
基于事件图的新闻标题生成研究
2017-06-08 05:50孙锐
乐山师范学院学报 2017年4期
孙锐
(乐山师范学院 计算机科学学院,四川 乐山 614000)
基于事件图的新闻标题生成研究
孙锐
(乐山师范学院 计算机科学学院,四川 乐山 614000)
为新闻自动生成标题是一个极具挑战的任务。文章基于事件图,提出一种有效的无监督标题生成方法。给定一篇新闻文档,首先为其构造事件图以表示整个篇章,然后采用图排序方法以计算每个事件的显著性得分。随后为排序后的多个事件,抽取其在文中的依存片段作为候选标题,最后设计一个目标优化函数以搜索最终的标题。在英文和中文数据集上的实验结果表明,文章提出的方法能有效地学习显著性事件并能较好地生成标题。
事件抽取;互增强原则;标题生成
0 引言
文本标题能帮助读者快速地从新闻报道中抓住主旨和感兴趣的内容。例如,Google新闻报道Ukraine Delays Announcement of New Government,读者可直观地了解该报道为乌克兰延迟新政府成立宣告。然而,标题的生成和评估都是非常有挑战性的,其原因是在长度受限的情况下标题应要求包含重要信息,同时也要具备可读性。

表1 新闻片段示例
观察Google News不同时段的新闻标题,超过95%的标题包含至少一个事件,且正文大多围绕事件来组织。根据报道者书写习惯的不同,主旨事件可能在正文的不同位置出现(通常出现在首句),而其他相关事件通过公共角色或实体与主旨事件产生联系。表1给出的新闻片段,描述了一个名叫Chris Scott Gilliam的恐怖主义者想杀掉每个人。容易看出,文中有大量与杀人相关的事件,如“sending mail bombs”“arresting”和“testifying”等。此外,该新闻的主角参与了包括主旨事件在内的大多数事件。因此,从文中学习主旨事件对标题生成是有意义的。一方面,主旨事件中的词或短语可以确保标题的信息度;另一方面,事件可以为各个短语提供语义上的约束。
本文工作旨在为单篇新闻文档从事件出发生成标题。因此,如何学习主旨事件是关键研究环节。首先,从文中提取词汇链和事件以构造事件图,该图可以看作是文章的压缩表示。不同于传统事件图[1],本文事件图并不描述事件间的因果或时序关系,而是论元间的语义关系。其次,利用图的排序方法来习得事件的显著性。最后将事件所在的依存片段作为候选标题并利用优化算法来搜索最终的标题。
本文利用结构化事件来生成标题,并对比了多种排序方法来学习显著性事件。在中英文两种语料上的实验结果表明本文方法能取得有效的性能。
1 标题生成
本文方法主要分为三个步骤:1)基于词汇链和事件集合来构建文章的事件图,该图描述了文章的篇章大意;2)采用图的排序方法学习显著性事件;3)抽取事件依存片段并搜索最终标题。
1.1 事件图构建
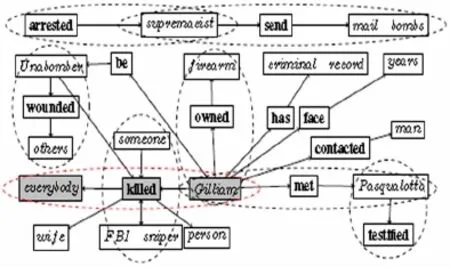
图1 篇章事件图示例
如图1所示,本文的事件图可以抓住新闻的主旨,从图中直观地发现新闻主角以及其参与的事件集合。图中,每个结点表示文档中的一条词汇链,边则表示事件中成分间的关系。因此,在事件图构建前需进行词汇链和事件的抽取。
