
LS-Cluster:大规模多变量时间序列聚类方法
2017-06-29 12:00:34郑诚王鹏汪卫
计算机应用与软件 2017年5期
郑 诚 王 鹏 汪 卫
(复旦大学计算机科学技术学院 上海 201203) (复旦大学上海市数据科学重点实验室 上海 201203)
LS-Cluster:大规模多变量时间序列聚类方法
郑 诚 王 鹏 汪 卫
(复旦大学计算机科学技术学院 上海 201203) (复旦大学上海市数据科学重点实验室 上海 201203)
现有的关于多变量时间序列聚类的研究中所研究的变量规模均较少,而现实生活又经常会出现大规模多变量时间序列,因此提出了LS-Cluster算法,旨在对有上万变量的大规模多变量时间序列进行聚类。首先,将每个时刻的多变量时间序列转化成矩形网格,然后使用二维离散余弦变换对其进行特征提取。接着提出了LS相似度用于计算特征序列之间的相似程度。最后,采用层次聚类方法发现其中所蕴含的模式。实验结果显示,该方法在人工合成数据和真实数据上都有较好的效果和可扩展性。
大规模 多变量时间序列 离散余弦变换 LS相似度 聚类
0 引 言
在现实生活中,经常会出现同一时刻产生多个数据值的情况,这些数据值共同描述了当前的状态。例如在有上千个传感器结点的大规模传感器网络中,同一时刻会有上千个数据产生,这些数据共同描述了当前传感器网络的状态。又如在金融领域中,沪深股市共有2 000多支股票,在交易时间段内每一时刻就会产生2 000多个价格,这2 000多个价格共同描述了当前股市的状态。这些状态按照时间顺序排列就构成了一条序列,这种序列就叫作多变量时间序列。多变量时间序列广泛存在于金融、传感器网络、医疗等各种领域。本文旨在对这种有上千甚至上万个变量的大规模多变量时间序列进行聚类分析。对大规模传感器网络多变量时间序列以天为周期进行聚类,我们可以得到一年中哪些天的传感器状态是相似的,这对传感器网络的监测和维护有着重要的意义。对股票行情数据以交易日为周期进行聚类,我们可以得到一年中哪些交易日的行情是相似的,这可以作为投资者投资和决策的参考依据。在已有的研究工作中,其研究的多变量时间序列的变量数目均很少,在这些已有研究所使用的数据集中,变量数目最多的是EEG数据集[1],有64个变量。而在现实生活中又经常会出现有上千甚至上万变量的大规模多变量时间序列的数据,并且变量之间有一定的相关性。例如在大规模传感器网络、股票行情和大型服务器机房监控等数据中,变量数就有可能会达到上千甚至上万。因此有必要研究在大规模多变量时间序列下的聚类方法。本文中,我们提出了LS-Cluster聚类方法,和之前的研究工作不同,我们主要聚焦于处理变量数目非常多的大规模多变量时间序列,例如数千甚至上万个变量的多变量时间序列,并且方法考虑了变量之间的相关性。
首先,将多变量时间序列中每个时刻的每个变量的值放入矩形网格中,使得每个时刻的数据都形成一个矩形网格,然后我们使用二维离散余弦变换来对矩形网格提取特征,得到一个特征矩阵。从一个时刻到另一时刻的特征矩阵的变换可以看成是高维空间中的一个向量,我们把这种向量称为线段,所有的线段的序列我们称之为线段序列。从而,多变量时间序列可以用高维空间的线段序列来表示。为了进行聚类分析,我们提出了LS相似度来计算线段序列之间的相似程度,最后我们采用层次聚类来发现其中的模式并找出其中的离群点。
