
电子商务网站的个性化“混合”推荐服务
2017-08-01 00:14:00蔡银英
重庆第二师范学院学报 2017年4期
蔡银英
(重庆第二师范学院 数学与信息工程学院,重庆 400067)
电子商务网站的个性化“混合”推荐服务
蔡银英
(重庆第二师范学院 数学与信息工程学院,重庆 400067)
随着电子商务网站的快速发展,网络商品销售数量急剧增加,要提升用户网购的体验度,就必须为用户提供个性化的推荐服务。目前常用的个性化推荐算法有:基于内容的推荐算法、基于关联规则的推荐算法和基于协同过滤的推荐算法。在实际应用中,各算法都存在一定的局限,为了发挥各算法的优势,可以采用个性化的“混合”推荐服务。
电子商务网站;个性化推荐算法;混合推荐服务
中国互联网络信息中心发布的《第38次中国互联网络发展状况统计报告》显示,截至2016年6月,中国网民总规模达7.1亿,人均周上网时长26.5小时;网络购物用户规模达到4.48亿,较2015年底增加3448万,增长率为8.3%。2015年发布的同期数据显示,当年的网络购物用户较2014年增长3.5%。从这些数据可以看出,越来越多的网民喜欢通过网络购物平台采购所需商品,究其原因无非就是因为网络的便捷性与选择的多样性。而有需求就有发展,随着电子商务网站的急速发展,网络购物平台的商品数量呈现爆炸式增长,商品数量的急剧增加在为用户提供更多选择的同时,也增加了用户选到心仪商品的难度。如何帮助用户快速找到自己喜欢的物品,提升用户的使用感受就成了电子商务网站关注的热点。目前普遍采用的方法为搜索引擎,搜索引擎可以根据用户的搜索过滤大量的信息,但是返回结果是大众化的,仍然需要用户花费大量时间对返回结果进行浏览辨别。为了提高用户的搜索效率,就需要对用户进行个性化的推荐。
一、个性化推荐服务的流程
个性化推荐服务主要是基于用户的历史行为记录以及用户的原始信息,预测用户感兴趣的产品,并为用户的购买行为或网页浏览提供建议的服务。个性化推荐服务一般包含三个模块:历史信息采集模块、推荐算法模块、用户寻求推荐模块。其通用流程如图1所示。从流程图可以看出,推荐算法模块是个性化推荐服务的核心。推荐算法其实就是从用户的历史行为记录以及用户的原始信息中深层次挖掘出用户的偏好信息、个性化信息,并从中提取用户的潜在兴趣因素。
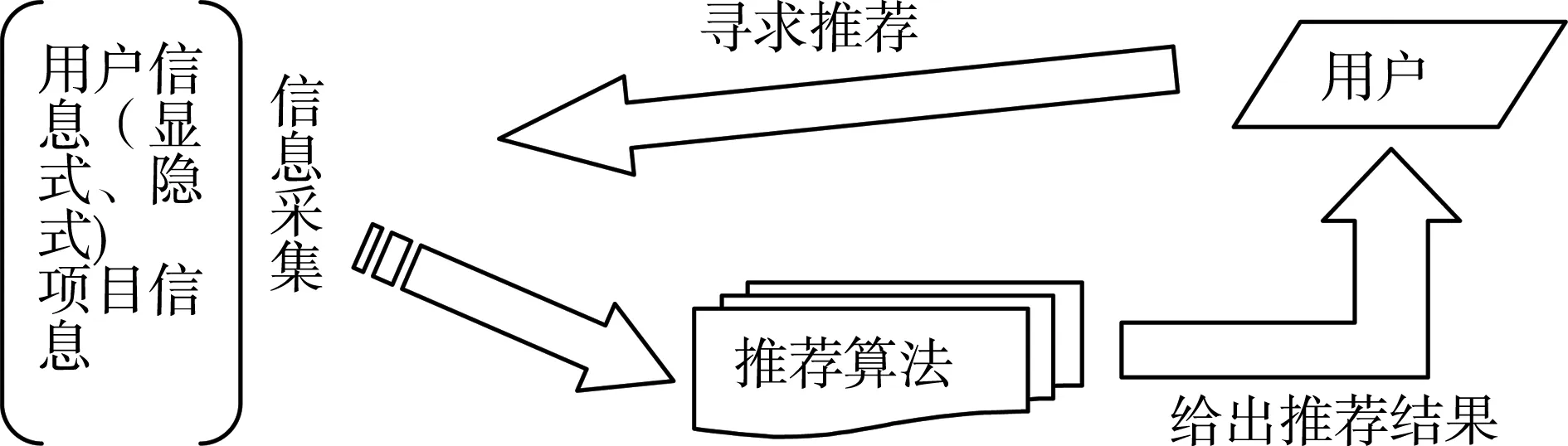
图1 个性化推荐服务的流程