本文词汇链的抽取采用以下原则:1)词干化后形态相同的词被视为同一个词;2)拥有相同头词的短词应在同一链中;3)代词应根据其同指关系加入相应词汇链;4)在词典中处于同一语义集合的词汇须在同一链中。根据以上原则,表1可生成词汇链:{Chris Scott Gilliam_3_2,he_5_2, He_2_3,Gilliam_10_7,Gilliam_4_9,Gilliam_4_11,Gilliam_8_13,Gilliam_3_14},链中第一次提及可视为代表词,即Chris Scott Gilliam。对词汇链初始权重的度量可使用两个特征:词汇链的长度和所跨行数。即采用如下公式计算:
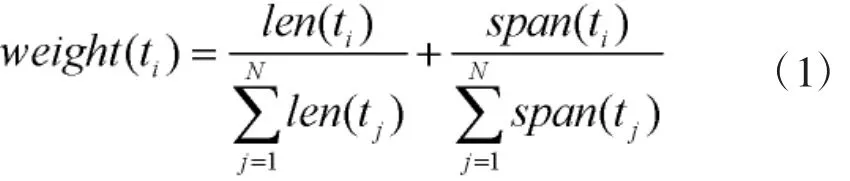
其中t表示词汇链,函数len和span分别表示词汇链长度和所跨行数,分别反映了词汇链中词的出现频率及分布。
本文事件采用三元组形式的定义。不同于标准事件抽取方法,本文采用一种简单且有效的方法进行事件抽取。该方法基于依存分析的结果,利用nsubj和dobj等动词依存关系。事件的论元是细粒度的。如表1中语句S14,“someone should kill the FBI sniper”可由依存关系“nsubj(kill-10,someone-8)”和“dobj(kill-10,sniper-13)”,组合成事件“someone kill snipper”。
一旦所有事件抽取完成后,即可构建篇章事件图。每个结点表示一条词汇链,每条有向边代表触发词与其论元间的关系。因此,一个事件至多可以对应图中的两条边。如图1所示,图中从主语到宾语的一条路径代表一个事件。不同于传统的篇章表示,篇章事件图并不关注语句元间的语义关系,而关注于篇章事件的分析,其事件间的关系通过公共的事件论元来呈现。
1.2 显著事件学习
直观地,类似于PageRank或HITS的传统图排序方法可用于在事件图中抽取最重要的事件。结点的权重与其在图中的度有关。本文首先采用一种类似于PageRank的方法在事件图中进行事件排序。不同地,结点权重不需要分散到其他结点。结点度越大,其权重越大。一个事件包含一个触发词和至多两个论元,因而事件权重可通过累加事件元素的权重获得,即:
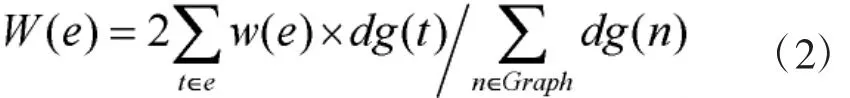
其中t表示事件e中每个元素,函数dg(.)表示图中结点n的度。该方法为GraphR。
GraphR中主要考虑了词汇链对事件权重计算的贡献,但事实上,事件对词汇链的权重也应同时考虑。因此,本文引入互增强原则来同时学习事件和词汇链的权重。互增强模型的关键是如何度量事件和词汇链的关系。
给定一篇新闻文档,假设有n个事件{e1,e,...,en}和m条词汇链{t1,t2,...,tn}。各自的权重分别定义为[w(e1),w(e2),...,w(en)]和[w(t1),w(t2),...,w(tn)]。关系矩阵r用于描述事件ei和词汇链tj间的关系。以往的研究表明多数标题出现在文章的开始,相应地出现在文章开始的事件也越重要,因而出现在ei的词汇的频率及事件的位置信息可用于度量事件和词汇的关系。关系矩阵定义如下:
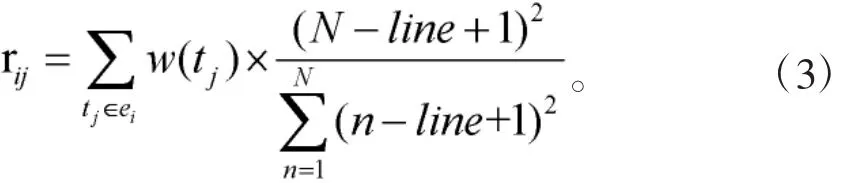
其中w(tj)可用式1计算,t表示事件中的词汇链;line和N分别表示事件所在行号和文章总行数。因此,可定义迭代算法按下式来计算权重:
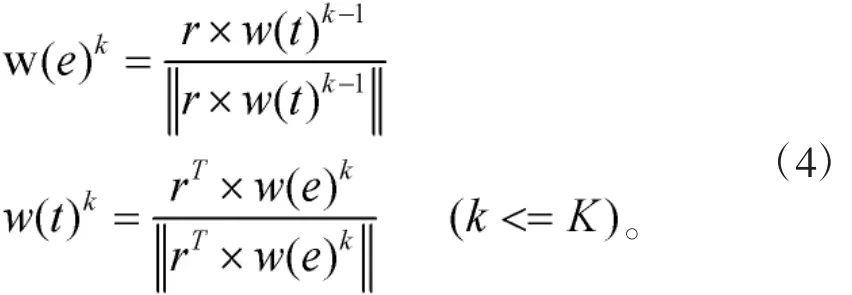
其中K表示最大迭代次数。从初始w(t)0开始,重复迭代过程直至权重向量移民定。参数在开发集上调节,当w(t)0和K分别设置为1.0和10时权重向量趋于稳定。
1.3 事件扩展
直观地,排序算法得到的显著事件更可能出现在标题中。观察显著事件所在语句的依存树,可发现如下一些现象。首先,事件论元中的指代须用相应词汇链的头词替换;第二,与事件论元有着语义关系的重要词汇可能因依存错误而丢失;第三,与标题直接相关的事件不一定能得到更高的排名。
因此,每个显著性事件需要扩展为一个依存片段。每个片段可视为一个候选标题,标题生成的过程即为搜索过程,目标函数可作如下定义:
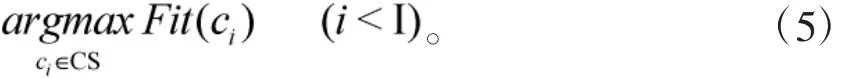
其中,I为候选标题数目,而ci和CS分别表示第i个候选和候选集合。Fit(.)函数可从两个方面度量。一是候选所包含的词汇链权重,另一个是该候选的排名。因而,该函数可定义如下:

具体地,每个事件候选的生成采用如下方法生成:1)构建词汇池,初始时包含了事件的所有论元;2)搜索所有与池中词汇有着直接语义关系的词,将权重最高的词汇加入到池中;3)如词汇池已满或没有词汇再被选中则结束,否则返回第2步;4)池中的所有词汇按其在文中出现的位置形成候选标题。以上过程是一种贪心的策略。如表中语句3,事件“he kill everybody”可扩展为片段“Chris Scott Gilliam wanted to kill everybody”。最后得分最高的候选即可作为最终的标题,本文方法为MutualR。
2 实验
2.1 实验设置
实验在中英文两个数据集上进行。英文语料为DUC04任务1标准评估语料,包括500篇文章。中文语料为新华社人民日报语料,包括800篇文章。DUC07语料中前100篇文章作为开发集。统计结果表明,测试集中有低于5%的抽象程度较高的标题,每篇文章约50个事件,由此可见本文方法在这些数据集上是适用且有意义的。
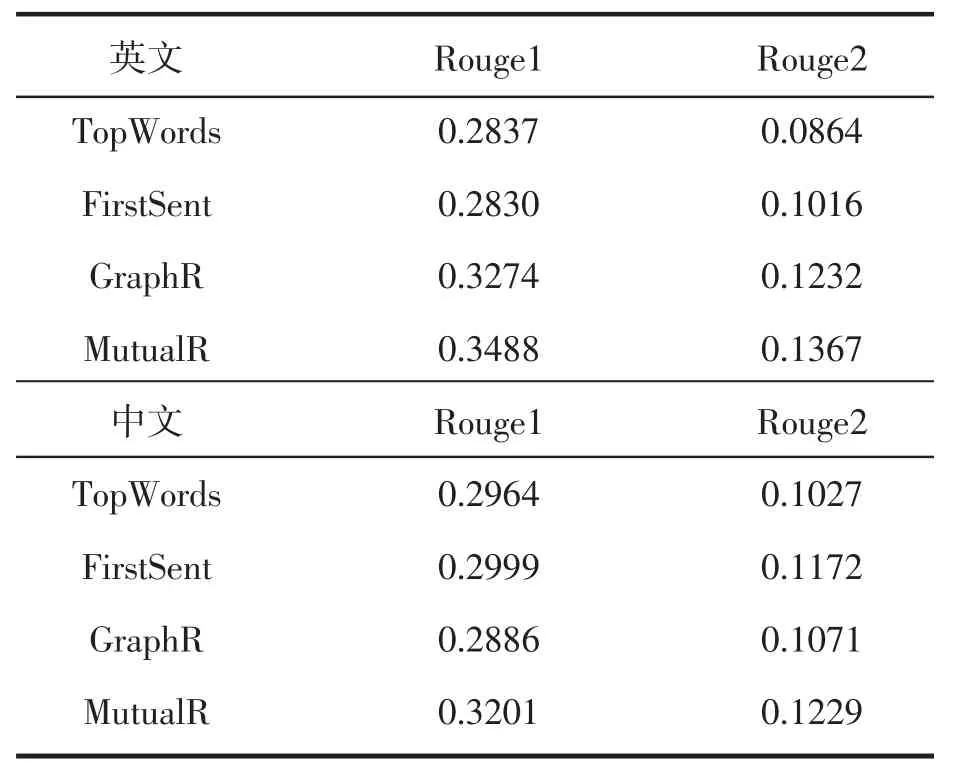
表2 中英文语料上不同方法的性能评估
系统评估采用Rouge方法[2],其中Rouge1和Rouge2用于评估标题的信息度和流畅度。因为需要进行中文数据集的评估,我们基于同义词词林扩展版重现了Rouge1和Rouge2的计算。
2.2 基线系统
TopWords:Lead10[3]方法简单地从首句中提取前10个词作为标题。尽管该方法简单,但它在标准评测数据上超过了以往了一些机器学习方法。
FirstSent:为验证事件扩展的有效性,直接在文章首句上执行了本文相同的实验。
2.3 结果
