
Kernel clustering—based K—means clustering
2017-07-14 07:48ZHUChangmingZHANG
上海海事大学学报 2017年2期
关键词:支持向量机
ZHU+Changming+ZHANG+Mo
Abstract: In order to process data sets with linear nonseparability or complicated structure, the Kernel Clusteringbased Kmeans Clustering (KCKC) method is proposed. The method clusters patterns in the original space and then maps them into the kernel space by Radial Basis Function (RBF) kernel so that the relationships between patterns are almost kept. The method is applied to the RBFbased Neural Network (RBFNN), the RBFbased Support Vector Machine (RBFSVM), and the Kernel Nearest Neighbor Classifier (KNNC). The results validate that the proposed method can generate more effective kernels, save the kernel generating time in the kernel space, avoid the sensitivity of setting the number of kernels, and improve the classification performance.
Key words: kernel clustering; Kmeans clustering; Radial Basis Function (RBF); Support Vector Machine (SVM)
摘要:為处理线性不可分、结构复杂的数据集,提出基于核聚类的K均值聚类(Kernel Clusteringbased Kmeans Clustering,KCKC).该方法先在原始空间中对模式进行聚类,再由径向基函数(Radial Basis Function, RBF)核把它们映射到核空间,从而保持大部分模式之间的关系.把提出的方法应用到基于RBF的神经网络(RBFbased Neural Network,RBFNN)、基于RBF的支持向量机(RBFbased Support Vector Machine, RBFSVM)和核最近邻分类器(Kernel Nearest Neighbor Classifier,KNNC)中,结果表明本文提出的算法可以生成更有效的核,节省在核空间中的核生成时间,避免核数目设置的敏感性,并提高分类性能.
关键词: 核聚类; K均值聚类; 径向基函数(RBF); 支持向量机(SVM)
0 Introduction
Clusters (i.e., kernels) play an important role on data analysis and the clustering is an unsupervised learning method and classifies patterns by their feature vectors. The Kmeans Clustering (KC)[1], the agglomerative hierarchical clustering[2] and the fuzzybased clustering[3] are classical clustering methods. But, some disadvantages of them are found[4]. First, they are used in some specific domains. Second, they always suffer from high complexity. Furthermore, patterns may be covered by wrong clusters and these methods can not process nonlinear problems well.
In order to overcome the disadvantages of the above methods, some scholars proposed the Kernelbased KC (KKC)[5]. By the method, the patterns to be classified in an original space are mapped into a high dimensional kernel space so that the patterns become linearly separable (or nearly linearly separable), and then the KC is carried out in the kernel space. If this nonlinear mapping is continuous and smooth, the topological structures and orders of the patterns will be maintained in the kernel space. So, the patterns to be covered in a cluster together are also covered together in the kernel space. By nonlinear mapping, the differences of pattern characteristics are highlighted and the linearly inseparable patterns in the original space become linearly separable. During clustering, certain similarity metrics (Euclidean distance between patterns in the kernel space) and the objective function (least square error) are defined in the kernel space. Thus, for those linearly inseparable patterns as well as the asymmetric distribution of patterns, the kernelbased clustering can be adopted to reduce clustering error and get better clustering effect. In order to solve the problem of unsupervised learning methods, GAO et al.[6] proposed the kernel clustering method to generate clusters for each class and cover patterns by right label class.
Taking the merits of the kernel clustering and KKC, they are combined and updated for clusters during the processing of the iteration between an original space and a kernel space. Namely, clusters are clustered in the original space and the centers and radii of clusters are got. Then, these centers and radii of clusters are used as the parameters of Radial Basis Functions (RBFs). Mapping the patterns in the original space into the kernel space by these RBFs, KKC is carried out in the kernel space and the new patterns are got in every cluster. The clusters are updated by the new patterns in the original space and the new centers and radii of clusters are provided. Then, the mapping and KKC are carried out again until the centers and radii of clusters in the kernel space are not changed any more. The proposed method is called Kernel Clusteringbased KC (KCKC).
The rest of this paper is organized below. First, the original KKC and the kernel clustering method are reviewed, respectively. Then, the framework of KCKC and the application of KCKC to some classical methods are given. Finally, conclusions and future work are given.
