
基于自动编码器的语音音色客观评价
2017-07-05 12:59:37涂中文赵艳明宋金宝
中国传媒大学学报(自然科学版) 2017年4期
涂中文,赵艳明,宋金宝
(1.中国传媒大学 播音主持艺术学院,北京 100024;2.中国传媒大学 信息工程学院,北京 100024)
基于自动编码器的语音音色客观评价
涂中文1,赵艳明2,宋金宝2
(1.中国传媒大学 播音主持艺术学院,北京 100024;2.中国传媒大学 信息工程学院,北京 100024)
本文详细介绍了嗓音识别和深度学习的基本原理,然后阐述了怎样将深度学习理论应用于嗓音质量识别分析的研究中,从基于深度学习的语音特征参数提取和神经网络模型建模两方面入手,首先提取不同的音频特征参数,然后构建以稀疏编码器为核心的堆栈式自动编码器,“封顶”softmax分类器以构成完整的深度学习网络,最后测试了不同特征参数、不同的网络层数和网络节点数对于实验准确率的影响。
语音音色;客观评价;自动编码器
说话人的嗓音质量识别包含在说话人识别之内。说话人识别又称声纹识别,是对说话人产生的语音信号进行分析处理,提取说话人的个性特征,从而对说话人进行辨认或确认,是人的一种身份认证形式。说话人的嗓音质量信息也蕴含在这些个性特征中,专业上可以将人的嗓音特质划分16对,如厚与薄、干与润等。在播音类艺考这样对嗓音质量有严格要求的场合下,对嗓音质量的分析与选拔具有广阔的应用需求市场。作为近年来发展迅速的一种神经网络模型,深度学习模拟人类大脑的学习方式,对海量数据量具有超强的建模能力,并且对于不完全信息具有良好的鲁棒性,广泛应用于多分类模式识别,在图像、语音识别等领域取得了惊人的效果。
1 嗓音质量主观评价标准
由于现今尚未出版系统、严谨、明确的音质评价客观评价体系,所以本实验采用国内主流的林达悃老师的主观评价理论[1]。在该理论中,音质主观评价的结果受到四个方面因素的影响:①主观评价用语的统一性、明确性;②评价人的评价素质保证;③评价素材的代表性;④传输系统声学特性的规范化。
主观评价用语的统一性、明确性。音质主观评价用语主要有两大类:艺术语言和音乐。本实验研究的嗓音质量就是针对艺术语言质量的分析。艺术语言采用两级评价标准,即音质良好用语/音质不足用语,包含:通/不通,有弹性/木,集中/散(以上3对为必要条件),亮/暗,窄、扁、横/空,柔/硬,刚/硬,圆/鼻音、闷、喉音、卡、挤,实/空、飘,(缺)/沙、哑,纯、净/浊,(缺)/炸,润/干,(缺)/抖,亲切、有力度/字音分裂,共16对。
在本研究中,评价用语沿用上述16对标准用语,评价者均为业界较为认可的专家,评价素材产出于经过选拔的、具备专业素质的专业人员,样本生产环境为标准配置的无噪录音室,满足主观评价体系的四点要求。
图1给出了说话人嗓音质量识别系统框图,和语音识别系统一样,建立和应用这一系统可以分为两个阶段,即训练阶段和识别阶段。在训练阶段,系统每种嗓音特质的说话人说出若干训练语句,系统据此建立每种嗓音特质的模板或模型参量参考集。而在识别阶段,待识别嗓音特质语音中导出的参量与训练中的参考参量或模板进行比较,并且根据一定的相似性进行判断。
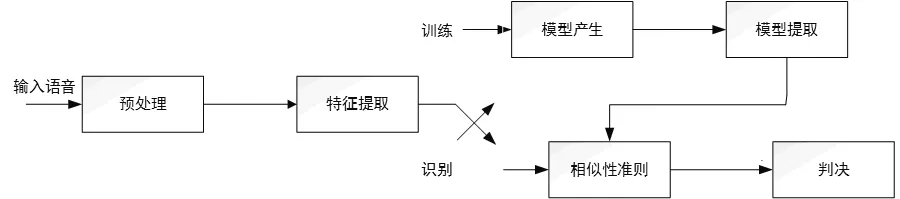
图1 嗓音质量识别系统框图
2 说话人识别研究发展与现状
