
基于视觉词袋模型的羊绒与羊毛快速鉴别方法
2017-07-21 05:01:25钟跃崎朱俊平柴新玉
纺织学报 2017年7期
路 凯,钟跃崎,2,朱俊平,柴新玉
(1. 东华大学 纺织学院,上海 201620;2. 东华大学 纺织面料技术教育部重点实验室,上海 201620)
基于视觉词袋模型的羊绒与羊毛快速鉴别方法
路 凯1,钟跃崎1,2,朱俊平1,柴新玉1
(1. 东华大学 纺织学院,上海 201620;2. 东华大学 纺织面料技术教育部重点实验室,上海 201620)
为快速准确地鉴别羊绒和羊毛,提出一种基于视觉词袋模型的鉴别方法。该方法使用羊绒和羊毛的光学显微镜图像作为实验样本,将纤维鉴别问题转化为图像的分类问题。首先对光学显微镜图像进行预处理以增强特征,然后从纤维形态中提取局部特征并生成视觉单词,再依据视觉单词对纤维图像进行分类,从而达到鉴别纤维的目的。使用了4 400幅纤维图像作为数据集,从中选择不同的羊绒和羊毛的混合比作为训练集和测试集,得到的识别率最高为86%,最低为81.5%,鉴别1 000根纤维需要的时间小于100 s,训练好的分类器可保存并用于后期的检测工作。
羊绒;羊毛;视觉词袋模型;图像处理;快速鉴别
羊毛和羊绒的鉴别一直是纺织行业的难题,目前常用的鉴别方法有光学显微镜法[1]、扫描电镜法[2]、近红外光谱鉴别法[3]、DNA分析法[4]。在显微镜下观察到的动物纤维表面形态差异可用于纤维鉴别[5],但通常只有经过专业训练的专业人员才能比较准确地观察到二者的差别。Tang等[4]提出一种DNA分析的方法,采用荧光定量聚合酶链式反应(PCR)引物与探针和羊绒羊毛的线粒体12S核糖体进行反应,通过建立对数曲线来计算羊绒羊毛的混合比例。该方法客观有效,但检测过程中需要比较精密的仪器,且只能由专业人员操作,成本相对昂贵。总而言之,上述几种方法耗时长,成本高,而且往往需要专业人员操作,因此目前急需一种成本低、速度快、操作简单、精确度较高、稳定可靠的检测方法。近年来有一些基于图像处理技术的羊绒与羊毛鉴别方法[6-7],通过测量纤维表面形态的一些特征测量如纤维直径、鳞片高度、鳞片厚度等值来识别纤维,但这些特征的测量工作难度比较大,如鳞片的厚度在光学显微镜下很难检测,并且近年来羊绒和羊毛纤维变异程度很大,例如羊毛羊绒的直径等特征差异越来越小,仅仅依靠挑选几个特征已经不能满足实际工作中的鉴别需要。
视觉词袋模型在图像分类与目标检测中具有良好的效果,本文将该模型引入到纤维鉴别领域,提取显微镜图像中纤维的形态特征并依据这些特征对纤维进行分类。本文方法将纤维检测技术与计算机视觉技术相结合,从大样本中提取特征,从而达到客观、快速地鉴别纤维的目的。
1 研究方法