二、常用的三种推荐算法
常用的推荐算法主要包含基于内容的推荐算法、基于关联规则的推荐算法与基于协同过滤的推荐算法。
(一)基于内容的推荐算法
基于内容的推荐算法,是利用用户的兴趣偏好属性与待推荐项目的特征属性的相似度进行推荐。该推荐算法首先建立用户与项目的特征属性集,采用向量空间模型得到用户与项目特征属性的稀疏矩阵集,再依据余弦相似度为用户提供推荐结果。假设第k个用户的特征属性集为Ck={wk1,wk2,…,wkr},第t个项目的特征属性集为Dt={dt1,wt2,…,wtr},这里的r是指项目与用户特征属性集中的关键词个数。余弦相似度就为
cos(Ck,Dt)值越高说明第k个用户与第t个项目的相似度就越高,共同属性就越多。也就是说,第k个用户也就越喜欢第t个项目,据此可以得到用户与所有待推荐项目的余弦相似度,采用TOP—N的方法进行推荐即可。
基于内容的推荐算法,其优点为可解释性强;不需要用户的评分数据,只需建立特征属性集;对于项目而言不存在冷启动的问题(不存在新项目无法获得推荐的问题)。其缺点为特征属性集需要从用户的描述与项目的表述中提取关键词,并不是所有项目都可以提取关键词,比如音乐、影视等项目是无法通过分词的办法提取关键词的;对于没有任何记录的新用户,因为没有数据可用,也就无法推荐;不可挖掘用户新的兴趣点(因为所有推荐项目都与用户的已有资料相匹配)。
(二)基于关联规则的推荐算法
基于关联规则的推荐算法,是从大量的数据中挖掘出项目间有意义的联系,再通过这种联系对用户进行推荐。项目间的这种联系可以用关联规则或频繁项集的形式来表示。该推荐算法的关键就是要发现频繁项集,建立关联规则。“啤酒与尿布”就是关联规则的推荐算法中非常经典的实例。
设待推荐项目总数为N,待推荐项目表示为ti,i为1到N中的正整数,表示各个项目的编号。用户的一次浏览或购买构成一个条目记为Sj,j表示该网站的浏览或者购买累计次数,取值为正整数,则Sj={ti|i为所购项目的编号}。由此构建所有历史条目的二元数据矩阵M,即以待推荐项目为列,以每个购买条目为行,交叉处的元素cij为0或者1,0表示第i个条目没有购买第j个货物,1表示第i个条目购买了第j个货物。

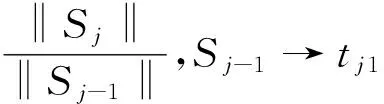
