
基于抽样的不确定图k最近邻搜索算法
2017-07-10 10:27:26张伟
计算机应用与软件 2017年6期
张 伟
(东北大学计算机科学与工程学院 辽宁 沈阳110819)
基于抽样的不确定图k最近邻搜索算法
张 伟
(东北大学计算机科学与工程学院 辽宁 沈阳110819)
在诸如生物网络或社交网络等各种由不确定数据组成的网络中,不确定图是一种十分重要和普遍使用的数学模型。由于不确定图中计算两点连通概率问题是#P完全问题,其k最近邻查询问题要比确定图复杂得多,并且与“距离”的定义相关。采用“最短距离”作为距离定义,讨论了在不确定图是加权图的情况下,求解k最近邻搜索问题(k-NN问题)。为了克服计算两点连通概率带来的时间指数爆炸问题,提出了一个基于Dijkstra算法的抽样k-NN查询算法,研究了其收敛性和收敛速度,同时通过实验验证了所提出的方法效率优于kMinDist方法并且具有很高的查全率。
人工智能 不确定图 概率图 生物网络 k-NN 抽样技术
0 引 言
随着云计算和大数据时代的到来,由于数据获取存在噪声、网络传送存在误差、数据使用颗粒度差异等各种原因,使得我们面临大量不确定数据的处理问题。在各种不确定数据组成的网络(诸如生物网络、社交网络)中,不确定图(或称概率图)是一种十分重要和普遍使用的数学模型,对不确定图的搜索问题,也成为当前大数据研究当中的一个研究热点[1-3]。
在实际应用中,不确定图搜索问题十分常见。例如,在社交网络中,用节点表示用户,用边表示好友关系,则好友之间的影响程度就可由边上的概率来表示,从而构成一个不确定图;在城市的路网中,用节点表示地点,用边表示街道,则街道是否拥堵就可由边上的概率来表示,亦构成不确定图。不确定图的搜索问题,通常是“在社交网络中,与张三关系最密切的三个人是谁?”、“在城市路网中,从地点A到地点B最通畅的三条路径是哪些路径?”。这些问题(实质是k-NN问题)在确定图中是容易解决的,但是对不确定图而言它们就变得十分复杂[4-5]。
图1所示的是一个简单的不确定图,其中第一条边线上的括号(1∶0.5)表示节点A到节点B的长度是1,该边的存在概率是0.5,其他边也使用类似的表示。在可能世界模型下,图1的一个可能世界,亦称可能图例,如图1(b)所示,该可能世界的概率是0.5×0.3×0.7×0.8×(1-0.4)×(1-0.6)=0.02。
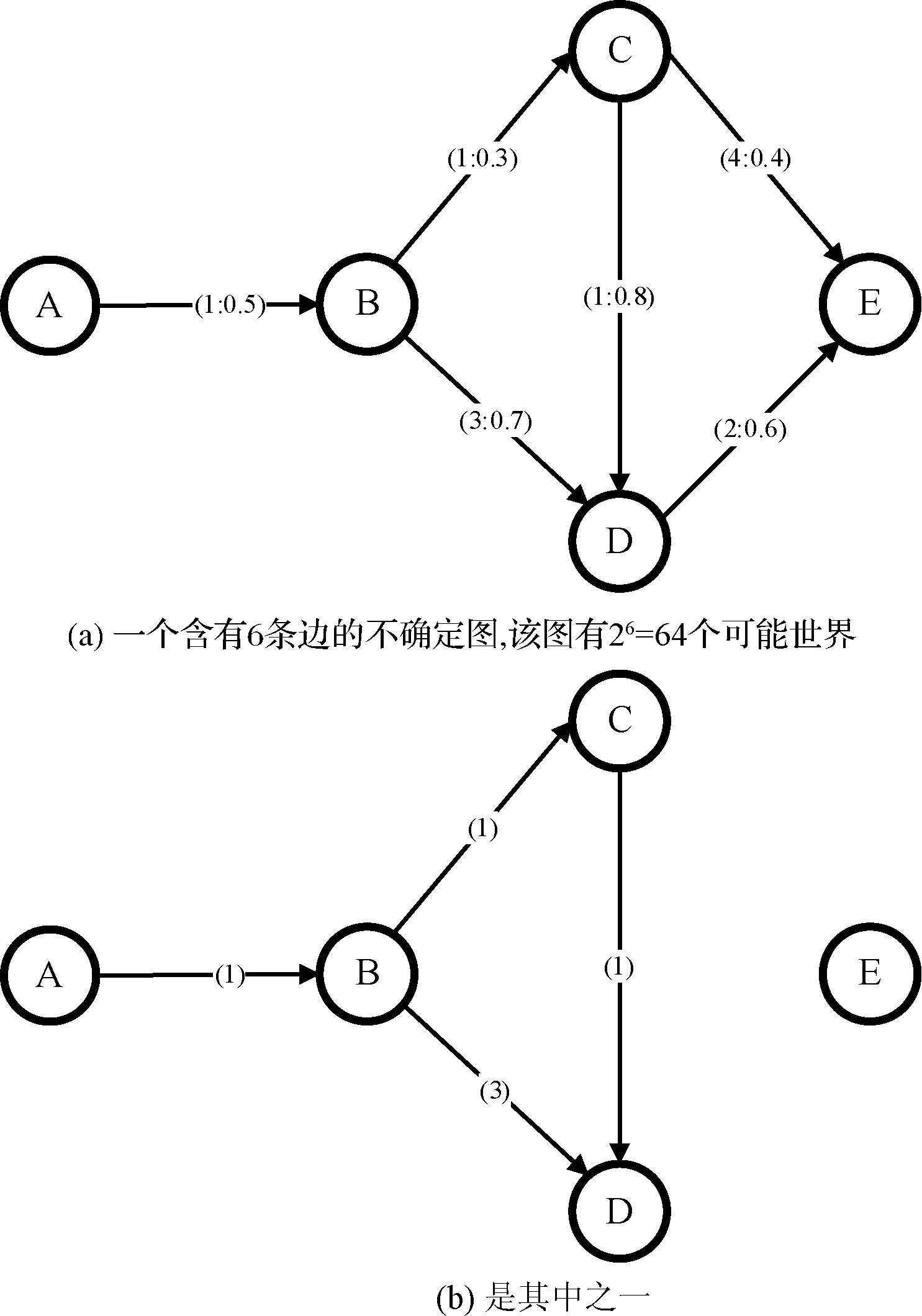
图1 一个简单的不确定图
对于图1(a),距离A点最近的两个节点,则有多种可能的答案:(1)按照文献[1]所定义的以实际距离(路径权值)占主导考虑因素的距离定义,答案是{B,C},因为B和C距A较近;(2)按照文献[2]所定义的最大可靠性距离定义(某些文献称之为概率可达性),答案是{B,D},其中节点A和B连通的概率是0.5,节点A和D连通的概率是0.5×(0.7+(0.3×0.8)-0.7×(0.3×0.8))=0.386,即A和B连通并且B和D至少有一条路径连通的概率。而节点A和C连通的概率则是0.5×0.3=0.15,故不选择C。注意,在最大可靠性距离中没有考虑路径的权值(长度)[6-8]。
由此可见,不确定图的近邻查询问题,比确定图复杂得多,并且与“距离”的定义相关。目前被研究者采纳比较多的“距离”定义主要有五种:(1)中位距离,其含义是:对于两个节点s和t,中位距离是一个最大的数字D,使得s到t的最短距离小于等于D的所有可能图例的概率之和不超过50%;(2)多数距离,其含义是:对于两个节点s和t,多数距离是一个数字d,使得s到t的最短距离恰好等于d的所有可能图例的概率之和最大;(3)期望可信距离,其含义是:两个节点s和t在所有可能图例中最短路径的期望长度;(4)最短距离,其含义是:两个节点s和t在所有可能图例中最短路径(即,在所有可能图例中的最短路径当中长度最小者)的长度,注意,该距离定义优先考虑路径的权值,路径的概率起辅助作用(详见下小节k-NN问题);(5)概率可达性距离,其含义是:两个节点s和t连通的概率[8-9]。
