
基于规则和统计相结合的西里尔蒙古文到传统蒙古文转换方法
2017-07-18 10:53:15高光来王洪伟
中文信息学报 2017年3期
飞 龙,高光来,王洪伟,路 敏
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
基于规则和统计相结合的西里尔蒙古文到传统蒙古文转换方法
飞 龙,高光来,王洪伟,路 敏
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
西里尔蒙古文与传统蒙古文分别是蒙古国与中国使用的蒙古文,西里尔蒙古文到传统蒙古文的转换工作不仅给两国同胞的交流带来更多的便利,而且对蒙古族的科学、文化和教育发展具有重要意义。本文结合规则与统计模型的优点,研究了西里尔蒙古文到传统蒙古文的转换方法。本文首先采用基于规则的方法对西里尔蒙古文集内词进行转换,其次对集外词的转换采用了基于联合序列模型的方法,并采用N-gram语言模型解决了一个西里尔蒙古文单词对应多个传统蒙古文单词的问题。实验结果表明,该系统单词转换错误率低至4.12%,基本达到了实用要求。
西里尔蒙古文;传统蒙古文;转换;规则;联合序列模型
1 引言
蒙古文是一种跨多国、多地区的语言,在世界上也是一种有广泛影响的语言文字,使用者分布在中国、蒙古国和俄罗斯等国家。中国和蒙古国使用的蒙古语言文字是“语同文不同”,即语言相同,但文字不同,在蒙古国使用的蒙古文叫“西里尔蒙古文”(也称为新蒙古文、基里尔蒙古文或斯拉夫蒙古文),中国使用的蒙古文叫“传统蒙古文”(也称为旧蒙古文),随着中国和蒙古国两国之间的文化、教育和经济合作与交流不断深入,西里尔蒙古文到传统蒙古文的转换工作就变得极其重要。西里尔蒙古文到传统蒙古文的转换工作不仅给两国同胞的语言交流带来更多的便利,而且对两国间科学、文化和教育发展同样具有重要意义。
吉仁尼格、包萨日娜、乌日力嘎等人采用基于词典和规则的方法对西里尔蒙古文与传统蒙古文的相互转换进行了研究[1-5],飞龙等人采用统计模型的方法也对西里尔蒙古文与传统蒙古文的相互转换做了研究[6]。但是基于词典和规则的系统与基于统计模型的系统都有自己的不足之处,蒙古文通过词根缀接多个后缀的方式生成新词,按照这种生成方式,可以构成大规模的蒙古文单词,词典一般很难包含全部。而且,基于规则的方法很难归纳出所有的转换规则,并且一部分单词并不遵循转换规则,所以基于词典和规则的方法有一定局限性。而统计模型的性能与语料库的规模、代表性、正确性及加工深度有密切关系,其过分依赖语料库的质量。
本文采用了基于规则与统计相结合的方法,建立了高效的西里尔蒙古文到传统蒙古文的转换(Cyrillic Mongolian To Traditional Mongolian Conversion,C2T)系统,获得了较好的实验效果。
