
面向Spark的遥感影像金字塔模型的并行构建方法
2017-06-29 12:00:34黄冬梅杨雨浩梅海彬王振华
计算机应用与软件 2017年5期
黄冬梅 杨雨浩 梅海彬 王振华
(上海海洋大学信息学院 上海 201306)
面向Spark的遥感影像金字塔模型的并行构建方法
黄冬梅 杨雨浩 梅海彬 王振华
(上海海洋大学信息学院 上海 201306)
随着遥感技术和摄影测绘的发展,遥感影像的分辨率不断提高,数据量日益增长,这对快速、高效地处理海量遥感影像数据提出了更高的要求,如何有效、智能地存储和处理海量遥感数据成为研究的热点。在分析现有金字塔模型的并行构建的基础上,设计一种面向Spark计算框架的影像金字塔模型。模型给出了影像金字塔构建算法及影像数据的分布式存储组织结构,实现了海量遥感影像数据在Spark中的并行处理,为Spark增加了计算处理空间数据格式的能力。实验结果表明,利用该方法能够在Spark云平台上实现快速、高效的解决海量遥感影像金字塔的并行构建,特别是在面对海量遥感影像数据时,无论从金字塔构建性能上还是遥感影像的计算效率上,Spark都更具优势。
遥感影像 金字塔 Spark 算法 分布式
0 引 言
金字塔模型是实现海量遥感影像可视化的基础[1],它是一种多分辨率层次模型,对于不同区域通常采用不同分辨率来提高影像的渲染速度。金字塔模型构造的过程本质上是对遥感影像进行影像分层和分块处理[2],通过对原始遥感影像重采样,建立不同分辨率的影像金字塔,从而提高地图缩放的响应速度。重采样可以根据采样顺序的不同,分为自底向上和自顶向下两种,而常规的串行计算方法一般只适合小规模的遥感数据,对于海量高分遥感影像的处理效率其实并不高[3]。在遥感影像的应用中,影像金字塔模型是一种非常重要的数据组织形式和应用模型,众多学者对其已有广泛的研究,并取得了许多重要成果[4-5]。利用金字塔模型来组织不同分辨率的影像已基本成为普适的方法,其对于数据的表现有较高的效率,能够实现不同分辨率之间的快速浏览[6]。然而,随着遥感技术和地理测绘的发展,今后的遥感影像数据面临多源、多类型、海量数据的局面,存在影像分辨率高、文件大的特点[7],这使得一些测绘区域的遥感影像数据量会变得更加大。因此,在对高分遥感影像特别是海量遥感影像进行处理时,我们需要高计算性能和高吞吐率,现有的利用MapReduce的分布式计算框架来提高金字塔构建效率的方法[8-9],在处理海量、多源、高分遥感影像时,所耗费时间仍然很长,且在海量遥感影像的可视化过程中响应较慢。例如40GB大小的原始遥感影像数据重采样生成尺寸大小为256×256像素的瓦片,其产生的瓦片总的大小为54 GB,用传统的并行方法可能需要8个小时,故而针对海量遥感影像处理的效率问题,有必要采用更高性能的处理方式。
