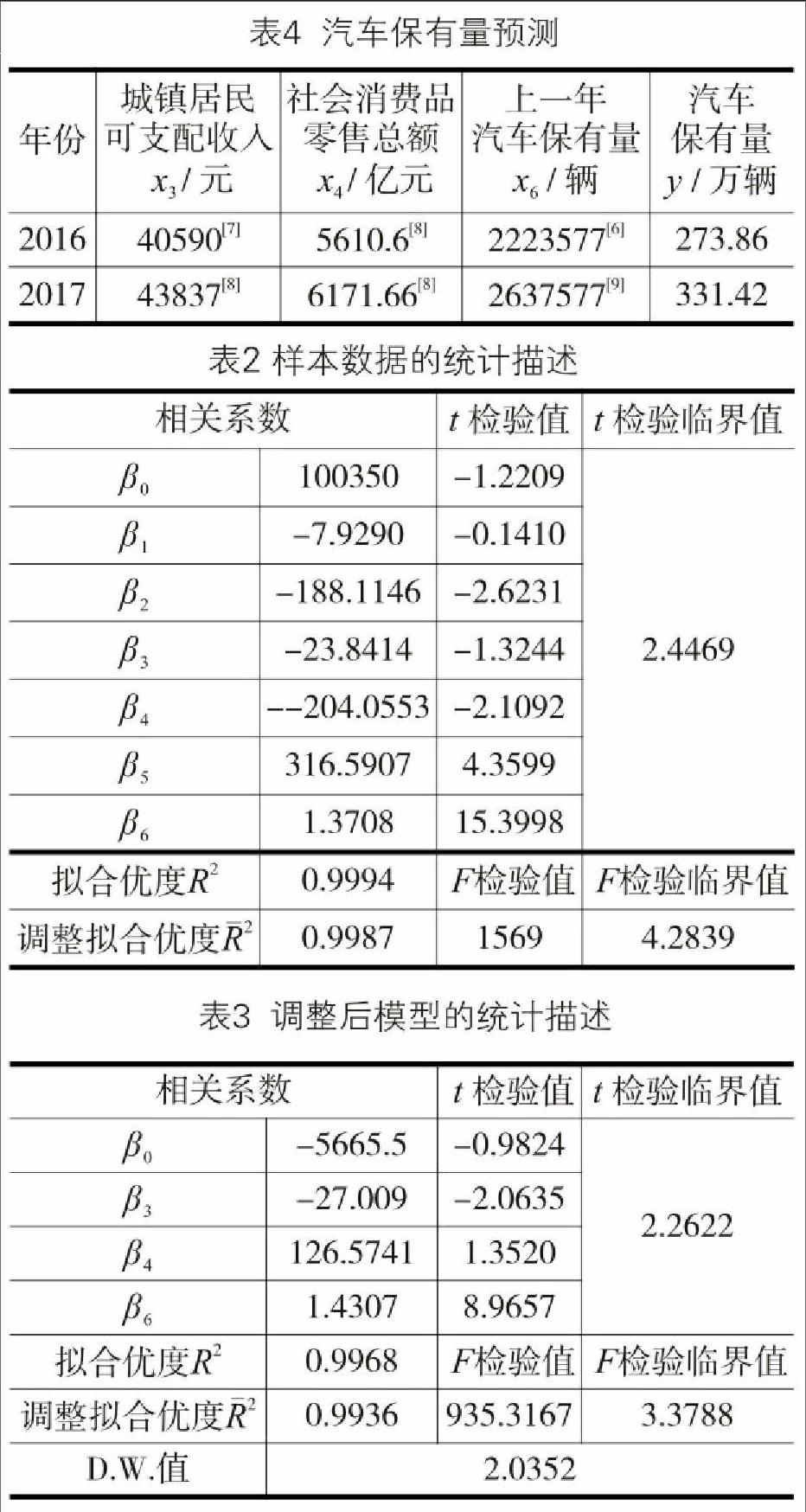
摘 要:本文根据武汉市统计数据,应用计量经济学方法,建立了汽车保有量预测模型,模型特别将上一年汽车保有量作为表征消费者购车心理的变量纳入了分析。通过MATLAB软件计算出回归系数和相关统计参数,并对模型进行了各项检验,最终根据修正后的模型计算了武汉市2016年的汽车保有量,结果较为准确,表明该方法是一种较为严谨的短期预测方法。本文亦对武汉市2017年的汽车保有量进行了预测。
关键词:计量经济学;武汉市;汽车保有量;预测
中图分类号:F064.1 文献标识码:A 文章编号:1005-2550(2017)04-0045-04
Abstract: According to the statistics of Wuhan, the forecasting model of vehicle population based on econometrics is established, the vehicle population of last year is especially considered in this model as a variable of representation of consumer psychology, and therewith regression coefficients and related statistic parameters are calculated through MATLAB in this paper, solid tests on the model are conducted as well. After model adjusted, the vehicle population of Wuhan in 2016 is eventually calculated. The result is comparatively accurate indicating it is a technically feasible method. The vehicle population of Wuhan in 2017 is predicted in this paper as well.
