
利用GATE的XML配置文件实现病历短语抽取的机器学习方法
2017-07-24 15:06倪晓华
中国医疗设备 2017年7期
倪晓华
南京医科大学第二附属医院 信息科,江苏 南京 210011
利用GATE的XML配置文件实现病历短语抽取的机器学习方法
倪晓华
南京医科大学第二附属医院 信息科,江苏 南京 210011
本文利用文本工程通用框架软件的XML配置文件,来指定所学文档使用的特征参数、学习算法,实现文本病历医学短语抽取的机器学习。结果计算机能很方便的在大段病程资料中快速自动获取医生所需的医学短语信息。本学习算法具有较好的实用性,达到了预期要求。
电子病历;机器学习;通用框架软件;支持向量机
引言
电子病历(EMR)是指医务人员在医疗活动过程中使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录。但它们不是完全结构化的数据(如病程记录),这种文本信息方便表达概念以及事件等,是临床治疗过程的主要记录形式,却不适宜数据的查询或统计。近年来随着医院病历逐步的电子化,使得大规模病历的自动分析成为可能。患者的疾病和症状、治疗过程和治疗效果,这些信息是重要的临床证据,将这些信息高效精确地收集起来辅助医生决策是很有意义的[1-11]。本文利用文本工程通用框架软件(General Architecture for Test Engineering,GATE)[12]的应用实例组件、批处理学习进程资源,来实现EMR记录中短语抽取的机器学习[13-14]。结果表明,机器学习信息抽取的结果符合预期要求,具有较好的准确性和实用性。
1 机器学习概述
机器学习是一门多领域交叉学科,专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。而在机器学习领域,支持向量机是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。该学习模型可以从给定的训练数据集中学习出一个函数,当新的数据到来时就根据这个函数预测目标。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标,训练集中的目标是由人标注的。监督学习主要应用于分类和预测,尤其在自然语言处理时被更加广泛的应用。本文在中使用到的机器学习方法是一个有监督的学习模型Gate,为了使用监督机器学习,可以通过手动注释NLP文档[12-15]或从其他资源获得一些标签数据,还需要确定哪些语言特征是用于训练(同样的功能也应该在应用程序中使用)。在这里要实现机器学习的功能是所有的机器学习属性都必须是Gate注释的特性。
2 电子病历短语抽取机器学习的方法
抽取短语机器学习的过程是:① 标签注释;② 确定语言特征;③ 用JAPE脚本生成想要实现的功能。
(1)脚本创建规则。本例是抽取病人入院原因短语的程序,使用脚本如下:
Rule:ru //创建规则
(
{Token.string == “因”} //读取字符“因”
({Token})[1,20] //读取后面1到20个字符,可自动调整
{ Token.string == “入院”} //读取字符“入院”
):ru
-->
:ru.Ru = {rule = “Ru”} //输出含特征的结果
短语抽取的结果,见图1。

图1 利用Gate实现的医学短语抽取
病人入院原因是病人住院前的主要症状,对医生的诊断起引导作用,是非常重要的病程描述。从大量的病程记录中快速识别出来,可以高效精确地收集证据来辅助医生决策。其他短语,如现病史、既往史、症状都可通过类似的方法实现。
(2)为短语机器学习创建XML配置文件。该文件应包含一个数据集,用来指定所使用的NLP特征,如Token、Lookup、major Type。一个指定学习算法的元素需进行必要的可选设置。
短语机器学习的类由一个单独的注释类型形式提供,如“Ru”包含一个特征“类”。
<ATTRIBUTE> \ 定义被训练的注释数据
<NAME>Class</NAME> \ 特征的名字
<SEMTYPE>NOMINAL</SEMTYPE> \ 特征值的类型,目前只支持NOMINAL
<TYPE>Ru</TYPE> \ 用于抽取特征的注释类型
<FEATURE>rule</FEATURE> \ 具体的抽取特征值
<POSITION>0</POSITION> \ 相对于当前的实例注释,用来抽取特征的实例注释位置
<CLASS/> \ 类的标志
</ATTRIBUTE> \ 注释数据的标志
这就是机器学习的输出程序,其他注释包括运行参数“Token”和“Lookup”。所有这些注释在相同的注释集合中,它们将作为运行时的参数传递。
配置文件中有一部分是数据集子元素,定义为所使用的语言特征。首先把“字符”注释作为第一个实例,其特征是字符串,如<RANGE from=“-5” to=“5”/>从“- 5”到“5”的范围意味着当前的字符,以及它5个前面的字符和它的5个随后的字符将被用作当前字符实例的功能,使得周边词在信息抽取中的作用明显,当为5时可使系统的性能表现最佳。
(3)预处理新文档。用与培训文档相同的方式预处理新文档,以确保相同的特征(类标签不需存在)。将学习模型设置为应用程序并在此语料库上运行PR,应用程序结果被添加到指定的注释集中。参数设置操作界面,见图2;字段抽取结果,见图3。
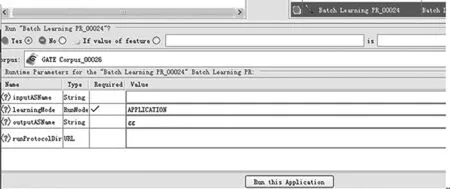
图2 应用程序参数配置图

图3 机器学习字段抽取结果
比较图1和图3,可以发现图3的CC中无规则Ru。这意味着对于新文档,使用的是机器学习的方法实现入院原因短语的抽取,而不是JAPE脚本生成的规则。机器学习的结果体现在输出函数指定的注释集中,结果是可接受的。最主要的是对于大量的电子病历病程来说,能让计算机学习需要抽取的内容,大大方便了医生,同时为病人病程的查询、辅助决策提供支持。
3 结果
本文使用3种评价指标[15]:准确率(P)、召回率(R)、F值(F-Score)来评估短语抽取的效果,这些指标也是目前抽取任务所普遍采用的。P与R是检索和分类系统中最常用的两个度量值。P也称查准率,指系统判断正确的正例个数与判断为正例的总实例数的比率;R也称查全率,是指系统判断正确的正例个数与语料中包含的所有正例数的比率。F值,对一个分类系统来说,准确率和召回率往往不能两全,是相互制约的,通常用准确率和召回率的调和平均数F值来衡量系统的整体性能,是信息检索领域一个常用的评价指标。本文机器学习抽取入院原因的P=94.59%,R=93.33%,F=93.96%。
[1] Fan J,Kalyanpur A,Gondek DC,et al.Automatic knowledge extraction from documents[J].J Res Dev,2012,56(4):501-510.
