
MPEG-1 Layer2双声道定点音频编码器的硬件设计∗
2017-08-01 13:49史伟伟赵光东徐渊易子林周德福
计算机与数字工程 2017年7期
史伟伟 赵光东 徐渊 易子林 周德福
(深圳大学信息工程学院深圳518000)
MPEG-1 Layer2双声道定点音频编码器的硬件设计∗
史伟伟 赵光东 徐渊 易子林 周德福
(深圳大学信息工程学院深圳518000)
MEPG-1 Layer2音频编解码在数字视音频广播领域有着广泛的应用。现有的MEPG-1 Layer2音频编码方案大多在DSP/CPU平台上用软件方式实现,算法本身实现起来复杂,且浮点数的运算本身占用更多的CPU资源,要实现实时性更多的依赖CPU的性能。论文采用全硬件的设计方法,设计实现了MEPG-1 Layer2双声道音频编码器,简化了算法的复杂度且实现了定点数的运算,使用Xilinx提供的ISE完成verilog代码的编写与综合,第三方软件Modelsim完成各功能模块的仿真,在VC707上完成验证,和MEPG-1 Layer2的音频软件编码相比实时性更好,资源使用更少。
MEPG-1 Layer2;modelsim;实时;verilog
Class NumberTN912.3
1 引言
由于数字计算机和数据网络的发展,数字音频技术也被应用于越来越多的消费类电子产品和一些专业设备。为了减少音、视频数据的存储空间和传输时占用的网络带宽,MEPG(Moving Pictures Expert Group)提出的相关标准,如MEPG-1、MEPG-2等,已经被广泛采用。根据不同的应用,MEPG-1和MEPG-2的音频编码采用的分层编码的方法,分为三个层,依次为layerⅠ(mp1)、layerⅡ(mp2)和layerⅢ(mp3),从layerⅠ到layerⅢ,编码的复杂程度和压缩率依次增加[3]。MP2均衡了性能和复杂度,它能在192Kbps~256Kbps的速率下实现CD级的音质,MP2音频编码算法在数字电视等领域广泛采用的编码算法,目前已经有专用的芯片来实现音频编码,但大多基于DSP/CPU的平台用软件的方式实现编码,本论文基于FPGA硬件可编程且可并行加速的特点实现MP2双声道定点音频编码的硬件设计,并完成相关的验证工作。
MPEG虽然提出了相关的标准,但对MP2音频编码算法的具体实现并未做出明确的指定,本论文基于MPEG的协议,用硬件实现MP2双声道音频编码算法,并对该算法进行了优化。
2 MP2音频编码过程
MP2音频编码原理如图1[1]所示。PCM音频采样数据输入到编码器,经过编码器的滤波模块(Fil⁃ter bank)并划分为32个等间距的子带,每个子带取36个样本,以12个样本为一组计算比例因子,计算出来的比例因子和心理声学模型(Psychoacoustic Model)计算出的信掩比(Signal to Mark Radio,SMR)经过比特分配模块(Bit or Noise Allocation)对采样数据进行量化和编码,量化和编码后的数据再经过成帧模块(Bitstream Formatting)形成一定格式的比特流输出。
以往的做法通常是基于DSP/CPU的方式软件实现MP2音频编码,本文基于FPGA硬件可编程且可并行加速的特点实现MP2双声道音频编码,并实现了定点数的运算。由于协议本身采用了浮点运算,浮点数到定点数的过程涉及精度的问题,精度问题直接关系到编码后音质的好坏。所以本文采用Matlab对浮点数进行精度确定,在保证音质的前提下还可利用Matlab把相应数据制成表,基于查表的方式来简化算法复杂度。

图1编码器原理图
2.1 滤波模块
子带滤波器的经典算法的流程如图2[1]所示

图2子带分析滤波器的经典算法流程图
本文中输入样本做了定点化的处理,样本数据由16bit组成,存放于深度为512的缓冲区,最先输入的数据放在最低位,并把旧的32个样本移除,采用经典的碟形算法,大大简化了算法的复杂度。其中存放数据的缓冲区在每帧开始时并不做初始化处理,硬件实现时容易出错。系数C是一个窗函数系列,可事先定点化后存于表中,系数M如式(1)所示:

其中i=0~63,k=0~31;M也可做相应的定点化处理,子带滤波部分大量的运算集中在系数S上,对系数M和Y的定点化处理简化了滤波模块的复杂度,滤波后样本被划分为等间距的32个子带。
2.2 比特分配
开始比特分配前首先由滤波出来的32个带,每个子带取36个样本,每12个样本进行一次计算,由12个样本中最大的值决定比例因子的值,这样每个子带就有3个比例因子,再计算出相邻两个比例因子的差值,通过查表决定对应的比例因子,同时决定比例因子选择信息(scfsi),比例因子选择信息的含义见表1[1]。音频编码是基于声学模型利用人耳听觉系统的感知特性去掉音频中一些不被感知的细节达到压缩的目的的[7],所以滤波出来的子带不是每个都需要编码,需要编码的子带比特数也不尽相同,所以由比例因子选择信息来指代哪些子带需要编码,编码的位数由声学模型计算出来的信掩比决定。

表1 比例因子选择信息的含义
比特分配的原则是要把每帧的总体噪声掩蔽减到最小,即使各子带得量化噪声尽量处于对应的掩蔽阈值以下,并且控制所用的比特数不超过该帧可用的总比特数,这种对每个子带的取样值进行降低数据率的编码方案进行的比特编码,即动态比特分配,MP2编码中对于子带号大于26的所有子带分配的比特数为0,它们是不在数据流中出传送的[5]。
比特分配是一个迭代的过程,每次迭代都使得总比特数尽可能地被利用。首先,由声学模型计算出信掩比(SMR),再由信噪比(SNR)减去信掩比(SMR)得到掩蔽比(MNR),选择相邻两个子带之间的较大者的掩蔽比作为最终的掩蔽曲线;如果第一次分配给子带的比特数非零,那么必须更新比例因子比特数,该子带的比例因子选择信息的比特数也要根据该子带所需的比例因子比特数来进行更新,这样每迭代一次就可以更新一次掩蔽曲线,最终掩蔽曲线接近人耳的掩蔽阈时迭代结束,即比特分配结束。在每一次迭代中,使超出掩蔽曲线最高的量化噪声的值降低,即对该量化噪声对应的子带分配更多的位数,在比特率完全足够的情况下,所有的量化噪声降至掩蔽曲线以下就可以了,如比特率受限制,不能使所有的量化噪声都降至掩蔽曲线以下,则重新开始迭代,直到分配满给定的总比特数。在迭代的每一步都找出具有最小掩蔽噪声的子带,使它分配更高的比特数。
2.3 子带样点的量化和编码
子带样点的量化采用具有对称零表示的线性量化器,这样可以防止围绕零变化的较小值被量化为不同级,每一个样点都要进行归一化处理,量化步骤如下:
1)计算AX+B;
2)提取N位有效位;
3)将此数中最高为取反。
其中X为子带样本除以比例因子的值,A、B通过查表可得,最高位取反是为了避免全“1”的码子。MPEG-1 Lyaer2编码中不同的频段提供了不同的量化等级,低频子带15个,中频提供7个,高频3个,这些可能的量化级包括3、5、7、9、15、31、63、…、65535。为进一步减小编码的比特数,对处于3、5、9的量化级的样点进行分组,即将三个连续的样本有一个码子编码,对这三元组只传送一个值Vm(m=3、5、9),Vm和这三个连续样点x,y,z之间的关系为:

2.4 心理声学模型[6]
基于掩蔽效应的心理声学模型是MPEG-1音频标准得以实现数据压缩的理论基础[2]。11172-3给出了两种不同的声学模型,每种模型实现都有不少的困难,对于一般的编码器来说在低比特率下可以把声学模型当作一个常数模型,这样不仅可以简化算法的复杂度,而且不影响人耳听觉,所以本文采用了常数模型来替换声学模型,声学模型最终输出的信掩比SMR(Signal to Mask Radio)如下。