1 KKC and kernel clustering
1.1 KKC
The riginal KC[7] aims to divide the patterns into K parts by the unsupervised learning method and its steps are
shown in Ref. [7]. The objective is to minimize the objective function J, J=Kk=1Nki=1xi-mk2, where K means that there are K classes to cover these patterns, Nk is the number of patterns in the kth class, xi is the ith pattern in the kth class, and mk is the center of the kth class. When the patterns are linearly inseparable in the original space, the kernel trick is useful. Note that the nonlinear mapping :Rn→F,x→(x) is used to map the patterns in the original space into the kernel space. J=Kk=1Nki=1(xi)-mk2, where (xi) is the mapping representation of pattern xi in the original space and mk is the center of the kth class in the kernel space. In the kernel space, (xi)-mk2=k(x,x)-2Nki=1k(x,xi)+Nki,j=1k(xi,xj) and k(·,·) is a kernel function. This Kmeans clustering is also called KKC.[7]
1.2 Kernel clustering
Kernel clustering always has a good performance for nonlinear data sets. GAO et al.[6] proposed the Kernel Nearest Neighbor Classifier (KNNC) and introduced an original method for clustering. By KNNC, an nclass problem can be transformed into n twoclass problems. Then, the class is clustered as the object class. Patterns in this class are called the object patterns. Then, other classes are called nonobject classes, and the patterns in nonobject classes are called outliers or nonobject patterns. For object class CA in each twoclass problem, KA kernels (also called clusters) are used to cover object patterns. After finishing all the n twoclass problems, n groups of kernels come into being. Then, for a test pattern, the minimum quadratic surface distance D(A)q from the existing KA kernels in CA is computed. If there are n classes, there are n minimum quadratic surface distances. The minimum one is chosen as the distance from the test pattern to the existing kernels. Finally, a pattern is labeled according to the class label of the nearest kernel.
2 KCKC
KCKC consists of 5 steps. (1) Use the kernel clustering to cover these patterns from n classes by some clusters. (2) Use centers and radii of clusters as the parameters of RBFs. Then, there are C clusters, and μc and σc mean the center and radius of cluster Pc, c=1, 2, …, C. (3) Map patterns by these clusters. k(x,Pc)=exp(-x-μc/σc) is used to compute the distance between each pattern and the center of cluster Pc. Then, the pattern is put into the nearest cluster. Here, the cluster with the expression like RBF is also called a kernel. (4) Return to the original space and use the new patterns covered by the clusters to update the centers and radii. (5) In the kernel space, the previous two steps are redone again until the centers of clusters will not be changed.
3 Application of KCKC to other methods
In order to validate the effectiveness of KCKC, the RBFbased Neural Network (RBFNN)[89], RBFbased Support Vector Machine (RBFSVM)[1011] and KNNC[6] with kernels from KCKC, KKC and KC are compared. In terms of kernels from these kernel clustering methods, the RBF kernel k(xp,xq)=exp-xp-xq22σ2 is adopted. The difference between them is the setting of the parameter σ (kernel width). For KKC, σ is set to the average of all the pairwise l2norm distances xi-xj2, i,j=1,2,…,N between patterns as used in Refs.[1215]. Here, N is the number of patterns and xi is the ith pattern in the training set. For others, σ equals the width of a cluster.
3.1 Kernel clustering with RBFNN
The principle of RBFNN is shown in Refs.[89]. There is a pattern x={x1, x2, …, xd} as the input vector, and then for RBFNN dr=1wrjxr=f(hj) is used to compute the input of the jth kernel. Lj=1wjkf(hj)=g(ok) is used to decide the input of kth output unit, and then the pattern is labeled into the class whose output result is the largest, i.e., the largest c. In RBFNN, RBF is used as the kernel function of the activation function of the hidden unit. By RBF, a ddimensional vector can be mapped into an Ldimensional kernel space; if L is larger than d, the nonlinearly separable problem in the ddimensional space may be linearly separable in the Ldimensional space.
3.2 KCKC with RBFSVM
In the original RBFSVM kernel, the width and the center of the kernel are fixed for each kernel expression, and it is not flexible. In Ref.[16], a clustering method is used to gain some kernels covering all patterns and each kernel only covers patterns belonging to one class, where the kernels have different widths σ and centers μ. The generated kernels are used as the newproduced patterns N1,N2,…,NNCLU, where the number of kernels is NCLU. The label of each new pattern dN1 is the original class label of patterns covered by the present kernel. NCLU new patterns are used to train SVM and each new pattern is a kernel. In our proposed method, the generated kernels are used to replace these in Ref.[16], and experimental results also show this method outperforms SVM with original RBF kernels.
