
基于异构Hadoop集群的负载均衡策略研究
2017-06-27 08:14冯亮亮
计算机技术与发展 2017年6期
秦 军,冯亮亮,孙 蒙
(1.南京邮电大学 教育科学与技术学院,江苏 南京 210003; 2.南京邮电大学 计算机学院,江苏 南京 210003)
基于异构Hadoop集群的负载均衡策略研究
秦 军1,冯亮亮2,孙 蒙2
(1.南京邮电大学 教育科学与技术学院,江苏 南京 210003; 2.南京邮电大学 计算机学院,江苏 南京 210003)
异构Hadoop环境中,每个节点的处理能力各不相同,且集群中的节点会不断增加和删除,随着作业量的增大,负载倾斜会越来越明显。显然,负载均衡也成为影响Hadoop集群性能的重要因素之一。针对异构Hadoop环境中MapReduce任务调度,提出了一种新的负载均衡算法。该算法充分利用节点性能和当前的计算资源,根据集群负载平衡度量值进行任务分配,将任务分配给适合的节点,使集群负载逐渐趋于平衡,以提高集群节点利用率。由于Hadoop集群中各节点通过网络连接,以节省网络传输代价,因此在负载均衡调度时,根据数据分布特点,优先考虑数据的本地性,以缩短任务执行时间。仿真实验结果表明,所提出的负载均衡算法能明显改善系统性能,有效缩短MapReduce作业执行时间。
Hadoop集群;MapReduce;节点性能;任务调度;负载均衡
0 引 言
Hadoop是由Apache基金开发的分布式系统基础架构[1]。该架构充分利用集群进行高速运算和存储。作为开源的云计算平台,已有大量学者加入到Hadoop集群的研究中,并且有许多著名的互联网公司,例如Facebook、Yahoo、百度、阿里巴巴等利用Hadoop集群进行海量数据的存储和处理[2]。在大规模的并行计算中,如何充分利用集群的计算资源,提高系统性能,成为负载均衡技术研究的重点[3-4]。
作为Hadoop的核心框架,MapReduce利用分而治之的思想将主节点JobTracker的作业执行分成很多个子任务task[5],然后交给集群中TaskTracker节点去执行。MapReduce作业执行主要分为map任务和reduce任务。在map阶段,接收
因此,为了保持异构Hadoop集群处于负载平衡状态,在对集群节点进行任务分配时,应该充分考虑节点之间的性能差异和集群当前的负载情况,将任务分配给与其计算能力相应的节点,从而不因局部节点负载过重导致集群负载失衡。仿真实验结果表明,所提出的负载均衡算法能明显改善系统性能,有效降低MapReduce的运行时间。
1 相关研究及改进模型
负载均衡问题一直是影响Hadoop集群性能[10]的重要因素之一。通过负载均衡可以使得集群中的节点处于相对的相等忙碌状态。一个好的负载均衡算法能通过均衡任务来重新分配负载、优化系统的资源利用率和任务的响应时间。
文献[11]提出了LBVP算法:利用虚拟分区Partition,将map阶段处理完成后的输出数据进行分区,保证各个reduce获取的数据量基本一致,从而达到负载均衡的目的。该算法对于同构环境下的集群负载均衡效果较好,但对于异构环境下的集群,每个节点处理能力各不相同,即使对于输入同样的数据量,其处理效果也会有较大差异。文献[12]提出了基于节点性能的LBNP负载均衡算法:异构环境下,根据节点性能,解决map阶段执行完后的数据预分配问题,从而均衡reduce阶段任务的执行时间。该算法考虑了异构环境下节点的性能差异,从局部reduce阶段任务调度进行均衡,不能解决在全局MapReduce执行过程中的负载均衡问题。同样地,文献[13]结合节点计算能力和数据本地性感知的MapReduce负载均衡也只是针对reduce阶段任务调度提出的。
针对上述集群负载均衡中存在的问题,提出了一种改进的任务调度负载均衡模型,如图1所示。

图1 任务调度负载均衡模型