Spark是一种基于内存的分布式计算框架[10-11],核心是图计算和数据流的快速处理,其本身并不具备直接处理遥感影像的能力,本文在现有的框架基础上,针对海量遥感影像处理性能的问题,设计并实现了一种面向Spark计算框架的遥感影像金字塔模型构建方法及其数据存储组织结构,解决了遥感影像的即时计算处理效率和分布式存储优化,实现了影像的动态渲染。本文充分运用Spark的弹性数据集RDD内存计算的特性,搭建Spark on Yarn模式下的分布式集群,与Hadoop中分布式文件系统(HDFS)相结合,利用Spark来加速影像金字塔的构建的过程。在影像金字塔的构建过程主要是对影像数据的重采样和遥感影像瓦片分割存储,并根据不同的模型与策略生成影像瓦片缓存[12-14],从而实现遥感影像可视化的快速渲染。与基于MapReduce的遥感影像金字塔模型构建效率相比,Spark可以将原始影像数据集转成RDD,并将计算处理后的中间结果保存在内存中,减少了影像数据的I/O次数,大大提高了遥感影像处理的处理速度。
本文提出的模型策略和应用主要包括:(1)设计面向Spark 框架的遥感影像金字塔模型的并行构建算法和影像数据的存储组织形式,提高了海量遥感影像的即时计算效率;(2)在Spark计算框架的基础上,依据影像金字塔构建算法,开发出面向Spark的遥感影像金字塔模型并行构建的相关接口库。
1 面向Spark的影像金字塔模型
面向Spark的影像金字塔是一种利用弹性数据集RDD来处理海量遥感数据的模型。该金字塔模型的构建过程中会同时考虑影像的分层和影像的分块,根据原始遥感影像的分辨率大小确定其最大分层数。同时将原始遥感影像切分成大小相等的瓦片,对于不足之处给予空值填充,进而根据最大分层数及每层的瓦片元数据构建金字塔模型,建立多分辨率层次影像瓦片缓存机制。金字塔模型的构建主要由影像的层级划分及影像的切片方式两部分组成,通常会通过预设倍率来实现分层分块,影像的分层数越多,其可视化渲染的速度就越快,客户端响应的时间就会越短,但随着层数的不断增加,越上层的影像就会越模糊分辨率越低,因而需要依据需求合理的分层。与传统的按照采样算子进行重采样处理来构建影像金字塔模型相比,本文提出的面向Spark的遥感影像金字塔的构建算法的效率将更高,计算量也会大大减少。其可以灵活的控制影像的分层,解决了遥感影像的分布式切片问题,实现影像金字塔模型的按需构建,是一种分布式并行的构建算法。本文中面向Spark的影像金字塔模型构建流程如图1所示,假设入库的原始遥感影像是可以进行缩放的,并没有达到分辨率的最小值。

图1 面向Spark的金字塔模型构建流程
从图1中可以看到整个金字塔模型的构建流程,原始影像数据入库后会被HDFS切块存储到不同的存储节点上,不同节点上的分块会被Spark处理成不同的RDD,Spark会将不同的RDD数据合并成Spark可以直接处理的RasterRDD,设置采样算子为2,影像瓦片的大小tileSize=256(像素)。按照影像金字塔构建算法来计算影像的最大分层数,其中每生成一个新的RasterRDD就是新一层影像数据,同时也是计算判断下一层的输入数据,这个过程中会对每一层的影像按四叉树的方式进行分块操作。求得最大分层数后,调用Ingest对象下的Sinklevel函数传入参数level和RasterRDD建立金字塔模型,从分辨率最小的最上层开始,影像瓦片会随着层级level的值不断向上重构融合,直到level的值小于等于1为止。终止计算后,将构建金字塔中生成的属性数据和元数据写到分布式文件系统(HDFS)中。