2 西里尔蒙古文与传统蒙古文的比较
蒙古文属于黏着语,由词根缀接多个后缀而生成新词。西里尔蒙古文与传统蒙古文之间有不可分割的联系,西里尔蒙古文保留了传统蒙古文的大多数语法特点,二者在语法上保持一致,并且读音基本相同。但是,西里尔蒙古文与传统蒙古文之间仍存在着很多不同点,具体的不同之处可以总结为以下四点:
(1) 西里尔蒙古文与传统蒙古文字母对照表如表1所示。西里尔蒙古文与传统蒙古文均有35个字母,但是西里尔蒙古文有13个元音、20个辅音、1个硬化字母及1个软化字母,而传统蒙古文有8个元音和27个辅音。
(2) 西里尔蒙古文字母有大小写之分,用法与英文相似,而传统蒙古文字母没有大小写之分,其每个字母在词中形式变化有很多,在一个传统蒙古文单词中,每个字母会因其处在单词的上、中、下位置不同而导致写法也不同。

西里尔蒙古文与传统蒙古文之间存在的这些差异为C2T的转换工作带来了一定困难,本文采用了基于规则与统计模型相结合的方法研究了C2T转换问题。
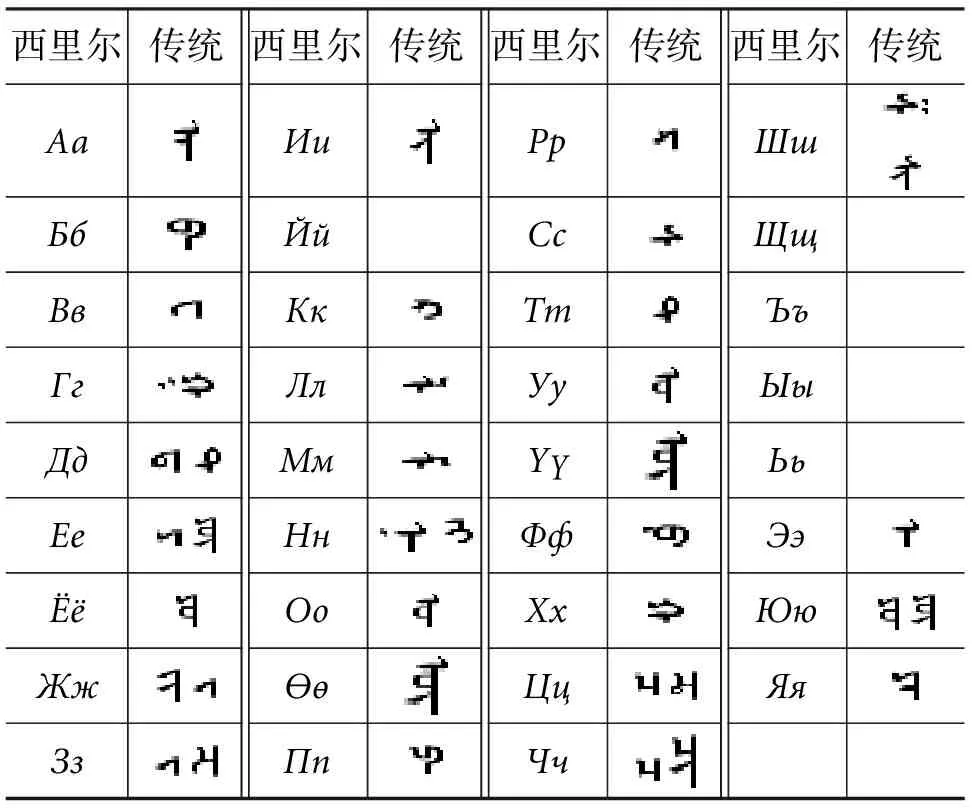
表1 西里尔蒙古文和传统蒙古文字母对照表
3 基于规则的C2T转换
西里尔蒙古文与传统蒙古文同属于黏着语,蒙古文单词从构造上可以分为: 词根、词干、附加成分。在形态学方面,其构词是以词根或词干为基础,后接词缀来派生新词和进行词形变化,而且变化复杂多样。表示蒙古文单词有意义的部分叫做词干,词干可以分为第一词干、第二词干、第三词干等,词根就是第一词干。附加成分单独没有意义,只在词干下附加后产生词汇意义和语法意义。附加成分有构形附加成分和构词附加成分: 词干缀接构形附加成分,词汇意义没有变化,只是语法意义发生变化,比如名词等的性、数、格,还有动词等的时、体、态等语法意义;词干缀接构词附加成分,会发生词汇意义的变化并产生新词。本文仅处理构形附加成分,它并没有改变词汇的意义,本文称其为后缀。
基于规则的单词级C2T转换流程如图1所示,主要分为三个步骤: 首先,对输入的西里尔蒙古文进行后缀切分;其次,分别对切分后的词干及后缀部分根据规则转换到对应的传统蒙古文词干及后缀;最后,依据传统蒙古文构词规则对传统蒙文词干及后缀进行缀接得到传统蒙古文单词。

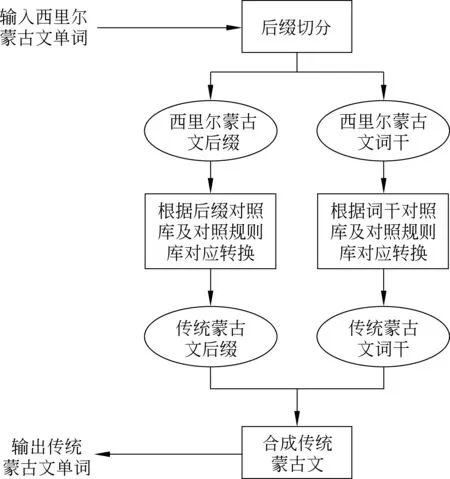
图1 基于规则的单词级C2T转换流程图
西里尔蒙古文后缀切分比较复杂,在西里尔蒙古文构词时会有元音及辅音的脱落、生成和变换等现象,所以对西里尔蒙古文单词进行后缀切分时就会有元音及辅音的恢复、脱落及还原过程。例如,西里尔蒙古文单词“амрах”(拉丁转写是amrah)切分后得到的词干及后缀分别是“амар”(拉丁转写是amar)和“ах”(拉丁转写是ah)。本文根据西里尔蒙古文构词特点,参考《基立尔蒙古文学习读本》[7]《蒙古语语法》[8],总结了共计30多条西里尔蒙文后缀切分规则。