实验环节中,我们采取人工合成数据和金融数据来验证我们的方法。在人工合成数据上的实验结果显示我们的方法比其他的方法有更好的聚类效果和可扩展性。进一步的,我们在2008年上海证券交易所的1 120支股票行情数据上进行了实验。我们发现聚类结果和上证指数有着较高的一致性,并发现了一些离群点,说明了我们的方法得到了较好的聚类效果。
1 问题定义和相关工作
1.1 问题定义
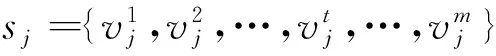
1.2 相关工作
文献[2]把构成多变量时间序列的每个单变量时间序列分别进行离散傅里叶变换,把变换后的结果分别保留前几个系数,并把这些系数连接起来作为特征。该方法把多变量拆分为单变量,使用单变量的特征提取方法进行特征提取,但是其忽略了变量之间的相关性。主成分分析(PCA)[3]是常用的多变量时间序列的特征提取方法,该方法通过寻找正交的方向向量,构成一个低维的特征空间,让各变量作为一个整体在该低维特征空间进行投影,从而得到一些新的互不相关的新的变量。该方法考虑了多变量之间的相关性,但对于不同的MTS其得到的新变量意义不同,破坏了MTS的同构性[4]。
Guan等提出了一种称为交叉相关系数矩阵的相似性度量方法[5]。文献[6]中,作者提出了一种基于主成分分析(PCA)的相似度度量方法Eros,用于度量多变量时间序列数据的相似度。文献[7]提出了一种基于点分布特征的匹配方法(PD),使用局部重要点来表示MTS,然而这样会导致丢失变量之间关联信息。文献[8]提出了一种基于二维SVD的相似度匹配方法——2DSVD,通过MTS的行-行和列-列协方差矩阵来得到特征向量,并利用Euclid范数来度量特征的相似度。
Yang和Zhou等提出了一种名叫HcluStream的聚类算法[9]。在文献[10]的研究中,采用基于分割的两步过程对多变量时间序列进行挖掘。Huang等使用朴素贝叶斯方法对时间序列进行聚类[11]。Owsley等使用隐马尔科夫模型来聚类多变量时间序列[12]。文献[13]中提出了基于PCA和K-Means的PCA-CLUSTER聚类算法。
2 提出的方法
2.1 概 述
首先,我们将多变量时间序列每个时刻所有变量的值都转化成矩形网格的形式。第二步,对矩形网格进行二维离散余弦变换,将变换后得到的系数矩阵的左上角的p×q部分作为特征矩阵。从一个时刻到另外一个时刻的特征矩阵可以形成一个高维空间中的向量,我们称这个向量为线段。所有的向量构成了一条线段序列。第三步,使用本文提出的LS相似度(LineSequenceSimilarityMeasure)来计算任意两条线段序列之间的相似度以得到相似度矩阵。最后,通过第三步得到的相似度矩阵使用层次聚类方法进行聚类。
2.2MTS的矩形网格表示
为了对大规模多变量时间序列进行聚类分析,首先需要对其进行转换。方法是将MTS中每个时刻所有变量的值放入一个矩形网格中。例如有10 000个变量就可以一一对应放入100×100的网格中,变量放置的次序可以是任意的,只要每次都将同一变量放在同一位置即可。
2.3 基于二维离散余弦变换的特征提取