1.1 影像金字塔模型构建算法
遥感影像数据在投入使用前,大多会因其数据量过大而进行分幅处理,因此其原始影像的尺寸大小不会过大,从而在构建金字塔模型的过程中,金字塔的层数一般不会超过20层。本文根据原始遥感影像的分辨率大小来确定遥感影像缩放的最大级别,即该原始影像可以划分的最大分层数。同时,考虑到原始遥感影像宽高尺寸大小不同的情况,因而需要分别计算以原始影像宽或高为参数的最大分层数,并取两者之间的最大值作为最终的分层数。具体最大分层算法描述如下:
(1) 根据原始遥感影像的坐标范围Extent,求得遥感影像的像素大小W0×H0,设置影像瓦片切片值tileSize,计算影像分层的最大值level,计算原始遥感影像像元值大小CellSize,其中W0=Extent,width,H0=Extent.height。
(2) 计算遥感影像的第I层(1≤I≤20)的分辨率ResI=WI/(2I×TileSize),若CellSize.with+k≥ResI(K是修正值常数),则停止计算,当前I的值即为原始遥感影像可以分层的最大值。否则,返回第(2)步,计算第I+1层。
(3) 重新赋值第(2)步中的WI,令其等于HI并计算新的I′,取I和I′的最大值max(I,I′)即为遥感影像的最大分层数level。
算法1 影像金字塔构建算法:
输入:遥感影像数据source,影像瓦片的尺寸tileSize
输出:最大分层数level,属性数据,元数据
Begin:
(1) 将分块的影像数据读到Spark中,取得影像的范围extent,计算原始影像的cellSize=extent.width/cols;
(2) 将cellSize、tileSize,extent.width传给最大分层算法Zoom(cellSize.width,tileSize,extent.width);
(3) 计算影像的最大分层数I,每一次分层都重新计算影像分辨率Resi的大小;
(4) 调用上述的分层算法,并判断影像的终止条件,若满足条件则返回I,执行第(6)步;
(5) 若不满足条件,则I=I+1,生成下一层的rasterRDD,返回第(3)步;
(6) 将当前最大层的数据Ingest到spark中,输入参数level=I,rdd=rasterRDD;
(7) 调用Sinklevel函数建立分布式金字塔模型,判断level是否大于1;
(8) 若level满足条件,则调用sink函数生成nextrdd,level=level-1,重新递归调用Sinklevel;
(9) 若level不满足条件,则停止计算,将生成的属性数据和元数据写入到HDFS中。
End
该算法是面向Spark的分布式构建方法,依赖于原始遥感影像的分辨率大小,即其可以缩放的最大级别。原始影像经过分块切片后,被转换成Spark可以直接处理的rasterRdd,计算过程中得到的中间数据集可以被cache到内存中,从而减少了数据的读取次数,缩短了影像计算处理的效率,提高了影像金字塔模型的构建速度。因而可以满足影像金字塔模型的高效构建,快速渲染的需要。同时,Spark的计算机制使得其在迭代计算上具有更高的优势。
