
大数据环境下的隐私保护研究
2017-07-19 11:02:03赵正伟
电子科技 2017年7期
胡 柳,王 梅,邓 杰,叶 静,赵正伟
(1.湖南信息职业技术学院 计算机工程学院,湖南 长沙 410200;2.湖南省长沙市岳麓观沙岭街道,湖南 长沙 410023;3.广西民族大学 信息科学与工程学院,广西 南宁 530006)
大数据环境下的隐私保护研究
胡 柳1,王 梅1,邓 杰1,叶 静2,赵正伟3
(1.湖南信息职业技术学院 计算机工程学院,湖南 长沙 410200;2.湖南省长沙市岳麓观沙岭街道,湖南 长沙 410023;3.广西民族大学 信息科学与工程学院,广西 南宁 530006)
针对大数据处理过程中泄露用户隐私的问题,必须要对大数据进行有效的保护,尽可能减少用户敏感信息的泄露。采用匿名与分级管理技术为中心的大数据隐私保护策略,研究表明,在现有的技术基础之上采用该策略,能有效减少用户隐私信息的泄露,为大数据隐私保护的研究提供了参考。
大数据;隐私数据;匿名技术;分级管理
随着物联网、智能交通、金融中心、云计算等技术的发展与运用,大数据概念逐渐进入人们的视野,这些无结构的数据通过网络进行交换与处理,最终形成与生活密切相关的支撑服务基础数据,如智能家居中各类传感器产生的数据、地下轨道交通中各设备传回管理中心的数据、云平台中的各类数据等[1-2]。
1 大数据概述
大数据的发展IDC的研究结果表明:全球数据量大约每两年翻一番,且产生的数据量按指数级增长,预计到2020年全球的数据量将达35 ZB(1 ZB=1 024 EB)[3]。大数据将成为信息产业的增长点,IDC预计中国大数据技术和服务市场在2011~2017年之间,年均增长率38.7%,由1.65亿美元增长至8.5亿美元[4]。目前,数据的增长速度已超越了数据存储如数据处理技术,如淘宝网每天产生的交易数据高达10 TB[5]。
大数据的特征大数据带来了机遇,但也存在对数据的有效管理和利用提出了新的挑战[6]。由于数据来源范围广,大数据的特征也比较明显,孟小峰等人对现有的大数据研究资料进行归纳和总结,在大数据定义层次上的3V(Volume,Variety,Velocity)基础上考虑4V(Value)特性[7]。大数据的来源有人、机、物等,其中人是指人们在信息网络中进行的各项活动产生的数据,如文本、音频、视频等数据。机是指计算机、磁盘等设备中的文件、数据等。物是指各类感知设备收集的数据信息。
(1)数据量巨大(Volume)。传统的存储技术和处理技术难以管理、处理PB、ZB级别的数据,未来将在存储、计算、分析技术及处理工具的发展上进行重点研究,以确保未来大数据的处理完整、精确;
(2)数据种类多(Variety)。大数据是包含着不同来源、不同数据产生源的数据,如网络、物联网、移动应用、汽车、传感器、医疗、金融、交通等各行业内产生的数据都是大数据的一部分,数据种类和格式无法实现以往的结构化、组织化、规律化,其中的数据可能是半结构化、非结构化、无组织、无逻辑的数据;
(3)数据产生速度快(Velocity)。IDC的预测中,数据量将呈现指数级别的增长,到2020年数据量为35ZB,随着处理技术的进步,而自处理过程同样将产生新的数据;
(4)区域内价值密度低(Value)。由于数据量的扩大,而在其中能寻找到的有效价值则越低。
大数据处理技术大数据的处理主要过程有:数据采集与预处理、管理与提取、分析、应用等,其整体架构如图1所示。
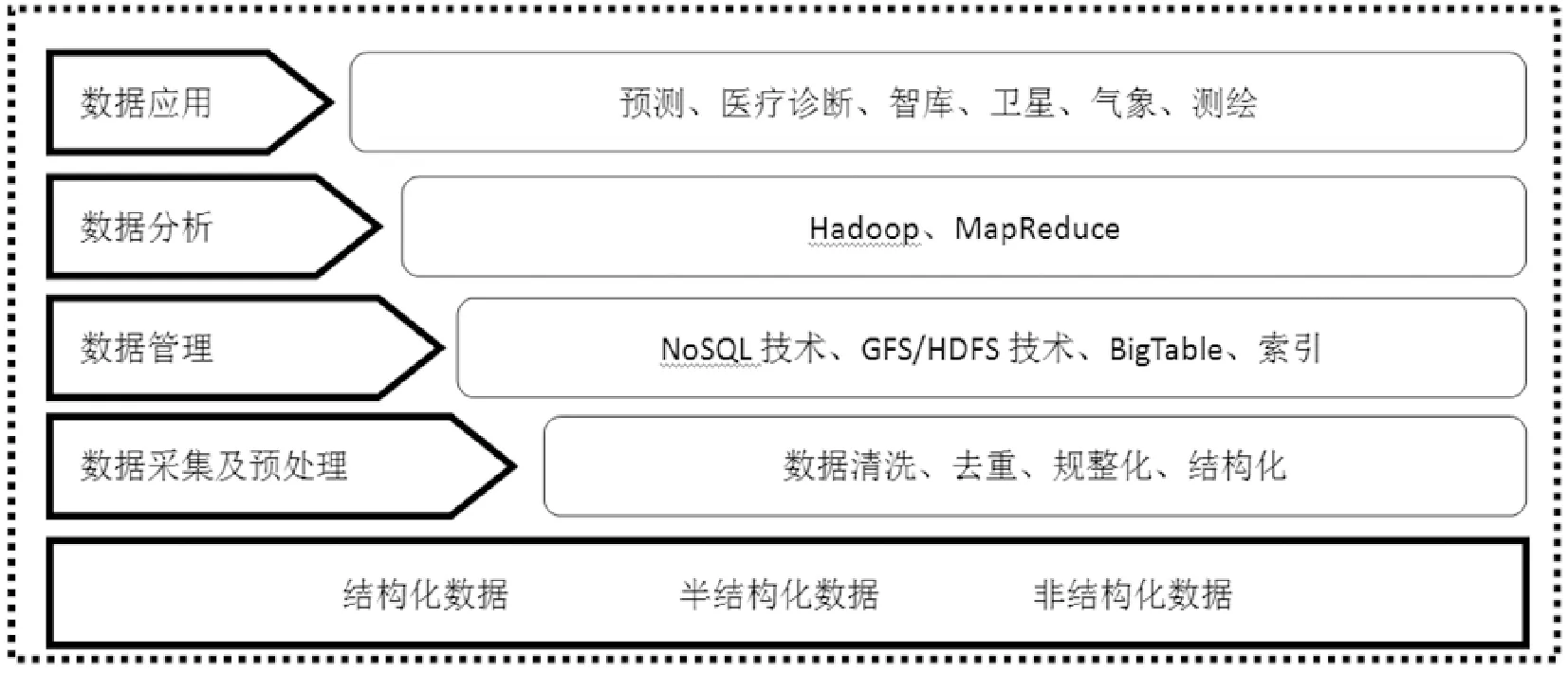
图1 大数据处理技术架构
