
基于移动轨迹数据的商圈消费者规模分析
2017-08-07 13:08刘志刘辉平赵大鹏王晓玲
华东师范大学学报(自然科学版) 2017年4期
刘志,刘辉平,赵大鹏,王晓玲
(华东师范大学计算机科学与软件工程学院数据科学与工程研究院,上海200062)
基于移动轨迹数据的商圈消费者规模分析
刘志,刘辉平,赵大鹏,王晓玲
(华东师范大学计算机科学与软件工程学院数据科学与工程研究院,上海200062)
随着城市化的推进以及大数据技术的不断发展,智慧商圈成为智慧城市建设的重要组成部分.智慧商圈的热门程度、消费者的规模、消费层次等因素成为智慧商圈建设的关注热点.然而,传统的消费者规模的统计,还是基于传统的问卷调查或者抽样等,这些方法不仅成本昂贵而且效率低下.但随着数据挖掘技术的发展,使得通过分析用户行为轨迹来确定商圈消费者规模成为可能.本文提出了一种基于轨迹数据分析的商圈消费者规模分析方法.本文的主要工作包括:①在轨迹数据中,如何确定商圈的边界这是一个首要的问题,基于此,才能确定一位消费者是在商圈内活动,还是在商圈外面.本文提出了根据商圈内基站点的位置分布,运用k-Nearest Neighbor(k NN)分类算法,对该商圈的范围进行圈定的方法.②由于轨迹数据的不确定性特点,确定一个用户与商圈的关系也是一个难题.本文利用计算不规则多边形面积的方法计算基站点的权重值,结合时间阈值分析该区域内每天的消费者规模.③最后,鉴于轨迹数据的海量性,本文提出了一个大数据计算框架BPDA(Business-Circle Parallel Distributed Algorithm),基于Hadoop大数据处理平台和Kafka分布式消息系统,实现了基于移动轨迹数据的商圈消费者规模分析系统,并使用中山公园商圈基站数据,展示了本文所提方法的可行性.
移动轨迹数据;消费者规模分析;k NN分类算法;商圈轮廓
0 引言
商圈作为城市的消费集中地,是一个城市经济水平高低的重要标志.一个商圈经营的好坏,往往可以通过商圈的消费者规模大小来直观的反应,商圈的消费者规模分析对于商圈的经济发展走势预测、商圈的热门店铺推荐等工作都具有重要的意义.除此之外,对于商圈自身来讲,统计消费人群的规模,可以准确的发现商圈的消费者人数变化规律,从而对商圈的规划提供更加合理有效的指导,促进商圈更加快速、稳步地发展.
商圈的消费者规模统计方法中,传统方法是采样技术或者问卷调查等人工方法,这对于商圈的消费者规模进行大数据意义上的统计,是一个难题.此外,还有很多人可能仅仅是路过商圈,并不是来商圈消费,另外还有很多的人是在商圈上班或者居住在附近,这些因素都会对传统方法的准确度产生一定的影响.因此,传统方法不仅调查范围为有限,需要耗费大量的资源,而且测定的商圈范围存在较大的误差.
近些年,基于时空轨迹数据的挖掘技术不断产生,通过分析用户空间移动轨迹来对商圈消费者流量进行统计成为了研究商圈消费者规模分析的一种新的方法.同时,这种研究方法也存在诸多挑战.
(1)商圈范围不确定性.商圈是一个集消费、娱乐、购物等为一体的多功能区域,多分布于商业活动频繁度高、人口密度大、面向客流量多、交通便利的街道,没有明确的边界范围划分.
(2)轨迹数据模糊性.用户在确定的时间点连接某商圈基站,只能说明用户在该时间处于该基站的覆盖范围内,并不能获知用户准确位置,因而不能准确的判断用户与商圈的位置关系.特殊的,存在信号“跳变”现象,即用户在短时间段内与多个基站连接信号频繁切换,这就更加导致了用户移动准确位置难以确定.
(3)轨迹数据海量性.随着硬件技术的提高和完善,越来越多的移动智能设备得到普及使用.如此大量的移动智能设备每天会产生大量的时空移动轨迹数据.据2008年的N ature专刊就大数据提出问题,“人类已经进入了海量存储PB时代,并预测下一个IT巨头的主营业务将会是大数据管理”.
本文针对于上述商圈消费者规模分析的挑战,提出了新的解决方案.该方案包括两个部分:商圈边界划分模块和商圈消费者规模统计分析模块.提出了新的商圈范围圈定算法以及基于规则的大数据计算框架BPDA来对商圈消费者规模进行统计分析.
本文主要贡献在以下几个方面.
(1)基于商圈基站的位置分布,采用k NN分类算法并结合轮廓优化算法对商圈的范围进行圈定,确保生成的商圈轮廓更加清晰.
(2)针对轨迹数据模糊性问题,提出通过计算不规则多边形面积的方法来依次计算基站点的权重值,并且结合不同的时间阈值以及轨迹判定规则来对用户的行为轨迹进行建模分析,从而对商圈消费者规模进行统计.
(3)基于大数据统计分析平台Hadoop以及消息流收集系统Apache Kafka(简称Kafka),提出了一种高效的分布式大数据计算框架BPDA来对商圈消费者规模进行统计分析,克服了传统方法的成本昂贵、效率低下以及误差大的缺点,并且以中山公园商圈为例,对算法的有效性以及可行性进行了准确分析.
本文剩余部分的组织结构如下:第1节描述相关工作;第2节介绍本文的商圈、基站、移动轨迹等概念以及研究的问题定义;第3节简要介绍商圈边界划分模块和商圈消费者规模统计分析模块;第4节详细介绍商圈边界划分模块;第5节详细介绍商圈消费者规模统计分析模块;第6节报告实验结果;第7节总结全文.
1 相关工作
目前,与商圈消费者规模统计分析研究相关的是城市功能化模块划分以及动态时空数据聚/分类两大领域.
关于功能化模块划分这一领域,已经有了很好的研究.文献[1]中提到基于人们的移动轨迹数据及POI数据,利用TF-IDF向量对城市的功能区进行了不同的划分,分为居住区,商业区,教育区等.文献[2]利用CPF向量以及新的topic模型对功能区进行了更准确的划分.文献[3]基于出租车上下车记录以及行驶轨迹数据,采用简单的分类算法,来对城市主功能区和非主功能区进行分类.文献[4]通过对伦敦市出租车的行驶轨迹数据分析,挖掘出租车的运动模式,来划分伦敦市的主要购物街道.文献[5]对比不同的机器学习方法,例如简单逻辑回归、决策树模型、贝叶斯分类器等,对城区地表覆盖物的图片进行了分类,根据分类结果分类不同的城市功能区.文献[6]中详细的介绍了城市功能区域的概念,并且给出了城市功能区划分的依据.文献[7]从cluster角度上介绍了城市功能区的特点、聚类方法、以及聚类的策略.