1.2 影像数据的存储组织结构
构建影像金字塔数据组织形式是影像数据存储过程中极为重要的步骤,也是搭建金字塔模型中的重要环节。在计算原始影像的最大分层数中,需要给分层后的每一层影像瓦片建立相应的索引,才能在后续金字塔模型构建中,获取到相应的影像瓦片块的数据信息。传统的影像金字塔模型大都会采用可递归的空间填充曲线来对遥感影像的分块瓦片进行编码,从而提高影像瓦片的空间检索效率,缩短客户端的渲染时间[15-16]。而在分布式的计算框架中,每个影像瓦片都是被独立计算的[17],因而本文的关注点在于如何快速检索到影像瓦片。金字塔模型的影像层是原始影像通过分层分块后融合拼接生成的,各个影像层中的像素是按照一定的算法映射到原始影像的像素上[18]。本文在影像划分时并不会对每个影像分区的瓦片数据内容进行单独存储,而是会对划分后形成的每一层的影像进行分布式存储。即将某一层或者某几层的影像数据存在一个或多个存储节点上,然后通过编码值(SpatialKey)及层级数I来确定每一层数据中所描述的影像瓦片的数据范围,从而确定瓦片元数据中的数据值。影像瓦片的编码方式如图2所示,在计算最大分层的过程中,同时会对影像进行切片分块的操作,本文采用四叉树的方式来实现影像分块后的快速索引。
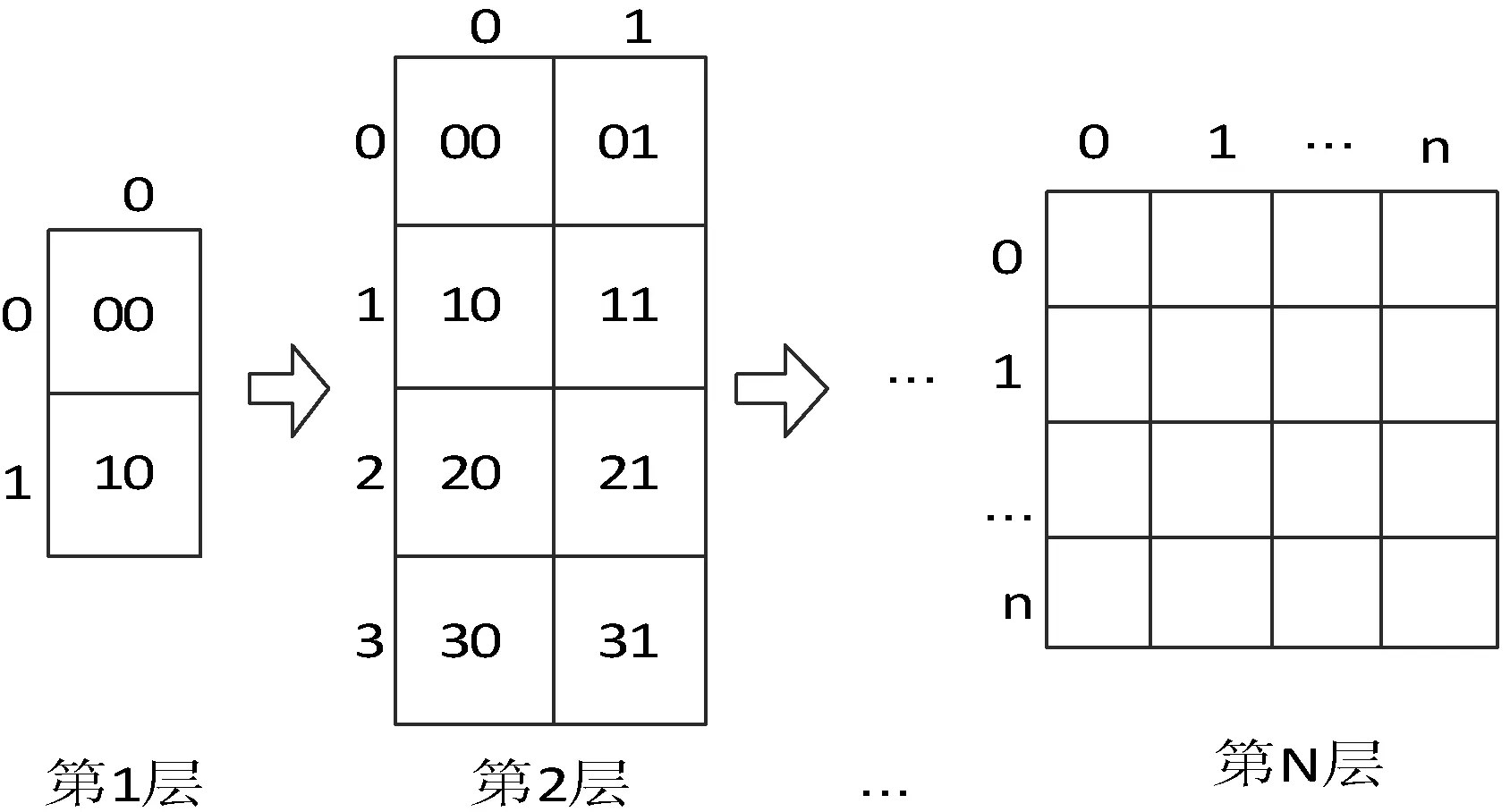
图2 影像瓦片tile的编码方式
由图2中可以看到,我们通过TMS算法(tile map service)对遥感影像瓦片进行编码,对遥感影像采用四叉树的方式来进行分层[19-20]。在实际的编程过程中,由于瓦片编码值的规律性(平面直角坐标系),加上投影也是一种算法,所以编码值和坐标之间就建立了一种索引关系,通过经纬度和层级可以得到瓦片的编码值,反之通过编码值可以找到经纬度区间[21]。具体的计算公式如下:
n=2zoom
(1)
xtile=((lon_deg+180)/360)×n
(2)
ytile=(1-(log(tan(lat_rad)+
sec(lat_rad))/π))/2×n
(3)
其中,zoom为影像的层级数, 由公式可以看出,只要确定经纬度和层级,就可以得到瓦片的编码值。相反,也可以通过编码值来推算未知的经纬度了,其计算公式如下:
lon_deg=xtile/n×360.0-180.0
(4)
lat_rad=arctan(sinh(π×(1-2×ytile/n)))
(5)
lat_deg=lat_rad×180.0/π
(6)
所以,在Spark构建金字塔模型的过程中,我们可以根据原始遥感影像的中心坐标和层级数,来确定需要加载的影像瓦片。同样,当我们单击底图时,我们也可以根据影像瓦片的编码值来确定瓦片的经纬度范围,从而确定某一点在当前tile上的像素坐标位置。