通过上一步的方法,将每个时刻的序列值转换成了一个矩形网格,为了更好地进行相似度的计算,我们需要进行特征提取,提取出主要信息,忽略细节和噪声。这里我们使用二维离散余弦变换DCT来进行特征提取。使用二维DCT不仅能够进行降维,而且考虑了多变量之间的关联性,相比于其他的一维方法,能够使特征更加明显。
离散余弦变换最早是由Ahmed于1974年提出的[14],作为一种实数域变换,DCT克服了离散傅里叶变换中复数域的缺点,因此被广泛运用于数据压缩、特征提取中。
DCT有多种表示形式,以下给出其中一种表示,假设矩形网格的规模是m×n,其二维DCT公式为:
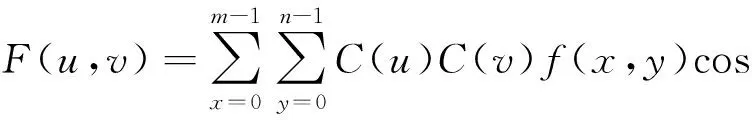
(1)
其逆变换是:
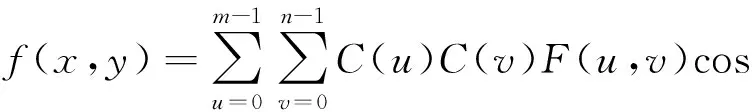
(2)
其中:
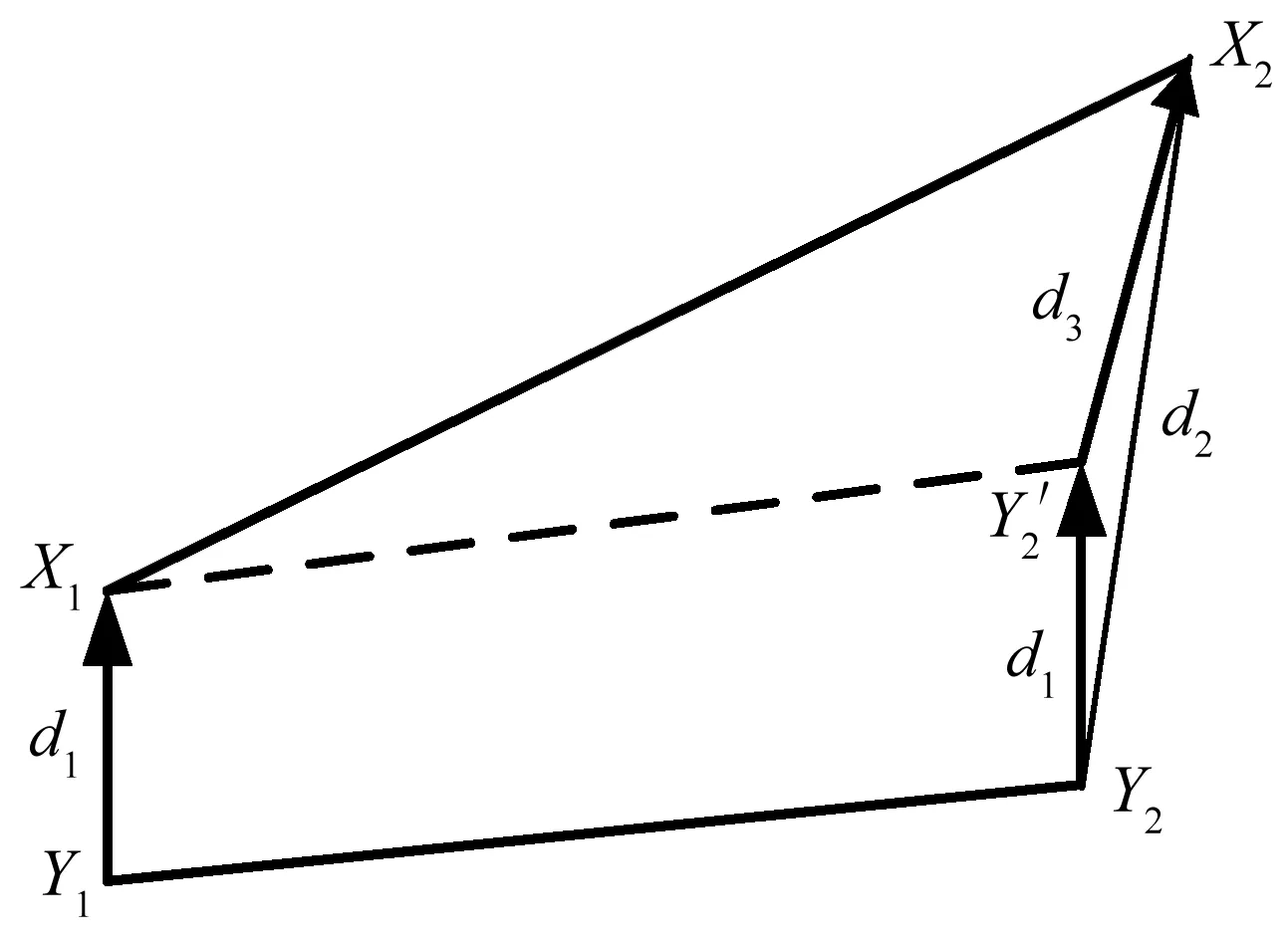
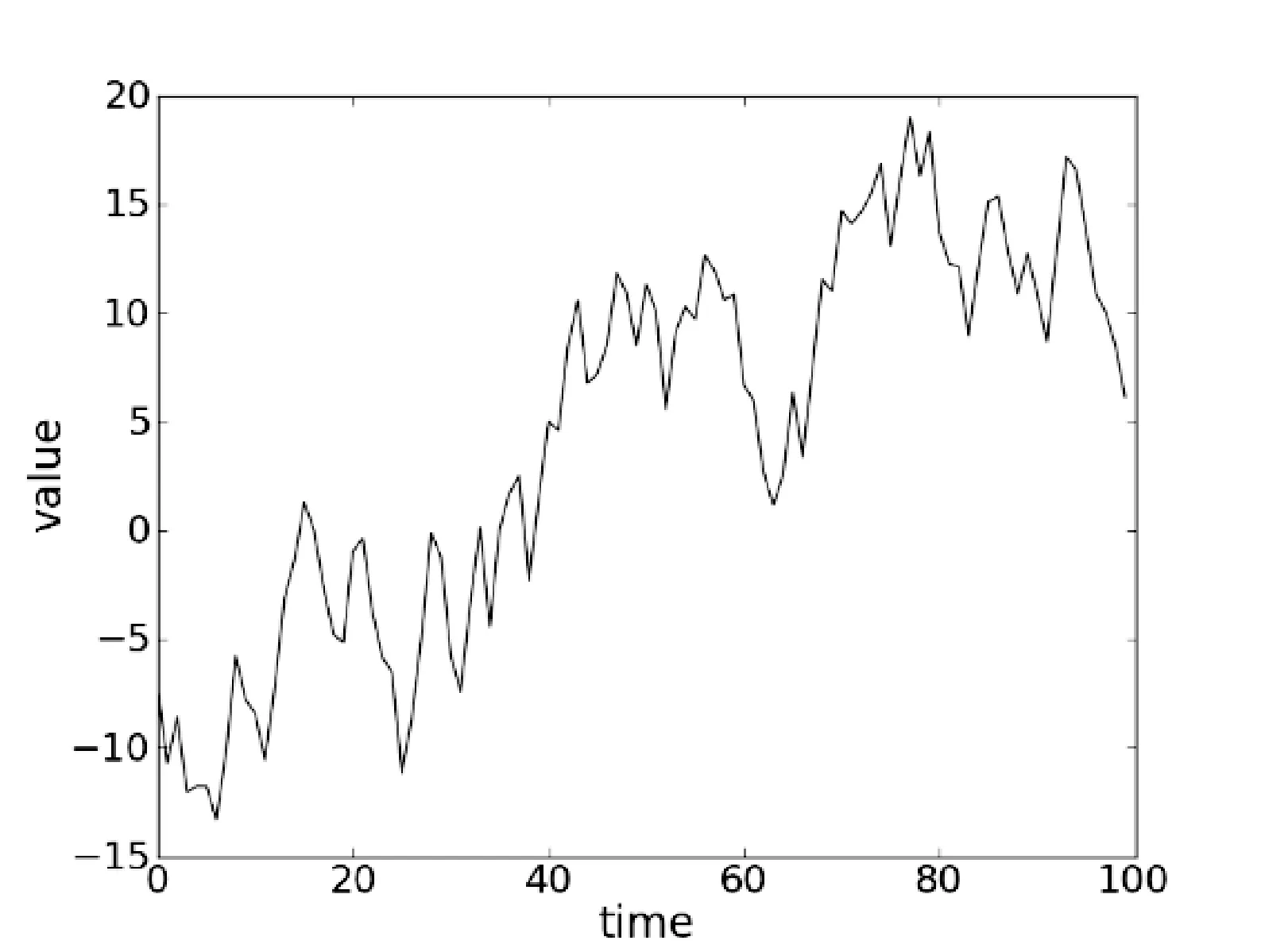
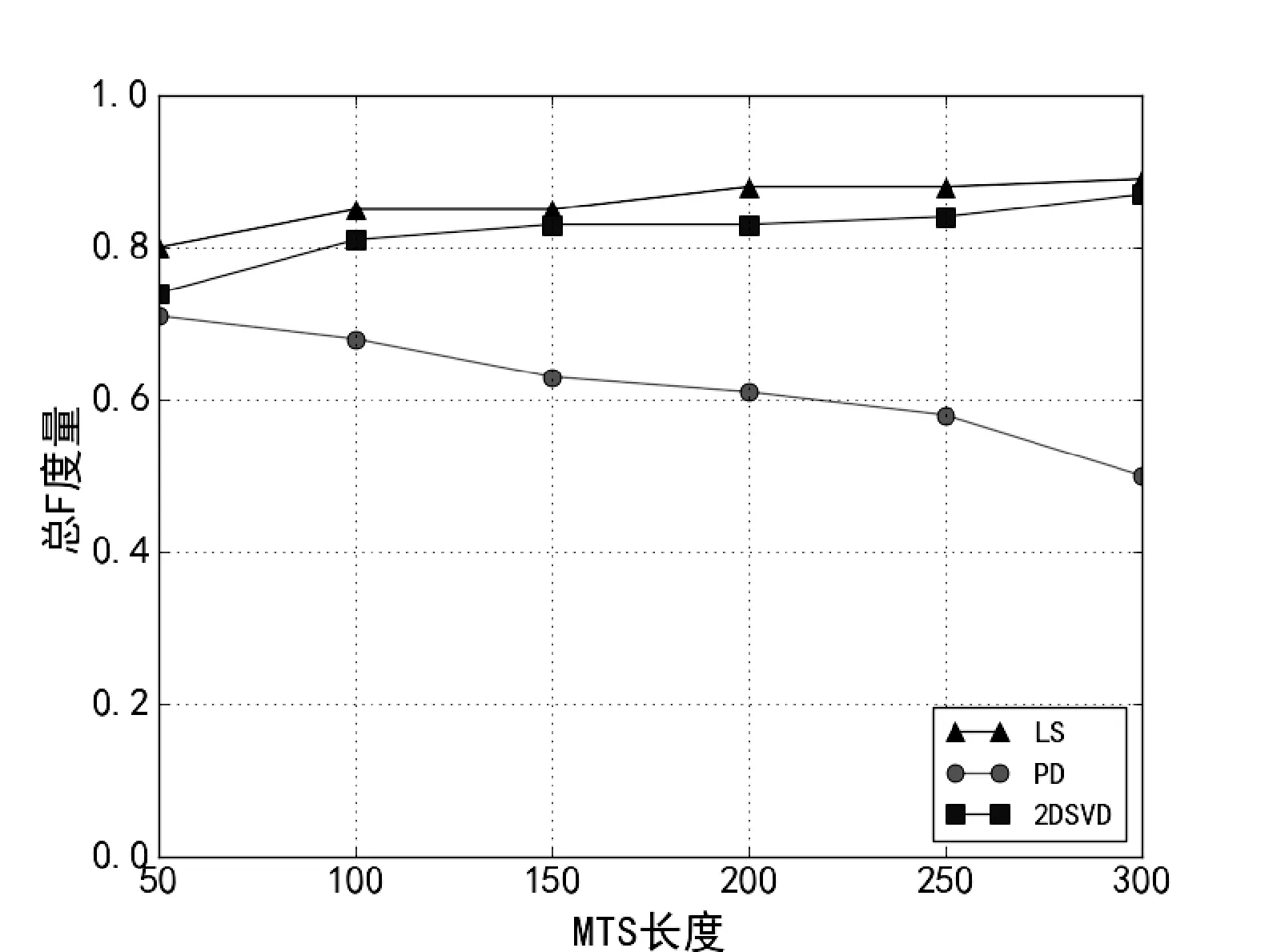
根据DCT的意义,原先m×n的矩阵经过DCT变换后得到系数矩阵的大小也是m×n,其中低频信息集中在左上角,高频信息集中在右下角,要提取特征只需要保留低频部分,去掉高频部分。因此,我们只保留左上角的p×q部分,其中1 2.4LS相似度 为了详细阐述LS相似度的定义,首先定义下面的一些概念。 (1) 矩形网格 一个多变量时间序列在某一时刻所有变量的值一一对应放入一个网格形成了一个矩形网格。 (2) 点(Point) 一个点是从一个矩形网格提取出来的维度是p×q的特征矩阵,如图1中的p1。 (4) 线段序列(LineSequence) 由高维空间中线段首尾相接组成,如图1中p1到p7之间所有线段首尾相接组成了一个线段序列。 因为一个矩形网格可以用一个高维特征矩阵来压缩表示,所以MTS可以用高维空间的线段序列来表示。如图1所示,对于一个点pi,它表示从时刻i的矩形网格所提取出来的特征矩阵。 图1 MTS用高维空间的线段序列表示 如图2所示,给定两个线段序列S1和S2,他们之间的相似度计算公式如下: (3) 图2 两个线段序列 如图3所示,X1X2和Y1Y2分别是线段序列S1和S2中的线段,它们是一对线段对。它们之间的相似度为: (4) d1=|X1-Y1|=∑i,j|MX1(i,j)-MY1(i,j)| (5) d2=|X2-Y2|=∑i,j|MX2(i,j)-MY2(i,j)| (6) 在上述公式中,(i,j)是特征矩阵MX1和MY1的索引。 图3 两个线段的距离 因此: 其中‖*‖表示一个线段的长度。 通过使用MX1、MX2、MY1和MY2取代上述公式中的X1、X2、Y1、Y2得到: MY2(k,l)-MX1(k,l)| 2.5LS-Cluster聚类方法 离群点的存在破坏了数据内在的一致性,导致了不可靠的结果,也降低了模式挖掘的有效性。然而,层次聚类算法[15]可以很好地发现数据蕴含的模式同时找到离群点。所以,我们LS-Cluster基于层次聚类算法来挖掘时间序列的模式并检测离群点。 