显然,基于关联规则的推荐算法不需要分析用户的兴趣偏好、物品的特征属性,仅通过用户的浏览与购买行为即可进行推荐,但是其推荐为共性推荐,忽略了用户的个性特点;随着数据量的累积,运算开销太大;对于新的物品,因为没有用户的购买数据,所以无法进行推荐,即存在冷启动的问题。
(三)基于协同过滤的推荐算法
基于协同过滤的推荐算法,是目前应用最多的推荐算法,其基本思想是利用群智对信息进行过滤筛选,分为基于近邻的协同过滤推荐算法与基于模型的协同过滤推荐算法。基于近邻的协同过滤推荐算法建立在用户以前有相同的爱好,以后也有相同的爱好这一假设之上,主要是利用用户的历史信息(注册信息、浏览信息、评分数据等)分析用户的兴趣爱好,并寻找与用户兴趣爱好相似的用户群,再根据相似用户群的选择对用户进行推荐,目前有基于用户的协同过滤推荐算法与基于项目的协同过滤推荐算法。
基于用户的协同过滤推荐算法是根据用户对项目的评价信息,计算用户间的相似性,并依据相似性寻找用户相似群即用户邻居群,再根据用户邻居群对项目的评价信息预测用户的偏好,并为用户进行推荐。该推荐算法有三个关键步骤:用户评价信息描述、用户邻居群构建、生成推荐。
用户对项目的评价信息可以通过用户—项目矩阵进行描述,设用户集合为U={u1,u2,…,um},
项目集合为
I={i1,i2,…,in},
rij,(i=1,2,…,m;j=1,2,…n),
表示用户ui对项目ij的评价,由rij所生成的m×n的矩阵就是对用户评价信息的描述。用户邻居群的构建主要依赖于用户间的相似性,用户的相似性可以采用余弦相似度与皮尔森相似度来衡量,皮尔森相似度为

利用预测的评分进行TOP—N推荐。
基于项目的协同过滤推荐算法根据用户对项目的评价信息,计算项目间的相似性,并依据用户的偏好(已购买的物品或点击过的页面)预测用户对各项目感兴趣的程度,再根据用户的兴趣度为用户进行推荐。该推荐算法主要依赖于项目的相似度与用户的兴趣度计算。
项目相似度的计算有多种方法,项目i,j的相似度较为直观的一种算法为
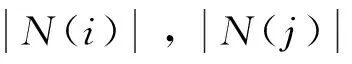
Ruj表示用户对项目j的兴趣度,可以将其简化为1。最后依据Pui对用户进行TOP-N的推荐。
基于协同过滤的推荐算法与基于关联规则的推荐算法一样,都不依赖于项目属性与用户自身的数据信息,不会对用户的推荐体验带来负面影响。但是基于协同过滤的推荐算法需要利用用户的历史数据或评价信息来推荐,若用户的历史数据较少或与其他用户的重叠数据较少时会影响评价的准确性,同时基于协同过滤的推荐算法对新用户与新项目是没有办法进行推荐的。