图1中的负载均衡器包括三个模块:负载均衡度量(Load Balancing,LB)、本地化节点请求队列和非本地化节点请求队列。通过对异构环境中TaskTracker节点进行合理的任务调度,保持集群中节点间的负载平衡。其中LB是通过周期地收集TaskTracker节点信息得到的集群负载均衡估量值。按照数据本地性要求,将请求map或reduce任务的TaskTracker节点分为本地化和非本地化请求队列,并根据当前集群负载均衡度量值LB优先对本地化节点请求队列中的节点分配任务。由于在每一个心跳周期内,集群性能和请求分配任务的节点是动态变化的,所以负载均衡器所维护的两个节点请求队列是基于抢占式优先的。这样负载均衡器在进行任务调度时是基于当前集群的实时信息进行的,保证了调度的可靠性。
2 算法实现过程
图1的任务调度负载均衡模型是为了在进行任务调度时,根据当前节点性能和负载均衡度量值将任务分配给与其能力相匹配的节点上,避免超载或饥饿现象,从而使集群的资源得到充分利用。该算法所需要的计算资源和实现步骤如下所述。
2.1 节点性能计算
为了充分反映节点当前性能,应该从多个变量因素进行分析,如CPU利用率、内存利用率、磁盘I/O占用率、网络带宽占用率以及执行task任务的响应等。综合这些因素来反映节点性能。对于节点i(i=1,2,…,n),其性能计算见式(1):
(1)
其中,pi表示节点i的性能;pcpu、pio、pmemeory、pbandwidth和presponse分别表示CPU利用率、磁盘I/O占用率、内存利用率、网络带宽占用率和单位时间内对task任务的响应速率;r1、r2、r3、r4和r5分别表示各变量在影响节点性能方面所占的比重,根据实际环境来确定,并且r1+r2+r3+r4+r5=1。
2.2 集群整体性能估算
JobTracker周期性地收集TaskTracker通过式(1)计算得到的节点性能,从而得到集群整体的负载状况。假设集群中含有n个计算节点,每个节点性能为pi(i=1,2,…,n),计算集群整体平均性能为:
(2)
2.3 节点请求队列的维护
TaskTracker节点向JobTracker请求分配新的任务时,不仅要保证当前节点运行良好,具有较高的性能,还要保证有足够的计算资源用于执行task任务。节点i(i=1,2,…,n)当前可以用的计算资源式表示为:
(3)
其中,qi表示当前节点剩余计算资源;qcpu、qio、qmemory、qbandwidth分别表示CPU、磁盘I/O、内存和网络带宽的剩余量;k1、k2、k3和k4分别表示各变量所占的比重,并且k1+k2+k3+k4=1。
当有多个节点请求分配任务时,考虑到异构环境中的节点差异,为同样性能表现的节点,分配相等任务量时,执行任务时间会受到剩余内存和CPU等可用计算资源的限制。因此任务调度器需要综合当前节点性能和剩余可用计算资源。可用两者的比值来表示:
(4)
其中,j表示请求分配任务的节点;Nodej表示作为任务调度器中节点请求队列排序的标准;pj和qj可分别由式(1)、式(3)计算得到。
考虑到数据本地性,任务调度器会维护两个节点请求队列:本地化节点请求队列和非本地化节点请求队列,分别用LocalityQueue和nonLocalityQueue来表示。当有多个节点同时请求分配任务时,通过判断该节点是否含有本地化数据,将其加入到相应的队列。加入到队列的节点按照式(4)从大到小进行排序。而且队列LocalityQueue具有比队列nonLocalityQueue更高的优先级,即在进行任务调度时,会优先从LocalityQueue队列中选择节点来分配任务。
2.4 负载均衡度量
在MapReduce集群大规模的数据计算时,集群负载应该是逐渐趋于平衡的,即大部分节点的计算资源能得到充分利用,节点性能均表现良好,出现节点负载超载或者长期空闲的概率很低。根据概率论中的大数定律和中心极限定理可知,节点性能表现值分布应该近似数学中的正态分布。用X表示集群节点性能值,则X~N(μ,σ2)。其中X即为式(1)中的pi,期望μ为式(2)计算得到的均值,σ2为方差,见式(5):