在聚类之前,我们先使用LS相似度计算每两个线段序列之间的相似度从而构建相似度矩阵,之后需要对该矩阵进行归一化,具体的做法就是将相似度矩阵中所有的值通过以下公式转化成之间的值: x′=(x-xmin)/(xmax-xmin) (7) 其中,x是原相似度,x′是归一化后的相似度,xmax和xmin分别为相似度矩阵中的最大值和最小值。 归一化后即可开始进行聚类操作,聚类算法的步骤如下:首先,把每个线段序列都看成一个簇,在每次迭代中,算法将相似度最高的两个簇合并,然后更新相似度矩阵。假设Ci和Cj是两个簇,他们的相似度是他们的组平均,计算公式定义如下: (8) 其中,mi和mj分别是两个簇Ci和Cj中线段序列的数目。两个簇之间的相似度是两个簇的所有点对的相似度的均值。为了避免将所有的线段序列合并成一个簇,我们设置了一个聚类数K,当簇的数目达到K时即停止合并。一旦聚类完成,含有大量的线段序列的簇被看成是正常模式,而含有少量线段序列的簇则被认为是离群点。 我们分别使用人工合成数据和2008年上海证券交易所1 120支股票的行情数据对我们的方法进行测试。所有实验的硬件环境为Inteli5-3470主频3.2GHz、8GB内存、1TB硬盘,操作系统为Windows10,代码使用Python2.7进行实现。 3.1 人工合成数据 由于本文主要聚焦于大规模多变量的时间序列,变量的数目可以达到几千甚至上万。所以许多的数据集对本方法来说并不合适。因此在本试验中,我们通过模拟传感器网络来生成测试数据。 假设有m×n个传感器,我们使用以下四种不同的模型来模拟生成多变量时间序列数据。数据生成的具体方法是,对于同一个传感器网络,每个传感器结点都使用相同的模型来进行数据生成,但对于不同结点使用随机生成的不同参数。四种数据生成模型如下: (1) 随机游走时间序列模型:时间序列的首个值从[-10,10]中随机选取,其后每个值均从前一值的偏移量在[-5,5]中随机选取,图4是某个传感器首个值取-5.38时的图像。 图4 随机游走时间序列模型 (2) 单一高斯时间序列模型:时间序列中的值从一个高斯分布中随机选取,而这个高斯分布的均值从[-10,10]中随机选取,标准差从[1,5]中随机选取,图5是某个传感器均值取6.86,标准差取2.11时的图像。 图5 高斯时间序列模型 (3) 多段高斯时间序列模型: 时间序列随机由多个连续的单一高斯模型序列片段连接而成,序列片段数从[5,10]中随机选取,图6是某个传感器序列片段数取4时的图像。 图6 多段高斯时间序列模型 (4) 混合正弦时间序列模型: 时间序列是基于多个正旋波叠加的曲线采样生成。这些正弦波的周期从[5,10]中随机选取,振幅从[5,10]中随机选取,正弦波的个数从[2,10],某个传感器的图像如图7所示。 图7 混合正弦时间序列模型 对于上述4种模型都各产生50条序列,4个模型一共是200条序列,每条序列的长度取100。为了验证我们提出的LS相似度的可扩展性,我们把LS相似度与文献[7]提出的PD匹配方法以及文献[8]提出的2DSVD匹配方法进行了比较,其中LS相似度特征矩阵的规模p和q均取max(5,m/10),PD方法的参数取i1=i2=4,j1=j2=2,分位点采用极小值、5%、10%、25%、50%、75%、90%、95%和极大值共9个。2DSVD方法参数取r=33,s=4。 