关于动态时空数据聚/分类方面目前也有比较成熟的研究.在时空数据聚类方面,文献[8]提出了基于密度的聚类算法ST-DBSCAN用于空间移动轨迹数据聚类分析,可以屏蔽噪音点,自动将中心点和边缘点聚成一个完整的簇.文献[9]提出了four-step时空数据聚类算法,自动去除数据中的噪音以及补齐缺失数据.文献[10]基于聚类方法DBSCAN提出了新的方法STDBSCAN对空间时空轨迹进行聚类,用于发掘潜在的POI.文献[11]提出了single-link的时空数据聚类算法,该方法是谱系聚类图的一种,可以方便的转换为树图来分析参数相似性问题.在时空数据分类方面,文献[12]提出了一种懒惰学习模型ML-k NN来解决文本分类问题.文献[13]将SVM和k NN模型结合到一起提出了混合模型SVM-k NN来降低可视化分类识别领域的计算复杂性,并提高了分类结果的准确性.文献[14]提出了GA-k NN分类算法,并优化算法的参数来成功解决基因分类问题.
然而,以上基于用户移动轨迹数据的城市功能区划分以及时空数据聚类方面的研究都是基于用户准确的GPS(Global Position System)坐标位置或者准确的上下车刷卡记录,针对存在位置模糊性的时空轨迹数据而言,以上方法都不适用.本文中研究的是用户与基站连接的空间移动轨迹数据,不能准确的定位用户的实时位置,借鉴了以上工作研究方法,文中提出了有效的大数据计算框架BPDA,对商圈轮廓范围进行了圈定,并且对商圈的消费者规模进行了统计和分析.
2 问题定义
问题描述:给定商圈基站点的集合以及用户的移动轨迹数据,对商圈范围进行圈定以及对商圈的消费者规模进行统计和分析.
定义1基站:一个基站sta(id,loc)是移动用户通信的节点,其中id表示该基站的标识, loc表示该基站的实际地理位置,通常用经纬度表示.如(C1270,(121.247 82,31.392 36))表示基站C1270位于东经121.247 82°,北纬31.392 36°位置.如图1(a),存在3个基站点.
基站有宏站和微站之分,宏站的信号覆盖范围比较大,大约为2.5 km,而微站的信号覆盖范围比较小,大约为500 m.
多个分散的基站交错构成了基站覆盖区域,将覆盖区域的边缘位置基站相互连接形成的一个多边形区域称为商圈.
定义2移动轨迹:一个移动轨迹Tr是指一系列的有时间标记的基站数据,Tr: p1→p2→p3→···→pn,其中pi表示有时间标记的移动轨迹点,pi=(sta,t).如((C1270, (121.247 82,31.392 36)),20130519134542)表示在时间点20130519134542该用户连接基站C1270.如图1(b),13#13:16:47~18#17:33:36存在往返轨迹1和轨迹2.
此外,存在不规则的用户轨迹—–“跳变”,即一个用户在短时间内与多个基站连接信号频繁切换的现象,这种情况下,不能明确地看出用户的移动轨迹,而是构成一个局部的环路.如图1(c),用户在2#16:58:50~18#19:21:18时间内不停地在基站a和基站b之间进行信号切换.
定义3商圈覆盖点集合:用于覆盖商圈范围的标示点组成的最小矩形,该矩形覆盖点用于确定商圈的范围.如图1(d).
定义4商圈消费者规模:特意来商圈消费的消费者规模数量的统计,不包括工作或者居住在商圈附近以及路过商圈的人群.

图1 示例图Fig.1 Sample
3 模块介绍
为了解决上述问题,本文首先基于基站数据集对商圈的范围进行划分,然后利用计算多边形面积的方法计算各基站的权重值,最后基于基站点的权重值以及用户移动轨迹判定规则来统计用户在商圈内的停留时间,根据停留时间统计出不同时间段的商圈内的消费者规模大小.
本文涉及商圈边界划分和商圈消费者规模统计分析两大模块.商圈边界划分模块又包括商圈网格化覆盖和商圈轮廓划分,商圈消费者规模统计分析模块包括权重计算和消费者规模统计.具体功能模块流程图如图2.
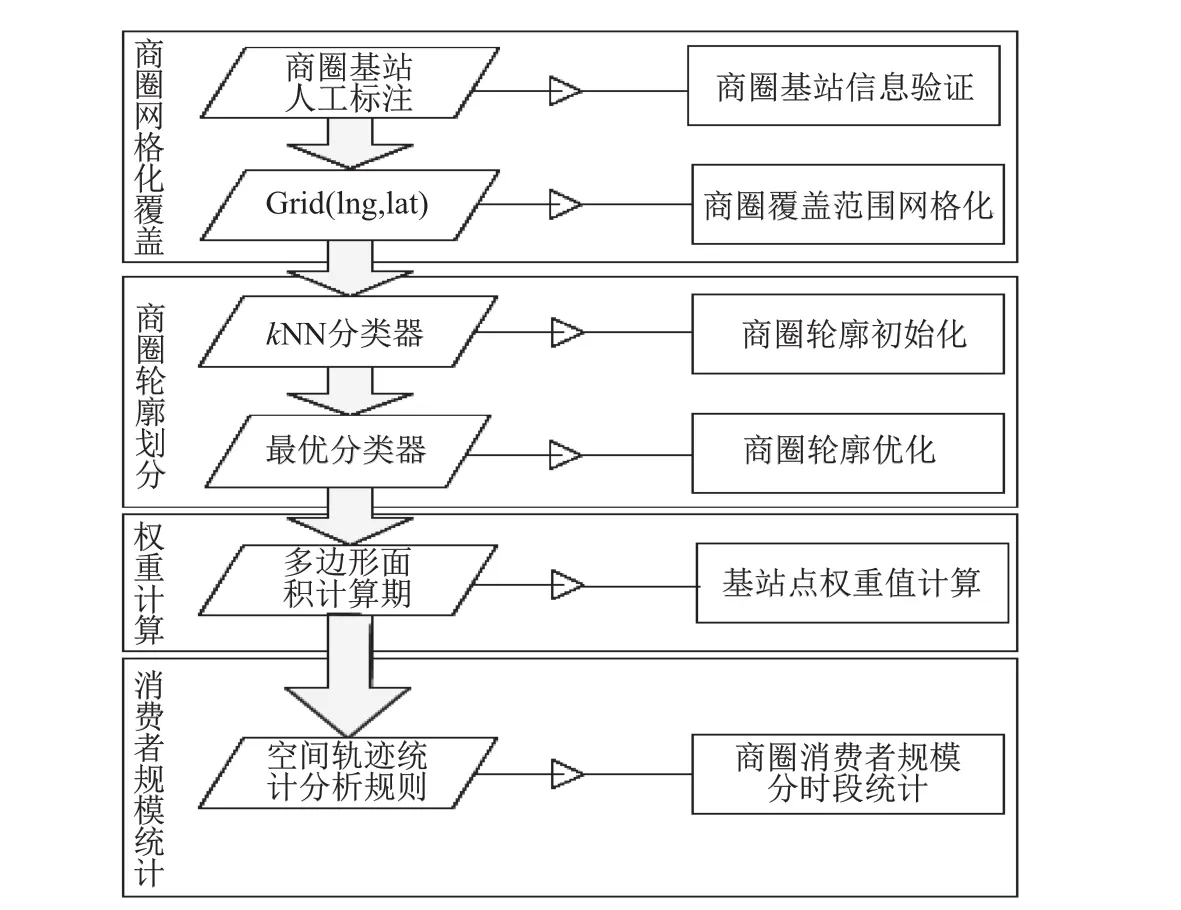
图2 功能模块流程图Fig.2 Function module process
商圈网格化覆盖:用于校验人工标注的商圈基站点的完整性以及生成覆盖商圈范围的矩形区域覆盖点.