三、个性化的混合推荐算法
(一)个性化的混合推荐算法及应用
为了提高推荐的准确性,改进各个算法中的缺陷,建议依据历史数据的多少将用户分为老用户(有较多的历史数据)、次新用户(有少量的历史数据)、新用户(没有历史数据)三类,分别适用不同的推荐算法。对老用户采用基于协同过滤的推荐算法进行个性化推荐,次新用户采用基于关联规则的推荐算法进行推荐,只要数据积累到一定数量即可转为老用户进行个性化推荐;新用户采用基于内容的推荐算法,主要是热点推荐,只要新用户有所选择便是次新用户,采用关联规则推荐算法对其进行推荐。对用户的推荐流程如图2所示。新项目的推荐采用简化的基于内容的推荐算法,根据用户的历史数据都可以为用户设定标签,计算新项目与用户的相似性,选择相似性较高的项目,作为TOP-N中的待选项目推荐给用户。
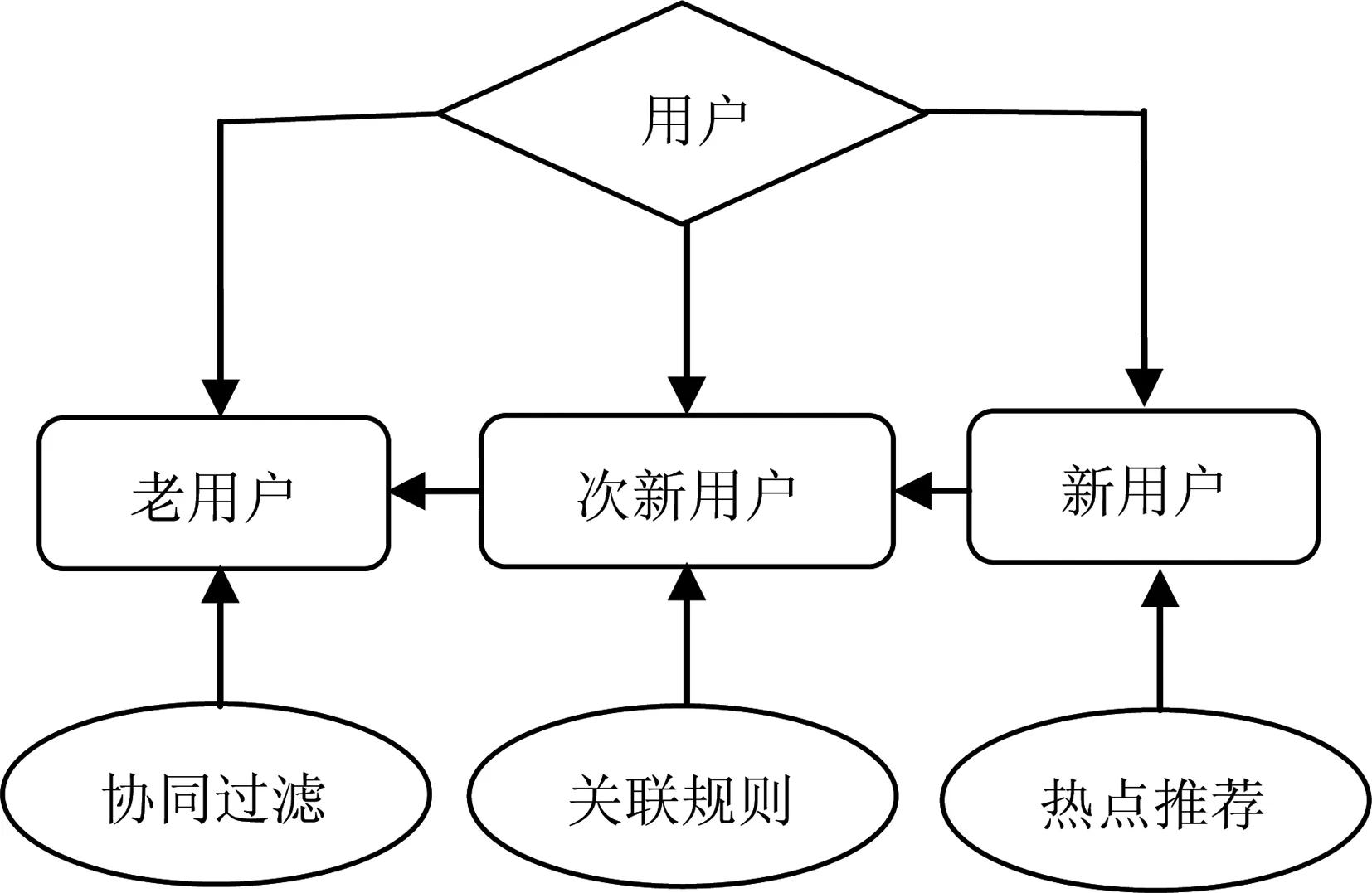
图2 混合推荐流程图
利用此混合推荐算法对某网站的客户进行推荐,主要分析步骤为:获取用户访问网站的原始记录;对数据进行预处理,包括数据去重、数据变换、属性规约、属性变换等;对比多种推荐算法,采用混合推荐算法对用户进行个性化推荐,即第一次登陆网站的用户采用内容相关的热点推荐,一旦用户有点击则采用基于关联规则的推荐对用户进行推荐;老用户采用基于协同过滤的推荐算法对其进行推荐。分析流程如图3所示。
在对数据的探索过程中,发现约有1/4的网站用户只登陆了网站的首页,而没有浏览其他页面,这部分用户应该是通过搜索引擎进入网站,在网站的导航页面没有找到所需要的内容而退出网站的;同时也说明网站原有的基于内容的新品推荐不能满足用户的需求。采用混合推荐算法中的对待新用户的推荐策略,利用基于内容的热点推荐与现有的社会热点或时事热点结合,可以留存部分用户。一旦用户浏览推荐页面,即为次新用户,可以采用关联规则的推荐算法对其进行较为个性化的推荐。因为关联规则模型中的最小支持度与最小置信度取值越大,事物之间的联系也就越密切;满足条件的频繁项集也就越少。当然频繁项集的多少也与数据量的大小有关,对于次新用户的推荐经过多次调整,最后选取模型最小支持度为0.6%,最小置信度为65%的频繁项集给出推荐结果。

图3 混合推荐算法流程图
