
基于多模态字典学习的微视频场所类别识别
2017-07-05 12:59:40张江龙黄祥林
中国传媒大学学报(自然科学版) 2017年4期
张江龙,黄祥林
(中国传媒大学 理工学部,北京 100024)
基于多模态字典学习的微视频场所类别识别
张江龙,黄祥林
(中国传媒大学 理工学部,北京 100024)
微视频的迅猛增长为对微视频的有效管理及利用带来新的挑战,本文对微视频的场所识别进行研究。场所信息可带来一些潜在的多媒体应用如:地标/场所检索、地理位置摘要生成、城市计算和基于地理位置服务。但是由于微视频的音频部分表达能力不强,这大大地影响到微视频场所信息的表达。为此,本文提出了一个基于多模态字典学习算法。该算法能借助外部音频信息来增强微视频音频部分的表达。大量的实验证明了该算法的有效性。
微视频;场所类别;多模态;字典学习
1 引言
传统视频分享网站的流行,大大地改变了互联网。这些视频分享网站允许用户录制高质量、长时长的视频,并分享给其他用户。但是自从2012年底,用户挖掘视频的方式发生了巨大的改变:微视频在不同的社交网络上快速增长。国内也出现了录制微视频的应用,比如秒拍;在2016年底,中国最流行的社交网络微信也推出了一个限制拍摄时长为10秒的微视频拍摄功能。
微视频除了具有简洁性、真实性和成本低等优点,社交网络鼓励用户在上传微视频的同时也签到其地理位置信息。智能手机或移动设备的GPS能够智能地列出其所在位置可能的位置选择,比如在一栋大楼中一层餐厅,还是二层的办公室,用户手动选择的这些场所位置。Foursquare等地理位置提供商自动把这个地理位置映射到场所类别。识别用户及其上传多媒体的地理位置信息有潜在应用及意义,如地标/场所检索、地理位置摘要生成、城市计算和基于地理位置服务。
微视频包含三个模态:视觉、听觉和文本模态,每个模态的表达能力差别很大,例如听觉模态远远不如视觉模态,这会造成模态表达的“木桶效应”。本文针对这问题,提出一种基于多模态字典学习的微视频场所类别识别框架。该框架包含两部分内容:外部音频数据库的建立和音频增强多模态字典学习的算法(acouStic enhAnced multI-modaL dictiOnary leaRning,SAILOR)。具体地,首先定义了几百个和生活有紧密关联的声学概念(acoustic concepts),并假设这些声学概念在微视频的音频中也存在的。接着通过这些声学概念到互联网去爬取相应的音频素材,并作为本文的外部音频资源库。在第二部分,本文通过多模态字典学习模型框架把外部音频模态和微视频的音频模态无缝地融合起来。这是通过假设它们之间共享一个空间的字典联系起来的。最后通过这个模型去判断未知场所的微视频类别。
接下来的章节安排:首先介绍现有的多模态字典学习及音频概念检测等相关工作;第三节详细描述增强多模态字典学习(SAILOR)算法;第四节给出实验的结果及分析,最后总结全文。
2 文献综述
2.1 字典学习