说话人的嗓音质量信息包含在说话人的被识别的信息内,对嗓音的分析属于说话人识别的分支,所以对说话人的识别研究在理论和操作上同样适用于对嗓音的分析。说话人识别的研究最早开始于20世纪30年代,早期的工作主要集中在人耳听辨实验和探讨听音识别的可能性方面。随着研究手段和工具的改进,研究工作不再仅仅局限于单纯的人耳听辨。1962年,Bell实验室的研究通过可见的语谱图进行人工说话人识别,并将语谱图称为声纹(Voiceprint),意思是同指纹类似。美国法院在1966年第一次采用了此方法进行取证。20世纪60年早期的说话人研究中,几乎所有的工作都使用语音时频能量分析。之后,随着计算机技术和电子技术的发展,使通过机器自动识别人的语音成为可能。Bell实验室的S.Pruzansky提出了基于统计方差分析和模式匹配的说话人识别方法,其间的工作主要集中在各种识别参数的提取、选择和实验上,并将倒谱和线性预测法分析等方法应用于说话人识别,从而引起了信号处理领域许多学者的注意,形成了声纹识别研究的一个高潮。
随着计算机技术的发展,七十年代起开始自动说话人识别相关领域的研究。70年代中期B.S.Atal研究了LPC稀疏、自相关系数、声道的冲激响应、声道的面积函数及倒谱系数等不同的特征参数在自动说话人识别中的有效性,并通过实验指出倒谱系数是较为有效的语音特征。从此,说话人识别的方法和技术在近几十年来得到了更加迅速的发展。识别模型从单模板模型发展到多模板模型,从模板模型发展到矢量量化模型、高斯混合模型、隐马尔科夫模型,再到人工神经网络;识别环境从无噪声环境下对少数说话人的识别发展到复杂环境下对大量说话人识别:所采用的识别技术从仅涉及动态规划发展到涉及统计信号处理、矢量量化与编码、莫不系统理论与方法、最优估计理论、人工神经网络、灰色系统分析等多学科领域。
如今,说话人识别技术已逐渐走向实际应用。AT&T应用说话人识别技术研制出了智慧卡(smart card),已用于自动提款机。欧洲电信联盟在电信与金融结合领域应用说话人识别技术,于1998年完成了CAVE(Caller Verification in Banking and Telecommunication)计划,并于同年又启动了PICASSO(Pioneering Call Authentication for Secure Operation)计划,在电信网上完成了说话人识别。
3 基于稀疏编码的堆栈式自动编码器的建模分析
3.1 堆栈式稀疏自动编码器原理[5]
如果给定一个神经网络,假设其输入与输出是相同的,然后训练调整其参数,得到每一层的权重。输入的几种不同表示(每一层代表一种表示),这些表示就是特征(representation)。自动编码器就是一种尽可能复原输入信号的神经网络,为此,自动编码器就必须捕捉到可以代表原信息的主要成分。
自动编码器的训练过程可分为以下3个步骤:
(1)输入无标签数据,采用非监督学习方式学习特征。
(2)通过编码器产生特征训练下一层,逐层训练。
(3)输入有标签数据,采用监督学习方式微调。
3.2 堆栈式稀疏自动编码器建模分析
本研究中,采用样本的MFCC[5]及其一阶差分参数、LPC以及这两者的结合作为网络的输入,构建的堆栈式自动编码器根据原理可以分为以下4个模块。
(1)输入数据的向量化处理
对样本提取特征后,得到的是一个个excel文件,训练网络时需要将数据集打包成向量形式的矩阵,包括数据Datafeature×samples矩阵和标签Label向量。其中Data的每一列表示一个样本,即将原来一个excel数据表降维reshape成一个列向量,需要注明的是,原数据的打包方式不影响后续模型训练过程中深层特征的提取。Label矩阵实质上是一个列向量,样本的标签用阿拉伯数字从0开始表示。
(2)稀疏自动编码器
每层隐藏层均为稀疏自动编码器,采用逐层贪婪[4]训练法来训练每层自动编码器,训练方法是用梯度下降法对目标损失函数(Cost-Function)求导,使之局部收敛到最小值,在这个过程中不断更新当前层的权值W2、b2和前一层的权值W1、b1,并由W1生成当前层的激励值a2,即更深层的特征,作为下一隐藏层的输入z3。此梯度下降法采用反向传播算法(back-propagation,BP)来计算每一步梯度,即对W和b的导函数,见式7-13。