[2] Uzuner O,Solti I,Cadag E.Extracting medication info-rmation from clinical Text[J].J Am Med Inform Assoc,2010,17(5):514-518.
[3] 原欢.基于GATE的货物动态邮件信息抽取方法与应用研究[D].南京:南京航天航空大学,2013.
[4] Ke CM,Huang FJ,Lee SS,et al.Use of data mining surveillance system in real time detection and analysis for healthcareassociated infections[J].BMC Proc,2016,(5):30-34.
[5] Tomaszewski JE,Hipp J,Tangrea M,et al. Madabhushi, machine vision and machine learning in digital pathology[J].Pathobiol Hum Dis,2016,(9):3711-3722.
[6] Taroni F,Biedermann A.Bayesian networks[J].Encycl Forensic Sci,2013,(8):351-356.
[7] Alonso AF,Rojo AJL,Rosado MA.Feature selection using support vector machines and bootstrap methods for ventricular fi brillation detection[J].Expert Syst Appl,2016,39(2):1956-1967.
[8] 徐永东,权光日,王亚东.基于HL7的电子病历关键信息抽取技术研究[J].哈尔滨工业大学学报,2011,(11):89-94.
[9] 叶枫,陈莺莺,周根贵,等.电子病历中命名实体的智能识别[J].中国生物医学工程学报,2011,(2):256-262..
[10] Bouvry C,Tvardik N,Kergourlay I,et al.The SYNODOS project: System for the normalization and organization of textual medical data for observation in healthcare[J]. IRBM,2016,37(4):109-115.
[11] Hong JL,Siew EG,Egerton S.Information extraction for search engines using fast heuristic techniques[J].Data Knowl Eng,2010,69(2):169-196.
[12] Cunningham H,Maynard D,Bontcheva K.Developing language processing components with GATE Version 8[EB/OL].http:// gateacuk/sale/tao/tao.pdf.
[13] Bisin A,Guaitoli D.Information Extraction and norms of mutual protection[J].J Econ Behav Organ,2015,84(1):154-162.
[14] Wiebe J,Riloff E.Finding mutual bene fi t between subjectivity analysis and information extraction[J].Affect Comput,2015,2(4): 175-191.
[15] Sheikh M,Conlon S.A rule-based system to extract financial information[J].J Comput Inf Syst,2015,52(4):10-19.
[16] 马续补,郭菊娥.基于GATE的任务信息抽取研究[J].情报杂志,2010,29(1):155-158.
本文编辑 韩淑英
Machine Learning Method to Realize Medical Record Phrase Extraction via Using the XML Con fi guration File of the GATE
N I X i a o-h u a
Department of Information, the Second Affiliated Hospital of Nanjing Medical University, Nanjing Jiangsu 210011, China
Based on XML con fi guration fi les of general architecture for text engineering, we speci fi ed characteristics and learning algorithm of the documents, and realized machine learning of text records phrase extraction. The result was that computer could automatically obtain the phrases that doctor required from the long course information quickly. This learning algorithm has good practicability and meets the expected demand.
electronic medical record; machine learning; general architecture for text engineering; support vector machine
TP391.1
C
10.3969/j.issn.1674-1633.2017.07.034
1674-1633(2017)07-0124-02
2016-10-25
2017-03-15
作者邮箱:nxh.2046@163.com
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
趣味(语文)(2021年9期)2022-01-18
电脑爱好者(2021年11期)2021-06-07
数学小灵通·3-4年级(2020年9期)2020-10-27
汉字汉语研究(2020年2期)2020-08-13
作文评点报·低幼版(2020年25期)2020-07-23
电脑爱好者(2020年9期)2020-07-05
电脑爱好者(2019年20期)2019-12-10
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