3 MP2音频编码及仿真验证
本文对各功能模块完成划分,对每个模块用verilog进行设计实现,modelsim完成设计的各个功能模块的仿真,比例因子及比例因子选择信息仿真图如图3所示,32个子带,每个子带3个比例因子(doutb_scalar_1_2_1、doutb_scalar_2_2_1、doutb_ scalar_3_2_1)和1个比例因子选择信息(scfsi)。比特分配仿真图如图5所示(doutb_bit_alloc、doutb_bit_alloc_second_ch分别为左声道和右声道比特分配),该帧只有17个子带需要编码,限于篇幅这里只给出了第一帧的仿真数据。输入音频数据采样率为44.1Khz,每个音频样本用16bit表示,如图4上,在主频为200MHz的VC707上下板验证,码流如图4下右边所示,完成一帧编码需要12ms,而开源的c代码在主频为3.1GHz处理器为酷睿i7的PC上完成同样一帧用时0.2ms(取十次的平均值),码流如图4下左边所示。

图3比例因子及比例因子选择信息

图4输入数据及软硬件编码结果

图5比特分配
在精度有损的情况下,硬件编码结果与软件编码结果能达到同样的效果,编码后的码流在一定的精度范围内软硬件结果完全一致,在用时上硬件有较明显的优势,完全能实现实时,而软件更多地依赖CPU的性能。
MP2音频编码资源使用情况如表2所示,xilinx提供的ise下综合结果。
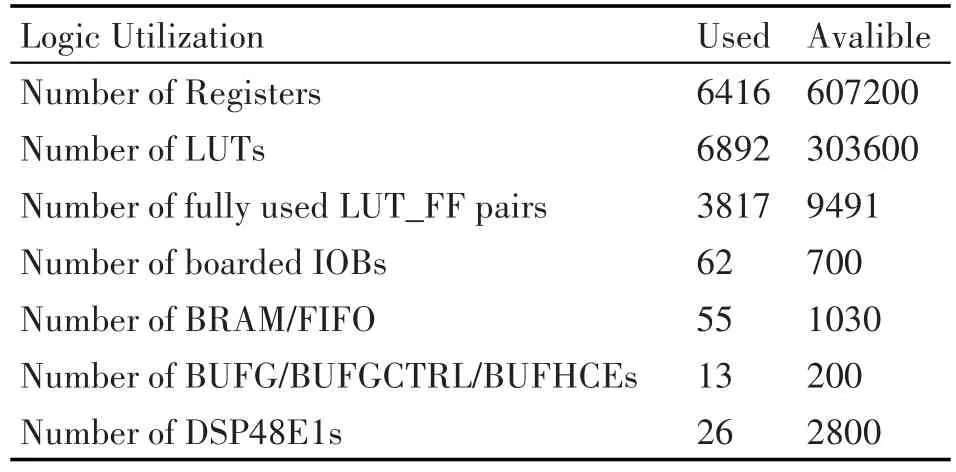
表2 音频编码资源使用情况
MP2音频编码在VC707开发板上完成验证,验证平台如图6所示,microblaze为xilinx提供的可配置的RISC精简指令集软核CPU[8],采用哈佛结构,DDR为外部存储器,用来存储音频数据和编码后的数据,MP2编码模块当作一个IP核挂到AXI总线上并通过AXI总线实现和microblaze的互连,组成一个小型系统。

