
一种相似重复记录检测算法的改进与应用
2017-06-28 14:22:56李军
成都工业学院学报 2017年2期
李 军
(安徽职业技术学院 信息工程学院,合肥 230011)
一种相似重复记录检测算法的改进与应用
李 军
(安徽职业技术学院 信息工程学院,合肥 230011)
介绍数据清洗与相似重复记录检测算法的相关概念以及相似重复记录的清洗原理。对基本近邻排序算法SNM进行了深入分析和研究,指出其中的不足,在此基础上给出改进策略并加以应用。实践证明:该改进算法在关键性能上有明显改善。
大数据;数据清洗;相似重复记录
信息化社会每天都产生大量的数据,这些海量数据通常包含一些重要信息,这些信息往往是信息决策支持系统的决策依据。但庞大的数据集中除了含有重要信息的数据之外,也夹杂着一些无用的、错误的、不一致的、不完整的、重复的数据,即“脏数据”。脏数据的存在不可避免,它不仅可能导致信息失真,还极有可能给依此而建立的决策支持系统以及应用商务智能带来隐患[1]。因此,在数据进入实用系统前进行数据清洗(data cleaning)是非常重要的。数据清洗是将数据库中的脏数据通过一定的技术和手段转变成合乎系统要求的数据处理过程。本文在分析邻近排序算法(Sorted-Neighborhood Method,SNM)原理的基础上,针对SNM算法的不足,提出了排序关键字预处理和伸缩窗口等改进措施,以提高数据的聚类速度和比较速度。
1 相似重复记录清洗
数据清洗通常是从数据是否完整准确、有无冗余以及时空有效性等方面来进行。从数据清洗的内容来看,主要包括错误数据、不完整数据以及相似重复记录3种清洗对象[2]。由于相似重复记录几乎会出现在所有未经清洗的稍大规模的数据集中,因此,针对相似重复记录的清洗尤为重要。
一个客观实体在同一个数据库中以多条完全相同或高度相似的记录形式存在,则这些记录之间彼此互称为相似重复记录。简单地说,在同一个数据库系统中,如果出现两条或两条以上的记录,它们之间出现足够多的相同或相似的属性值,即可认定其为相似重复记录,如表1所示。

表1 相似重复记录实例
最简单的相似重复记录检测方法是用一条记录与数据集中的每条记录进行匹配比较。若数据库中的记录总数为n,则需要进行n(n-1)/2次比较,其时间复杂度为O(n2),对于海量数据来说,显然是不可取的方法。
为提高检测效率,目前通常使用“排序-合并法”,它先以数据表的某个特征属性或组合属性对数据表进行排序处理,尽可能地使相似重复记录聚集在一起,再将记录与一个较小范围内的记录逐一比较,如发现相似重复记录,则根据预定义的相关规则,对它们进行合并。其清洗过程如图1所示。
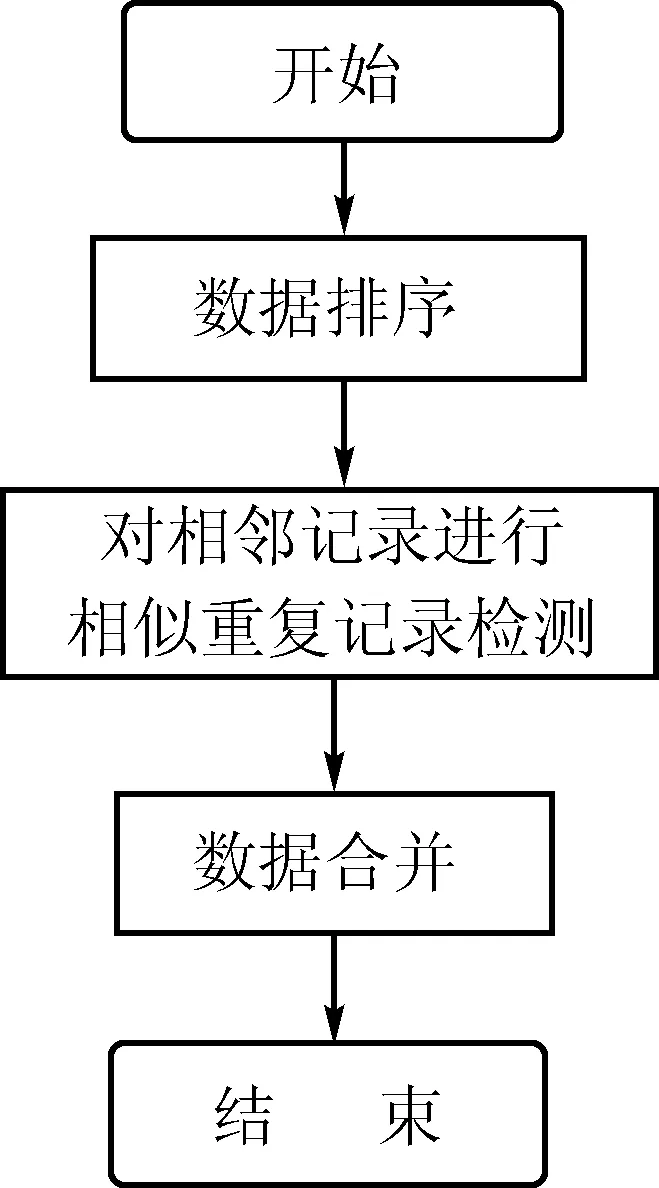
图1 相似重复记录的清洗过程
由图1可知,排序-合并法一般包括3个阶段:
1)作为数据预处理的方式之一,数据排序依据排序关键字对数据库中的记录进行排序处理。这一环节的主要目的是把可能的相似重复记录尽可能地排在一起。排序的结果显然依赖于排序关键字,采用不同的排序关键字,可能得到差异很大的排序结果。因此,如何选择和处理排序关键字,在数据排序这一环节中尤为重要。
2)第2阶段是对相似重复记录的检测。由于进行相似重复记录检测是在一个经过排序处理后所得到的子集范围内实现,其算法的时间复杂度为O(nlogn),检测效率明显提升。目前已有的相似重复记录检测方法大多依此思想为基础[3]。
