
除了比赛,你或许对这些问题也感兴趣
2017-06-14 18:26
第一财经 2017年22期
Q AlphaGo是什么?
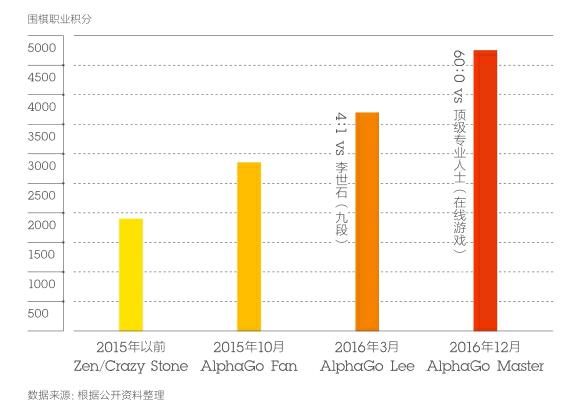
AlphaGo是DeepMind于2010年开始研发的围棋人工智能,与之前棋类游戏人工智能主要依靠强大的计算能力来暴力破解不同,AlphaGo采用了更类似于人的算法,以应对围棋这个具有超高复杂度的游戏。运用了全新的机器学习技术,在走每一步棋时,先通过策略网络(policy network)将棋盘上的局势作为信息输入,对所有可行的落子位置生成概率分布—这就像是围棋高手先对局势作出判断,进而发现可以进攻的薄弱地带。接下来它再通过价值网络(value network)分析每一个落子位置影响胜负的概率—这相当于棋手面对具体问题时,高手会选择冲、挡、扳、接等各种下法。AlphaGo通过强化学习不断训练这两种神经网络,最终实现了人工智能可以实时有效解决围棋棋局问题的目标。
随着AlphaGo能力的不断增强,围棋圈对它的称呼也从开始的“阿尔法狗”到“阿尔法围棋”,进而到现在的“阿尔法师”。
QDeepMind为什么会选择围棋?
自从人工智能诞生的那一天起,游戏就是它最好的伴侣。人工智能的目标在于分析真实世界,而游戏的本质是人类对于世界的模拟,想像一下象棋里的将、士、车、马、炮,以及楚河、汉界等元素就能明白这一点。此外,由于这些游戏有着广泛的受众,对于提高和测试人工智能的水平来说,都是再适合不过的对象。
在所有游戏中,棋牌类游戏又因为规则简洁明了,输赢都在盘面,而备受科学家青睐。从简单的跳棋、五子棋,到更加复杂的中国象棋、国际象棋,以及高难度的围棋和德州扑克,它们成为一步步检验人工智能新算法水平最好的标杆。
QAlphaGo还能做什么?
AlphaGo虽然是围棋人工智能,但它解决围棋时所使用的机器学习方法却能够广泛应用到其他领域。例如DeepMind团队曾在TensorFlow上開源了一个高级框架Sonnet,以帮助科学家快速创建神经网络模块;此外他们还与Google应用商店Play Store一起尝试将机器学习应用到广告推荐系统中,以及与Android团队合作,试图提高系统的效能。
其中最令人惊喜的是,他们尝试利用人工智能来优化Google数据中心的冷却系统,数据显示,优化过的系统可以降低40%的能耗,对于有着成千上万台服务器的Google来说,这意味着每年能节约上亿美元的开销。
Q从棋手角度看,AlphaGo给围棋带来的冲击有哪些?
首先,AlphaGo冲击了很多围棋选手固有的理念。
过去,人类棋手的下法都是对过往经验的研究和总结,但即使是职业棋手,一辈子可以下的围棋盘数只有几千量级,而其中真正有参考价值、能够推动这门技术前进的仅在百盘左右。然而,AlphaGo最新版本开始自我对弈之后,每天下棋的盘数从几千到一万不等,甚至更多,这迅速将围棋理念推向极致。
其次,未来顶尖棋手的收入可能会逐渐下降,但是随着参与围棋的门槛降低,普及率上升,整体市场将有可能扩大。
围棋未来的路径多少可以参考曾经的国际象棋,1997年,IBM研发的人工智能Deep Blue在第二次挑战国际象棋世界冠军卡斯帕罗夫中以3.5:2.5赢得胜利,在整个人类世界引起轩然大波,这场精彩的营销使得IBM的股价一度上涨30%左右。据统计,在Deep Blue战胜人类后,很多国家象棋的赞助商吝于投资冠名,顶级棋手收入略有下降,次一级的棋手收入相比与1970年巅峰时期则下降很多。因为人类之间比赛的关注度远远低于人机大战。
但与此同时,国际象棋通过人机大战在全球普及开来。原先国际象棋的影响力主要集中在苏联,以及德国、西班牙、古巴等几个国家,在非洲和亚洲几乎没有影响力。但现在完全不同,例如在中国,这几年国际象棋的发展速度就非常显著。
猜你喜欢
汽车观察(2022年12期)2023-01-17
国际太空(2021年10期)2021-12-02
汽车观察(2021年11期)2021-04-24
诗选刊(2019年8期)2019-08-12
中国外汇(2019年22期)2019-05-21
金桥(2018年4期)2018-09-26
金色年华(2016年8期)2016-02-28
太空探索(2014年5期)2014-07-12