本文方法的思路是通过羊绒羊毛纤维的图像来提取特征,并以此鉴别2种纤维图像,这就将纤维的鉴别问题转化为纤维图像的分类问题。人们对图像分类和物体识别已经做了许多研究,在诸多方法中,视觉词袋模型(Bag-of-Visual-Word,简称BoVW)是比较受关注的方法,该方法原理简单,效果好。首先需要对获取的显微镜图像进行预处理,然后介绍如何使用BoVW模型来表示纤维的特征,接下来使用支持向量机(SVM)对纤维图像进行鉴别分类,最后通过预测结果和真实值的比较来评价识别效果。
1.1 图像预处理
图1(a)、(b)示出常见的羊绒和羊毛纤维的显微镜照片。由图可看出,二者外观形态比较接近,显然直径等单一特征已经不能作为识别依据。另外由图1可看出,2种纤维表面的鳞片边缘很不清晰,需要对图像进行增强处理。在拍摄的图像中不可避免地会出现一些气泡和杂质,这些干扰信息要尽量去除,而且还要尽可能地保留纤维有效信息。接下来的预处理过程将会增强纤维图像表面,并且可去除纤维背景。

图1 原始羊绒和羊毛显微镜图像(×500)Fig.1 Original microscope images of cashmere and wool(×500). (a) Cashmere; (b) Wool
羊绒和羊毛纤维图像的预处理过程相同,以图1(b)中的羊毛纤维为例。首先将原始图像转换为灰度图像,然后使用对比度拉伸、直方图增强和滤波增强等3种方法对图像进行增强处理。可发现,对比度拉伸算法效果更好,能使图像中纤维表面的鳞片边缘清晰度明显增强。图2示出图1(b)转化成灰度图的直方图,可看到图像中像素的灰度值集中在很小的区域,在灰度值150附近的区域,通过对100根随机挑选的纤维图像统计发现,图像95%以上的像素灰度值集中在[115,180]区间,将此区间的灰度值拉伸到[0,255]这个范围,处理结果如图3(a)所示。可看到图像中纤维表面信息已经有了明显增强。

图2 羊毛纤维图像灰度直方图Fig.2 Gray histogram of wool image
接下来,使用自动局部阈值方法将纤维图像二值化,如图3(b)所示。可看到图像中噪声比较多,这里的目的是仅获取纤维本身的图像,需要去掉图像中其他部分。使用图像形态学操作,先通过“开”操作除掉图中的孤立单像素小块,然后计算图中像素点连通区域的面积,将小于面积最大值一半的小块去掉,再填充孔洞,并对所得图像求反,最后去掉图像边界四周的几行像素,得到的结果就是二值化的纤维轮廓,如图3(c)所示;接下来将增强的图像和轮廓二值图进行形态学中的“与”操作,即图3(a)与图3(c)相与,得到去掉背景的纤维增强图,如图3(d)所示。

图3 羊毛图像预处理(×500)Fig.1 Image pre-processing of wool fibers(×500).(a) Image enhancement; (b) Binary image; (c) Binary contour; (d) Background removal