文献[10]以生物信息学中的蛋白质交互网和作者合作网络为背景,提出了适用于中位距离、多数距离和期望可信距离的k-NN查询算法。该算法使用了抽样和剪枝技术,实现了较好的搜索效率[10-11]。文献[10]提出了一个基于随机抽样的、可快速估计两点连通概率的算法,该算法也是面向最大可靠性距离的,如进行一定延展,可以扩展到不确定图的k-NN查询问题中。
文献[12]介绍了在一个有障碍物体的空间内查询一个特定点可见概率最大的k-NN近邻的算法。该算法是面向最大可靠性距离的,使用了剪枝技术和近似采样技术来提高搜索效率[12-13]。
然而,在很多不确定数据组成的网络应用中,上述的第4种距离定义(即“最短距离”)是最适合的距离定义。例如,在社交网络中有一类很常用的问题是好友推荐问题:当一个社交网络用户A向系统提出好友推荐要求时,怎么给他推荐好友呢?一个经常的做法是,考察A的好友B、C有没有共同的好友;如果B、C有共同的好友D、E,那么D、E很可能也是A感兴趣的人,就可以推荐给A。当D、E距A相等且只能给A推荐一个好友时,优先选择D、E中与A连通概率大的节点。这里使用的“距离”定义就是以路径长度为主导以概率为辅助的最短距离定义。文献[1]根据社交网络的这种特点,提出了最短距离的定义,并给出了一个k-NN查询算法。由于该算法是基于可能世界模型的朴素路径概率计算思想的,故效率受到一定限制。虽然文献[1]对其算法做了“公用边”优化,在一定程度上推迟了时间复杂度拐点的出现时间,但不能避免时间复杂度指数爆炸。
因为最短距离在社交网络中好友推荐类问题及相似的问题中有较好的应用意义,并且可以得到精确的计算结果,本文采用这个距离定义,并讨论在不确定图是加权图的情况下,求解k最近邻的查询问题。提出了一个基于Dijkstra算法的抽样k-NN算法,同时通过实验验证了本文所提出的方法效率优于文献[1]的kMinDist方法。
1 不确定图模型
虽然人们根据所探讨的具体问题提出过很多与不确定图相关的问题定义,但是以下概念是核心的、共同的[14-16]。
定义1(不确定图) 一个不确定图可由四元组G=(V,E,P,W)表示,其中V和E分别表示G含有的节点集和边集,变量P表示边上的概率集合,即P(e)表示边e∈E的存在概率,变量W表示边上的权值集合,即W(e)表示边e∈E的权值,我们约定W的值均为正整数。
定义2(可能世界模型) 对于一个不确定图G,我们按照概率P对G的边集合E进行一次采样得到边子集E’⊆E,则称由E’及V、W构成的确定图G’=(V,E’,W)为不确定图G的一个可能世界。
定义3 (最短距离) 对于一个不确定图G=(V,E,P,W)中的任意两个节点s和t,我们称s和t的最短距离是在所有可能图例中最短路径(即在所有可能图例的所有连通s和t的最短路径当中长度最小者)的长度[1],记为dL(s,t)。本定义采用了文献[1]的最短距离定义。
对于图1(a)而言,dL(A,D)=3。
与文献[1]相同,我们定义k-NN查询(即kMinDist查询)为:对一个源点s,找到它的k个最近邻节点,当其中长度最大的节点多于查询所需时,用路径概率PL(s,t)决定取舍(PL(s,t)路径概率是含有该(最短)路径的所有图例的概率之和)。这个k-NN定义意味着k-NN查询中距离不是最大的节点应直接进入查询结果集中,其他则须用概率决定取舍。
2 基于Dijkstra算法的k-NN查询算法
按照上述的距离定义,我们提出了一个基于Dijkstra算法并采用抽样技术估计连通概率的k-NN查询算法。首先,给出一个基础的k-NN算法,它采用两点连通概率的定义精确计算路径概率PL(s,t);当然基础算法存在指数爆炸的缺点。其次,我们给出了一个对基础算法的改进算法:它采用抽样技术来估计概率PL(s,t),进而解决k-NN查询。可以证明,该方法不仅克服了指数爆炸具有高效率,而且也具有很高的k-NN查全率和查准率。
我们首先讨论第一种方法,即基础的k-NN查询算法(亦称朴素k-NN算法)。