图6MP2音频编码验证平台

图7编码前后MP2频谱图
编码前后的MP2频谱图如图7所示,同一个wav文件编码前后进行对比可以看出,定点前后引入的误差很小,人的耳朵基本分辨不出,达到了压缩的目的,同时保证了音质[9]。
4 结语
本文采用硬件的方式在精度有损的情况下实现定点MP2双声道音频编码,最终编码结果能与软件完全匹配,并且本文对算法进了行优化,基于查表的方式简化了算法本身的计算量,在晶振为200MHz的VC707板子上验证了设计的实时性,和软件实现相比具有明显的速度优势,而且就算法本身来说简化了心理声学模型,算法的复杂度明显降低,基于查表的方式也大大降低了硬件的计算时间,同时硬件本身的并行性也利于编码的实时性。本设计资源使用率并不是很好,还有待提升,但本论文的硬件MP2编码实现为MPEG-1 Layer2音频编码硬件IP核的SOC整合应用打下了基础。
[1]ISO/IEC 11172-3:1993,Information technology–Coding of moving pictures and associated audio for digital storage media at up to about1.5Mbit/s,1993.
[2]潘逸.MPEG-1 Layer2音频解码器的硬件设计和仿真[D].上海:上海交通大学,2006. PAN Yi.Hardware design and simulation of audio decoder of MPEG-1 Layer2[D].Shanghai:Shanghai Jiao Tong University,2006.
[3]汪文,谢智学.实时MP2音频编码算法的优化设计[J].计算机与数字工程,2008,36(7):24-26. WANG Wen,XIE Zhixue.An optimization implementa⁃tion for mp2 real-time audio encode[J].Computer and Digital Engineering,2008,36(7):24-26.
[4]杨兆选,周延献.感知音频编码算法研究[D].天津:天津大学,2011. YANG Zaoxuan,ZHOU Yanxian.Research of Perceptual Audio Coding Algorithm[D].Tianjin:Tianjin University,2011.
[5]王国裕,高博.MPEG音频编码算法的研究和VLSI前端设计[D].成都:四川大学,2003. WANG Guoyu,GAO Bo.The Implementation of MPEG au⁃dio coding algorithm And the Design of VLSI Front End[D].Chengdu:Sichuan University,2003.
[6]朱丽,郭从良.心理声学模型在数字音频中的应用[J].电声技术,2002(8):11-14. ZHU Li,GUO Congliang.Psychoacoustic Model Used InDigital Audio[J].Audio Engineering,2001(8):11-14.
[7]刘丽,郭立.音频压缩编码中参数比特分配算法的研究和实现[J].微电子学与计算机,2008,25(2):160-163. LIU Li,GUO Li.Research and Implementation on Para⁃metric Bit Allocation Algorithm in Audio Compression Coding[J].Microelectronics and Computer,2008,25(2):160-163.
[8]何宾.基于AXI4的可编程SOC系统设计[M].北京:清华大学出版社,2011. HE Bin.AXI4-Based SOC Programmable System Design[M].Beijing:Tsinghua University Press,2011.
[9]梅猛,刁鸣.MP2实时音频编码的定点化及优化设计[EB/OL].http://www.paper.edu.cn/releasepaper/content/ 201310-212. MEI Meng,DIAO Ming.MP2 real-time audio encoding de⁃sign and optimum of fied point[EB/OL].http://www.paper. edu.cn/releasepaper/content/201310-212.
[10]孟哲,杨杰.基于DSP的MPEG-2音频实时压缩编码算[J].武汉理工大学学报,2002,24(3):63-65. MENG Zhe,YANG Jie.MPEG-2 audio compression al⁃gorithm of real-time based DSP[J].Journal of WOT,2002,24(3):63-65.
Two-channel Audio Encoder with Fixed-point of MEPG-1 Layer2 by Hardware
SHI WeiweiZHAO GuangdongXU YuanYI ZilinZHOU Defu
(College of Information Engineering,Shenzhen University,Shenzhen518000)
MEPG-1 Layer2 audio coding and decoding has a wide use in the field of DAB and BVB.The majority of existing MEPG-1 Layer2 audio coding methods are realized by software on DSP/CPU platform.Those approaches are complex to implement,while the floating-point operations consume more CPU resources.What's worse,to achieve real-time performance mainly depends on the performance of CPU.In our algorithm,hardware implement is adopted and two-channel audio encoder of MEPG-1 Layer2 is presented and realized.It simplifies the complexity of the traditional algorithms and implements the fixed-point number operations. The verilog coding and synthesis is completed by ISE provided by Xilinx and the simulation of each function module is done via mod⁃elsim.The algorithm is verified in VC707.The experimental result demonstrates that the presented method holds better real-time per⁃formance and fewer resources are employed compared to the previous algorithms.
MEPG-1 Layer2,modelsim,real-time,verilog
TN912.3
10.3969/j.issn.1672-9722.2017.07.045
2017年1月14日,
2017年2月25日
史伟伟,男,博士,讲师,研究方向:超低功耗数字集成电路设计及定制化逻辑电路设计。赵光东,男,硕士,研究方向:视频图像处理方面。徐渊,男,博士,讲师,研究方向:面向视频处理的SOC芯片设计。易子林,男,硕士,研究方向:视频图像处理方面。周德福,男,硕士,研究方向:视频图像处理方面。
猜你喜欢
信号处理(2022年4期)2022-05-13
空间电子技术(2021年4期)2021-11-10
家庭影院技术(2021年1期)2021-03-19
电子制作(2019年22期)2020-01-14
家庭影院技术(2018年11期)2019-01-21
雷达科学与技术(2018年6期)2019-01-07
电子制作(2018年19期)2018-11-14
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
银行家(2017年1期)2017-02-15