1.2 视觉词袋模型
BoVW的主要思想是创建一个由视觉单词组成的词典,其中视觉单词是对纤维图像中检测到的关键点的描述,也就是图像中纤维表面的特征表示,然后统计纤维图像中的视觉单词在词典中出现的频率,并将其转换为直方图,用直方图向量表示纤维的特征。BoVW方法包括以下几个步骤:1)特征提取;2)生成视觉单词;3)建立视觉词典;4)生成直方图;5)分类。下面对模型的主要步骤进行说明。
1.2.1 特征提取
图像的特征提取就是通过获取目标图像中的必要信息,借助于这些信息可有效区分其他类别图像。特征提取是图像分类与识别的前提,尺度不变特征变换(SIFT)是著名的方法之一,其对尺度缩放、亮度、旋转保持不变,对亮度、仿射变换、噪声也有较强鲁棒性。这里使用SIFT获取的关键点用128维向量表示[8-9]。SIFT方法包括以下步骤:1)尺度空间关键点检测;2)关键点定位;3)关键点的方向确定;4)关键点的描述。
按照上面各个步骤可得到纤维图像中的关键点,如图4所示,关键点用圆圈中心表示。

图4 纤维图像的关键点检测Fig.4 Keypoints detection
1.2.2 视觉单词与词典的生成
接下来需要将这些关键点转换为视觉单词。视觉词袋模型中使用聚类算法对获得的关键点进行聚类,得到的聚类中心称为视觉单词,其中K-means聚类是最常用的方法。K-means方法的主要思想是在集合X={x1,x2,…,xi,…,xn}中找到k个聚类中心{m1,m2,…,mj,…,mk},使得集合X中的点到其所属聚类中心的欧式距离最小,公式为
(1)
式中Wn表示集合中的点xi到聚类中心mj的欧式距离,聚类中心就是前面所述的视觉单词,对应于图像中的特征。这里的视觉单词就是纤维图像表面图案的各个特征,而一组图像的视觉单词的集合就是视觉词典,表示为
V={w1,w2,…,wi,…,wM}
(2)
式中:V表示视觉词典;wi为词典中第i个视觉单词;视觉单词总数为M。将图像中的视觉单词在视觉词典中出现的次数直方图转换为向量,并用其描述图像,记为
BI=[t1,t2,…,ti,…,tM]
(3)
式中:BI表示数据集中第I个图像的视觉单词直方图;ti表示视觉单词wi在图像中出现的次数。选取前500个视觉单词作为描述图像的特征,结果如图5所示。

图5 视觉单词直方图Fig.5 Visual word histogram
1.2.3 空间金字塔
借助空间金字塔匹配方法,可使得BoVW模型在计算视觉单词时获得特征点相对的空间位置关系,这样可更好地描述图像特征。
空间金字塔主要思想是在不同分辨率的层次上来计算图像中的视觉单词的匹配程度,将图像分为多层(0,1,…,l,…,L),L为层数,0≤l≤L,第l层将图像水平和垂直方向都分为2l个方格,则图像l层共有22×l(4l)个方格[10]。统计每个方格中的视觉单词直方图,如图6所示。