西里尔蒙古文与传统蒙文的词干及后缀对应转换同样需要遵循规则。本文参考《新蒙汉词典》[9]、《蒙古文词典》[10]《蒙古文基里尔文正字法比较研究》[11],总结并建立了C2T转换词干对照库(包含63 501词条)、动词后缀对照库(包含495条)、静词后缀对照库(包含335条)及对照规则库(包含130条对应规则)。

基于规则的C2T转换对于集内词的转换获得了较好的实验效果,但无法对集外词进行转换,而且无法对一个西里尔蒙古文对应多个传统蒙古文单词的情况进行处理。
西里尔蒙古文与传统蒙古文都是拼音文字,即用字母表示语音的文字,每个西里尔蒙古文与传统蒙古文单词都是一个字母序列,所以可以用数据来训练西里尔蒙古文与传统蒙古文字母或者音节间的对应关系,并通过拼接得到对应的传统蒙古文,所以可以使用统计模型来进行C2T转换。
4 基于联合序列模型的C2T转换[6]
假设G表示所有西里尔蒙古文字母串的集合,φ表示所有传统蒙古文字母串的集合。C2T转换过程可以描述为: 对于任意给定的西里尔蒙古文字母串g∈G,来寻找最优的传统蒙古文字母串φ∈φ,使得二者一一对应。进一步,可以使用贝叶斯决策规则形式化描述此问题,即
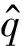
联合概率p(g,φ)可以由与其相匹配的所有cytrone表示,即
其中,S(g,φ)是g和φ的所有联合分割的集合,即

于是,联合序列模型的形式化表示为

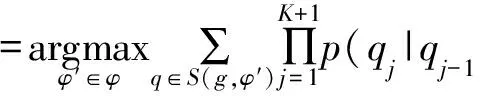
本文使用最大似然方法估计模型参数,并使用Kneser-Ney平滑算法来做数据平滑。基于联合序列模型的单词级C2T可以很好地解决对集外词的转换。
5 基于规则与统计模型相结合的C2T转换系统
C2T转换系统框架如图2所示。首先,对输入的西里尔蒙古文预处理;其次,使用基于规则的方法完成单词级C2T的转换,转换不成功的单词则使用基于联合序列模型的方法对其进行转换;最后,通过语言模型选择词序列,从西里尔蒙古文到传统蒙古文会有单词一对多的情况,需要使用语言模型进行选择最优词序列。

图2 规则与统计相结合的C2T转换系统框架
5.1 预处理
预处理分为四个主要部分: 首先,对西里尔蒙古文文章进行分句并分词处理;其次,对非西里尔蒙古文字母进行处理,一方面识别并保留非西里尔蒙古文字符,另一方面完成对西里尔蒙古文普通标点符号及数字符号等的对应转换;再次,对西里尔蒙古文的缩略语进行识别并还原,缩略语在西里尔蒙古文中很常见,缩略语处理是C2T转换工作中的主要难题之一,对其处理得当与否将影响C2T转换质量,本文对缩略语的识别及还原是基于缩略语词典(本文参考《新蒙汉词典》[9]及《蒙汉缩略语及外来词词典》[15]整理总结了9 573条缩略语)的方法来完成的;最后,对西里尔蒙古文姓名进行处理,姓名中的名字与普通单词的转换是一致的,但是姓氏通常由单个字母组成,我们使用西里尔蒙古文与传统蒙古文姓氏对照表处理,西里尔蒙古文中的姓名通常有固定的格式,例如,“Т.