商圈轮廓划分:用于生成商圈的轮廓以及对轮廓的优化.
权重计算:通过计算多边形面积来计算商圈基站点的权重值.
消费者规模统计:利用大数据计算框架BPDA结合不同轨迹模式判定规则来对商圈消费者规模进行统计分析.
本节简要介绍文章中要做的工作是商圈轮廓的划分(即商圈识别)以及商圈中有效消费者规模的统计,在接下来的章节中将会详细介绍如何通过算法和大数据统计分析工具来对这两部分进行实现.
4 商圈边界确定
本节先描述商圈基站点的预处理以及商圈最小矩形覆盖点的生成,再介绍如何利用KNN分类算法对商圈覆盖点进行分类以确定商圈的轮廓范围.
4.1 商圈最小矩形覆盖
对存在Kafka上的基站数据,通过消息拉取的方式将消息从Kafka中取出并保存在HDFS中,利用数据仓库处理工具Hive筛选出所有上海市的基站点,保留每个基站点ID,经、纬度坐标以及基站的类别(宏、微站)字段.由于人工标注过的商圈基站点集合可能没有完全包括所有的商圈基站点或者存在非商圈基站点,为了能够更加清晰地划分出商圈轮廓,需要利用百度地图API对人工标注的商圈基站点进行打点校验,并对未能标注出的基站点进行补充.如图3所示,红色点为某通信运营商标注的商圈基站点,蓝色点为所有的基站点(商圈基站点和非商圈基站点).
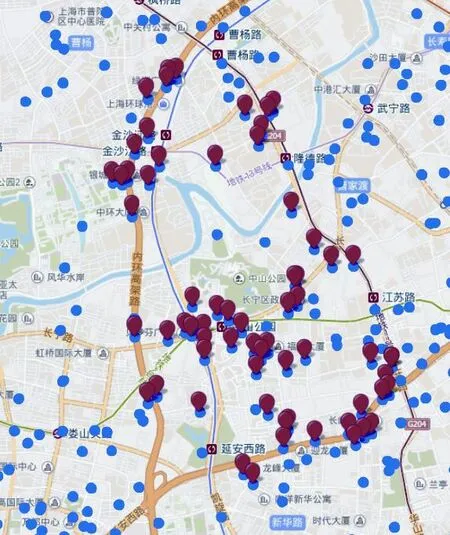
图3 人工标注的商圈基站点图Fig.3 Business circle base station
对于已修正过的商圈基站点集合,分别计算出基站点的最大经度lngmax、最小经度lngmin、最大纬度latmax、最小纬度latmin,然后根据经纬度的范围确定一个可以覆盖所有基站的最小矩形,经度坐标范围为(lngmax,lngmin),纬度坐标范围为(latmax,latmin).需要设置矩形内部的分辨率m×n,即对该矩形经度坐标进行m次等分,纬度进行n次等分,分别生成m×n个坐标点,即m×n个商圈覆盖点.
关于矩形分辨率中m和n的取值,m和n越大,商圈识别算法要处理的点数越多,耗时越长,但是得到的商圈轮廓更加清晰自然.因此考虑到算法耗时问题,实验中m和n值的选择只要大小合适、商圈轮廓清晰自然便可.
4.2 商圈识别
本节中,首先使用k NN[15]即k最近邻分类对商圈最小矩阵覆盖点进行分类,从而确定粗略的商圈边界.具体做法是基于商圈基站点和非商圈基站点这两种类别对第4.1节中整个商圈覆盖点集合进行二分类,得到商圈轮廓的覆盖点集合和非商圈轮廓的覆盖点集合.因为所要计算得到的是轮廓边界,不是完整区域,因此k NN分类器k值设置为3,即与一覆盖点最相邻的3个基站点(Top3)中,满足count商圈>count非商圈,且Top2中count商圈=1, count非商圈=1,该覆盖点保留.
商圈识别算法如算法1所示,其中,序号1至序号4确定商圈经纬度范围;序号5至序号9生成最小矩阵覆盖点;序号10至序号11依次计算m×n个覆盖点与所有基站点(包括商圈基站以及非商圈基站)之间的欧式距离di;序号12对距离值di进行升序排序;序号13至序号16取集合Di前3个即d1,d2,d3对应的3个基站点进行判断,如果这3个基站点当中count商圈>count非商圈,且d1,d2对应的基站点满足count商圈=1,count非商圈=1,保留该覆盖点,否则,删除.

算法1 商圈识别算法
对于算法1,由于需要对所有的商圈覆盖点与每个基站点进行欧式距离计算,然后根据距离进行快速排序,并且只排序至最小的k个元素(Top k)就停止排序.由于快速排序的最优时间复杂度为O(n log2n),最坏时间复杂度为O(n2),所以时间复杂度为O(m×n+(m×n)2),其中m为商圈覆盖点数,n为商圈基站数.
从算法1中可以看到商圈识别算法利用了k NN分类器对商圈覆盖点进行分类,保留位于商圈基站和非商圈基站之间的覆盖点,并且最终通过阈值τ的判断只保留位于接近两类基站点连线的中间位置的商圈覆盖点,这样做的好处是使得生成的商圈轮廓贯穿两类基站点的中间位置.