一般地,把字典学习分为:无监督字典学习和有监督字典学习。无监督字典学习的主要思想:在大量无标签的数据中学习得到的字典能够尽可能重构原始信号。1993年,Mallat[1]提出了基于小波分析提出了信号可以用一个超完备字典(Over-complete Dictionary)进行表示,并引进了匹配追踪算法(Matching Pursuit,MP),从而开启了超完备字典的稀疏表达的先河。Olshausen 和 Field[2]显示了自然图片和哺乳动物大脑的视觉感知皮层的关系。同时提出了一个不同的稀疏表达模型,该模型可以从训练数据自适应地学习超完备字典,并使用最优方向算法(Method of Optional Directions,MOD)分别对字典和稀疏表达进行交替更新。其不仅能够限制了模型的稀疏性,同时对字典进行L2范式限制,以防止字典元素过于大而引起过拟合。然而当训练数据比较大的时候,MOD的训练时长比较长。因此为了处理大量数据的训练,Elad等[3]提出一个快速的字典学习方法K奇异值分解方法(K-Singular Value Decomposition,K-SVD)。K-SVD使用奇异值分解的方法依次对字典的单个原子(atom)进行更新。在每轮迭代中,只有被使用的到原子才会更新,这样大大减少了运算量。Mairal等[4]提出一个在线的算法来学习字典,来进一步提高学习效率。无监督字典学习在不少学习领域虽然取得很大的成果,但是其只注重信号的重构能力(reconstruction ability),因此不少学者在此基础上对在任务分类能力(dicriminative capability)进行了不少的研究。该类的研究主要利用任务数据的标签来增加字典学习模型的判别能力,因此也称有监督字典学习。Mairal等[5]对于每个分类类别学习一个字典,这种基于类别的字典(task-specific dictionary)能够增强字典的判别能力。Wang等[6]先从训练数据中学习出来的字典及其表达,接着把其表达放入到分类器中去进行训练。 但是,其把字典学习和分类器的训练分开学习而成,这种方式不能同时优化字典学习和分类损失。为此,Mairal等[7]提出一个任务驱动字典学习(task-driven dictionary learning)方法,把分类的损失函数加入到字典学习中,来一起训练字典和分类模型的系数。Zhu等[8]更进一步考虑把领域知识的适用性(domain adaptability)加入到有监督字典学习,进一步提高分类器的判别性。
目前大多的字典学习是单模态的,即其训练数据只包含单模态。在Zheng等[9]工作中,一个共有的字典(common dictionary)和几个特殊视角的字典(view-specific dictionary)同时被学习出来,并应用于多视角运动识别。这些特殊视角的字典是用于表达不多视角的特征,而共有字典则是表达不多视角的共同特征。这种方法属于任务驱动字典学习,但是其不能用在异构多模态的字典融合。Monaci等[10]提出一种多模态字典学习模型(Multi-modal Dictionary Learning,MDL)来提取多模态特征的经典模板。该模板可以捕捉动态瞬时多模态信息,并可以用在同时恢复多模态信息。Zhuang等[11]学习多模态字典,并使用单个模态去检索多模态信息。但是这种方法并没有利用模态之间的关系去做特征融合。Bahrampour等[12]提出一个多模态任务驱动字典学习(Multimodal Task-Driven Dictionary Learning,MTDL),即可以融合异构多模态特征,又考虑了分类模型的判别性。本文提出的算法也属于有监督多模态字典学习,但是同上述算法不同的是,本算法使用外部资源来增强字典的表达能力,从而提高模型的表达和判别能力。