目标损失函数定义为J(W,b),由3部分组成:均方差项Jcost,权重衰减项Jweight和稀疏性惩罚项Jsparse:
J(W,b)=Jcost+λJweight+βJsparse
(1)
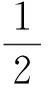
(2)
(3)
(4)
其中λ是权重衰减参数,β是控制稀疏性惩罚因子的权重。
梯度下降法中,对W和b进行更新:
(5)
(6)
其中α是学习速率,且:
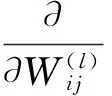
(7)
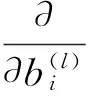
(8)
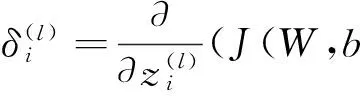
(9)
对于输出层,即nl层,没有稀疏性限制,有:
(10)
对于隐藏层,即l=nl-1,nl-2,……,2层,有:

(11)
最终,
(12)
(13)
在本实验中,每次下一层都作为输出层来对待,所以当前层更新权重参考的残差来源于第nl层,参考式10,上一层更新权重参考的残差来源于当前层,认为是第nl-1层,参考式11。图2为两层隐藏层权重W和b的更新示意图。
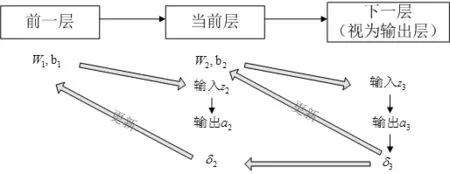
图2 W,b更新流程图
(3)softmax分类器
当所有层的自动编码器都预训练完备后,需要封顶一个分类器,并输入有标签数据来训练这个分类器,达到分类识别的作用。假设共有k中分类标签,样本集构成为
(14)
与稀疏自动编码器一样,采用梯度下降法计算分类器代价函数的梯度,然后更新分类器的权重。记输入x的每一种分类结果y=j,j=1,2,……k的概率为p(y(i)=j|x(i);θ),有

(15)
softmax分类器的代价函数J(θ)与自动编码器的代价函数不同,它仅由两部分组成:判断正确的概率Jcost(θ),权重衰减项Jweight(θ)
J(θ)=Jcost(θ)+Jweight(θ)
(16)
(17)
(18)

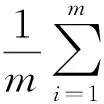
(19)
θj每次迭代更新为:
θj=θj-α▽θjJ(θ)(j=1,…,k)
(20)
(4)微调(fine-tuning)
在本实验中,所采用的微调方式是将所有隐藏层和分类器看成一个整体进行更新。其糅合了稀疏性自动编码器与softmax分类器更新方式的特点,也是采取BP算法进行权重更新,此时系统整体的error是softmax分类器的损失函数,所以从后向前推,所以除softmax分类器层外,每一层自动编码器的残差error都是来自后一层,即满足
(21)
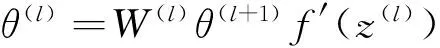
(22)
4 实验结果分析
本实验中,实验样本为2686个不带标签的音频样本和672个标签为由“厚”到“薄”划分6个等级的有标签样本,672个有标签样本中400个样本用于训练,272个样本用于测试。选择MFCC、LPC以及二者的结合作为神经网络的输入;隐藏层的节点数在200~800范围内;隐藏层层数范围在2~4层。以下是改变某一变量时测试准确率的变化情况,具体数据参见附录。
4.1 音频特征参数对实验准确率的影响

(a)2层隐藏层下不同特征参数的准确率分布图

(b)3层隐藏层下不同特征参数的准确率分布图
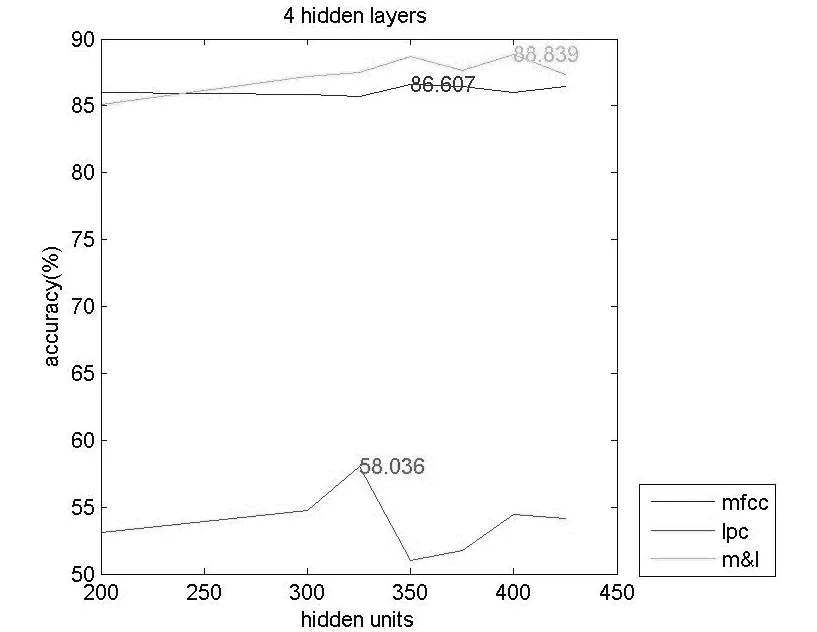