然而对于算法1得到的商圈轮廓点通过调用百度API打点之后会发现存在覆盖点堆积的问题,即在小范围内存在多个点的经度或者纬度相同的情况,多个覆盖点聚集在一起,使得商圈的轮廓变得不均匀.因此,需要删除冗余的覆盖点,对商圈轮廓进行进一步优化,使其更加规整自然,优化过程如算法2所示,其中序号1选取k NN分类算法所得到的覆盖点集中任意一个覆盖点为初始点a;序号2至序号9找到与该初始点a之间距离小于阈值τ2的另一覆盖点b,如果存在多点情况下,可任选其中一个覆盖点;序号10至序号14重新以覆盖点b为初始点,继续循环以上操作,直到找到的下一覆盖点为最开始的初始点a为止.

算法2 商圈轮廓优化算法
算法2需要对算法1的结果集进行遍历,对于每个覆盖点ai,分别计算该覆盖点与结果集中的其他覆盖点的欧式距离di,直到找到任何一个欧式距离di小于阈值τ2的覆盖点dj为止.结果集中删除di,然后以覆盖点dj为新的起点,进行下一轮迭代查询.如果每轮迭代结果集第一个元素就满足与起点ai的欧氏距离小于τ2,那么最优时间复杂度为O(n);如果是结果集的最后一个元素,最坏时间复杂度为O(n2).因此,算法2的时间复杂度为O(n2).
5 商圈消费者规模统计
本节首先计算出每个基站点的权重值,然后结合基站点的权重以及用户移动轨迹判定规则来确定商圈消费者规模.
不同基站有不同权重值可以很好地解决轨迹数据位置模糊性问题.根据用户与商圈基站连接时间与基站点的权重值的乘积来计算用户轨迹在商圈的停留总时间,结合用户轨迹模式判定规则来进行商圈内有效消费者规模统计.
5.1 基站权重值计算
由于商圈的基站有一定的覆盖范围,因此仅仅通过用户轨迹数据无法有效地定位用户的地理位置.另外,由于基站的覆盖范围存在一定的交叉重叠,导致存在信号“跳变”的情况,所以仅仅通过用户与商圈基站的连接时长这一个维度来进行商圈消费者规模统计是不足的,需要加入另一个维度—–商圈基站的权重值.
对于任意基站点stai,其权重值等于该基站点覆盖范围和商圈的重叠面积与基站点覆盖面积的比值,计算公式为

其中,A重叠代表基站点覆盖范围和商圈的重叠面积,S代表基站点覆盖面积.
由于商圈轮廓是不规则的多边形,计算基站stai覆盖范围与商圈的重叠面积比较复杂,所以采用随机抛洒样本点的方式,在基站覆盖范围圆内抛洒若干样本点,统计在商圈范围内的样本点数目占所有样本点的比例并作为基站stai的权重值大小.计算基站权重值步骤如算法3所示,其中,序号1至序号9遍历所有商圈基站,如果为宏站,则以该基站点为圆点,以宏站最大信号覆盖范围r1=2 500 m为半径建立覆盖圆,在圆内随机生成m个随机点,计算落入商圈轮廓范围内的随机点数目与m的比值;序号10至序号17基站点为微站,则以微站最大信号覆盖范围r2=500 m为半径建立覆盖圆,其他步骤同上.

算法3 计算基站权重值算法
对于算法3,需要对商圈基站点集合S5进行遍历,以Si为圆心,r为半径建立覆盖范围圆,在圆中随机生成m个点,统计位于商圈范围内的基站点数.因此,该算法的时间复杂度为O(m×n),n为商圈基站点数,m为每次随机生成的样本点数.
5.2商圈消费者规模统计
该模块利用Kafka、Hadoop[16]大数据平台,提出基于MapReduce的计算框架BPDA.整体算法思想:首先通过文献[17]所提出的工作地和居住地挖掘方法,在统计过程中去除工作或居住在商圈附近这部分用户;然后基于用户轨迹来统计用户与各个商圈基站点的连接时间ti,乘以相应基站点的权重值wi,求和,得到用户在商圈内停留总时间∑若停留时间超过阈值§,则认为用户在该时间段来商圈消费.数据处理流程图如图4.

图4 用户轨迹数据处理流程图Fig.4 Trajectory data processing
由于用户移动轨迹中存在“跳变”现象,即用户信号在不同的基站之间形成了局部的“环”.根据“环”中基站点与商圈的不同位置关系,做不同的处理规则,具体如下.
(1)用户与多个商圈基站点连接.分别统计用户与各个基站点连接时间乘以权重值,然后求和.
(2)用户短时间内频繁在商圈基站和非商圈基站进行信号切换.分别统计用户与商圈基站和非商圈基站的连接时间,如果用户与商圈基站连接时间明显大于非商圈基站连接时间,则将与非商圈基站连接时间归为商圈基站的时间来统计;反之,则认为该用户未在商圈停留,只是简单的基站信号跳变.
(3)用户与商圈基站和非商圈基站切换连接,且每次切换连接时间较长.如果与商圈基站和非商圈基站的连接时间差超过1 h,则认为用户在与商圈基站的最后一个连接时间点离开了商圈,与非商圈基站的连接时间不计入统计;否则,则认为是信号跳变,计入统计.
轨迹判定规则流程图如图5所示.
基于以上的规则,利用大数据计算框架BPDA对商圈消费者规模进行统计.BPDA算法需要运行3轮MapReduce计算模型:第一轮是对所有用户的移动轨迹数据按照每个用户手机号码进行分组处理,得到每个用户按照时间排序的有序移动轨迹数据集;第二轮是对第一轮的结果数据集进行处理,结合轨迹判定规则和商圈基站的权重值来计算每个用户在商圈的停留时间,将该停留时间按照1 h为步长划分成多个时间段,从而得到各个日期不同时间段商圈的消费者规模数据集;第三轮是对第二轮的不同时刻商圈消费者规模数据集按照日期进行分组处理,对每个分组内的24个时间段进行排序,结合MapReduce模型本身的内部排序特点对日期进行排序,得到日期和时间段均有序的商圈消费者规模数据集.整个BPDA计算框架处理步骤如图6.
BPDA计算框架第二轮详细处理过程如算法4所示,其中,序号1至序号9用于判断一条轨迹记录的基站stai是否是商圈基站,如果是,保存该基站点,并且对该基站点的连接时长乘以基站权重值进行累加;序号10至序号19判断基站stai不是商圈基站,需要判定前一条记录的基站staraserved是否为商圈基站,如果不是,不作处理,如果是,则需要对基站staraserved的连接时长与时间阈值§1进行判定,小于时间阈值§1,则累加连接时长.否则,不作处理;序号20至序号26对用户与商圈基站的连接时长(tbegin,tend,∆ttotal)与阈值§2进行判定,对时间长度tbegin到tend基于1 h为单位进行拆分,分成〈ti,1〉作为Map部分的输出;序号31至序号32对输入〈ti,[1,1,1,···]〉按照时间点ti进行聚合成〈ti,numi〉.