Индра”(拉丁转写是t.indra)表示一个人的名字,其中姓氏由大写字母构成,名字首字母大写,二者以字符“.”分隔,“Т”(拉丁转写是t)根据姓氏对照表可得到传统蒙古文姓氏“”(拉丁转写是t),名字“Индра”(拉丁转写是indra)对应的单词是“”(拉丁转写是indar_a),传统蒙古文姓名为“” (拉丁转写是t·indar_a)。
5.2 单词级C2T转换
经过预处理后,对输入的西里尔蒙古文集内词采用基于规则的方法进行转换,转换成功的单词将给出所有对应的候选传统蒙古文单词,对集外词则使用联合序列模型进行转换。
对输入的西里尔蒙古文句子预处理后进行单词级的C2T转换结果如图3所示,西里尔蒙古文例句共包含12个单词,其中十个单词由规则进行转换,有两个单词由统计模型进行转换,分别是“хэмжээний”和“армяни”。

图3 规则与统计结合的C2T转换示例
5.3 语言模型选择最佳词序列[16]
一些西里尔蒙古文单词会有多个与其对应的传统蒙古文单词,如图4所示,在进行C2T转换时,必须给出一个符合上下文关系的对应传统蒙古文单词,本文采用N-gram解决了此问题。
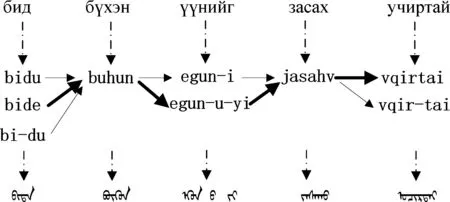
图4 C2T转换示例
C2T转换的N元语言模型可以用以下条件概率公式形式化表示,即
其中,C表示西里尔蒙古文词序列,T={t1t2…tL}表示传统蒙古文词序列,Q表示C对应的所有传统蒙古文词序列的集合。
无论是使用规则还是联合序列模型进行单词级C2T转换时都会出现一个西里尔蒙古文单词对应多个传统蒙古文单词的情况,语言模型的使用可以很好地解决这一问题,其在C2T转换系统中起着非常关键的作用。
6 实验结果及分析
6.1 实验数据
本文首先分别对基于规则和基于联合序列模型的单词级C2T做了实验并进行对比分析,其次对基于规则与统计相结合的C2T系统做了相关实验。
本文采用的实验数据如表2所示,系统测试集为gonews100_data,共包含100篇西里尔蒙古文文章,词汇量为47 261。对联合序列模型将使用从《新蒙汉词典》[9]中搜集的西里尔蒙古文与传统蒙古文对应词对60 000对作为模型的训练及测试集(cytra60000_data),对语言模型的训练使用数据集Tranews624M_data,其中包含320万句传统蒙古文句子,大小为624MB。