2.1 朴素的k-NN查询算法
查询一个不确定图的给定源点s的k个最近邻节点,可采用以下简捷的方法:
将不确定图G看成确定图,采用Dijkstra算法从源点s出发,找到距离s节点最短距离(≤d)的所有节点集T(这里d为记录当前离开s的距离阈值变量,初始时d=0),当|T|
上述求解k-NN方法可用算法语言形式描述如下:
算法1 Minimum Distance k-NN(G,s,k)
/* G是一个不确定图,s是源点,k是需要查询的节点个数 */
begin
置T :=∅;
令G’ = (V,E,W),其中V,E,W 与不确定图G=(V,E,P,W)中的相同;/* 此操作将不确定图G当作确定图G’来处理 */
d := 0; /* d为以源点s为中心的搜索范围半径,初始时为0 */
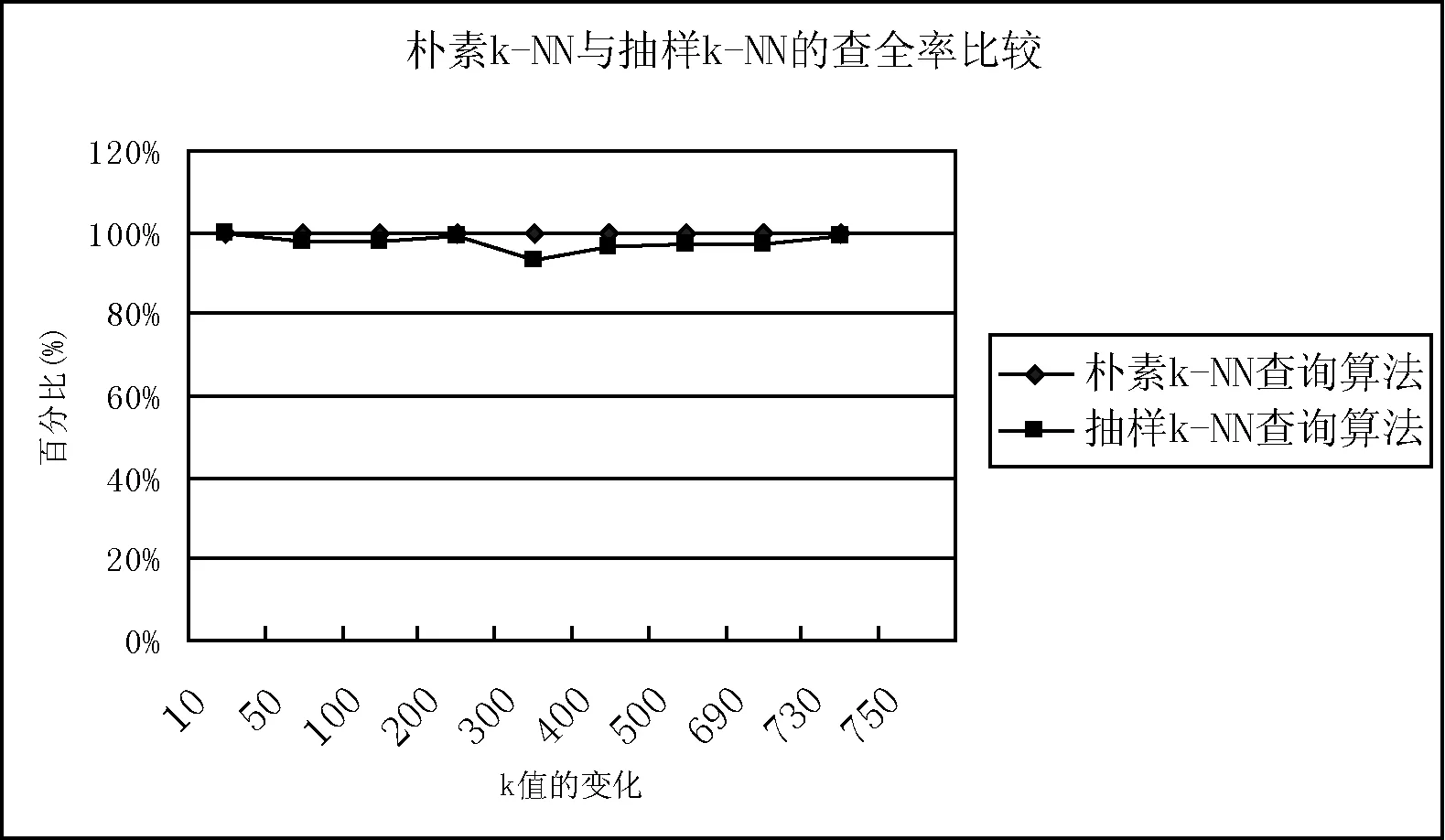
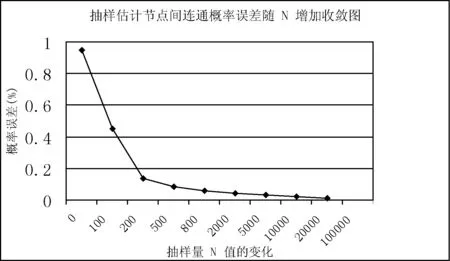
While (|T| begin Dijkstra (G’, s, d, T); /* 调用Dijkstra求取G’中离开源点s最短距离小于等于d的所有节点,放入T */ d := d+1; /* 递增d */ end; /* while */ If |T|=k then return(T); else /* |T|>k */ { for (tn1,…,tnj∈T with the largest dL(s,tni)) do { /* tn1,…,tnj是T中具有相等的最大dL(s,tni)的节点,要选取概率最大的几个留在T中*/ shortest-path-length = dL; ComputPL(G,s, tni, shortest-path-length); 按照PL(s, tni)(1≤i≤j)的从大到小顺序排列{ tn1,…,tnj},取前m个留在T中使|T|=k; Return (T); } /* for */ } /* else*/ end /* of the algorithm */ 这里Dijkstra算法是稍做修改的Dijkstra*算法,当同一个节点t离开源点s有多条最短路径时,Dijkstra*算法要记录所有这些最短路径。子算法ComputPL(s, t)计算源点s到节点t的最短路径概率,其算法描述如下: 子算法1 ComputPL(G,s,t,shortest-path-length) /* 这里G是不确定图,s是源点,t是当前节点,shortest-path-length是s到t的最短路径长度 */ begin PL(s, t) :=0; /* 初始化 */ 计算G中所有连通(s,t)的最短路径长度为shortest path-length的路径集合,记之为shortest-paths; 依shortest-paths删节G得到g,使g是G的子图且仅含shortest-paths中的边和节点,则g由源点s到节点t的长度为dL(s,t) 的所有最短路径组成; 生成g的所有可能图例集Pg; for Pg中的每个图例g’ do { If g’包含shortest-paths中的任一最短路径, then { 计算g’的概率Pr(g’): 累加Pr(g’)到PL(s, t)中: PL(s, t) := PL(s, t) + Pr(g’); } /* end of if */ } /end of for */ return(PL(s, t)); end /* Sub-Algorithm */ 该算法根据定义3的距离定义,求取k-NN查询时找到距离源节点s最近的k个节点集T,并在解决最后竞争时(离开s具有相同距离的多个节点全加入T使|T|多于k)将最短路径概率大者保留在T中。由于需精确计算最短路径概率,故其不能避免可能世界图例的指数爆炸。为了解决这个问题,我们提出了一个基于抽样技术的k-NN算法。 