表1比较了三种方法在不同传感器规模下计算两个MTS间的相似度所花费的时间。在传感器规模在10×10的情况下,LS所花费时间稍微比PD和2DSVD多一些,然而随着传感器规模的增大,LS显示出比2DSVD和PD更好的性能。由此可见,LS相似度在对大规模多变量时间序列的处理上有着较好的可扩展性。 表1 计算两个MTS的相似度所花费的时间 s 在准确性方面,我们使用F度量来对聚类的效果进行评估,F度量基于精度和召回率,是两者的综合评价。对于已知划分{P1,P2,…Pj,…,Pn}和聚类得到的簇{C1,C2,…,Ci,…,Cm},其精度、召回率和F度量定义如下: 精度: (9) 召回率: (10) F度量: (11) 利用式(11),我们对于每个预先标注的Pj,可以得到其F度量: F(Pj)=max1≤i≤mF(Pj,Ci) (12) 对所有的簇进行F度量加权平均就得到了整个聚类结果的总F度量: (13) 分别使用LS、PD和2DSVD三种方法作为相似性度量,采用组平均来计算合并后的簇间相似度,使用凝聚层次聚类来考察不同时间序列长度下三种方法聚类的加权平均F度量。使用传感器的规模是100×100,聚类簇的个数均为4,结果如图8所示。横坐标表示MTS的长度,纵坐标表示聚类的总F度量。结果显示,LS的效果在不同序列长度下表现均为最优,2DSVD次之,PD最差,并且LS和2DSVD聚类方法的总F度量随着序列长度有增大的趋势,而PD方法的总F度量随着序列的长度有所降低。由此可以得出,PD只适合应用在小规模的多变量时间序列,不适用应用在规模较大的多变量时间序列上,而本文提出的LS和基于PCA的2DSVD能够很好地应用在大规模对变量时间序列上,并且LS的效果要略优于2DSVD。 图8 各相似性度量方法在不同长度下的聚类总F度量 3.2 真实的金融数据 在本实验中,采用2008年上证1 120支股票,共有246个交易日。2008年是中国股票大跌的一年,上证指数从2007年10月16日的6 120.04点下跌到2008年10月28日的1 664.93点,因此选择2008年的股票行情数据来进行实验很具有代表性。具体实验方法是将每个交易日作为一个时间窗口,将1 120支股票的每支股票均作为一个变量分别放入35×32的矩形网格内,每分钟的收盘价作为一个采样值,对于每支股票一天产生240个值,因此一个交易日的数据就可以用长度为240的矩形网格的序列来描述。在本实验中,特征矩阵的规模取p×q取p=q=6。 通过本方法的聚类,一共产生了5个类:类1包含了106天,类2包含了40天,类3包含了97天,类4只有2天,类5只有1天,因此可以把类4和类5看作是离群点。由于实验的数据是上证的几乎所有股票数据,因此上证的指数(股票代码:SH000001)可以一定程度上的反应股票整体的情况,而本方法也是将每只股票作为一个变量,结果也是反映所有股票的整体情况,因此可以和上证指数进行对比分析。在上证指数中共有139天收盘价下跌,其中有94天跌幅大于1%;有107天上涨,其中有63天涨幅大于1%;另外有94天涨跌幅小于1%。而实验结果的类1中,106天中有78天跌幅大于1%,因此可以认为类1的标签是跌幅较大的类。而类2中的40天有34天涨幅大于1%,因此类2可以看作是涨幅较大的类。