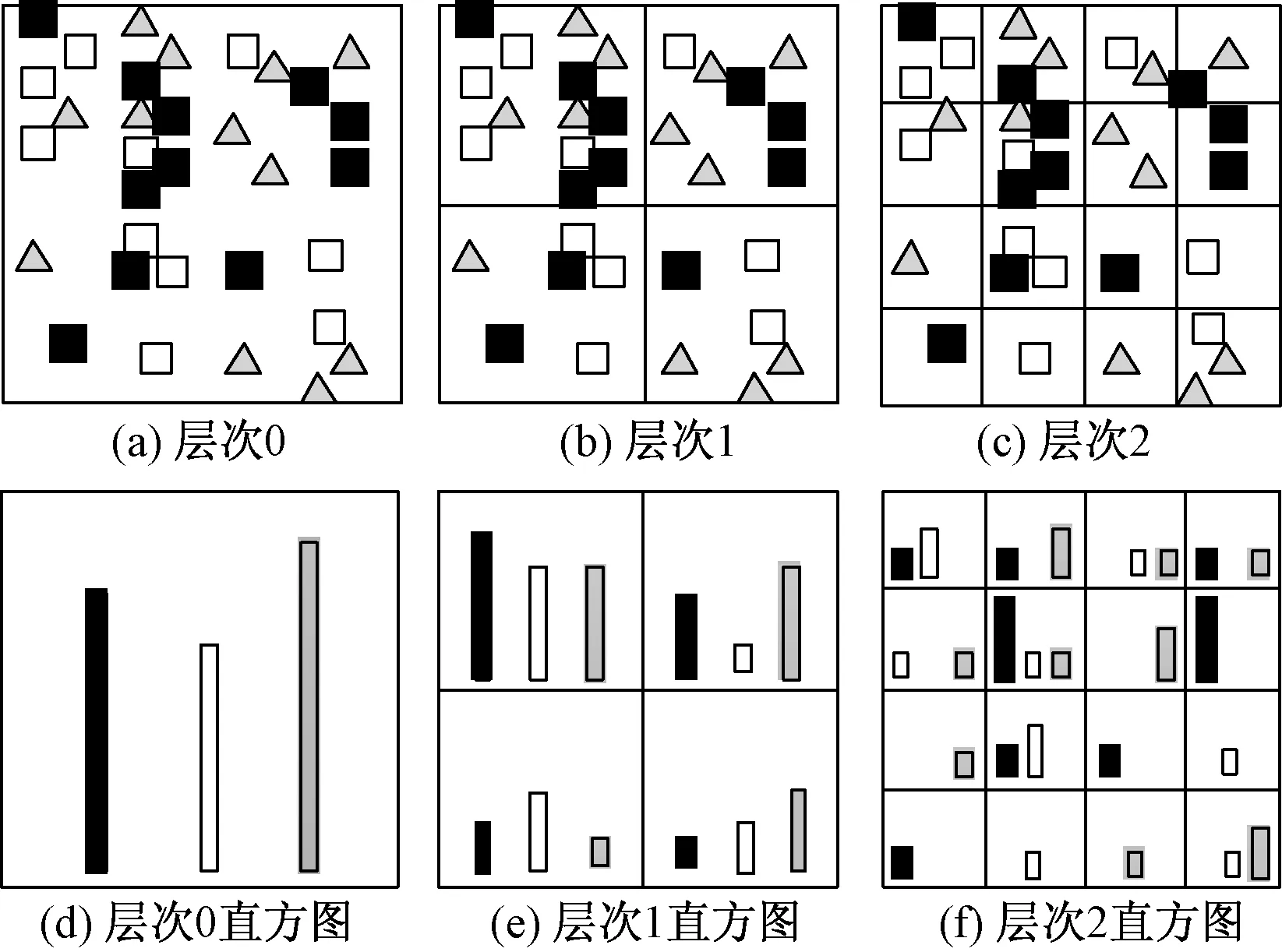
图6 空间金字塔示意图Fig.6 Schematic diagram of spatial pyramid.(a)Level 0;(b)Level 1;(c)Level 2; (d) Histogram of level 0;(e)Histogram of level 1;(f)Histogram of level 2
2 实验过程
实验样品是鄂尔多斯羊绒集团提供的20批羊绒和24批羊毛纤维,每批次选择100根纤维,使用蒸馏水清洗后晾干。取纤维放置于清洁的载玻片上,均匀涂抹甘油后加上盖玻片,由测试中心工程师拍摄。拍摄仪器为北京合众视野的CU系列纤维投影仪,纤维图像由安装在光学显微镜上的CCD摄像机获取,放大倍数为500,每副图像上有1根纤维。GB/T 16988—2013《特种动物纤维与绵羊毛混合物含量的测定》中规定,纤维总数不少于1 500根,这里选择的纤维图像总数为4 400张,其中包含2 000根羊绒图像和2 400根羊毛图像,实验的数据集从样本容量中选择不少于1 500根作为数据集。按照前面提到的方法流程进行实验。首先,原始纤维图像要按照1.1的方法进行图像预处理,将纤维图像增强,并且去掉背景;然后使用文中介绍的BoVW模型生成视觉单词和视觉词典,接下来用基于视觉词典的视觉单词直方图向量表示纤维图像;最后使用SVM对纤维图像进行分类。
2.1 评估指标
实验中使用混淆矩阵来评估方法的有效性,总体识别率用准确率的平均值At表示,定义如下。
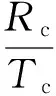
(4)
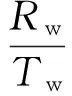
(5)

(6)
式中:Ac和Aw分别表示羊绒和羊毛的识别率;Rc和Rw分别表示正确识别羊绒和羊毛纤维的数量;Tc和Tw分别表示样本中羊绒和羊毛纤维的数量。实验记录了训练和测试所需的时间,采用计算机的处理器为Intel Xeon E5-2620,主频为2.0 G,内存为8 G。
2.2 结果与讨论
表1示出羊绒与羊毛鉴别结果。实验中进行的是监督学习训练,每次从数据集中随机选择不同数量和比例的纤维图像作为训练集和测试集,训练集与测试集的比例为6∶4。表中第1列给出了每次选择的数据集的纤维数量,第2列给出了羊绒和羊毛的混合比。第3~4列为训练集和测试集的纤维数量,第5~7列分别为测试集中羊绒、羊毛以及平均识别率,第8~9列为训练和测试所耗费的时间。从表1中实验结果可看到,在不同的纤维混合比的数据集上,测试集平均识别率最高为86.0%,最低为81.5%,表1中第8列数据表明该方法训练分类器的时间稍长,但实际应用中分类器是提前训练好,可保存并多次使用,而鉴别样本所需时间是表1中最后1列的测试时间,可得知本文方法鉴别1 000根纤维需要时间小于100 s。