(1)数据采集及预处理。对结构化、半结构化或无规则的非结构化数据进行前期处理,如数据清洗、去除重复的数据、数据规整、结构化等,检查数据的一致性、处理无效值和缺失值等。文献[8]基于D-S证据理论中置信区间的概念,提出了一种基于待测数据项置信区间来检测查询结果中错误数据的方法;
(2)数据管理。采用NoSQL技术、文件存储、索引等技术对数据进行存储与管理,大数据的来源广泛,对实时性要求较高的系统需要提高数据吞吐量,一般采用分布式文件来存储大数据,如GFS/HDFS[9],GFS是谷歌文件系统,一种可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。HDFS是Hadoop分布式文件系统,HDFS具有高度容错性,适合部署在普通的设备上,具有较高吞吐量的数据访问,适合大规模数据集上的应用;
(3)数据分析。对大数据进行实时分析,是大数据应用的核心部分,MapReduce是当前采用最为广泛的计算模型,文献[10]对MapReduce并行编程进行了综述研究,重点对模型改进、任务调度、负载均衡和容错性进行分析。文献[11]提出了基于BloomFilter的等值连接算法,利用BloomFilter减少Map和Reduce之间网络传输量从而提高等值连接算法的效率。文献[12]提出一种在异构环境下基于蚁群算法的多任务集群调度算法MSBACO,同时提出一种新的目标转移函数,提高集群性能;
(4)数据应用。通过对大数据统计分析得到的结果可以进行相应的预测、推理,用于医院、交通、金融等行业,对日常生活将产生积极的推动作用。
2 大数据环境下的信息安全
2.1 个人数据隐私
大数据环境下最为关键的就是个人数据的隐私问题,当海量而繁杂的数据汇总到一块时,会呈现出结构化、非结构化等形式,而其中就会包括各类含有个人隐私的数据,如论坛、贴吧、资讯、博客等网站上的用户数据,可以匹配出联系电话、邮箱、姓名、价值取向、位置等用户个人的隐私数据。如A用户在博客上的信息包括用户名、性别、地址、从事职业,其在资讯网上的信息包括姓名、电话等实名注册信息,当这些信息混合在一起时,通过相同的用户名进行连接,则有可能将该用户的全面的个人隐私资料都分析出来。
2.2 安全风险提升
在网络中,大数据以其信息量、集中度、规范性等特点,成为黑客攻击的主要目标,只要能进入到平台中,即意味着能获取大量的信息,这些内容中包含有用户信息、商业信息、金融信息等各类敏感数据,这样降低了黑客获取数据的成本、提高了效率。因此,安全风险问题不断提升,成为黑客攻击的主要目标。
2.3 平台管理
大数据平台通常都具有较快的运算速度、数据存储速度、网络传输速度,全面的大数据平台每天都处理海量的数据信息,平台管理者需要时时监控当前的运行情况,包括数据处理和数据存储,采用新的处理技术、数据缓冲技术来解决遇到的问题。
3 隐私保护方法
3.1 加密技术
若用户在A应用程序中进行注册,应用程序可以对其提交的每条信息进行加密存储,Y为加密后的密文,n为字符串长度,C为加密算法,对每一位字符进行条件加密,如式(1)所示
(1)
应用程序在使用用户的信息时,则进行解密过程,按加密的逆过程将明文应用于数据处理过程中。
3.2 水印技术
大数据平台中,水印技术可以用于验证和溯源,但是大数据快速的处理速度和存储速度又使得水印技术需提高其应用场景,不仅在多媒体载体文件,而应该是包含在更多的数据信息中。
3.3 匿名技术
社交网络数据通常是攻击者的主要目标,大数据中某一份用户数据将包含大量其它用户群体的数据,通常一个用户的社交数据可以描述如式(2)所示
k={(t1,r1),(t2,r2),(t3,r3),…,(tn,rn)}
(2)
其中,t为序列,r为关系,即当前用户的n个社交关系数据集合。