(c)4层隐藏层下不同特征参数的准确率分布图图3 不同隐藏下不同特征参数的准确率分布图
图3中的3张图分别是2层隐藏层、3层隐藏层和4层隐藏层的结构下,以MFCC参数、LPC参数以及两者结合作为输入时,测试准确率的分布情况。总体来说,以LPC参数作为输入时,识别准确率最高在59%左右,但MFCC参数作为输入时,识别准确率最高达到88.8%,识别能力显著提高。另外,以MFCC&LPC参数作为输入时,其识别准确率相较于MFCC又有微小的提升,这从侧面也反应出在这种高准确率下,MFCC参数对实验准确率的贡献远高于LPC参数对实验准确率的贡献。
4.2 网络层数对实验准确率的影响
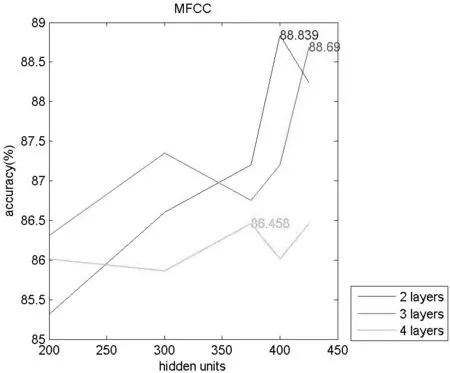
(a)MFCC参数下,不同隐藏层层数时的准确率分布图

(b)MFCC&LPC参数下,不同隐藏层层数时的准确率分布图图4 不同特征参数下不同隐藏层层数时的准确率分布图
以上2张图片分别是以MFCC参数和MFCC参数与LPC参数相结合作为输入时,2层隐藏层、3层隐藏层和4层隐藏层结构下识别准确率的对比。当输入为MFCC参数时,3层隐藏层的网络结构能达到最高的识别率(注意MFCC此时还有上升的趋势),接近89%,2层隐藏层的网络结构的准确率稍低,4层隐藏层的网络结构识别准确率最低。但当输入为MFCC&LPC时,仅2层网络层就可以达到很好的识别效果,识别准确率有91%,3、4层隐藏层的网络结构时的准确率都只有88%左右。由此说明最优的网络层数受到输入参数选择的影响,且网络层数并非越多越好,在某一范围内其作用效果最佳,低于或高于这个范围,其会阻碍实验准确率的提高。
4.3 网络节点数对实验准确率的影响

图5 3层隐藏层下不同特征参数时的准确率分布图
上图反映了网络节点数对识别准确率的影响状况:不管是LPC参数、MFCC参数还是两者结合,随着隐藏层节点数的增加,识别准确率随之增加;当隐藏层节点数达到一定值时,识别准确率不再增加,持平或发生微小的抖动。
以上各组实验说明,在较少的有标签样本情况下,构建堆栈式自动编码器+softmax分类器的深度神经网络,选择MFCC&LPC特征参数为输入,采取两层隐藏层,隐藏层节点数在450左右时,对嗓音分析的准确率可以达到91%,实现较好的分类效果。
5 总结与展望
5.1 总结
深度学习是当前机器学习领域的一个热门研究课题,在图像、语音处理等多个方面具有很强的应用价值[3]。而自动编码器在标签样本数据量不足的情况下,通过输入无标签数据预训练网络,初步提取网络参数,再通过有标签数据进行微调,可以很好的克服这个限制。嗓音也可以作为一个人的身份特征信息,特别在对人嗓音条件有严格要求的场合下,基于深度学习的嗓音分析的模型的建立,可以有效地节省人力资源,并保证相当高的准确率。
本文主要以深度学习理论为基础,以语音特征提取和堆栈式稀疏自动编码器建模为切入点,以MATLAB为实验平台,较为系统地研究了深度学习在嗓音分析中的具体问题。实验结果证明,深度学习在嗓音分析研究上具有准确性和可靠性,堆栈式稀疏性自动编码器在少量有标签数据的限制下也能达到很好的分析效果。
5.2 展望
尽管本实验整体上符合目标预期,但在实验结果分析中,我们发现一个出乎意料的规律,就是在测试网络层数对识别准确率的影响时,不管输入是什么特征参数,在准确率最大值附近都有一个偏大的抖动,随后识别准确率会随着隐藏层节点数的增加恢复上升至一个平稳值。在将来,我们希望对这一特殊现象作具体研究与分析。
此外,本实验仅对一组声音特性做研究,后期应当广泛采集标签样本,系统完整地测试稀疏自动编码器对不同声音特性的识别准确率的作用效果。