(5)
其中,Xi表示节点i(i=1,2,…,n)的性能。
由正态分布3σ准则可知,数据的取值几乎全部集中在(μ-3σ,μ+3σ)范围内。对于负载均衡的集群来说,其节点性能值的分布也应遵守3σ准则。这里设定集群负载均衡的范围为μ-2σ
2.5 任务调度负载均衡算法的实现步骤
在异构环境下,基于集群节点性能和数据本地性的任务调度负载均衡算法的实现步骤如下:
(1)每个心跳周期内,JobTracker收集TaskTracker节点的信息。节点的性能和可用资源的计算根据式(1)、式(3)完成。
(2)当有多个TaskTracker节点发送请求分配新任务的请求时,任务调度器会将含有本地化数据的节点放入到LocalityQueue队列中,而不含本地化数据的节点放到nonLocalityQueue队列。并按照式(4)将队列中的节点从大到小进行排序。
(3)当LocalityQueue队列非空时,依次取队列中节点,当节点性能值大于LB时,可以为该节点分配新任务,否则判断队列中的下一个节点。
(4)当LocalityQueue为空或者已经遍历结束时,依次取nonLocalityQueue队列中的节点,同样当节点性能值大于LB时,可以为该节点分配新任务,否则判断队列中的下一个节点。
(5)重复步骤(1)~(4)。
需要说明的是,在心跳周期内如果有新的节点请求分配任务,则将其按照步骤(2)中的规则加入到相应队列,可见负载均衡器所维护的节点请求队列是实时更新并且是基于抢占式优先的。这样保证了任务分配时,选择性能和计算资源最好的节点,缩短任务执行时间,并且满足负载均衡的要求。
3 仿真实验及结果分析
通过仿真实验评估改进后的任务调度算法和Hadoop默认的FIFO调度算法[14]的性能表现。实验中选取10台在CPU频率、内存大小等各不相同的物理机器用来模拟异构的集群环境。MapReduce应用作业选择sort,即对输入字典中的数据进行排序。作业的大小依次选择2 G、4 G、6 G、8 G和10 G。在相同输入数据规模的情况下,分析原有Hadoop框架中FIFO任务调度算法和改进后的任务调度算法在作业完成时间、集群性能和系统吞吐量方面的对比,结果见图2~4。

图2 基于作业完成时间的比较
从图2可以看到,改进后的任务调度执行时间通过更多的执行本地化数据,缩短了任务执行时间,从而加快了整个作业完成时间。
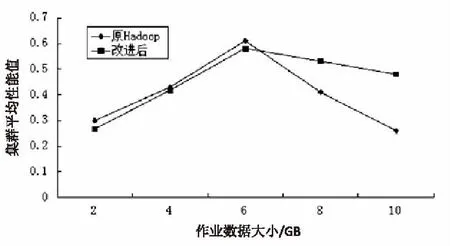
图3 基于集群性能表现的比较
从图3可以看到,作业在6 GB左右时,集群平均性能达到了最大,随着作业规模的增加,负载加大,改进后的集群性能相对于原Hadoop仍然能保持在一个较高水平,可见负载均衡效果得到了明显的改善。
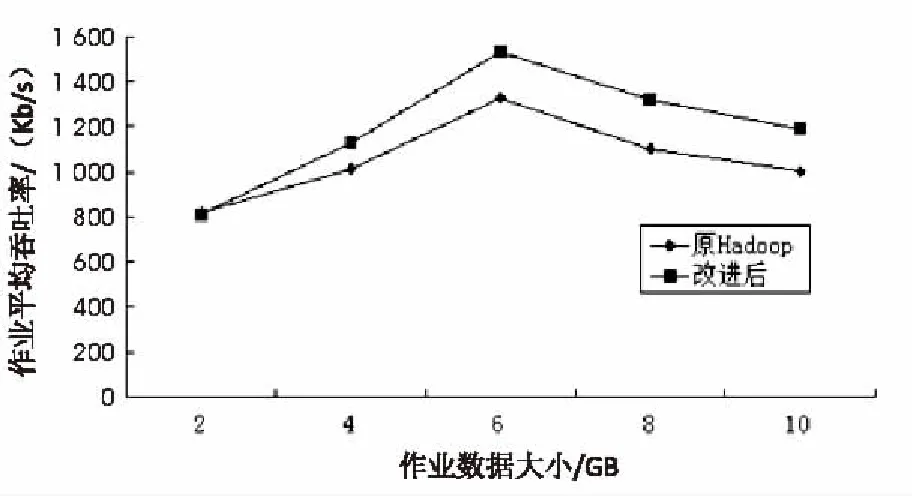
图4 基于集群系统吞吐量的对比
从图4中可以看到,系统的吞吐量增大,这是由于改进后的任务调度算法充分考虑异构环境下的节点差异,通过利用集群中节点计算资源增大了系统吞吐量。
4 结束语
MapReduce中的调度相关问题是影响其执行性能的重要因素之一,负载均衡则是其在调度中需要考虑的因素。在分析节点计算性能的基础上,提出了一种负载均衡度量新的计算方式,通过与LB的比较,将任务分配给与节点计算能力最匹配的节点,使计算资源得以充分利用,使得集群负载逐渐趋于均衡,增加了系统吞吐量。且在进行负载均衡调度的同时,通过优先调度本地化节点,以减少数据迁移代价和网络带宽,缩短了任务的执行时间。仿真实验结果表明,提出算法显著提高了系统的综合性能。
[1] Apache Hadoop[EB/OL].2016-02-13.http://hadoop.apache.org.