类3的97天有80天涨跌幅小于1%,因此类3可以看作是涨跌幅度不大的类。类4只包含了2天,分别是4月24日和9月19日,4月24日由于财政部、国家税务总局决定从2008年4月24日起,调整证券交易印花税率,由原来的3%调整为1%,导致股市大涨9.29%,而9月19日有三大利好消息,即印花税单边征收、国资委鼓励国企大股东回购公司股票、中央汇金公司将在二级市场购入工、中、建三行股票,因此股市大涨9.45%,导致了这两天的数据和其他交易日的数据有较大的不同。类5中只有一个类,即2008年7月2日,当天的涨幅只有0.004 5%,因此也和其他交易日的数据有较大不同,因此成了离群点。实验结果显示,我们在2008年的上海证券交易所1 120支股票的行情数据上的聚类结果和实际股市表现较为相符。 本文中,我们提出了一种新的方法——LS-Cluster来发现大规模多变量时间序列蕴含的模式。把多变量时间序列每个时刻所有变量的值放入一个矩形网格中,再用二维离散余弦变换来提取高维特征向量。为了进行聚类分析,我们提出了LS相似度来计算不同的多变量时间序列之间的相似程度。最后采用层次聚类来发现其中的模式并找出其中的离群点。 我们在人工合成数据和2008年1 120支股票的数据进行了实验,证明了本方法的有效性和可扩展性,可以被用于有上万变量数的大规模多变量时间序列的聚类分析。虽然我们的实验是基于金融数据的,但是本方法还可以被应用在其他的数据上,例如传感器网络、医疗、服务器机房状态监控等。 [1]EEGDatabase[OL].http://kdd.ics.uci.edu/databases/eeg/eeg.html. [2]WuYL,AgrawalD,AbbadiAE.AcomparisonofDFTandDWTbasedsimilaritysearchintime-seriesdatabases[C]//ProceedingsoftheNinthInternationalConferenceonInformationandKnowledgeManagement.ACM,2000:488-495. [3]JolliffeI.Principalcomponentanalysis[M].Hoboken,NJ,USA:JohnWiley&SonsInc,2002. [4] 李正欣,张凤鸣,张晓丰,等.多元时间序列特征降维方法研究[J].小型微型计算机系统,2013,34(2):338-344. [5]GuanH,JiangQ,HongZ.Anewmetricforclassificationofmultivariatetimeseries[C]//FuzzySystemsandKnowledgeDiscovery,2007FourthInternationalConferenceon.IEEE,2007:453-457. [6]YangK,ShahabiC.APCA-basedsimilaritymeasureformultivariatetimeseries[C]//Proceedingsofthe2ndACMInternationalWorkshoponMultimediaDatabases.ACM,2004:65-74. [7] 管河山,姜青山,王声瑞.