2.2 音频概念检测
对用户生成视频的音频概念检测是一个相对较新的领域[13]。从音频概念模型角度考虑,其可以分为基于数据驱动(data-driven)[14]和任务驱动(task-driven)[15]两种方法。对于视频的音频概念检测的主要动力是:音频能够为特定事件提供补充信息,特别是当有些图片或视觉信息很难捕捉的到信息。最近几项研究[14,15],表明了检测音频事件比单纯使用基于特征学习方法更加能够填补底层特征语义与高层语义之间的关系。本文也是基于这个考虑,使用音频概念检测来为最终的微视频的内容分析做准备。
3 多模态字典学习算法
微视频本身就是多模态的(视觉和听觉模态),每个模态都带有互补信息,它们之间的融合可以包含各自模态所不能表达的信息。基于这个考虑,微视频的场所识别问题是多模态的问题。本小节包含以下两个部分:1)介绍传统MDL的不足;2)总结增强多模态字典学习(SAILOR)的介绍。
MTL,其可以通过以下公式的优化获得字典和稀疏表达:
(1)


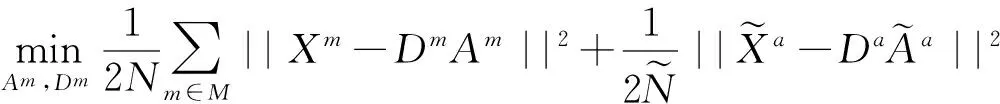
(2)

(3)
其中δm是个半径参数,在此简单地等价于所在第m个模态样本特征空间欧式距离的中值。公式(2)的最后一项表示样本表达的顺畅性,但是这一项直接求解比较困难,为了简化优化目标,可以进一步把其写成
(4)
(5)
一般可以通过梯度下降方法去对公式(5)求解。
4 实验及结果分析
本实验的数据库,包含了276,264个微视频,442个场所类别。使用两种测度来评估结果:宏F1(Macro-F1)和微F1(Micro-F1)。
4.1 音频模态表达
为了理解音频模态特征的代表性,本文首先学习不同音频特征表达的效果。本文分别抽取了短时频谱能量(spectrum)、梅尔倒谱系数(MFCC)和堆叠去噪自解码(SDA),其维度分别513、39和200维。其中spectrum和MFCC的窗大小为46ms加上50%的重复率,两种池化方式:最大值池化和平均值池化分别应用在每个音频的所有窗函数中。而SDA则是通过spectrum的平均池化的结果去训练。由于外部数据是带有标签的,每个音频代表一个音频概念,因此可以使用带标签的数据来了解特征的代表性。本实验报告10折交叉验证的均值和方差来验证不同特征的代表性,测量尺度为Micro-F1和Macro-F1,其结果如表1所示。从表1可以观察到:1)对于spectrum特征,平均值池化得到Micro-F1和Macro-F1效果,都比最大值池化的效果好。2)而对于MFCC的结论和spectrum却是相反的。这可能是由于MFCC包含语义比spectrum高,因此最大值池化的效果会好。3)MFCC最大值池化的效果比spectrum平均值池化效果好。4)SDA无论在Micro-F1还是在Macro-F1的效果都比其他好不少。本文对SDA和其他方法做学生测试(t-test),发现其p-value的值都远小于0.05,这说明了SDA的代表性比其他特征表达方法显著。因此接下来的音频特征表达使用的是SDA。