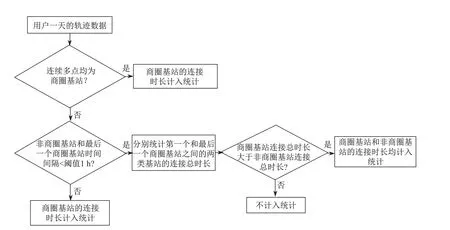
图5 用户轨迹判定规则流程图Fig.5 Trajectory decision rules
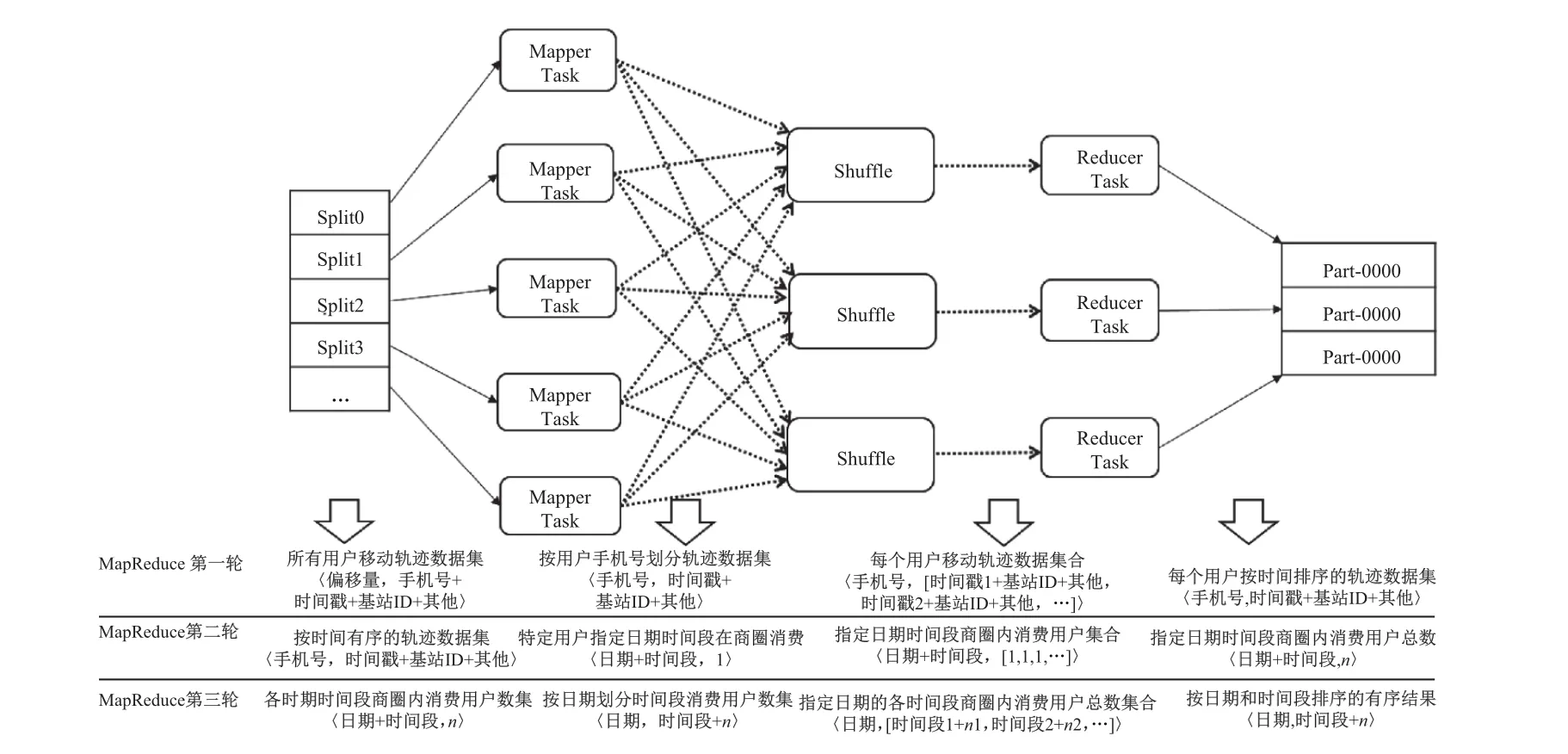
图6 BPDA整体处理流程图Fig.6 BPDA processing flow

算法4 商圈消费者规模统计算法
6 实验
这一节给出具体实验.实验是以中山公园商圈为例,对该商圈的轮廓进行圈定,计算商圈基站的权重值以及对该商圈消费者规模进行统计与分析.
6.1 实验数据
实验数据:本文使用上海某通讯运营商提供的用户连接基站OIDD数据以及商圈基站点数据.这些数据包括3 200 000名用户从2014年8月15日至2015年3月1日(共208 d)期间用户连接基站OIDD数据,数据源大小约为1.6 TB,以及238个用户标注的商圈基站点.具体数据格式如下.

此外,本文还随机选取了96名志愿者的移动轨迹数据对BPDA计算框架的准确性和精确度进行验证.志愿者每月平均商圈消费次数分布情况和志愿者每月平均经过商圈次数分布情况如表1和表2所示.

表1 志愿者商圈消费次数分布Tab.1 Business consumption time distribution

表2 志愿者经过商圈次数分布Tab.2 Business passing time distribution
6.2 实验环境及相关设置
本实验采用的是40个节点的Hadoop集群,每个节点运行的操作系统为RedHat Linux version 6.7,处理器为Intel(R)Xeon(R)CPU E5620,主频为2.40 GHZ,软件版本为Hadoop2.6.
对于商圈轮廓识别模块,设置商圈识别算法的阈值τ为30,商圈轮廓优化算法的阈值τ2为15.对于消费者规模统计模块,通过多次实验分别计算用户离开商圈的阈值§1以及商圈的停留时间阈值§2所对应的F1-score,最终设置§1为30 min,§2为60 min.
6.3 阈值确定
在判定用户来商圈消费的规则当中,对商圈停留时间阈值的选取做了如下计算.采样1 000个用户在30 d里的不同用户移动轨迹数据,通过人工标注的方式得到有581 d存在用户来商圈消费行为,以10 min为步长,递增时间阈值,进行多组实验,然后分别计算每组实验的Recall和Precision值;再通过公式来计算F1-score,公式为

其中,i代表停留时长,Pi代表i停留时长的准确率,Ri代表i停留时长的召回率,Tp代表计算出来的真实商圈消费行为,Fp代表错误商圈消费行为,Fn代表未计算出来的真实商圈消费行为.
通过实验分析可以得出,当时间阈值§2选择为接近60 min的时候,如图7中的红色三角形位置,F1-score为最高值0.859.