2.2 采用抽样技术的k-NN查询算法 理论和实验都表明,当k变大时,计算图中两点的最短路径概率是影响算法kMinDist[1]和本文的朴素k-NN查询算法(Minimum Distance k-NN算法)效率的关键因素。为了彻底避开可能图例的指数爆炸问题,我们对朴素Minimum Distance k-NN算法做以下改进,主要想法是放弃朴素k-NN查询算法查询最优k-NN的目标,转而求取近似最优k-NN来保持k-NN算法的高效率。 注意到本文的朴素算法Minimum Distance k-NN算法仅在计算(s,t)以最短路径连通的概率PL(s,t)时,才引发可能图例数量的指数爆炸。在下面的对该朴素算法的改进算法Approximate Minimum Distance k-NN中,对T中距离s最远的若干节点tn1,tn2,…,tnj(它们与s的距离相等)中,在计算PL(s,tni) (1≤i≤j)时,不再按照子算法ComputPL(s,tni)去逐一枚举连通(s,tni)的所有可能图例来计算源点s到节点tni的精确最短路径概率,而是抽取所有可能图例的一部分样本来估计PL(s,tni)的近似值。抽取可能图例的方法是:按照连通(s,tni)的子图中每个边的存在概率来决定该边出现与否,并组成图例。根据Chernoff引理,只要图例抽样个数N达到足够大,就可以保证估计的精确度,而N不是k-NN查询之k的一个指数函数,从而避免了指数爆炸。 改进算法按照上述最远点最短路径概率(估计值)较大原则,选取若干最短路径概率较大的节点保留在T中使|T|=k,而从T中删除其他最远节点。我们实现了这个算法Approximate Minimum Distance k-NN,并分析和验证了其不仅效率大大高于文献[1]的kMinDist算法,而且其给出的k-NN的查询结果具有令人满意的查全率(平均≥97%)。 算法Approximate Minimum Distance k-NN的伪代码形式描述与上节的算法Minimum Distance k-NN只有一条语句不同:即使用计算最短路径概率近似值的Approx-ComputPL′(G,s,tni,shortest-path-length)语句替代了前算法的计算最短路径概率之精确值的ComputPL(G,s,tni,shortest-path-length)语句。对应的子程序也相应改变: 子算法Approx-ComputPL′(s,t)采用抽样法计算源点s到节点t的最短路径概率的近似值,其算法描述如下: 子算法2 Approx-Comput PL′(G, s, t, shortest-path-length) /* 这里G是不确定图,s是源点,t是当前节点,shortest-path-length是s到t的最短路径长度 */ begin (1) N=0,M = 0; /* N表示需要抽取图例总数,其计算法见Chernoff定理;M为循环记数器*/ (2) number-of-I = 0; /*N个图例中使(s,t)以最短路径连通的图例个数*/ (3) 计算s到t的所有的最短路径集shortest-paths,根据该最短路径集组成一个子图g,使g是G的子图且仅含shortest-paths中的边和节点; (4) 子图g =(V,E)的所有的边组成一个向量(e1,e2…em); (5) while (M≤N) { /*循环N次*/ 对每边ei依该条边上的概率P(ei)选取“1”作为Xi的值(未能取1则取0),得到由{0,1}构成的 随机向量X = (X1,X2,…,Xm);随机向量X有2m种取值,代表所有可能图例;若X的当前取值代表的图例使(s,t)以最短路径连通,我们记I(X) =1,否则记I(X) =0; (6) if (I(X)==1) number-of-I = number-of-I + 1; (7) M=M+1; /* 递增循环计数变量M*/ (8) } /* end of while */ (9) return (number-of-I/N); /* number-of-I/N =PL′(s, t)就是节点s与节点t抽样算法得到的概率近似值*/ end /* Sub-Algorithm */ 该算法按照最远节点概率较大原则选取若干最短路径概率较大的最外层节点保留在T中仍可保证给出的k-NN的查询结果是最优k-NN查询的很好近似的原因有两个:(1)根据我们采用的文献[1]的最短距离dL(s,t)定义,所有非最外层节点应落入最优k-NN查询结果T中,该近似算法首先将所有非最外层节点选入k-NN查询结果T中;(2)对于最外层节点(它们与源点s的距离相等)tn1,tn2,…,tnj,要选取近似概率PL′(s,tni)最大的几个tni留在T中,使得|T|=k。我们通过大量的实验,证明了这种近似算法的有效性,它不仅效率大大高于朴素k-NN查询算法,而且其给出的k-NN的查询结果具有令人满意的查全率。 关于子算法Approx-ComputPL′(s,t)采用抽样法计算连通概率近似值PL′(s,t)时的取样容量N,我们有以下Chernoff定理[2]给出的取样容量N与估计概率值(与精确概率值)的误差关系作理论保障。 定理1 (Chernoff定理) 令X1,X2,…,XN是独立同分布的随机变量且它们有相同的期望值μ=E(Xi)。当N满足 那么有: 我们称N个样本(的平均值)给出了μ的一个(ε,δ)精度的近似,其中0≤ε≤1、0≤δ≤1分别是误差精度和置信度。 上述Chernoff定理在概率图k-NN查询问题中的一个直接应用[2]就是以下定理2。 定理2 令g是s到t的所有的最短路径组成一个子图、向量Xi=(e1,e2,…,em)是对g中所有边ek按照其存在概率抽样得到的一个图例,当Xi使(s,t)以最短距离连通时令I(Xi)=1,否则I(Xi)=0。显然I(X1),I(X2),…,I(XN)是独立同分布的随机变量且它们有相同的期望值E(Ii)=PL(s,t)。当N满足: 那么有: 在定理2的实际应用中,为了计算N,我们引进一个连通概率阈值ρ(通常为某个很小的常数,如ρ=0.001),当节点对(s,t)的(最短路径)连通概率PL(s,t)小于ρ时,认为k-NN查询可以忽略t,也即这样的t是我们不感兴趣的节点。于是定理2变为:当N满足: 有: 其中0≤ε≤1、0≤δ≤1分别是误差精度和置信度,ρ是预先给定的一个很小的常数。 定理2的最后形式既给出了抽样容量N与近似连通概率误差的关系,也为我们计算N提供了理论公式。下一节的实验验证了该公式的准确性。 为了验证上述算法的有效性,我们在美国Enron公司的邮件网络数据[1,10]上进行了k-NN查询实验。该邮件网络把每个邮件帐户看作一个网络节点,如果帐户i曾经向帐户j发送过一个邮件,就认为节点i与节点j之间存在一条无向边。这个网络有36 692个节点、183 818条边。我们对数据进行了预处理:为每条边附加了一个随机产生的概率值,使之成为不确定图,每条边的权值为1。于是,每条边附加的信息为:(1:p),其中1为权值、p∈[0,1]为概率值[10,17-19]。 3.1 实验环境 我们实验的硬件为主频率为2.6 GHz的双核CPU、4 GB内存、硬盘500 GB的PC台式计算机,操作系统为Windows XP,编程环境为VS2010集成开发平台,编程语言为C++语言。 3.2 实验1 本实验主要显示本文的朴素k-NN查询算法(Minimum Distance k-NN)的效率。我们对美国Enron公司的邮件网络数据进行了抽取以减小其图数据的分枝系数(即,出边数),使每个节点连接的边不超过7条,抽取到的不确定图数据Data1的节点个数N=200,边数为665条;Data2的节点个数为663节点,边的条数为1 785;Data3的节点个数为3 480节点,边的条数为6 815。本实验中我们采用数据集Data3 ,观察k-NN查询的k由50至730不断增长时,算法为了得到查询结果所需要的时间(时间单位为毫秒ms)。 图2所示的是本文给出的朴素k-NN查询算法(Minimum Distance k-NN)所耗费时间随k变化的情况。