基于点分布特征的多元时间序列模式匹配方法[J].软件学报,2009,20(1):67-79. [8] 吴虎胜,张凤鸣,钟斌.基于二维奇异值分解的多元时间序列相似匹配方法[J].电子与信息学报,2014,36(4):847-854. [9]YangC,ZhouJ.Aheterogeneousdatastreamclusteringalgorithm[J].ChineseJournalofComputers,2007,30(8):1364-1371. [10]LiaoTW.Aclusteringprocedureforexploratoryminingofvectortimeseries[J].PatternRecognition,2007,40(9):2550-2562. [11]HuangYP,HsuCC,WangSH.Patternrecognitionintimeseriesdatabase:acasestudyonfinancialdatabase[J].ExpertSystemswithApplications,2007,33(1):199-205. [12]OwsleyLMD,AtlasLE,BernardGD.Automaticclusteringofvectortime-seriesformanufacturingmachinemonitoring[C]//Acoustics,Speech,andSignalProcessing,1997IEEEInternationalConferenceon.IEEE,1997:3393-3396. [13] 周大镯,姜文波,李敏强.一个高效的多变量时间序列聚类算法[J].计算机工程与应用,2010,46(1):137-139. [14]AhmedN,NatarajanT,RaoKR.Discretecosinetransform[J].IEEETransactionsonComputers,1974,23(1):90-93. [15]TanPN,SteinbachM,KumarV.数据挖掘导论(完整版)[M].范明,范宏建,译.北京:人民邮电出版社,2011. LS-CLUSTER: LARGE SCALE MULTIVARIATE TIME SERIES CLUSTERING METHOD Zheng Cheng Wang Peng Wang Wei (SchoolofComputerScience,FudanUniversity,Shanghai201203,China) (ShanghaiKeyLaboratoryofDataScience,FudanUniversity,Shanghai201203,China) In the existing studies on multivariate time series clustering, the size of the variables studied is small, and in real life, large scale multivariate time series often appear. Therefore, LZ-Cluster algorithm is proposed, which