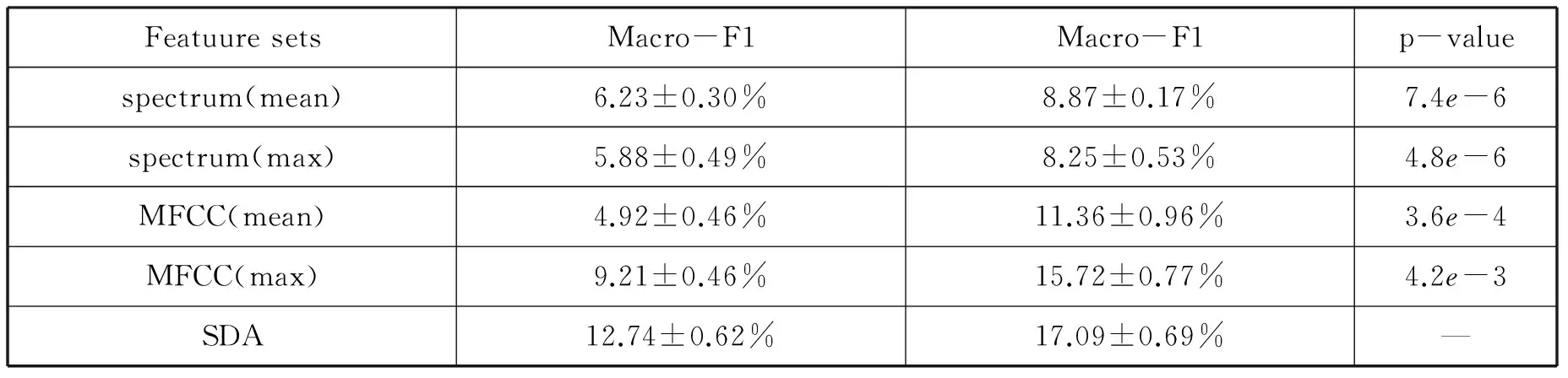
表1 不同音频特征的表达性
4.2 模型比较
本文把SAILOR与以下几个基准算法进行比较:
1)晚期融合(late fusion):该方法把每个模态特征单独训练softmax模型,最终把模型综合起来决定最终结果。
2)任务驱动字典学习(task-driven dictionary learning,D3L):该方法是字典学习的有监督版本,其可以利用标签信息来增强模型的判别性。本文分别对各个模态进行任务驱动字典学习,最终利用晚期融合算法来判别最终结果。
3)多模态字典学习(Multimodal Dictionary Learning,MDL):该方法利用了模态之间的联合稀疏表达来增强字典的表达能力,其属于特征前期融合领域。最终学习出来的稀疏表达,再通过softmax分类器进行训练。
4)多模态任务驱动字典学习(Multimodal Task-driven Dictionary Learning,MTDL),该方法不仅在多模态特征层学习共同稀疏表达,而且在决策层使用判决分数来共同决定结果。
5)SAILOR-e:这是SAIOLR版本的缩减版本,其不借助外部音频资源,即不考虑公式(2)的第二项。
6)SAILOR-rs:这是SAIOLR版本的缩减版本,其不考虑特征表达的顺畅性,即不考虑公式(2)的最后一项,把λ2设置为0。
7)SAILOR-sc:这是SAIOLR版本的缩减版本,其不考虑特征表达的稀疏性,即不考虑公式(2)的第三项,把λ1设置为0。
不同模型比较结果显示在表2中,其列分别表示模型方法,Micro-F1,Macro-F1和p-value。由表2可以观察到:1)所有的字典学习方法在Micro-F1测度上都比晚期融合算法好,这说明了稀疏表达的有效性。2)MDL表现比D3L要好,这说明了联合稀疏表达能够增强字典之间的表达能力。3)TMDL比MDL略好,说明了任务驱动字典学习可以增强单纯使用多模态字典学习模型的判别性。4)SAILOR比其他模型都好,包括TMDL,这更加确定了微视频听觉模态表达的不足,需要借助外部资源来增强模型表达。5)SAILOR比其他SAILOR缩减版本算法要好,这同时说明了借助外部音频资源,模型表达的顺畅性和稀疏表达的必要性。
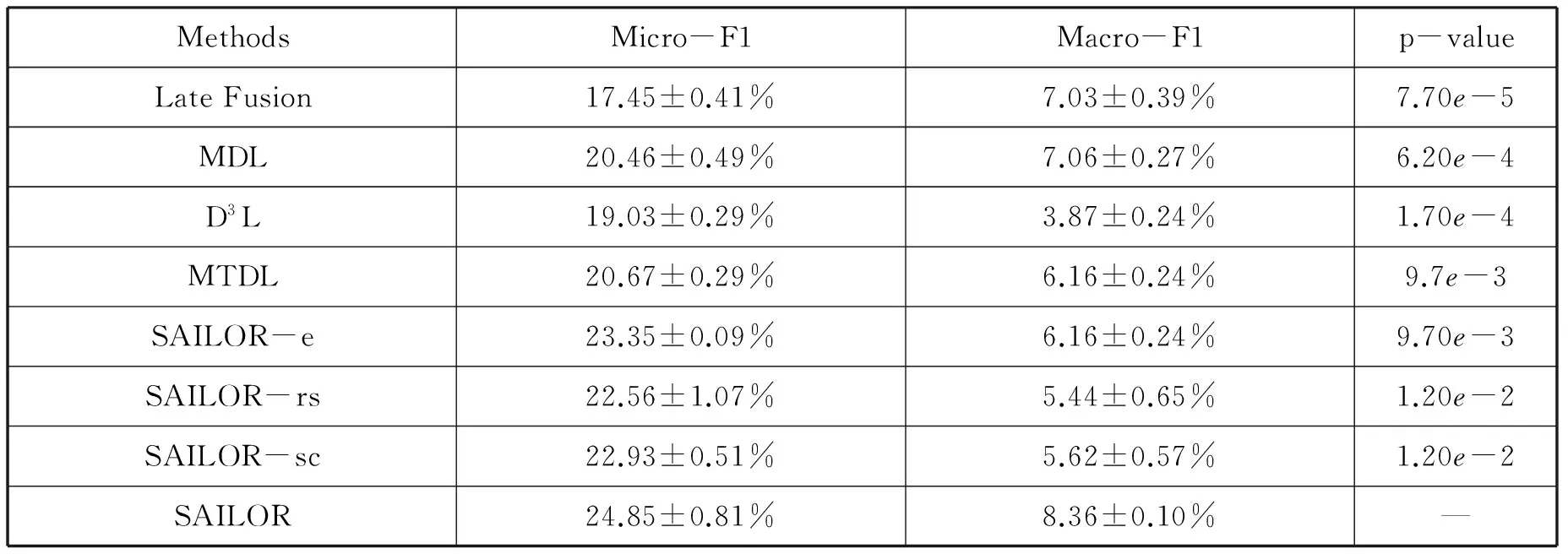
表2 不同模型性能的比较
5 总结
首先介绍了字典及音频概念检测的相关工作。接着分析传统的MDL的两个不足,引出本文提出的算法SAILOR,该方法基于两个重要的假设,从这两个假设出发,详细介绍了SAILOR的建模。最后通过音频模态的表达和模型比较的实验来验证了SAILOR的有效性。
[1]Daubechies I.The wavelet transform,time-frequency localization and signal analysis[J].IEEE Transactions on Information Theory(TIT),36(5):961-1005,1990.