我们知道,求取最短路径的概率要枚举含有最短路径的子图上的可能世界模型的所有图例,是最耗费时间的计算步骤,也是决定k-NN算法效率的关键因素。上述实验表明,朴素k-NN算法的时间复杂度会发生急速上升(指数爆炸),拐点是在k=690处。这个实验表明,在k较大时,即使求取一次两节点连通概率都可能引发指数爆炸。 图2 朴素k-NN查询算法的时间复杂度随k值变化的过程 3.3 实验2 实验2主要比较本文提出的朴素k-NN查询算法(Minimum Distance k-NN)与抽样k-NN查询算法(Approximate Minimum Distance k-NN)的效率及查全率(recall ratio)。我们采用的不确定图数据Data3是从Enron邮件数据中抽取的:节点个数为3 480节点,边的条数为6 815时,观察k-NN查询的k由10至750不断增长时,朴素k-NN查询算法、抽样k-NN查询算法为了得到查询结果所需要的时间(时间单位为毫秒ms),同时考察两算法的查全率变化情况。抽样算法的参数为ε=0.1,δ=0.1,ρ=0.01。 从图3中我们可以看到,抽样k-NN查询算法效率比朴素k-NN查询算法高得多,因为它只对实际可能世界中的N个图例(N是常数)计算路径的概率,减少了一个指数级复杂度的计算。朴素k-NN查询算法在k大于690后时间复杂度开始急剧上升,而抽样k-NN查询算法则一直没有骤然上升的情况。同时,从查全率和查准率来看(这里查全率指:抽样k-NN查询所得的k个节点与标准定义的k-NN查询所得的k个节点的交集的势除以k所得的比例[20]。显然针对本文的k-NN定义,查准率等于查全率),朴素k-NN查询算法的查全率和查准率(当然)是100%;而抽样k-NN算法也保持了很高的查全率和查准率(平均≥97%),在实际应用中表现很好(如图4所示)。 图3 朴素k-NN查询算法与抽样k-NN查询算法的时间比较 图4 朴素k-NN查询算法与抽样k-NN查询算法的查全率比较 我们也将本文的抽样k-NN查询算法与文献[1]提出的“共用边”优化kMinDist算法的效率进行了比较。实验表明(见图3所示),该优化算法较之朴素k-NN只是推迟了指数爆炸而不能避免它,而抽样k-NN算法则避免了指数爆炸。 3.4 实验3 我们对抽样法近似计算连通概率近似值PL(s,t)的收敛速度(相对于抽样容量N)进行了研究。针对不确定图数据Data1、 Data2和Data3,我们以朴素k-NN查询算法(可以)计算出的节点间连通概率为基础真实概率数据,考察抽样算法计算的相应节点间近似连通概率的误差的绝对值随着抽样量N的变化趋势。我们做了k取不同值时的k-NN实验,并记录了在对应的k个节点上的近似连通概率与真实连通概率误差的平均值(这里‘对应的k个节点’是指用抽样算法近似计算出的k-NN节点集与真实k-NN节点集交集节点上的概率误差)。在图5中,以抽样算法计算近似概率的抽样容量N为横轴,以近似概率误差为纵轴,画出了绝对概率误差的平均值随着抽样量N的变化曲线。 可以看出,概率误差随着N的增加而迅速收敛。通常可在N≥2 000的范围内收敛到误差不超过10%。这是相当好的结果,它为抽样算法既保持较高的查询搜索速度又保证高查全率提供了抽样容量N的经验数据。 图5 抽样估计节点间连通概率之误差随抽样量N的增加而变小 在各种不确定数据组成的网络(诸如生物网络、社交网络)中,不确定图(或称概率图)是一种十分重要和普遍使用的数学模型,对不确定图的搜索问题,也成为当前大数据研究当中的一个研究热点。依据参考文献[1],本文采用最短距离作为不确定图的节点间距离定义,并讨论在不确定图是加权图的情况下,求解最近k近邻的查询问题(k-NN问题)。本文提出了一个基于Dijkstra算法的抽样k-NN算法,同时通过实验验证了本文所提出的方法效率优于以前的方法。 [1] 张旭,何向南,金澈请,等. 面向不确定图的k最近邻查询 [J]. 