对于老用户采用协同过滤推荐算法进行个性化的推荐,因为该网站的网页数明显少于用户数,所以采用基于项目的协同过滤推荐算法。丰富的历史数据可以提高推荐准确度,利用协同过滤推荐算法对老用户进行推荐时,发现部分用户没有推荐结果,主要是因为用户的浏览量较少所致,对这部分用户仍然采用次新用户的推荐结果进行推荐。
(二)推荐算法评价
为了对比个性化推荐算法与非个性化推荐算法的结果,通过两种非个性化的算法:随机推荐算法、热点推荐算法和个性化的算法:基于项目的协同过滤算法来对数据进行建模并对模型进行评价与分析。
数据中用户行为是二元选择(有浏览、无浏览),对用户的推荐也就是一个二分问题。二分问题中,常将实例分为正类(positive)与负类(negative),预测中会出现四种情况,即正类被预测为正类(真正类Truepositive)、负类被预测为正类(假正类Falsepositive)、负类被预测为负类(真负类Truenegative)、正类被预测为负类(假负类Falsenegative)。可用表1来表示。

表1 二分问题的分类
二分问题的预测常用准确率(P)、召回率(R)、真正率(TPR)、假正率(FPR)作为评测指标,其中
由公式可以看出准确率就是预测正确的实例占总实例的比例;召回率是正类中预测正确的实例占预测为正类实例的比例;真正率又称为灵敏度,是正类中预测正确的实例占正类实例的比例;假正率是负类中预测为正类的实例占负类实例的比例;除了假正率外,其余的准确率、召回率、真正率都是值越大越好,假正率是越小越好。
对于推荐算法的评价采用离线测试的方法来获取,选择准确率(P)、召回率(R)、真正率(TPR)、假正率(FPR)作为评测指标。
对三种推荐算法,选择不同K值(推荐个数,K取3、5、10、15、20)的情况下进行模型构造,得到评测指标准确率、召回率、真正率(TPR)、假正率(FPR),并绘制出ROC(真正率-假正率)曲线如图4所示。从ROC曲线可以看出,不管K取何值时基于项目的协同过滤推荐其真正率比其他两种非个性化推荐取值都要高,假正率比非个性化推荐的取值都低,这说明个性化的推荐基于项目的协同过滤推荐优于随机推荐与热点推荐。同时又注意到随机推荐与热点推荐的假正率取值接近,但是随机推荐的真正率要比热点推荐的真正率低得多,所以热点推荐优于随机推荐。
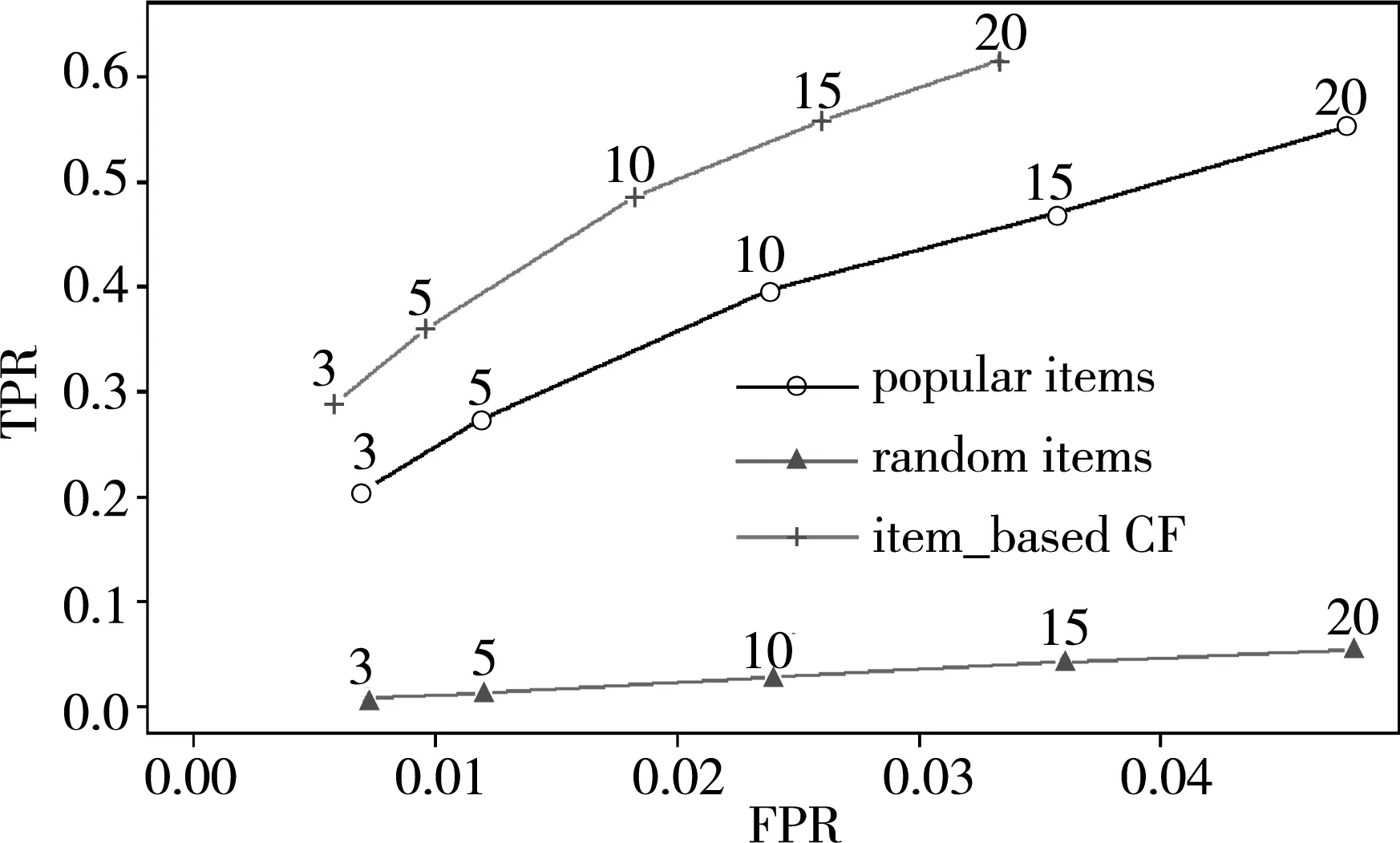
图4 ROC曲线
四、结语