(1)图8是商圈识别算法的性能示意图,该算法的时间复杂度为O(m×n+n2),m为基站数,n为商圈覆盖点数,k为k NN分类器参数.图中对比了k NN算法k分别值为3,5,7的时候,不同分辨率(即不同数目的商圈覆盖点)对应的时间性能.从图中可以看出,随着k值的增大,由于算法要判断的排序之后的Top k的个数增加,算法耗时也相应增大.例如,当分辨率为100×100的时候,k=3的耗时为1.974 s,k=7的耗时为2.441 s.同时,也可以看出,对于同一个k值而言,随着分辨率成倍增长,算法的耗时以二次方增长.例如,对于k=3,当分辨率为100×100时,时耗为1.974 s,当分辨率为1 000×1 000时,耗时为191.15 s,分辨率增长10倍,耗时也增长接近100倍.

图7 F1-score随时间阈值变化图Fig.7 F1-score threshold value
6.4 算法性能分析
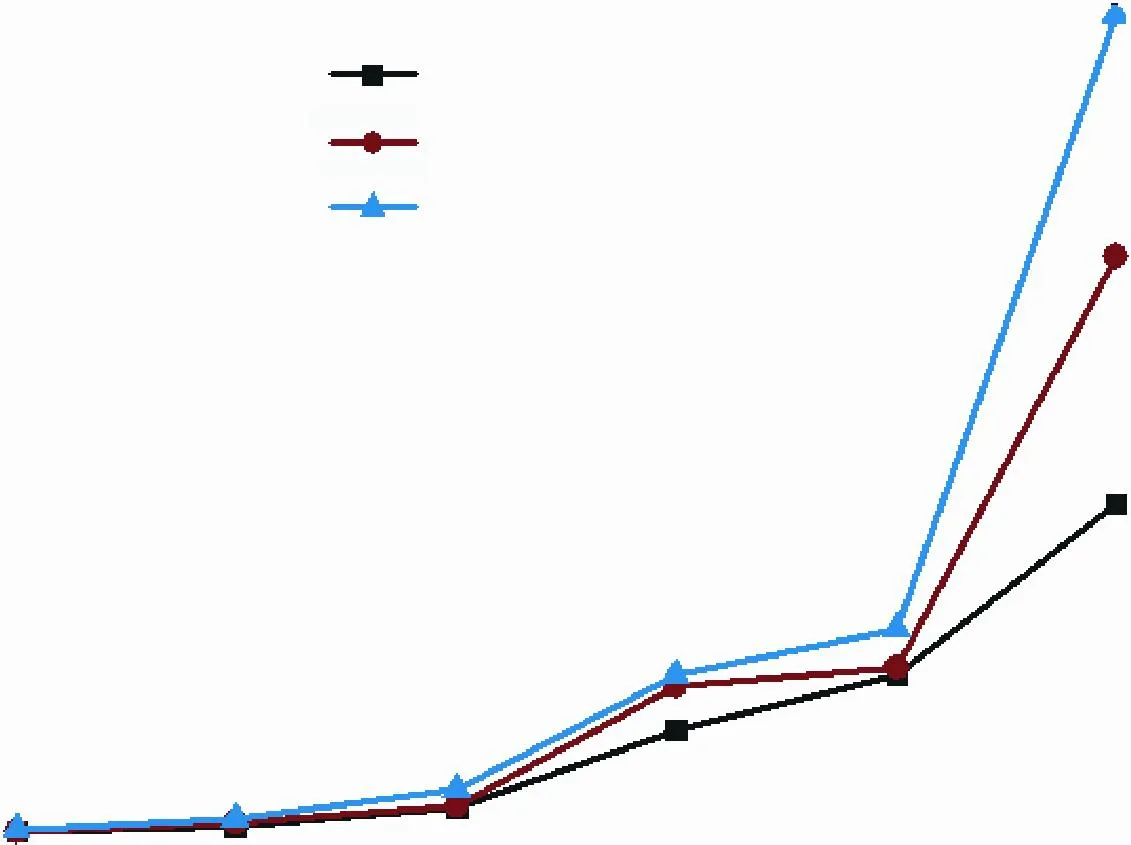
图8 商圈识别算法时间代价Fig.8 Business recognition time complexity
(2)图9是商圈轮廓优化算法的性能示意图,该算法时间复杂度为O(n2),n为商圈识别算法所保留的商圈覆盖点.从图中可以看出,随着分辨率的增加,算法耗时也接近线性增长.图中举例k=3的时候,当分辨率为1 000×1 000,算法处理时间为40 s,算法性能比较好.
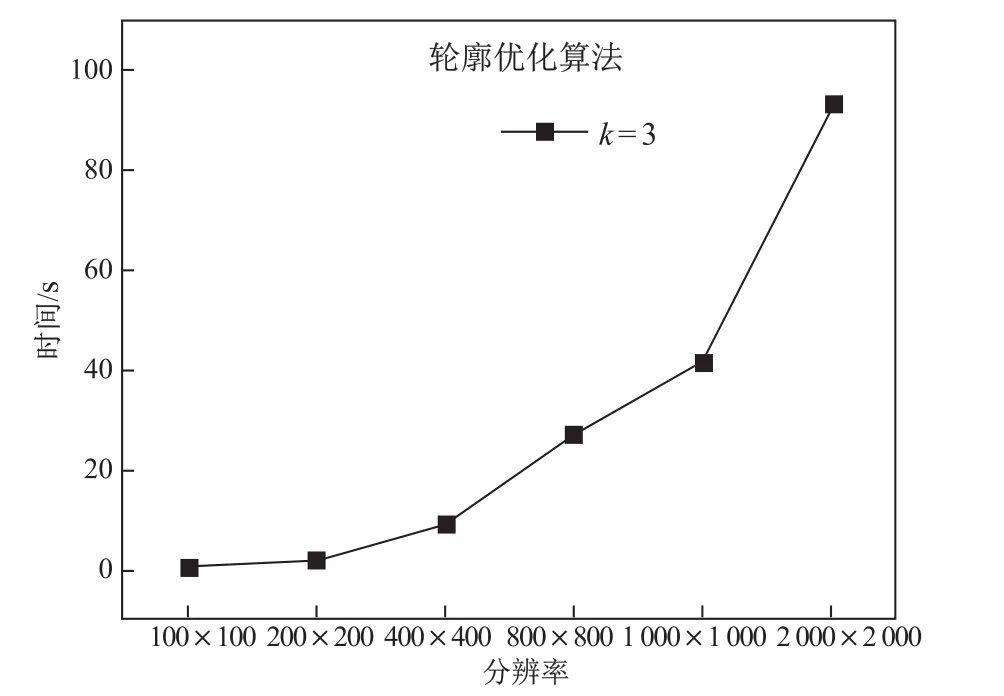
图9 商圈轮廓优化算法时间代价Fig.9 Business optimizing time complexity
(3)表3是时间阈值§1和§2分别为不同值时BPDA计算框架的准确度、召回率以及F1-score的变化情况.随着阈值§1的增大,更多用户在商圈外部边缘的停留时间被计入统计,从而可能导致更多经过商圈的移动轨迹无效记录被计入统计,进而导致统计的准确率降低,同时也会使得小于停留时间阈值§2的有效移动轨迹记录纳入统计,从而召回率增大;随着阈值§2的增大,更多经过商圈小于时间阈值的无效记录被删除,保留更多在商圈停留时间大于时间阈值的有效记录,因此统计的准确率会增大,同时会有小于停留时间阈值§2的有效移动轨迹记录没有计入统计,从而导致召回率下降.由图8中红色记录可以看出当§1为1 800 s、§2为3 600 s时, F1-score为最高值0.859.