3.3 KCKC with KNNC
KNNC means that a pattern is labeled according to the minimum distance between the pattern and the surfaces of the existing kernels, and a kernel means a cluster that covers some patterns with the same class label. After kernel clustering, KNNC is used to test the test set. As we know, in NNC, the test pattern belongs to the nearest patterns class. In KNNC, by the chosen distance computing method, the distance from the test pattern to each kernel is computed. If the nearest kernel belongs to a class, the test pattern is also classified into the class. Here, the distance from the pattern to the kernel is defined as D=dp→cKr, where dp→c is the distance from the pattern to the center of a kernel, and Kr is the radius of the kernel. Furthermore, KNNC is carried out in the kernel space with kernels from KCKC. The difference is the center and radius of the new kernel and the distance should be computed in the kernel space.
3.4 Results from different kernels applied to RBFNN, RBFSVM and KNNC
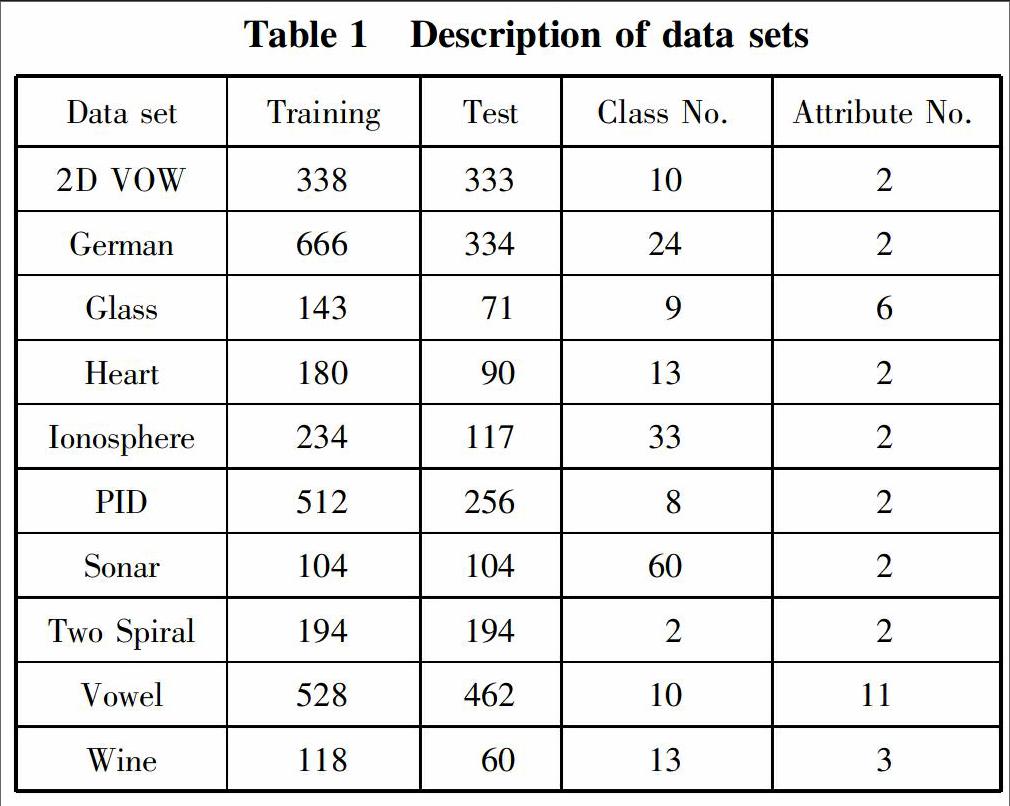
Table 1 gives the description of the adopted data sets.