3)数据合并是对数据集进行增删补改的清洗阶段。经过检测被认定为相似重复记录的两条记录需要进行数据合并。如果两条相似重复记录是完全重复记录,只需删除两者之一即可;如果仅是相似重复记录,则需将两条记录合并为一条新记录,新记录中保留被合并的两条记录中的关键属性(排序关键字)和相同属性,对于差异化的属性则根据具体实用系统的要求而制定的合并规则进行合并。
2 邻近排序算法
目前基于“排序-合并”思想的相似重复记录检测方法有很多,如邻近排序算法(Sorted-Neighborhood Method,SNM)、多趟近邻排序算法和优先权队列算法等。
多趟近邻排序算法一般能够得到较全的相似重复记录的集合,降低漏配的可能性,但该算法需多次独立地执行SNM算法,且每趟执行之前需重新创建不同的排序关键字,时间性能不佳。
优先权队列算法借用Union-Find数据结构,将记录根据相似性程度的不同,分别放在不同的优先权队列。这种算法能够减少记录的比较次数,但如采用单趟优先权队列算法,很有可能造成相似重复记录的漏配,实际应用中多采用多趟优先队列算法,但这又导致消耗较多的时间。
SNM算法是比较成熟的相似重复记录检测算法,它包括以下3步:
1)组建排序关键字。从数据表中提取若干关键属性或属性值的一部分作为排序关键字。被抽取作为排序关键字的属性通常是对记录具有较强区分度的属性或属性子串。
2)排序。根据上步设定的关键字对数据库排序,通过排序,即可把原来分散在数据库不同位置的可能的重复记录聚集在一个邻近的区域内。为了实现这一目的,在确定排序关键字时,需要做更深入的研究。如何确定排序关键字,对于排序结果的影响起到关键作用。
3)合并。为数据集设定一个大小固定的可滑动窗口[4],其大小可根据经验确定,最后进入滑动窗口的记录将与窗口内的其他记录逐一比对。若窗口最多可存放W条记录,则称窗口宽度为W。显然,最后进入窗口的记录只需与窗口中先期进入的W-1条记录进行比较,最多判断W-1次即可确定其是否为相似重复记录。若判断出两条记录是相似重复记录,则对它们进行合并操作。窗口中的记录采用先进先出的队列方式来组织,一旦处理完一条记录,则窗口自动向下(高地址方向)滑动一条记录的位移,再次进行一次新的检测与合并操作,如此反复,直到数据集最后。
该算法先通过排序把可能的相似重复记录尽可能地聚集在一起,再引进滑动窗口,每次只比较窗口中的W-1条记录,通过总共N×(W-1)次的比较,实现相似重复记录的检测。通常情况下,W总是远远小于N,所以采用这种方法进行相似重复记录检测,可提高匹配效率和检测速度。
但SNM算法仍存在以下不足:
1)排序关键字的选定对排序结果影响太大。实践表明,排序关键字选取的好坏不仅直接检测效率,对相似性检测的精度也有很大影响,如果选取不当,还有可能漏配一些重复记录。
2)难以适当控制滑动窗口的大小W。W较小时可能漏配掉相似重复记录;W较大时,会导致比较次数增多,降低检测效率;对于一个确定的数据集,如果重复记录聚类数值差别较大,则根本无法选择出较为恰当的W。
3)滑动窗口内两条记录的比较时间长。这是因为在滑动窗口内,两条记录基本上采用笛卡尔成绩方式进行字段比较。
3 邻近排序算法的改进思想
针对SNM算法的不足,做出以下修改:
1)改进关键字预处理方法。由于排序关键字的选定对SNM算法的排序结果影响很大,在对数据集进行排序之前,提前对排序关键字做一些预处理,以进一步提高相似重复记录集中的效果。具体做法是先用统一的标准格式对排序关键字中的繁杂表示形式实现规格化处理,形成统一格式的数据;再对排序关键字中的单词进行排序处理,以增强数据库中数据排序结果的单一性[5]。
2)采用可伸缩窗口。为弥补在SNM算法中因滑动窗口大小固定而带来的不良影响,在改进算法中,滑动窗口的大小可以随着已排序记录聚类规模的大小来进行自适应式的调整。设当前窗口宽度Wdi为:
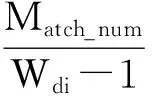
(1)
其中:Wd1为最小窗口宽度;Wd2为最大窗口宽度;Match_num为窗口中相似记录数目,其取值范围为[0,Wdi-1]。
由式(1)可知,当Match_num变大时,在该窗口内聚集的相似重复记录变多,Wdi也随之变大,即通过增大滑动窗口来扩大相似重复记录的检索范围,以减少相似重复记录遗漏的可能性;当Match_num增大到Wdi-1,即意味着整个滑动窗口的记录均为相似重复记录,此时的Wdi=Wd2。如果当前窗口中没有相似重复记录,则Match_num=0,那么Wdi=Wd1,即通过缩小滑动窗口来减小比较范围,以避免过多的无效检索。
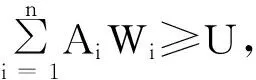
4 验证结果及衡量标准
衡量相似重复记录检测算法的性能指标通常用召回率和误识别率来加以描述。
1)召回率R(Recall)也叫查全率。设T为数据集中的相似重复记录的实际条数,C为检测算法实际检测出来的相似重复记录条数,则有R=C/T。显然,R的值域为[0,1],求得的R值越大,表明检测算法的查全性能越好。
2)误识别率PF(False Percent)也叫失误率。在相似重复记录检测过程中,算法错误地判定为重复记录的数目用F表示,被算法判定为重复记录的总数用A表示,则PF=F/A。PF越低,算法判别的准确性越高。
实验数据来自于当地一家销售公司的部分客户信息数据集,该部分数据集共有1 218条记录,数据表含有姓名、性别、身份证号码、通信地址、联系电话、单位名称、单位地址、办公电话共8个属性。在实验中设定相似度阈值U=0.85,表2记录了4种不同情况下的检测结果。
实验表明,在传统SNM算法的基础上,适当修改算法,采取诸如对排序关键字进行统一数据格式处理、对排序关键字中的单词进行排序、根据属性对记录的区分度不同为部分属性设置权重值,在进行相似重复记录检测时采用可伸缩窗口等措施,能够显著改善SNM算法的性能。此外,改进后的SNM算法相较于多趟近邻排序算法,具有更加优越的时间性能;而相较于单趟优先权队列算法,改进后的SNM算法则具有更好的查全性能。
5 结语
本文针对SNM算法的不足,提出了一些改进措施。通过排序关键字的预处理,提高记录聚类的速度;采用伸缩窗口思维可以使滑动窗口的大小,自动跟随滑动窗口内的相似重复记录的数目呈现正相关的变化,既能避免过多的无效检索,又能进一步减少相似重复记录因窗口固定大小而被遗漏的可能。为关键属性或其部分属性设置权重值,只需对设有权重值的属性进行比较,省略了非关键属性的比较,明显加快了窗口内两条记录的比较速度。但本改进算法也还存在一些不足,主要是:1)窗口内两条记录的比对没能找到更加高效的算法,导致整个检测算法的时间性能还有待提高;2)伸缩窗口的引入,确实提升了SNM算法的性能,但依然存在极少数相似重复记录漏配的现象。此外,实验系统的数据集规模偏小,可能掩盖了改进算法的某些缺点等,这将是今后工作的研究重点。