[2]Olshausen,Bruno A,David J Field.Sparse coding with an overcomplete basis set:A strategy employed by V1[J].Vision research,37(23):3311-3325,1997.
[3]Aharon,Michal,Michael Elad,Alfred Bruckstein.K-SVD:An algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing(TSP),54(11):4311-4322,2006.
[4]Mairal J,Bach F,Ponce J,Sapiro G.Online dictionary learning for sparse coding[J].International Conference on Machine Learning(ICML),689-696,2009.
[5]Mairal J,Bach F,PonceJ.Task-driven dictionary learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI),34(4):791-804,2012.
[6]Wang S,Zhang L,Liang Y,Pan Q.Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis[J].IEEE conference on Computer Vision and Pattern Recognition(CVPR),2216-2223,2012.
[7]Mairal,Julien,Jean Ponce,Guillermo Sapiro,Andrew Zisserman,Francis R Bach.Supervised dictionary learning[J].Advances in Neural Information Processing Systems(NIPS),1033-1040,2009.
[8]Zhu F,Shao L.Weakly-supervised cross-domain dictionary learning for visual recognition[J].International Journal of Computer Vision(IJCV),109(1-2):42-59,2014.
[9]J Zheng,Z Jiang.Learning view-invariant sparse representations for cross-view action recognition[J].IEEE International Conference on Computer Vision(ICCV),3176-3183,2013.
[10]G Monaci,P Jost,P Vandergheynst,B Mailh’e,S Lesage,R Gribonval.Learning multimodal dictionaries[J].IEEE Transaction Image Processing(TIP),16(9):2272-2283,2007.
[11]Y Zhuang,Y Wang,F Wu,Y Zhang,W Lu.Supervised coupled dictionary learning with group structures for multi-modal retrieval[J].Association for the Advancement of Artificial Intelligence(AAAI),1070-1076,2013.
[12]Bahrampour,Soheil.Multimodal task-driven dictionary learning for image classification[J].IEEE Transactions on Image Processing(TIP),25(1):24-38,2016.
[13]Ravanelli M,Elizalde B,Ni K,Friedland G.Audio concept classification with hierarchical deep neural networks[J].IEEE European Signal Processing Conference(EUSIPCO),606-610,2014.
[14]Pancoast,Stephanie Lynne,Murat Akbacak,Michelle Hewlett Sanchez.Supervised acoustic concept extraction for multimedia event detection[J].ACM international workshop on Audio and Multimedia methods for large-scale video analysis,9-14,2012.
[15]Castan D,Akbacak M.Segmental-GMM Approach based on Acoustic Concept Segmentation[J].International Speech Communication Association(INTERSPEECH),15-19,2013.
(责任编辑:宋金宝)
Multi-modal Dictionary Learning towards Venue Category Estimation from Micro-videos
ZHANG Jiang-long,HUANG Xiang-lin
(Faculty of Science and Technology,Communication University of China,Beijing 100024,China)
The rapid development of micro-videos poses great challenges for multimedia management and retrieval.To alleviate this problem,we focus on venue category estimation from micro-video.The spatial information embedded in micro-video benefits multifaceted application,such as location/venue retrieval,landmark summarization,city computing,and location-based services.However,we find that the audio tracks embedded in micro-videos are less representation among three modalities,which greatly hinder the venue expression of micro-videos.Towards this end,we proposed a novel multi-modal dictionary learning approach.This approach is capable of borrowing external audio source to enhance the micro-videos.Extensive experiments conducted on a real-world data set have demonstrated the effective of our proposed model.
micro-videos;venue category;multi-modal;dictionary learning
2017-03-28
张江龙(1987-),男(汉族),福建泉州人,中国传媒大学博士研究生.E-mail:zhangjianglong135@126.com
TP
A
1673-4793(2017)04-0034-06
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
现代装饰(2020年7期)2020-07-27 01:28:32
计算机技术与发展(2019年1期)2019-01-21 00:56:38
小学生必读(中年级版)(2019年6期)2019-01-11 09:17:10
中国现当代社会文化访谈录(2016年0期)2016-09-26 08:46:13
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