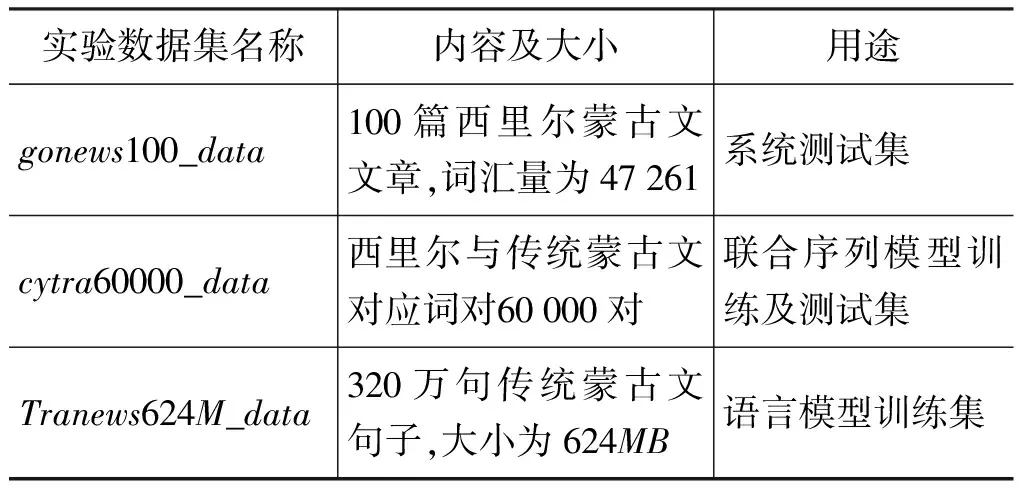
表2 实验数据集
6.2 系统评价指标
本文实验采用的系统性能评价指标是单词转换错误率(word convert error rate,WER)、字母误识率(letter error rate,LER)及句子绝对准确率(sentence absolute accurate,SAA),即
其中,Ncorrect表示转换正确的西里尔蒙古文单词数;Ntotal表示待转换的西里尔蒙古文词汇总数;Nins为转换时出现的字母插入错误个数;Ndel为转换时所有出现的字母删除错误总合;Nsub为转换时所有出现的字母替换错误总合;SNcorrect表示C2T转换时完全被正确转换的西里尔蒙古文句子数,SNtotal为待转换的西里尔蒙古文句子总数。
6.3 实验结果
6.3.1 基于规则的C2T转换实验
在使用基于规则的方法时,由于西里尔蒙古文与传统蒙古文的对应词干或对应词缀覆盖不全的问题会导致一些西里尔蒙古文单词不能够被转换成对应的传统蒙古文。能够被成功转换的西里尔蒙古文单词中: 一部分只有一个传统蒙古文与其对应(1-1);另一部分会有多个传统蒙古文单词与其对应(1-m),而其中只有一个传统蒙古文单词满足当前上下文关系。
在测试集gonews100_data上,实验结果如表3所示,转换失败的单词数占5.8%,转换成功的单词数占94.2%,其中88.9%是一对一(1-1)的情况,5.3%是一对多(1-m)的情况,使用基于规则的方法将西里尔蒙古文成功转换且转换准确的单词共有42 015个,即Ncorrect=42 015,转换错误率WER=11.1%。

表3 使用基于规则的C2T转换结果
实验表明,基于规则方法的单词级C2T转换有较低的转换错误率,大部分单词使用规则可以被转换,但是仍有一部分不能够被转换,而且,被转换出的单词有相当一部分是一对多的情况。
6.3.2 基于联合序列模型的C2T转换实验
将数据集cytra60000_data中随机选取45 000词对作为联合序列模型的训练集train,剩余15 000词对作为模型测试集test1,gonews100_data作为测试集test2。需要指出的是测试集test1与训练集train没有重复的单词,即对于使用训练集train训练出的联合序列模型而言,测试集test1内的单词全部是集外词。
在联合序列模型中cytrone的长度上限L=1时,不同N-gram阶数N下所获得的实验结果如表4所示,具体实验参数可参考文献[6]。

表4 使用基于联合序列模型的C2T转换结果(L=1)