Key Words: econometrics; Wuhan; vehicle population; forecast
1 引言
对于汽车行业从业者来说,准确预测汽车保有量是准确规划产能和调整未来发展战略的一项重要工作。不仅如此,它还是城市建设部门、交通管理部门合理分配公共泊车资源,有效规划交通路网时需要参考的重要指标。因此,准确预测汽车保有量不论是对于汽车行业,还是对社会整体经济的发展来说都意义重大。
通常用来预测汽车保有量的方法有:时间序列法、神经网络法、灰度预测法等。这些方法各有局限性。例如,时间序列法的優点是所需的数据较少,预测方法较为简单;其缺点是仅将汽车保有量作为随时间单一变化的统计量,忽略了可能影响汽车保有量的其他因素特别是经济政策等。神经网络法的优点是预测精度高,但缺点是训练耗时较长等。[1]
计量经济学模型与以上介绍的方法相比,优势是在引入了相关经济因素作为解释变量,提升了预测精度,计算方法相对简单,便于操作。因此,本文应用计量经济学模型来预测汽车保有量。
2 计量经济学模型
计量经济学(Econometrics)产生于上世纪30年代,是一门经济学、统计学和数学交叉产生的学科。它以数学和统计学为方法论基础,对统计数据进行分析研究,建立模型以探索、验证经济规律。经历了大半个世纪的发展后,计量经济学在各领域内的应用也越来越广泛。
2.1 计量经济学建立模型的步骤
使用计量经济学建立汽车保有量预测模型的步骤如下:
(1)理论模型的设计。针对研究对象,选择合适的变量。本文的研究对象是武汉市汽车保有量,选择的变量见下文3.1。
(2)样本数据的收集。确定研究的变量后,收集相关的统计数据。
(3)建立数学模型。本文使用的是多元线性回归模型,其表达式为[2]:
其中,β是模型的回归参数,u是误差干扰项。
(4)模型参数的估计。本文使用MATLAB软件对模型参数进行求解。
(5)模型的检验。该步骤的工作介绍见下文2.2。
(6)运用模型进行预测。
2.2 模型检验
建立模型之后,还需对其进行检验确定其是否可以付诸使用。本文主要使用的是针对参数的R2检验、F检验、t 检验以及针对假设条件的多重共线性检验。
(1) R2 检验即拟合优度检验。在多元线性回归模型中,可决系数 R2 衡量的是模型的拟合程度,其值介于0至1之间,越接近1,则拟合程度越好。
(2) F 检验是对回归方程总体线性的显著性检验。它检验的是解释变量对被解释变量的影响是否显著成立。
(3) t 检验是对回归参数的检验。其目的是用于判断每个参数对被解释变量的影响是否显著。
(4)多重共线性检验。该检验的其目的是判断各变量之间是否存在线性关系,并将多重共线性程度较强的变量删去,从而保证各解释变量都是独立影响被解释变量。
3 建立模型
3.1 变量选择
被解释变量的选择。本文选取的被解释变量为汽车保有量。
解释变量的选择。结合经济学理论以及武汉市经济发展的实际情况,本文选择如下指标作为模型的解释变量:
(1)国内生产总值 x1。国内生产总值是衡量一个国家或地区总体经济状况的重要指标,其增长情况直接影响汽车保有量。
(2)工业生产总值 x2。工业生产总值是一个国家或地区工业实力的体现,也是国民经济的基础。武汉是中部地区中心城市,全国重要的工业——特别是汽车工业——基地。因此,工业生产总值与汽车保有量之间也存在十分密切的联系。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
红蜻蜓(2021年11期)2021-12-03
作文大王·低年级(2020年9期)2020-10-12
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
同舟共进(2018年9期)2018-11-10
速读·中旬(2018年5期)2018-07-07
中国经贸(2017年24期)2017-12-26
创新作文(1-2年级)(2014年7期)2014-09-23