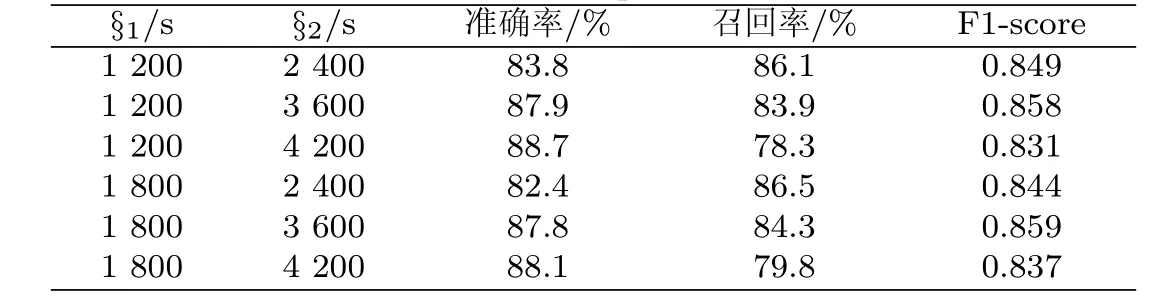
表3 BPDA算法性能统计Tab.3 BPDA performance
(4)表4所示是BPDA计算框架与其他文献中的消费者规模统计算法的性能对比.文献[18]和文献[19]是利用数据库存储过程来计算分析用户移动轨迹数据进而统计指定区域的消费者规模,没有特意考虑排除对商圈工作人员、居住和工作在商圈附近以及路过商圈的人的统计.此外,没有充分考虑用户移动轨迹信号“跳变”的问题,因而没有结合不同的轨迹判定规则以及时间阈值对商圈消费者规模进行分类分析统计,准确率以及召回率比较低;文献[20]是通过统计监控视频中行人的数量来对商圈消费者规模进行统计,能够准确判定用户的存在,因而准确率和召回率都比较高,但是该种方法在适用范围上具有局限性,且投入成比较大.
(5)图10是BPDA计框架基于不同商圈停留时间阈值以及不同集群计算节点的运算时间图.可以看出,随着计算节点数的成倍增加,框架整体运算时间大幅度减少,计算节点数由10变为20时候,运算时间接近成倍减少,计算节点继续增加,框架运算时间减少幅度变小;从对比时间阈值为600 s的黑线和3600 s的蓝线可以看出,相同数目的计算节点对应的计算时间相差较大,可以得出真实用户移动轨迹中存在大量的短时间商圈停留,即用户经过商圈的记录.
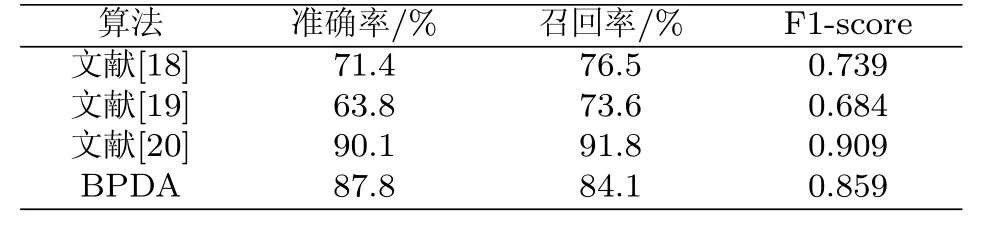
表4 BPDA算法性能对比Tab.4 BPDA performance contrast

图10 BPDA算法运行效率示意图Fig.10 BPDA time cost
6.5 实验结果分析
(1)图11是中山公园商圈轮廓.图11(a)是商圈矩形覆盖点示意图;图11(b)是k NN分类器分类之后的商圈轮廓,可以看出该轮廓中黑线标注的部分存在明显的覆盖点堆积的现象;图11(c)是利用轮廓优化算法优化过的商圈轮廓,可以看出图中的商圈轮廓更加清晰自然.
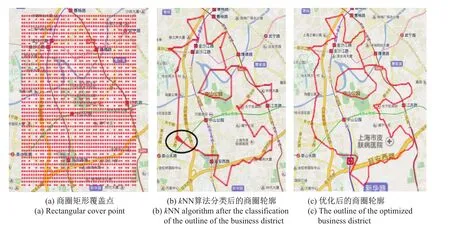
图11 商圈轮廓精细化示意图Fig.11 Business outline sample
(2)图12是BPDA计算框架统计中山公园商圈的正常工作日与周末消费者规模对比图.横轴为一天不同的时间段,纵轴为商圈有效消费者规模大小.图中有4条曲线,黑色曲线代表周六的时候消费者规模变化情况,红色曲线代表周日的消费者规模变化情况,蓝色和紫色曲线分别代表正常工作日周三和周五的消费者规模变化情况.
由图12中可以看出,总体来讲,中山公园商圈周末比工作日的消费者规模大很多.周末的消费者规模高峰期出现在14:00左右,只有一个波峰,而且高峰期两端分布比较均匀,呈高斯分布.周六消费者规模比周日消费者规模稍大,这与很多消费者周六选择逛街消费,周日选择休息的生活习惯吻合.周三和周五消费者规模分别有两个波峰,第一个高峰期出现在13:00左右,第二个高峰期出现在晚上18:00左右,这与上班族下班之后去商圈消费比较符合,而且周五高峰期的消费者规模比周三相对较大,这也符合大多数人会选择在周五晚上商圈聚餐、娱乐、消费的习惯.