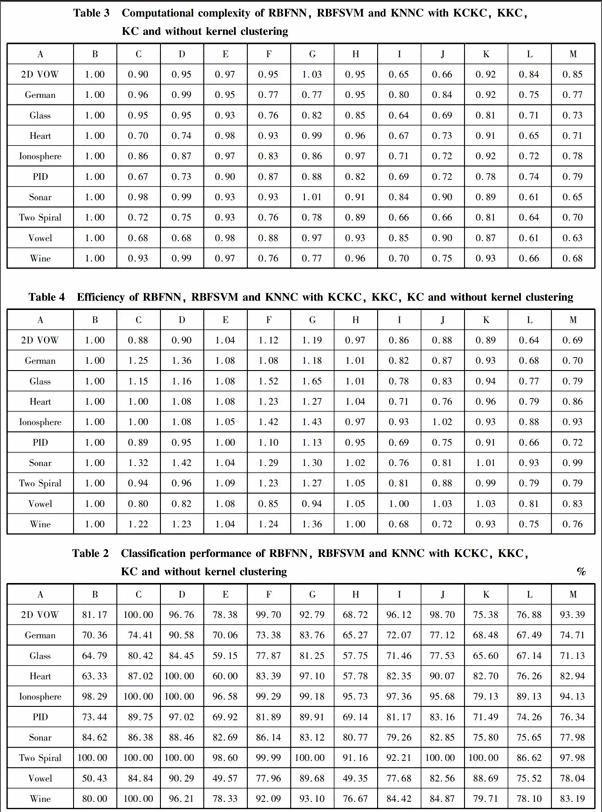
Table 2 shows the results of RBFNN, RBFSVM and KNNC with KCKC, KKC, KC and without kernel clustering. The algorithms about KKC used in RBFNN, RBFSVM and KNNC are like the method of KCKC. In terms of the cases without kernel clustering, KNNC, RBFSVM and RBFNN are used. In Table 2, A to M denote Data set, KNNC+KCKC, RBFSVM+KCKC, RBFNN+KCKC, KNNC+KKC, RBFSVM+KKC, RBFNN+KKC, KNNC+KC, RBFSVM+KC, RBFNN+KC, KNNC, RBFSVM and RBFNN, respectively.
From Table 2, it can be found that KCKC outperforms KKC and KKC outperforms KC. It can be said that KCKC is used to process the problem of unsupervised learning method KC and has better clusters in the kernel space. Since the structure of KCKC is more complicated than that of KC and KKC, their computational complexity and efficiency are also different. Table 3 and Table 4 show the differences about computational complexity and efficiency, respectively. For convenience, define the computational complexity (efficiency) of KNNC+KCKC as 1. In the two tables, the larger the value is, the larger the computational complexity (efficiency) is. Compared with KC and without kernel clustering, KCKC is of a larger computational complexity and a lower efficiency at average. But from the comparison between KCKC and KKC, we find that their computational complexities are similar while KCKC has a better efficiency. According to these three tables, we draw a conclusion that KCKC is of better classification performance although it is of a larger computational complexity and a lower efficiency sometimes.
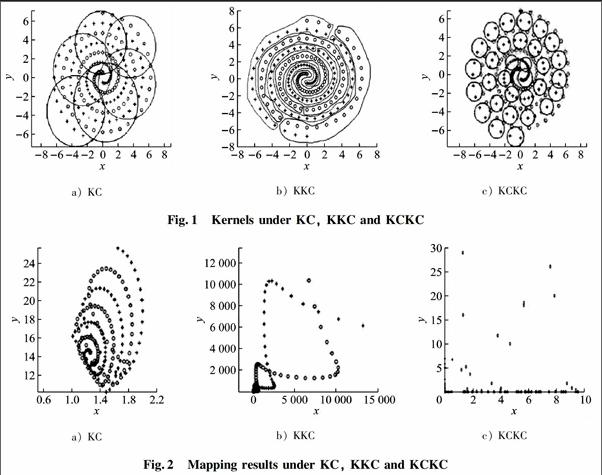
3.5 Distribution of kernels and the mapping results under two kernels with KCKC, KKC and KC
The “Two Spiral” data set is taken as an example, and the distribution of kernels and the mapping results under two kernels are given when KCKC, KKC and KC are carried out. For KC and KKC, predefine k = 6. Fig. 1 and Fig. 2 give the kernel distribution and the corresponding mapping results under KC, KKC and KCKC, respectively. Under KC, 2 kernels are chosen to map the patterns into a 2D space. In fact, 6 kernels will map the patterns into a 6D kernel space. Here, the showing under 2D is only given. In terms of the basic steps of KKC, circleshape kernels are generated in the kernel space, so in the original space, the kernels are not circles like the ones in Fig. 1a). It can be seen that new kernels can cover patterns well and only a small part of patterns are covered by wrong kernels. Comparing Fig. 2a) with Fig. 2b), it can be found that KC and KKC can not make patterns linearly separable in the kernel space, but the mapping results under KKC are better than those under KC. Then, for KCKC, the kernels cover patterns better in the original space as shown in Fig. 1c). From Fig. 2c), we find that KCKC makes patterns nearly linearly separable in the kernel space.