aims at clustering large scale multivariate time series with tens of thousands of variables. Firstly, the multivariate time series of each time is transformed into a rectangle grid, and then two-dimensional discrete cosine transform is used to extract features. LZ similarity is proposed to calculate the degree of similarity between feature series. Finally, hierarchical clustering method is used to discover the patterns. The experimental results show that the proposed method has good performance and extensibility in both synthetic data and real data. Large scale Multivariate time series Discrete cosine transform LS similarity Clustering 2016-04-01。国家自然科学基金项目(U1509213)。郑诚,硕士生,主研领域:时间序列,数据挖掘。王鹏,副教授。汪卫,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.05.036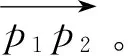
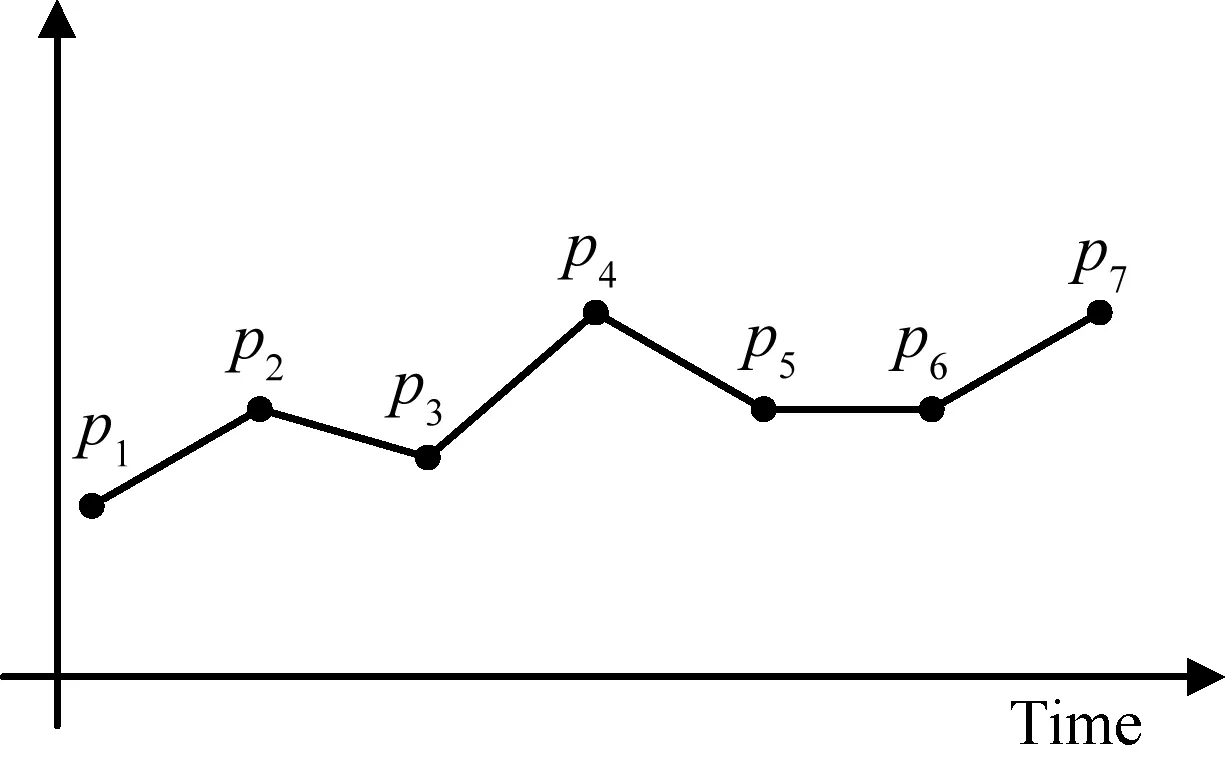
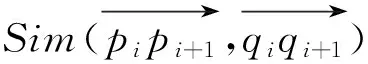
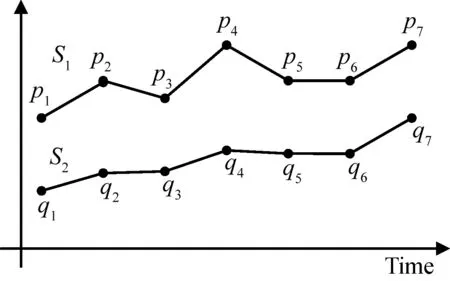
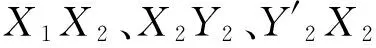
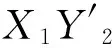
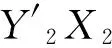
3 实 验
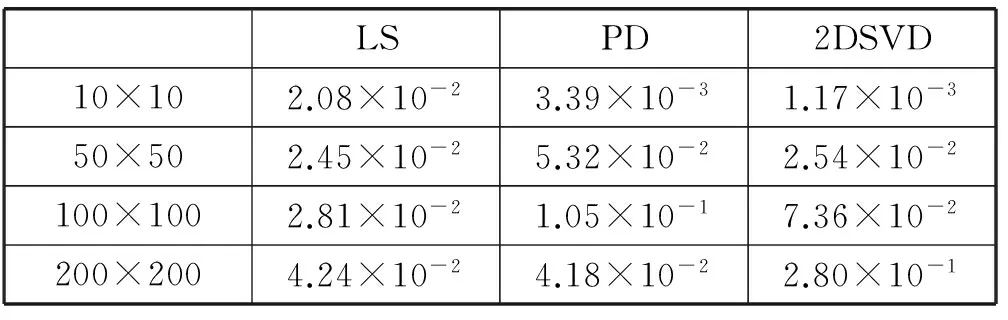
4 结 语
猜你喜欢
小学生学习指导(高年级)(2021年5期)2021-05-18 07:34:42
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
小学生学习指导(低年级)(2019年4期)2019-04-22 03:28:40
小学生学习指导(低年级)(2018年12期)2018-12-29 11:13:38
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
电子设计工程(2015年6期)2015-02-27 12:04:53