综上所述,个性化的“混合”推荐算法具有一定的优势,它能够改进协同过滤推荐算法中的数据稀疏性问题,同时可以利用协同过滤推荐的个性化及精准性为用户进行推荐;可以有效改进冷启动问题,使每一位用户都有推荐项目;有效利用特征属性的提取对新项目进行推荐,使特征属性的提取最小化。
但是,该算法不能改善协同过滤算法的可扩展性的问题。
[1]中国互联网信息中心.第38次中国互联网络发展状况统计报告[DB/OL].http:∥www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201608/t20160803_54392.htm,2016-10-6.
[2]何佳知.基于内容和协同过滤的混合算法在推荐系统中的应用研究[D].上海:东华大学,2016.
[3]张同启.基于关联规则及用户喜好程度的综合电子商务推荐系统的研究[D].北京:北京邮电大学,2014.
[4]Pang-NingTan,MichaelSteinbach,VipinKumar.数据挖掘导论[M].范明,范宏建,译.北京:人民邮电出版社,2011.
[5]博客频道.基于物品的协同过滤算法[DB/OL].http:∥blog.csdn.net/yeruby/article/details/44154009,2017-2-17.
[责任编辑 文 川]
2017-03-24
重庆第二师范学院“青年教师成长支持计划”(201605);重庆市教委科研项目(KJ1501414)
蔡银英(1976— ),女,山西运城人,副教授,研究方向:概率论与数理统计。
O244
A
1008-6390(2017)04-0122-05
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
文苑(2020年4期)2020-05-30 12:35:12
当代陕西(2019年15期)2019-09-02 01:52:00
汽车观察(2019年2期)2019-03-15 06:00:50
新闻传播(2018年12期)2018-09-19 06:27:10
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
汽车与新动力(2016年6期)2017-01-04 10:50:48
中国卫生(2016年5期)2016-11-12 13:25:26
中国卫生(2015年1期)2015-01-22 17:20:15