当攻击者获取到部分数据时,可以通过循环而获取大量社交网络用户群体的个人信息,从而造成严重的后果。
匿名技术要求用户或大数据平台都采用相关的机制进行隐私保护,如对用户关系结点、边界、中心进行加密或重分布技术,保护用户隐私数据不被泄露或破解。
3.4 访问控制技术
用户访问大数据平台时,根据其兴趣或角色的不同为其提供不同的数据服务,安全维护管理员需要为访问者进行数据访问控制,跟踪访问者在大数据平台中的操作行为,查看是否存在有危险的操作。对用户访问进行控制,将敏感数据进行角色或权限保护,安全管理员确认用户的合法性之后再放开权限。随着安全技术的不断提高,目前采用自适应的访问控制技术进行安全性控制是较好的方法,Cheng等人[13]提出了一个多级别的安全模型的安全自适应访问控制解决方案。大数据平台由于其处理程度复杂、数据行为监控难度大、安全风险量化困难等因素,导致采用访问控制技术来解决安全问题显得比较困难。
4 匿名技术与分级管理的保护策略
大数据的数据来源广泛,为了有效保护用户隐私数据,提出采用基于匿名技术对网络社交数据进行保护与分级管理的保护策略,网络中每天产生的社交数据量大,腾讯QQ、微信、人人网等社交网络平台中用户发表的言论或图片达数TB,这些隐私数据既包含用户的行为、生活、政治倾向、社会关系等内容,通过心智模型、语言模型的分析,则很有可能完整的分析出用户的心理状态,造成一定的影响。
匿名技术应用在社交网络数据中能在一定程度上切断用户之间的关系。当前有一些学者对这类问题进行了研究,文献[14]对匿名化隐私保护技术进行综述研究,阐述了匿名化技术的一般原理,并从匿名化原则、匿名化方法和匿名化度量等方面对匿名化技术进行了总结。文献[15]对数据发布中的个性化隐私匿名技术进行研究,对各类技术和基本原理、特征进行概括性的阐述,根据信息度量的差异给出个性化隐私度量的方法与标准。文献[16]对社交网络隐私保护技术最新研究进展进行了分析与阐述,重点对基于K-匿名、Markov链、聚类、随机化等技术的隐私保护方案的优点与不足进行了深入比较与分析。同时,在保护用户的属性方面也有较好的效果。
分级管理策略是根据大数据平台中对数据的级别定义,可以将其定义为5级,每一级别的访问策略不同,当访问者请求数据时,先对其身份等级进行审核,再给予其相应的访问权限。同时,为了实现最佳的效果,也需要将数据进行分级管理,其级别定义如表1所示。
输入为字符串或段落A,对其进行级别定义过程即是对字符串的分类,一般采用SVM或其它文本分类算法,如文献[17]设计与实现了新型快速中文文本分类器,提出一种将词频和综合评估函数值相结合的权重计算方法,设计了基于贝叶斯原理的快速分类器。文献[18]设计了一个基于Boosting算法的文本自动分类器。

表1 分级管理策略中级别定义
每一次访问都将判断请求者的身份级别,默认级别为中,通过操作行为来不断维护请求者的身份级别,请示者的级别定义如式(3)

(3)
其中,Ts为级别类型;Ri为某个请求者第i次的级别;n为某个请求者的访问总次数。
得到请求者的访问级别之后,能在大数据平台中请求到与之相应级别的数据信息,这样有利于屏蔽非法用户的非法请求,避免个人隐私数据大范围的泄露。
5 结束语
针对数据安全问题,用户个人隐私在大数据中成为新的安全域。从加密技术、水印技术、匿名技术、访问控制技术及个人信息保护、法律制度监督管理等方面进行阐述,提出了基于匿名技术与分级管理技术相结合对大数据平台中用户隐私数据的保护,通过技术手段和相关政策法规相结合来保障用户的隐私数据。
[1] 陶雪娇,胡晓峰,刘洋.大数据研究综述[J].系统仿真学报,2013,25(8S):142-146.