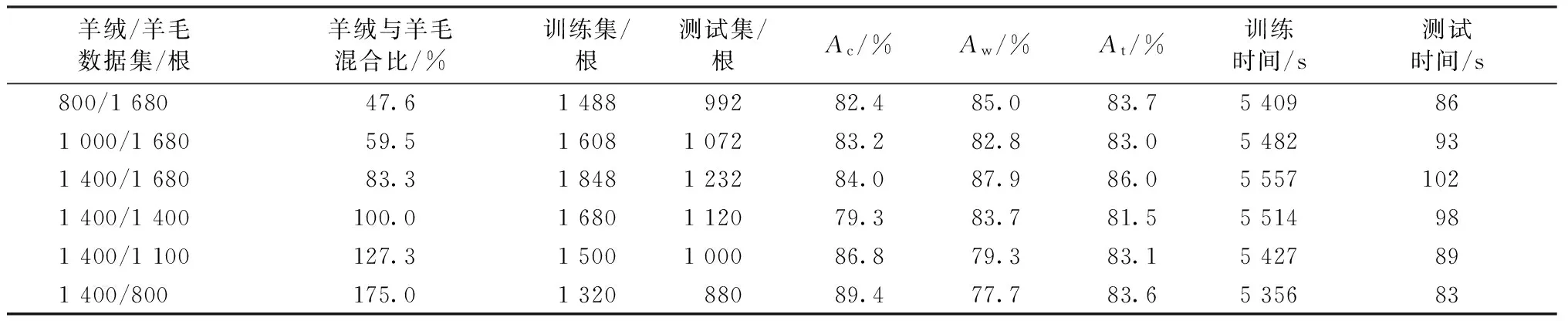
表1 羊绒与羊毛鉴别结果Tab.1 Identification results and cashmere and wool
与其他鉴别方法相比,本文方法检测速度快,适合用于初步鉴别,且样本来源于光学显微镜图像,成本比较低,易推广到实践中使用。
3 结 论
本文提出了一种基于视觉词袋模型的羊绒羊毛鉴别方法,该方法使用羊绒羊毛纤维的光学显微镜图像,借助于计算机视觉技术中的特征提取及特征描述方法,将纤维鉴别问题转化为图像分类问题。通过提取纤维图像表面特征,并使用视觉单词来表示纤维特征,然后使用SVM分类图像,以此来鉴别羊绒羊毛纤维,最后通过实验验证该方法的效果。从实验结果看出本文方法速度快,方便灵活,但识别率不算高,适合用于羊绒和羊毛的初步鉴别,接下来的工作应着眼于如何获取纤维表面更多有效的特征,从而进一步提高识别准确度。
FZXB
[1] 盛冠忠, 李龙. 关于山羊绒鉴别有关问题的探讨[J]. 毛纺科技, 2007(12): 52-55. SHENG Guanzhong, LI Long. Study on distinguishing problem of cashmere fiber[J]. Wool Textile Journal, 2007(12): 52-55.
[2] WORTMANN F J, PHAN K H, AUGUSTIN P. Quantitative fiber mixture analysis by scanning electron microscopy: part V: analyzing pure fiber samples and samples with small admixtures according to test method IWTO-58[J]. Textile Research Journal, 2003, 73(8): 727-732.
[3] ZOCCOLA M, LU N, MOSSOTTI R, et al. Identification of wool, cashmere, yak, and angora rabbit fibers and quantitative determination of wool and cashmere in blend: a near infrared spectroscopy study[J]. Fibers & Polymers, 2013, 14(8): 1283-1289.