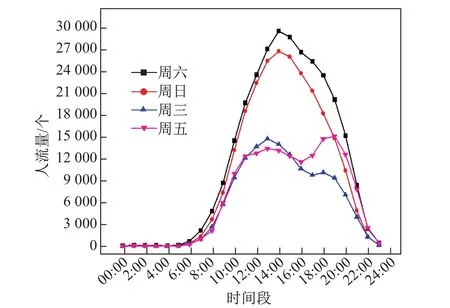
图12 商圈的不同时段消费者规模分布图Fig.12 Human traffi c distribution
7 总结
本文基于Kafka、Hadoop大数据平台,提出了对商圈消费者规模进行统计分析的大数据处理方法.首先,对于商圈范围不确定性,利用分类模型k NN对商圈的轮廓范围进行了有效圈定;其次,由于用户移动轨迹模糊性,根据商圈基站的不同位置,计算不同基站点的权重值;最后,利用大数据计算框架BPDA结合用户轨迹判定规则以及时间阈值,对商圈有效消费者规模按时段进行统计分析.在未来的研究工作中,将会基于当前的研究工作,采用更多的分类和聚类模型,对商圈内消费者的性别、年龄、收入情况等信息进行挖掘,从而有助于提高商家广告投放的精准性,帮助商家创造更大的经济价值.
[1]YUAN J,ZHENG Y,XIE X.Discovering regions of diff erent functions in a city using human mobility and pois[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2012:186-194.
[2]YUAN N J,ZHENG Y,XIE X,et al.Discovering urban functional zones using latent activity trajectories[J]. IEEE Transactions on Knowledge&Data Engineering,2015,27(3):712-725.
[3]QI G,LI X,LI S,et al.Measuring social functions of city regions from large-scale taxi behaviors[C]//IEEE International Conference on Pervasive Computing and Communications Workshops.IEEE,2011:384-388.
[4]GODDARD J B.Functional regions within the city centre:A study by factor analysis of taxi fl ows in central London[J].Transactions of the Institute of British Geographers,1970,49(49):161-182.
[5]VATSAVAI R R,BRIGHT E,VARUN C,et al.Machine learning approaches for high-resolution urban land cover classifi cation:A comparative study[C]//Proceedings of the 2nd International Conference on Computing for Geospatial Research&Applications.ACM,2011:Article No 11.
[6]ANTIKAINEN J.The concept of functional urban area(Findings on the ESPON project 1.1.1)[J].Informationen Zur Raumentwicklung,2005,7:447-456.
[7]KARLSSON C.Clusters,functional regions and cluster policies[R/OL].JIBS CESIS Electron,Working Paper Ser(84).[2016-06-01].https://www.researchgate.net/publication/5094404.
[8]BIRANT D,KUT A.ST-DBSCAN:An algorithm for clustering spatial–temporal data[J].Data&Knowledge Engineering,2007,60(1):208-221.
[9]CHEN X C,FAGHMOUS J H,KHANDELWAL A.Clustering dynamic spatio-temporal patterns in the presence of noise and missing data[C]//Proceedings of the 24th International Joint Conference on Artifi cial Intelligence (IJCAI 2015).2015:2575-2581.
[10]BIRANT D,KUT A.ST-DBSCAN:An algorithm for clustering spatial-temporal data[J].Data&Knowledge Engineering,2007,60(1):208-221.
[11]SLINK S R.An optimally effi cient algorithm for the single-link cluster method[J].The Computer Journal,1973, 16(1):30-34.
[12]ZHANG M L,ZHOU Z H.ML-k NN:A lazy learning approach to multi-label learning[J].Pattern recognition, 2007,40(7):2038-2048.
[13]ZHANG H,BERG A C,MAIRE M,et al.SVM-KNN:Discriminative nearest neighbor classifi cation for visual category recognition[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society,2006:2126-2136.
[14]LI L,WEINBERG C R,DARDEN T A.Gene selection for sample classifi cation based on gene expression data: study of sensitivity to choice of parameters of the GA/k NN method[J].Bioinformatics,2001,17(12):1131-1142.
[15]李秀娟.k NN分类算法研究[J].科技信息,2009,31:81+383.
[16]WBITE T.O’Reilly:Hadoop权威指南[M].周敏奇,王晓玲,金澈清,等,译.第2版.北京:清华大学出版社,2011.
[17]章志刚,金澈清,王晓玲,等.面向海量低质手机轨迹数据的重要位置发现[J].软件学报,2016,7:1700-1714.
[18]吴松,雒江涛,周云峰,等.基于移动网络信令数据的实时人流量统计方法[J].计算机应用研究,2014(3):776-779.
[19]沈泽,吴松,杨勇,等.移动通信网信令处理平台的实时人流量统计方法[J].广东通信技术,2013,8:56-60.
[20]肖江,丁亮,束鑫,等.一种基于计算机视觉的行人流量统计方法[J].信息技术,2015,8:22-25.
(责任编辑:李艺)
Business circle population mobility statistics based on mobile trajectory data
LIU Zhi,LIU Hui-ping,ZHAO Da-peng,WANG Xiao-ling
(Institute for Data Science and Engineering,School of Computer Science and Software Engineering,East China Normal University,Shanghai 200062,China)
With the advancement ofurbanization and continentaldevelopment ofbig data technology,smart business has become an important part of smart city construction.The popularity,consumer number scale and consumption level of smart business also become the hot spot in the construction of smart city.However,traditional consumer statistics method is based on traditional survey and sampling,etc.All of these traditional methods are high-cost and ineffi cient.Fortunately,the fast development of data mining technology makes statistics in business circle by analyzing user behavior trajectory data possible.In this paper,we propose a consumer scale analysis method on business circle using usertrajectory data.There are three mainly work parts:①How to determine the realboundary of business circle in trajectory data analysis domain is a primary problem,and we can judge a consumer activity within or outside the business circle based on it.Facing this issue,we raise a new method to delineate business circle using k-Nearest Neighbor(k NN) classifi cation algorithm based on the location of base station within business circle.②How to determine the relationship between user and business circle is also a new problem due to uncertainty of trajectory characteristics.We calculate irregular polygon area to evaluate the weight of each base station and also combine with time threshold in order to analyze consumer scale every day.③Finally,considering large amounts in trajectory data, we propose a big data computing framework BPDA(Business-Circle Parallel Distributed Algorithm),which is based on Hadoop big data platform and Kafka distributed message system,to implement business circle consumers scale analysis system.Moreover,we take Zhongshan Park business circle as an instance to verify the feasibility of our algorithm.
mobile trajectory data;consumer scale analysis;k NN classification algorithm;business circle outline
TP311
A
10.3969/j.issn.1000-5641.2017.04.009
1000-5641(2017)04-0097-17
2016-07-20
刘志,男,硕士研究生,研究方向为数据挖掘.E-mail:lyz8538350@126.com.
猜你喜欢
房地产导刊(2021年8期)2021-10-13
海峡科技与产业(2021年1期)2021-05-22
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
中国交通信息化(2017年4期)2017-06-06
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
中国老区建设(2016年12期)2017-01-15
中国交通信息化(2016年8期)2016-06-06
移动通信(2015年17期)2015-08-24