实验结果表明,随着N的不断增大,无论在训练集train还是测试集test1及测试集test2上,单词的转换错误率及字母误识率都在不断下降,而在N=8时模型获得最佳性能,在全部是集外词的测试集test1上的单词转换错误率WER=18.78%,字母误识率LER=7.17%,在测试集test2上的单词转换错误率WER=7.43%,字母误识率LER=1.24%。
6.3.3 基于规则与统计模型相结合的C2T转换实验
本文将基于规则与基于联合序列模型的方法结合,建立了C2T转换系统,并做了实验以评价系统性能。
如前所述,在C2T转换时会有一个西里尔蒙古文单词对应多个传统蒙古文单词的情况,所以本文引入语言模型来挑选 最合适的传 统 蒙古文词序列,在这里我们使用的是三元语言模型,表5为对联合序列模型解码时选取N-best的C2T转换实验结果。
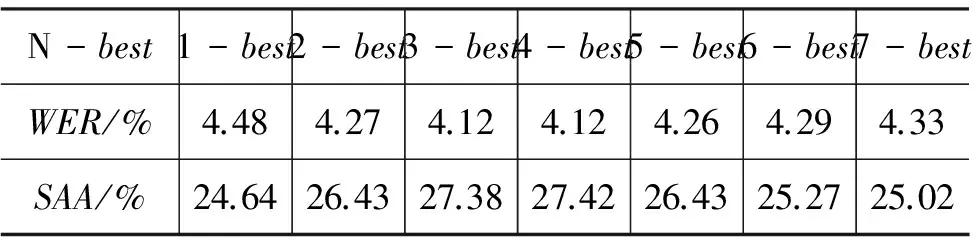
表5 C2T转换系统转换结果
实验结果表明,随着联合序列模型中N-best的N不断增大,系统性能逐渐提升。当N=4时系统以单词转换错误率WER=4.12%及句子绝对准确率SAA=27.42%取得最佳性能。并且基于规则与统计模型相结合的C2T转换系统性能比单独基于规则或者基于统计的C2T转换效果都好。
7 结束语
本文首先分别介绍了基于规则和基于联合序列模型的C2T的转换方法,其次将基于规则的方法与基于联合序列模型的方法相结合,并使用N元语言模型解决C2T中西里尔蒙古文到传统蒙古文的一对多对应的问题,提出了高效的西里尔蒙古文到传统蒙古文转换方法,并建立了C2T转换系统(系统网址是http://trans.mglip.com)。实验结果表明,C2T转换系统的单词转换错误率低至4.12%,句子绝对准确率为27.42%,本文所建立的基于规则与联合序列模型相结合的C2T转换系统获得了很好的实验效果,已基本达到实用要求。
[1] 吉仁尼格. 蒙古文同形词的统计法[C]. 第十一届全国民族语言文字信息学术研讨会论文集,2007.
[2] 包萨日娜. 传统蒙古文到新蒙文转换中名词及其格附加成分转换的研究[D]. 内蒙古大学硕士学位论文, 2009.
[3] 乌日力嘎. 传统蒙古文、西里尔蒙古文—汉文电子词典的建立[D]. 内蒙古大学硕士学位论文, 2009.
[4]HaoLi,BaoSarina.TheStudyofComparisonandConversionaboutTraditionalMongolianandCyrillicMongolian[C]//Processingsofthe2011 4thInternationalConferenceonIntelligentNetworksandIntelligentSystems, 2011: 199-202.
[5] 高红霞,马小蕾. 西里尔蒙古文网页向传统蒙古文自动转换系统的文字转换研究[J].内蒙古民族大学学报,2012,18(5): 17-18.