本文金字塔模型是面向Spark计算框架所构建的,目的是通过Spark的分布式内存计算的特性,来进一步加速影像的处理过程,然而Spark本身并不能直接处理遥感影像,因而需要将原始遥感影像处理成为Spark可计算处理的数据组织形式,处理后的数据以分布式的形式存储在HDFS中。如图3所示即为原始遥感影像经过Spark处理后生成的两类数据结构,一类是JSON文件格式的属性数据;另一类是不带有头部数据信息的元数据。

图3 面向Spark处理后的遥感影像数据组织形式
从图3中可以看到,在进行上述的金字塔模型构建的过程中,生成的影像数据会分布式存储在各个节点上,影像数据分为属性数据和净数据,其中属性数据中的存储着从第0层到第N层的属性数据,每一层的属性数据中又包含了三个数据信息,分别是索引数据信息、影像范围数据信息、元数据的存储位置信息。而净数据中保存了从第0层到第N层的用于计算的数据信息,每一层的净数据中又记录了影像数据的数据偏移量和影像净数据信息两个方面。构建好影像数据的组织形式后,我们可以根据不同层的编码值(SpatialKey)来快速检索到某一层或某几层的影像瓦片来进行分布式计算,从而计算资源和属性数据索引参数会从master节点上分发到有相应资源数据的计算节点上,计算节点可以通过属性数据索引参数较快的获取到映射的某一层的遥感影像的净数据。
2 面向Spark影像金字塔构建机制的原型系统及实验
2.1 系统架构
为了测试面向Spark的影像金字塔模型的性能优劣性,本文的实验环境是将管理云平台OpenStack部署在8台浪潮服务器上,利用OpenStack的虚拟化技术,建立了2个控制节点NameNode、SecondaryNameNode和5个Worker计算节点的小型集群,服务器中的节点通过千兆网卡连接,每个节点的包含8个核心,16 GB的计算内存。搭载Ubuntu14.04系统,建立基于Spark On Yarn的分布式集群,所使用的开源软件包括:Hadoop2.6.3和Spark1.5.2。整个实验中,在Spark框架的基础上,依据影像金字塔构建算法开发的接口库,实现遥感影像在Spark下的快速分层、切片分块,以及遥感影像金字塔模型的并行构建,实验的总体架构设计如图4所示。
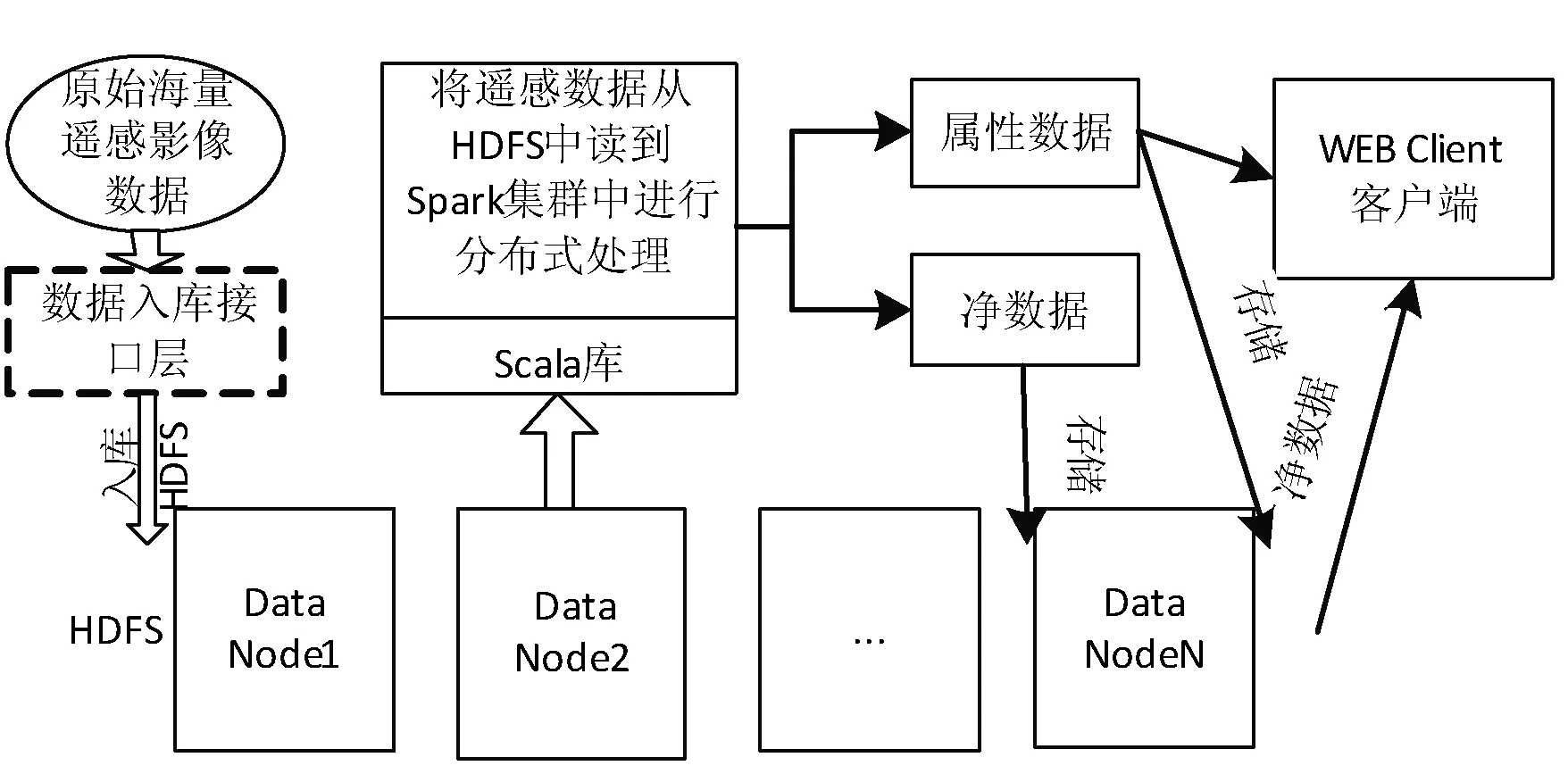
图4 实验的总体架构设计
从图4中可以看出,本文的总体框架设计与实现是基于分布式文件存储系统(HDFS)的。在实际的操作过程中,首先将海量的遥感数据入库存储到HDFS中,接着通过开发的接口库将遥感数据读到Spark集群中进行分布式计算处理,经过处理后的遥感影像会生成两类数据重新存储到分布式文件系统中,便于集群中的所有客户端共享、渲染显示。在Spark计算模式中,在分层和分块计算处理的过程中,生成的中间影像数据,可以被Spark计算框架Cache到内存中,进而可以直接被客户端所调用,直到处理的中间结果被内存释放,这也是Spark计算模式的最大优势,不需要进行多次I/O操作。
2.2 影像瓦片参数优化实验
在SIPM的构建及遥感影像的分布式处理过程中,对性能结果存在较大影响的参数有2个,分别是遥感影像数据的数据量和影像瓦片的切片参数值(tileSize)。为了验证该方法的优越性,需要确定影像瓦片的切片参数,在不考虑局域网中网络的传输效率的环境下,根据实验的总体架构设计,搭建出一套面向Spark的影像处理系统,并由此进行了多组的测试和比较,实验结果如表1所示。