4 Conclusions and future work
A new kernelbased Kmeans clustering, namely KCKC, is proposed to replace KKC and Kmeans Clustering (KC). KCKC can avoid the problem of unsupervised learning method KC and improve the performance of KKC. By generating kernels with the alternating cycle between an original input space and a high dimensional kernel space, we can make the kernels more flexible. Furthermore, the ordinal KKC pays much time on the decision of the center of kernels in the kernel space. As we know, if a nonlinear mapping is continuous and smooth, the topological structures and the orders of the patterns will be maintained in the kernel space. So, during the processing of KCKC, the center and width of kernels can be estimated in the kernel space. This method can save the kernel generating time in the kernel space and avoid the sensitivity of setting K value. Furthermore, KCKC works well in other algorithms including the RBFbased Neural Network (RBFNN), the RBFbased Support Vector Machine (RBFSVM) and the Kernel Nearest Neighbor Classifier (KNNC). In the future research, more attention will be paid to the influence of different kernel clustering methods on KCKC using some image data sets.
References:
[1]HARTIGAN J A, WONG M A. Algorithm as 136: a Kmeans clustering algorithm[J]. Journal of the Royal Statistical Society: Series C (Applied Statistics), 1979, 28(1): 100108. DOI: 10.2307/2346830.
[2]JAIN A K, DUBES R C. Algorithms for clustering data[M]. London: PrenticeHall, Inc, 1988: 227229. DOI: 10.1126/science.311.5762.765.
[3]ZADEH L A. Fuzzy sets[J]. Information and Control, 1965, 8(3): 338353.
[4]YU S, TRANCHEVENT L C, LIU X H, et al. Optimized data fusion for kernel Kmeans clustering[J]. IEEE Transactions on Software Engineering, 2012, 34(5): 10311039. DOI: 10.1007/9783642194061_4.
[5]孔銳, 张国宣, 施泽生, 等. 基于核的K均值聚类[J]. 计算机工程, 2004, 30(11), 1214.
[6]GAO Daqi, LI Jie. Kernel fisher discriminants and kernel nearest neighbor classifiers: a comparative study for largescale learning problems[C]//International Joint Conference on Neural Networks. Vancouverj, BC, Canada, July 1621, 2006: 13331338. DOI: 10.1109/IJCNN.2006.1716258.
[7]BALOUCHESTANI M, KRISHNAN S. Advanced Kmeans clustering algorithm for large ECG data sets based on a collaboration of compressed sensing theory and KSVD approach[J]. Signal, Image and Video Processing, 2016, 10(1): 113120. DOI: 10.1007/s1176001407095.
[8]YEH Icheng, ZHANG Xinying, WU Chong, et al. Radial basis function networks with adjustable kernel shape parameters[C]//2010 International Conference on Machine Learning and Cybernetics (ICMLC). Qingdao, 1114 July 2011. IEEE, 2011: 14821485. DOI: 10.1109/ICMLC.2010.5580841.
[9]SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529: 484489. DOI: 10.1038/nature16961.
[10]XU Guibiao, CAO Zheng, HU Baogang, et al. Robust support vector machines based on the rescaled hinge loss function[J]. Pattern Recognition, 2017, 63: 139148. DOI: 10.1016/j.patcog.2016.09.045.
[11]WADE B S C, JOSHI S H, Gutman B A, et al. Machine learning on high dimensional shape data from subcortical brainsurfaces: a comparison of feature selection and classification methods[J]. Pattern Recognition, 2017, 63: 731739. DOI: 10.1016/j.patcog.2016.09.034.
[12]CUI Yiqian, SHI Junyou, WANG Zili. Lazy quantum clustering induced radial basis function networks (LQCRBFN) with effective centers selection and radii determination[J]. Neurocomputing, 2016, 175: 797807. DOI: 10.1016/j.neucom.2015.10.091.
[13]ZHU Changming. Doublefold localized multiple matrix learning machine with Universum[J]. Pattern Analysis and Applications, 2016, 128. DOI: 10.1007/s1004401605489.
[14]ZHU Changming, WANG Zhe, GAO Daqi. New design goal of a classifier: global and local structural risk minimization[J]. KnowledgeBased Systems, 2016, 100: 2549. DOI: 10.1016/j.knosys.2016.02.002.
[15]ZHU Changming. Improved multikernel classification machine with Nystrm approximation technique and Universum data[J]. Neurocomputing, 2016, 175: 610634. DOI: 10.1016/j.neucom.2015.10.102.
[16]GAO Daqi, ZHANG Tao. Support vector machine classifiers using RBF kernels with clusteringbased centers and widths[C]//Proceedings of International Joint Conference on Neural Networks. Florida, USA, August 1217 2007. IEEE, 2007. DOI: 10.1109/IJCNN.2007.4371433.
(Editor ZHAO Mian)
猜你喜欢
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