[1]林悃达.录音中的监听与审听——关于音质主观评价的若干问题[J].广播电视信息,1995.
[2]余建潮,张瑞林.基于MFCC和LPCC的说话人识别[J].计算机工程与设计,2009.
[3]余凯,贾磊,陈雨强,徐伟.深度学习的昨天、今天和明天[J].计算机研究与发展,2013.
[4]YoshuaBengio,PascalLamblin,DanPopovici,HughLarochelle.GreedyLayer-WiseTrainingofDeepNetworks[J].NIPS,2007.
[5]BengioY.LearningDeepArchitecturesforAI[J].FoundationsandTrendsinMachineLearning,2009.
(责任编辑:宋金宝)
Objective Evaluation of Speech Timbre Based on Auto Encoder
TU Zhong-wen1,ZHAO Yan-ming2,SONG Jin-bao2
(1.School of Presentation Arts,Communication University of China,Beijing 100024,China;2.School of Information Engineering,Communication University of China,Beijing 100024,China)
This paper would first introduce the basic principles of voice recognition and Deep Learning in detail,then set forth how to put the theory of DL into use of voice quality recognition.Starting with extraction of the feature of audio signal,we then set up stacked auto encoder with sparse coding as the core and softmax classification as top.Finally,we take the different features as input and change the number of hidden layers and hidden unites to observe their impacts on validating accuracy.
speech timbre;objective evaluation;auto encoder
2017-04-05
涂中文(1979-),男(汉族),山东济宁人,中国传媒大学播音主持艺术学院高级工程师.E-mail:bytuzhongwen@cuc.edu.cn
TP391.4
A
1673-4793(2017)04-0008-06
猜你喜欢
星星·散文诗(2023年28期)2023-11-09 17:35:18
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
海峡姐妹(2017年12期)2018-01-31 02:12:21
制造技术与机床(2017年11期)2017-12-18 06:46:39
歌剧(2017年6期)2017-07-06 12:50:21
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2015年7期)2015-04-09 11:40:04