[2] 应 毅,刘亚军.MapReduce并行计算技术发展综述[J].计算机系统应用,2014,23(4):1-6.
[3] 柳 香,李瑞台,李俊红,等.Hadoop性能优化研究[J].河北师范大学学报:自然科学版,2011,35(6):567-570.
[4] 周一可.云计算下MapReduce编程模型可用性的研究与优化[D].上海:上海交通大学,2011.
[5] 孙彦超,王兴芬.基于Hadoop框架的MapReduce计算模式的优化设计[J].计算机科学,2014,41(11A):333-336.
[6] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[7] 许 丞,刘 洪,谭 良.Hadoop云平台的一种新的任务调度和监控机制[J].计算机科学,2013,40(1):112-117.
[8] Fan Y,Wu W,Cao H,et al.A heterogeneity-aware data distribution and rebalance method in Hadoop cluster[C]//ChinaGrid annual conference.[s.l.]:IEEE,2012:176-181.
[9] 顾 涛.集群MapReduce环境中任务和作业调度若干关键问题的研究[D].天津:南开大学,2014.
[10] 荀亚玲,张继福,秦 啸.MapReduce集群环境下的数据放置策略[J].软件学报,2015,26(8):2056-2073.
[11] Fan Y,Wu W,Cao H,et al.LBVP:a load balance algorithm based on virtual partition in Hadoop cluster[C]//Asia Pacific cloud computing congress.[s.l.]:IEEE,2012:37-41.
[12] Gao Z,Liu D,Yang Y,et al.A load balance algorithm based on nodes performance in Hadoop cluster[C]//16th Asia-Pacific network operations and management symposium.[s.l.]:IEEE,2014:1-4.
[13] 李航晨,秦小麟,沈 尧.数据本地性感知的MapReduce负载均衡策略[J].计算机科学,2015,42(10):50-56.
[14] Tao Y,Zhang Q,Shi L,et al.Job scheduling optimization for multi-user MapReduce clusters[C]//2011 fourth international symposium on parallel architectures,algorithms and programming.[s.l.]:IEEE,2011:213-217.
Research on Load Balancing Strategy with Heterogeneous Hadoop Clustering
QIN Jun1,FENG Liang-liang2,SUN Meng2
(1.College of Education Science & Technology,Nanjing University of Posts and Telecommunications,Nanjing 210003,China; 2.College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
In the heterogeneous Hadoop environment,processing capabilities of the nodes are diverse and various,among which each node may be continuously added or removed in the clustering and its load slope may increase obviously with tasks.Apparently,load balancing is one of the most important factors that affect the performance of Hadoop clustering.Thus a new load balancing algorithm has been proposed and employed in MapReduce task scheduling of the heterogeneous environment,which makes full use of the node performance and current computation resources according to the cluster load balancing measurement value to allocate task to suitable node for balancing the cluster load gradually and promoting coefficient of utilization of cluster nodes.Since the nodes in the Hadoop clustering are connected with network to save the costs of network transmission and the data locality should be considered with priority to decrease execution time for each task according to the characteristics of data distribution during load balancing scheduling.Simulation results show that the proposed load balancing algorithm has improved performances of whole system significantly and shorten the execution time of the MapReduce task.
Hadoop clustering;MapReduce;node performance;task scheduling;load balancing
2016-07-15
2016-10-20 网络出版时间:2017-04-28
江苏省自然科学基金项目(BK20130882)
秦 军(1955-),女,教授,研究方向为计算机网络技术、多媒体技术、数据库技术;冯亮亮(1992-),女,硕士研究生,研究方向为分布式计算机技术与应用。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1703.070.html
TP301.6
A
1673-629X(2017)06-0110-04
10.3969/j.issn.1673-629X.2017.06.023
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
吉林大学学报(信息科学版)(2022年2期)2022-08-15
小学教学研究(2022年5期)2022-04-28
计算机测量与控制(2022年2期)2022-03-30
科学与财富(2020年6期)2020-05-19
微型电脑应用(2019年10期)2019-10-23
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
科技与创新(2017年11期)2017-07-01
软件(2016年5期)2016-08-30