表1 影像瓦片参数优化实验结果
从表1中可以看到,建立遥感影像金字塔模型的过程中,影像瓦片的取值越小所消耗的时间就越长,而客户端加载影像瓦片的响应时间却越短。同时,当遥感影像的数据量增大时,切片所消耗的时间也在增加,客户端的响应时间在误差范围内基本不变。考虑到客户端的快速响应,tilesize参数设置应当尽可能的小,但小的分块却不利于客户端进行连贯的缩放。同时当遥感影像的数据量较大、数据文件较多,需要即时处理发布时,大的分块反而更能提高影像处理的效率,但却不利于客户端的渲染显示。
2.3 面向Spark的影像金字塔并行构建性能对比实验
本文通过两组对照实验来验证影像金字塔模型并行构建性能,经过实验证明本文提出的方法在面对海量遥感影像的处理方面将更加快速,能满足客户端的即时响应、影像瓦片服务的快速发布。本文提出的影像金字塔的并行构建方法中,首先判断原始遥感影像是否可以建立金字塔模型即需求得原始遥感影像可以分层的最大值,其次根据求得最大值再向上逐层建立影像金字塔模型。为了测试影像金字塔模型的并行构建的效率,实验需要从两个方面来评估其在遥感影像金字塔并行构建的性能,一方面是遥感影像数据分层和瓦片切割中影像处理的吞吐效率;另一方面是遥感影像金字塔构建的性能,实验中设置tilesize=256,实验选用临港滴水湖、洋山港周边海域的遥感影像数据作为数据来源进行多次对照实验。
实验一中,我们将该算法打包部署到Hadoop单机模式的环境下和Hadoop分布式模式的环境进行对比实验,实验中的数据量大小为50 MB、100 MB、1 GB、10 GB,实验结果如图5、图6所示。
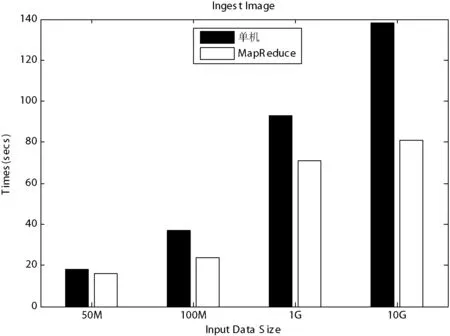
图5 遥感影像的吞吐效率对比

图6 遥感影像金字塔模型的构建性能对比
从图5、图6中可以看出,当遥感影像的数据量较小时,单机模式下遥感影像的吞吐效率要比分布式低,但其影像金字塔构建性能却比分布式模式下的性能快。而当数据量越来越大时,相对于单机模式下的效率,分布式模式下的影像金字塔模型的构建性能要更快,影像的吞吐效率也更高。
实验二中,我们将该算法部署到面向Spark计算框架和面向Hadoop MapReduce计算框架下的分布式实验环境中,实验中的数据源和参数保持不变,同时保证计算节点的资源一致,实验的数据量大小为100 MB、1 GB、10 GB、100 GB,实验的结果如图7、图8所示。

图7 遥感影像的吞吐效率对比
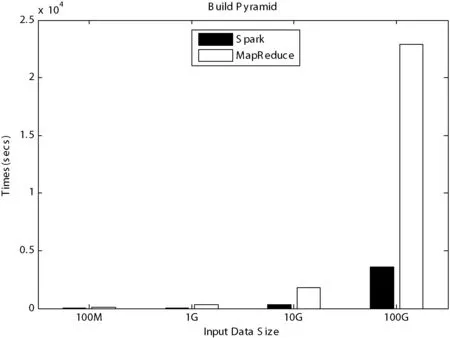
图8 遥感影像金字塔模型的构建性能对比
从图7、图8中可以看到,在遥感影像金字塔模型的并行构建中,当遥感影像的数据量较小时,两种框架下的影像吞吐效率和影像金字塔模型的构建性能相差不大。但当遥感影像的数据量较大时,采用面向Spark的构建方法进行金字塔的并行构建要比采用MapReduce的构建方式在影像的吞吐效率和影像金字塔模型的构建性能上都要优越的多。经过对比计算,当数据量达到100 GB时,其在吞吐效率和构建性能上将提升30%~35%。