计算机研究与发展, 2011,48(10):1871-1878. [2] Potamias M,Bonchi F, Gionis A, et al. K-nearest neighbors in uncertain graphs[J].The VLDB Journal, 2010,3(1):997-1008. [3] 华斌,杨超.主成分分析在复杂网络社区发现的应用[J].计算机应用与软件,2015,32(9):261-263. [4] 张硕,高宏,李建中,等.不确定图数据库中高效查询处理[J].计算机学报, 2009,32(10):2066-2079. [5] Beskales G, Soliman M A, Ilyas I F. Efficient search for the top-k probable nearest neighbors in uncertain databases[J]. Proceedings of the Vldb Endowment Vldb Endowment Hompage, 2008, 1(1):326-339. [6] 张伟,俞瑞钊,何志均. 可采纳搜索算法最坏复杂度的下确界[J].计算机学报,1990,13(6):449-455. [7] 梁聪,唐振华.一种基于DCT域局部能量的多聚焦图像融合算法[J].计算机应用与软件,2016,33(5):235-238. [8] 信俊昌,王国仁,公丕臻,等. 不确定数据库中的阈值轮廓查询处理[J]. 计算机研究与发展,2009, 46(5):126-132. [9] 黄冬梅,邓斌,赵丹枫.带权不确定图的K最近邻查询算法[J].计算机应用与软件,2016,33(2):212-216. [10] 袁野,王国仁. 面向不确定图的概率可达查询[J].计算机学报, 2010,33(8):1378-1386. [11] Aggarwal C C. Managing and mining uncertain data: advances in database systems[M].New York: Springer,2009:77-107. [12] 李传文,谷峪,李芳芳,等.一种障碍空间中不确定对象的连续最近邻查询方法[J].计算机学报,2010,33(8):1359-1368. [13] 王艳秋, 徐传飞, 于戈,等. 一种面向不确定对象的可见k近邻查询算法[J]. 计算机学报, 2010, 33(10):1943-1952. [14] 梁美丽,牛之贤.改进的综合颜色纹理特征图像检索[J].计算机应用与软件,2014,31(6):228-231. [15] 于戈,谷峪,鲍玉斌,等.云计算环境下的大规模图数据处理技术:挑战与进展 [J]. 计算机学报,2011,34(10):1753-1767. [16] 张伟,洪声贵. 基于GAG的Horn逻辑分布式推导模型[J]. 辽宁大学学报,2012,39(4):1-6. [17] 周林,晏立,沈项军.基于边密度的复杂网络社区结构划分方法[J].计算机应用与软件,2013,30(12):8-11. [18] 唐德权,吴绍兵,凌志刚.一种新的图聚类算法研究[J].计算机应用与软件,2014,31(6):18-20. [19] 亚森·艾则孜,李卫平,郭文强.复杂网络中基于WCC的并行可扩展社团挖掘算法[J].计算机应用与软件,2016,33(6):37-39. [20] Jiang L, Cai Z, Wang D. Bayesian citation-knn with distance weighting[J].International Journal of Machine Learning and Cybernetics,2014,5(2):193-199. K-NEAREST NEIGHBOR SEARCH ALGORITHM FOR UNCERTAIN GRAPHS BASED ON SAMPLING Zhang Wei (CollegeofComputerScienceandEngineering,NortheasternUniversity,Shenyang110819,Liaoning,China) Uncertain