[4] TANG M, ZHANG W, ZHOU H, et al. A real-time PCR method for quantifying mixed cashmere and wool based on hair mitochondrial DNA[J]. Textile Research Journal, 2014, 84(15): 1612-1621.
[5] WORTMANN F J, ARNS W. Quantitative fiber mixture analysis by scanning electron microscopy: part I: blends of mohair and cashmere with sheep′s wool[J]. Textile Research Journal, 1986, 56(7): 442-446.
[6] 季益萍, 杨云辉, 黄少君. 基于决策树算法的羊绒羊毛鉴别[J]. 纺织学报, 2013, 34(6): 16-20. JI Yiping, YANG Yunhui, HUANG Shaojun. Identification of wool and cashmere based on decision tree algorithm[J]. Journal of Textile Research, 2013, 34(6): 16-20.
[7] 石先军,胡新荣,蔡光明. 基于鳞片纹图基因码的羊绒理论识别精度及正误判率[J]. 纺织学报,2014, 35(4): 5-10. SHI Xianjun, HU Xinrong, CAI Guangming, et al. Theoretical recognition accuracy and error rate for cashmere based on scale pattern gene code[J]. Journal of Textile Research, 2014, 35(4): 5-10.
[8] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
[9] 解文杰. 基于中层语义表示的图像场景分类研究[D]. 北京:北京交通大学, 2011: 69-77. XIE Wenjie. Research on middle semantic representation based image scene classification[D]. Beijing: Beijing Jiaotong University, 2011: 69-77.
[10] 赵春晖, 王莹, KANEKO M. 一种基于词袋模型的图像优化分类方法[J]. 电子与信息学报, 2012, 34(9): 2064-2070. ZHAO Chunhui, WANG Ying, KANEKO M. An optimized method for image classification based on bag of words model[J]. Journal of Electron & Information Technology, 2012, 34(9):2064-2070.
Rapid identification method of cashmere and wool based on bag-of-visual-word
LU Kai1,ZHONG Yueqi1,2,ZHU Junping1,CHAI Xinyu1
(1.CollegeofTextiles,DonghuaUniversity,Shanghai201620,China;2.KeyLaboratoryofTextileScience&Technology,MinistryofEducation,DonghuaUniversity,Shanghai201620,China)
In order to identify cashmere and wool rapidly and accurately, a method based on bag-of-visual-word was proposed. Optical microscope images of cashmere and wool were taken as experimental samples in this method. The problem of fiber identification was changed to the problem of image classification. Firstly, fiber images were pre-processed to enhance their characteristics. Then, local features were extracted from fiber morphology and these local features were converted to visual words. Fiber images can be classified using visual words mentioned above. The experimental dataset contains 4 400 fiber images. Different mixing ratio of cashmere and wool were selected as train set and test set from the dataset. In this experiment, the highest recognition ratio is 86%, and the lowest is 81.5%. The time required to identify 1 000 fibers is shorter than 100 s. The trained classifier can be saved and used for the late detection.
cashmere;wool;bag-of-visual-word;image processing; rapid identification
10.13475/j.fzxb.20160606906
2016-06-27
2016-11-24
国家自然科学基金资助项目(61572124);中央高校基本科研业务费专项资金资助项目(CUSF-DH-D-2016016);上海市自然科学基金资助项目(14ZR1401100)
路凯(1979—),男,讲师,博士生。研究方向为纤维图像鉴别、纺织图像技术。钟跃崎,通信作者,E-mail:zhyq@dhu.edu.cn。
TS 102.3
A
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
学苑创造·A版(2021年10期)2021-10-30 10:34:43
纺织服装流行趋势展望(2020年4期)2020-02-01 06:31:06
意林·全彩Color(2019年9期)2019-10-17 02:25:52
汉语世界(The World of Chinese)(2019年2期)2019-04-19 01:38:10
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
流行色(2018年5期)2018-08-27 01:01:32
作文与考试·小学高年级版(2017年23期)2017-12-14 00:15:29
计算机工程(2015年8期)2015-07-03 12:20:21