2.4 实验结果分析
在实验一中,我们发现该算法并不是在分布式的环境下性能就会更好,而是当影像的数据量越大时,其在分布式的环境下的效率和性能就越快。在实验二中,我们对比了该算法在两种不同的分布式计算框架下,其在遥感影像的吞吐效率和金字塔模型的构建性能上的优劣性。实验结果表明,面向Spark的遥感影像金字塔模型的构建方法,在Spark框架下具有更好的效率和性能,尤其是在面对海量遥感影像的情况下,其对遥感影像的处理及影像金字塔的构建上更能提高时间效率。
3 结 语
本文针对海量遥感影像的金字塔模型构建性能低下的问题,提出了一种面向Spark计算框架的遥感影像金字塔模型的并行构建算法及其分布式数据存储组织结构,并据此设计开发出面向Spark框架的接口库,实现了海量遥感影像在Spark中的并行计算处理,为Spark计算框架增加了处理地理空间数据格式的能力,解决了遥感影像的即时计算处理效率和分布式存储优化,提高了遥感影像的动态渲染性能。本文提出的方法可以有效的把不同区域、不同分辨率的遥感影像集成在Spark框架下,通过实验证明,面向Spark的遥感影像金字塔模型的并行构建方法,更适用于海量遥感影像的快速处理,能极大地缩短金字塔模型构建所需时间,加速遥感影像处理计算的性能,提高客户端的渲染效率。
[1] 邓雪清. 栅格型空间数据服务体系结构与算法研究[J]. 测绘学报, 2003, 32(4):362.
[2] Viola I, Kanitsar A, Groller M E. Hardware-based nonlinear filtering and segmentation using high-level shading languages[C]//Proceedings of the 14th IEEE Visualization 2003 (VIS’03). IEEE Computer Society, 2003: 41.
[3] 刘坡, 龚建华.大规模遥感影像全球金字塔并行构建方法[J/OL]. 武汉大学学报(信息科学版), 2016, 41(1): 117-122. http://www.cnki.net/kcms/detail/42.1676.TN.20150730.1305.002.html.
[4] 杜清运, 虞昌彬, 任福. 利用嵌套金字塔模型进行瓦片地图数据组织[J]. 武汉大学学报(信息科学版), 2011, 36(5): 564-567.
[5] 舒宁. 关于遥感影像处理智能系统的若干问题[J]. 武汉大学学报(信息科学版), 2011, 36(5): 527-530.
[6] 李德仁, 朱欣焰, 龚健雅. 从数字地图到空间信息网格——空间信息多级网格理论思考[J]. 武汉大学学报(信息科学版), 2003, 28(6): 642-650.
[7] 周成虎, 骆剑承. 高分辨率卫星遥感影像地学计算[M]. 北京:科学出版社, 2009.