graphs are a very important and widely used mathematical model in networks composed of uncertain data such as biological networks or social networks. Since the two-point connectivity probability problem in the graph is a complete problem, the k nearest-neighbor query problem is much more complex than the normal graph and is related to the definition of "distance". Using the shortest distance as the definition of distance, we discuss the k-nearest neighbor search problem (k-NN) under the condition that the uncertain graph is a weighted graph. In order to overcome the problem of time exponential explosion caused by computing two-point connectivity probability, a sampling k-NN query algorithm based on Dijkstra algorithm is proposed. The convergence rate and convergence rate are studied. The proposed method is proved to be more efficient than kMinDist method and has high recall rate. Artificial intelligence Uncertain graphs Probability graph Biological network k-NN Sampling technique 2016-07-07。国家科技支撑计划项目(2014BAI17B01);软件开发环境国家重点实验室开放课题(SKLSDE-2012KF-02)。张伟,教授,主研领域:人工智能,机器学习。 TP311.13 TP392 A 10.3969/j.issn.1000-386x.2017.06.033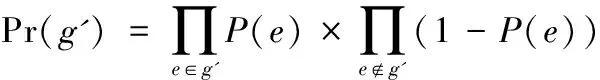
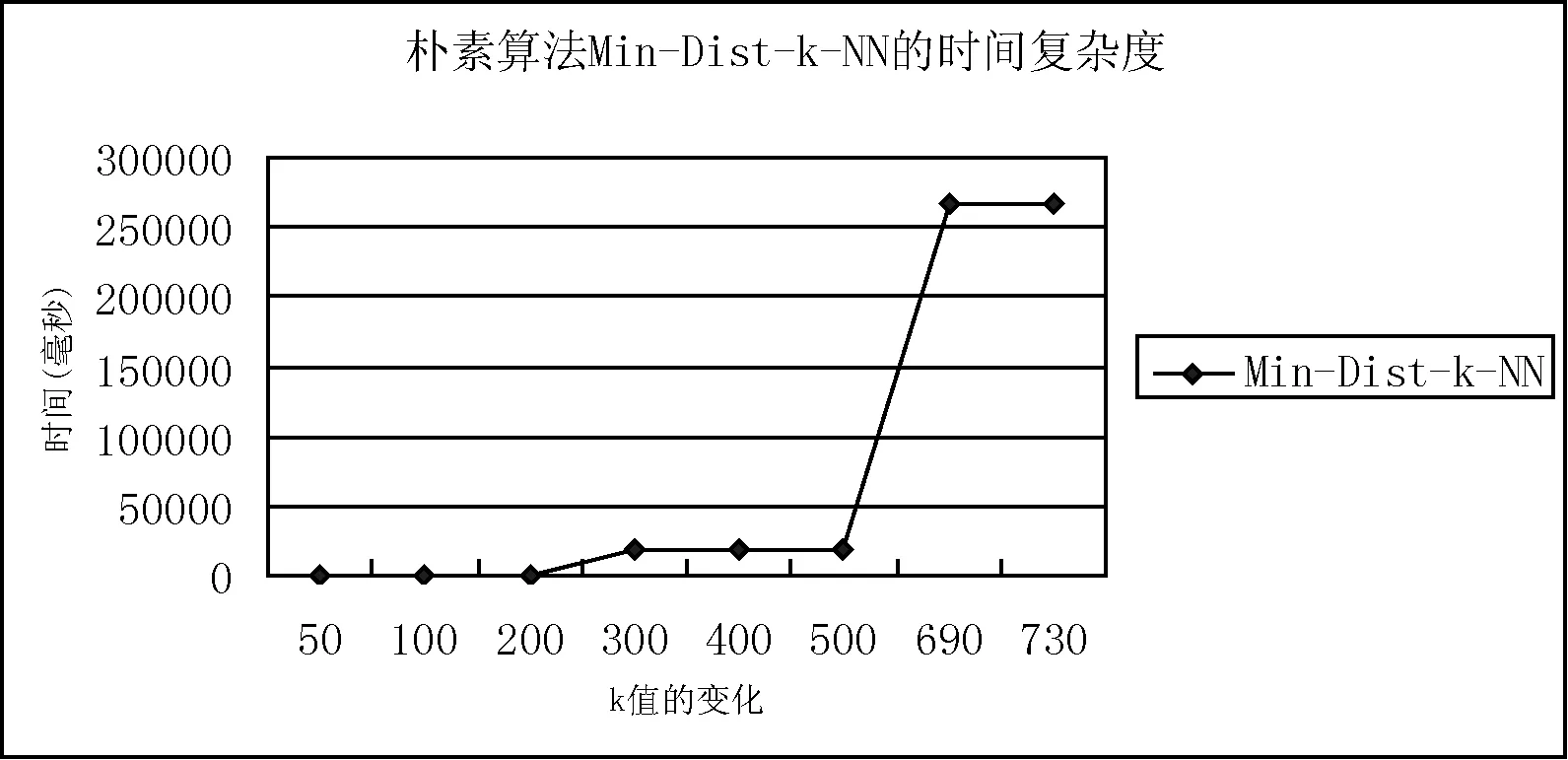
3 实验结果与性能比较
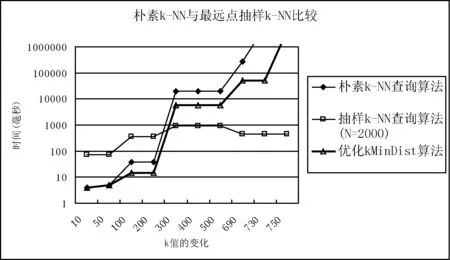
4 结 语
猜你喜欢
格言·校园版(2025年2期)2025-02-13 00:00:00
现代电子技术(2018年20期)2018-10-24 04:39:04
小朋友·快乐手工(2018年7期)2018-08-15 11:08:56
老年教育(2018年6期)2018-07-06 08:03:18
现代情报(2018年11期)2018-01-07 09:41:14
外语学刊(2017年3期)2017-12-07 01:45:38
新课程·上旬(2017年8期)2017-09-24 00:07:06
陕西理工大学学报(社会科学版)(2017年1期)2017-03-02 10:50:35
中国科技博览(2016年27期)2017-01-23 04:18:13
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