[1]HAN J,KAMBER M.Data mining: concepts and techniques[M].2版.北京:高等教育出版社,2011:1-18.
[2]刘喜文,郑昌兴,王文龙,等.构建数据仓库过程中的数据清洗研究[J].图书与情报,2013(5):22-28.
[3]郭志懋,周傲英.数据质量和数据清洗研究综述[J].软件学报,2002,13(11):2076-2082.
[4]谢文阁,佟玉军,贾丹,等.数据清洗中重复记录清洗算法的研究[J].软件工程师,2015,18(9):61-62.
[5]戴颖,李兴国,赵启飞.一种相似重复记录检测算法的改进研究[J].计算机技术与发展,2010,20(7):13-16.
Improvement and Application of a Detection Algorithm for
Similar and Duplicated Records
LIJun
(School of Information Engineering,Anhui Vocational and Technical College,Hefei 230011,China)
In the age of big data,the research of data cleaning algorithm is very important.This paper briefly introduces the concept of data cleaning and detection algorithm for similar duplicate records,then introduces the principle of cleaning the similar duplicate records.The Sorted-Neighborhood Method(SNM) is analyzed and studied and its shortcomings are pointed out,based on this improved strategy and application,the practice proves that the improved algorithm,the key performance is significantly improved.
big data;data cleaning;similar duplicate record
10.13542/j.cnki.51-1747/tn.2017.02.004
2017-05-09
李军(1967—),男,讲师,硕士,研究方向:数据挖掘、智能算法,电子邮箱:wodejiaren2017@126.com。
TP311
A
2095-5383(2017)02-0017-04
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
制造技术与机床(2018年11期)2018-11-23 01:08:02
意林(绘英语)(2018年1期)2018-04-28 01:21:42
儿童绘本(2018年5期)2018-04-12 16:45:32
城市轨道交通研究(2015年11期)2015-02-27 11:02:50
雷达学报(2014年4期)2014-04-23 07:43:07