[8] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[9] 刘义, 陈荦, 景宁, 等. 利用MapReduce进行批量遥感影像瓦片金字塔构建[J]. 武汉大学学报(信息科学版), 2013, 38(3): 278-282.
[10] Tsutsui A, Miyazaki T. ANT-on-YARDS: FPGA/MPU hybrid architecture for telecommunication data processing[J]. IEEE Transactions on Very Large Scale Integration Systems, 1998, 6(2):199-211.
[11] Apache Spark[OL]. http://spark.apache.org.
[12] Quinn S, Gahegan M. A predictive model for frequently viewed tiles in a web map[J]. Transactions in Gis, 2010, 14(2): 193-216.
[13] Li R, Guo R, Xu Z, et al. A prefetching model based on access popularity for geospatial data in a cluster-based caching system[J]. International Journal of Geographical Information Science, 2012, 26(10):1831-1844.
[14] Martín R G, Fernández J P D C, Pérez E V, et al. An OLS regression model for context-aware tile prefetching in a web map cache[J]. International Journal of Geographical Information Science, 2013, 27(3):614-632.
[15] Yu J, Wu L. On coding and decoding for sphere degenerated-octree grid[J]. Geography and Geo-Information Science, 2009, 25(1):5-9,31.
[16] 聂云峰, 周文生, 舒坚, 等. 基于Z曲线的瓦片地图服务空间索引[J]. 中国图象图形学报, 2012,17(2):286-292.
[17] Lei X, Liu X, Zhang W, et al. A method for real-time accessing massive remote sensing image data in three-dimensional GIS[C]//Geoinformatics, 2010 18th International Conference on. IEEE, 2010:1-4.
[18] Kokoulin A. Methods for large image distributed processing and storage[C]//2013 IEEE International Conference on Computer as a Tool. IEEE, 2013:1606-1610.
[19] Xu D, Yuan Z, Yu T, et al. The research of remote sensing image segmentation and release which are based on tile map service[C]//Geomatics for Integrated Water Resources Management (GIWRM), 2012 International Symposium on. IEEE, 2012:1-4.
[20] Yoon C R, Kim H C, Lee K J, et al. Method and system for providing tile map service using image fusion: 8670614[P]. 2014-3-11.
[21] Sample J T, Ioup E. Tile-based geospatial information systems: principles and practices[M]. New York, NY, USA: Springer US,2010.
A PARALLEL CONSTRUCTION METHOD OF REMOTE SENSING IMAGE PYRAMID MODEL FOR SPARK
Huang Dongmei Yang Yuhao Mei Haibin Wang Zhenhua
(SchoolofInformation,ShanghaiOceanUniversity,Shanghai201306,China)
With the development of remote sensing technology and photogrammetry, the resolution of remote sensing image is increasing and the data is growing day by day. This has put forward higher requirements for fast and efficient processing of massive remote sensing image data, and how to store and process effectively and intelligently remote sensing data become the research hotspot. On the basis of analyzing the parallel construction of existing pyramid model, a Spark image pyramid model is designed. The model provides the image pyramid construction algorithm and the distributed storage structure of image data. The parallel processing of massive remote sensing image data in Spark is realized, and added with the ability of calculating and processing the spatial data format for Spark. The experimental results show that this method can achieve fast and efficient solution to the parallel construction of massive remote sensing image pyramid on Spark cloud platform, especially in the face of massive remote sensing image data, both from the pyramid to build performance or remote sensing images on the calculation efficiency, Spark is more advantages.
Remote sensing image Pyramid Spark algorithm Distribution
2016-03-08。国家自然科学基金项目(61272098);上海市自然科学基金项目(13ZR1455800);海洋大数据时空特征匹配关键技术及在海洋灾害中的示范应用(15590501900)。黄冬梅,教授,主研领域:WebGIS,智能信息处理,辅助决策系统。杨雨浩,硕士生。梅海彬,副教授。王振华,博士。
TP391
A
10.3969/j.issn.1000-386x.2017.05.031
猜你喜欢
环球时报(2022-09-19)2022-09-19 17:19:22
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
浙江大学学报(理学版)(2020年1期)2020-03-12 05:54:30
当代陕西(2019年14期)2019-08-26 09:42:00
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
扬子江(2019年1期)2019-03-08 02:52:34
童话世界(2017年11期)2017-05-17 05:28:25
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
测绘科学与工程(2014年6期)2014-02-27 07:06:23