[2] 维基百科.大数据[EB/OL].(2014-12-12)[2016-8-27]http:∥zh.wikipedia.org/wiki/%E5%A4%A7%E6%95%B8%E6%93%9A.
[3] 孙红,郝泽明.大数据处理流程及存储模式的改进[J].电子科技,2015,28(12):167-172.
[4] 潘永花.中国大数据技术与服务市场2013-2017年预测与分析[EB/OL].(2014-03-05)[2016-8-27]http:∥www.idc.com.cn/prodserv/detail.jsp?id=NTc3.
[5] 程建云,魏文军.轨道电路故障诊断大数据处理技术综述[J].电子科技,2015,28(11):161-165.
[6] 申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[7] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[8] 樊金辉,岳昆,张骥先.基于D-S证据理论的不确定数据清洗[J].云南大学学报:自然科学版,2014,36(6):815-822.
[9] 孙知信,黄涵霞.基于云计算的数据存储技术研究[J].南京邮电大学学报:自然科学版,2014,34(4):13-19.
[10] 李建江,崔建,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[11] 张常淳.基于MapReduce的大数据连接算法的设计与优化[D].合肥:中国科学技术大学,2014.
[12] 张建平.云计算中基于MapReduce集群模型的调度优化与研究[D].南京:南京邮电大学,2013.
[13] Cheng P C,Rohatgi P,Keser C,et al.Fuzzy multi-level security: an experiment on quantified risk-adaptive access control[C].Oakland,USA:Proceedings of the 2007 IEEE Symposium on Security and Privacy(S&P’2007),2007.
[14] 王平水,王建东.匿名化隐私保护技术研究进展[J].计算机应用研究,2010,27(6):2016-2019.
[15] 王波,杨静.数据发布中的个性化隐私匿名技术研究[J].计算机科学,2012,39(4):168-171.
[16] 马飞,蒋建国,李娟.社交网络隐私保护技术最新研究进展[J].计算机应用研究,2015,32(5):1291-1297.
[17] 陈艳秋,熊耀华.新型快速中文文本分类器的设计与实现[J].计算机工程与应用,2009,45(22):53-55.
[18] 董乐红,耿国华,周明全.基于Boosting算法的文本自动分类器设计[J].计算机应用,2007,27(2):384-386.
Research on Big Data Privacy Protection
HU Liu1, WANG Mei1, DENG Jie1, YE Jing2, ZHAO Zhengwei3
(1.School of Computer, Hunan College of Information, Changsha 410200 China;2. Guanshaling Street,Yuelu District, Changsha 410023, China;3. School of Information Science and Engineering, Guangxi University for Nationalities, Nanning 530006, China)
Effective protection for big data is a must and the leakage of sensitive information of users should be minimized. The anonymous technology and hierarchical management is adopted as the center of big data privacy protection. Research suggests that this policy effectively reduces the leakage of user privacy information and brings a new and important approach to big data privacy protection.
big data; private data; anonymous technology; hierarchical management
2016- 08- 25
湖南省教育厅高校研究项目(15C0980)
胡柳(1988-),男,硕士研究生。研究方向:大数据等。王梅(1978-),女,讲师。研究方向:大数据。邓杰(1982-),男,高级工程师。研究方向:信息安全。
10.16180/j.cnki.issn1007-7820.2017.07.045
TP309
A
1007-7820(2017)07-159-04
猜你喜欢
基层中医药(2021年8期)2021-11-02 06:25:02
当代水产(2019年11期)2019-12-23 09:03:18
收藏界(2018年3期)2018-10-10 05:34:00
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
中学生(2017年13期)2017-06-15 12:57:48
商用汽车(2016年11期)2016-12-19 01:20:16
商用汽车(2016年6期)2016-06-29 09:18:54
商用汽车(2016年4期)2016-05-09 01:23:12
创业家(2015年10期)2015-02-27 07:55:08