[6] 飞龙,高光来. 基于统计的传统蒙古文和西里尔蒙古文相互转换方法的研究[J]. 计算机工程与应用,2014,50(23): 206-211.
[7] 嘎拉桑朋斯格. 基立尔蒙古文学习读本[M]. 呼和浩特: 内蒙古教育出版社. 2006.
[8]Davaagiin,Battuul.MongolianGrammar[M].Mongolia:ADMON,Ltd, 2008.
[9] 张志忠. 新蒙汉词典[M]. 北京: 商务印书馆,2011.
[10] 巴雅尔赛罕. 蒙古文词典(西里尔与传统蒙古文对照词典)[M]. 乌拉巴托: 索永布印刷出版社,2011.
[11] 舍·却玛. 蒙古文基里尔文正字法比较研究[M]. 呼和浩特: 内蒙古教育出版社,2010.
[12] 清格尔泰. 蒙古语语法 [M]. 呼和浩特: 内蒙古人民出版社,1991.
[13] 朝洛蒙. 现代蒙古语[M]. 呼和浩特: 内蒙古大学出版社. 2009.
[14]BisaniM,NeyH.Joint-sequencemodelsforgrapheme-to-phonemeconversion[J].SpeechCommunication, 2008, 50(5): 434-451.
[15] 李继学. 蒙汉缩略语及外来词词典[M]. 呼和浩特: 内蒙古人民出版社,2003.
[16]FeilongBao,GuanglaiGao.LanguageModelforCyrillicMongoliantoTraditionalMongolianConversion[C]//ProcessingsofThe2ndConferenceonNaturalLanguageProcessing&ChineseComputing(NLPCC2013),Chongqing,China,2013: 13-18.
CombiningofRulesandStatisticsforCyrillicMongoliantoTraditionalMongolianConversion
BAO Feilong, GAO Guanglai, WANG Hongwei, LU min
(College of Computer Science, Inner Mongolia University, Hohhot,Inner Mongolia 010021, China)
Cyrillic Mongolian and Traditional Mongolian are used in Mongolia and China, respectively. Cyrillic Mongolian to Traditional Mongolian conversion not only will bring more convenience to exchanges between the two countries, but also has great significance for scientific, cultural and educational development of Mongolian. This paper proposes a highly efficient Cyrillic Mongolian to Traditional Mongolian conversion method. It adopts the rule-based approach to convert the words in the vocabulary, and the statistical model to convert the out-of-vocabulary words. A large part of Cyrillic Mongolian words correspond more than one candidates in Traditional Mongolian, which is solved by the N-gram language model. Experimental results show that the word error rate is as low as 4.12%, meeting the practical requirement.
Cyrillic Mongolian; Traditional Mongolian; conversion; rules; joint sequence model

飞龙(1985—),博士,副教授,硕士生导师,主要研究领域为蒙古文信息处理、语音识别、语音合成。

高光来(1964—),硕士,教授,博士生导师,主要研究领域为模式识别、自然语言处理。

王洪伟(1989—),硕士研究生,主要研究领域为蒙古文信息处理。
1003-0077(2017)03-0156-07
2015-06-05定稿日期: 2016-03-20
国家自然科学基金(61563040);内蒙古自然科学基金(2016D06);内蒙古大学高层次人才引进科研项目资助
TP391
: A
猜你喜欢
现代装饰(2020年6期)2020-06-22 08:43:14
现代职业教育·高职高专(2020年22期)2020-03-24 22:46:34
中文信息学报(2018年11期)2018-12-20 06:08:44
卫拉特研究(2018年0期)2018-07-22 05:47:46
学苑创造·B版(2017年3期)2017-05-03 16:04:17
西部蒙古论坛(2016年4期)2017-01-16 12:12:47
卫拉特研究(2016年0期)2016-12-06 09:11:56
中文信息学报(2015年5期)2015-04-21 10:41:55
中文信息学报(2015年3期)2015-04-21 08:33:49
宠物世界·猫迷(2014年1期)2014-02-19 01:14:16