由表2所示的实验结果可见,MutualR在两个数据集上均取得比基线系统更好的性能。First-Sent方法总体性能和TopWords方法相当,验证了事件扩展可以有效地找回丢失信息。由于新闻报道中大多在篇章开始处直接呈现主题,主流的标题生成方法均将第一条语句作为候选标题。但英文数据集上的实验结果表明数据集中约30%的标题并不是直接来源于首句。如表1中示例的标题来源于语句S3。因此,标题生成任务更应该被视为篇章分析任务。如图2所示,MutualR方法总体效果均高于GraphR,由此可见基于互增强的排序方法优于传统方法。其主要原因在于GraphR简单地考虑了结点权重,而忽略了词和事件间的相互关系。此外,基于主旨事件的扩展既能抓住重要信息,也能在一定程度上保障标题的语法。
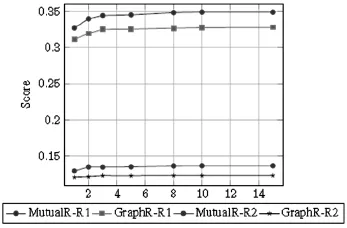
图2 GraphR和MutualR在英文数据上的性能比较
3 分析和讨论
实验结果证明了方法的有效性。从事件图中习得的主旨事件能抓住篇章主旨。表3呈现了中英文语料上的一些生成结果。
从第一个示例可以看出参考标题和机器生成标题从语义上是大体相似且与篇章语义紧密相关的,然而,评估得分却因为缺乏共同词汇而并不理想。显然,采用能从语义推理进行标题生成评估的方法更符合实际。观察第二个示例可见,参考标题中并没有特定的事件,此时本文的方法仅能通过事件论元来提升信息度得分。统计结果表明,极端情况下评估得分为零。此类现象在中文中出现较多。因为中文依存分析性能的影响,特别是指代消解等问题,事件抽取结果存在一些论元丢失或错误的情况。故在中文标题生成领域仍有许多工作需要开展。

表3 中英文语料上不同方法的标题生成结果示例
为进一步评估基于图的排序方法的性能,也进行了事件显著性学习比较的实验。候选事件的个数I分别从1变化到15。图3给出了实验的结果。显然,候选越多,得分应趋近于一个极值。当I等于 15时,Rouge得分分别达到 0.4717和0.2404。近似地,互增强模型中,91%的主旨事件出现在前5位,98%的事件出现在前10位,因而这种基于事件图的方法仍有很大的上升空间。
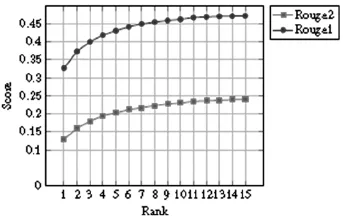
图3 不同候选个数下英文数据集的性能比较
4 相关工作
新闻标题生成的方法大体分为两类:抽取式和生成式。抽取式方法采用自顶向下的策略,在重要语句上实施语句压缩技术以达到标题长度的要求。Dorr等[4]利用语言学的策略,提出了Hedge算法。Zajic等[5]则在Hedge算法的基础上利用无监督的主题发现方法组合了文档的一个或多个主题词。这些方法不需要过多的语言分析,一些重要的语法成分可能被错误的删除掉。
生成式方法通常分为两个阶段:内容选择和标题合成。首先识别出能反映篇章主题的候选词或短语,然后再利用语句合成技术将这些候选成果组合成一条满足语法规则且连贯的标题。Woodsend等[6]基于伪同步语法提出了一种联合模型。该模型中使用整数线性规则以优化内容选择和语句生成。受自然语言生成技术的影响,基于短语和词的合成仍无法确保语句的可读性。Alfonseca等[7]首先基于现有知识库Freebase生成事件模板,再利用“噪声或”模型为一组相类新闻文档集合生成标题。受该工作的启发,本文从事件的角度出发为单篇新闻生成标题。显著性事件组合了一些显著性词汇或短语,并且事件的扩展基于依存关系进行,因而能为标题生成提供一定的性能保障。
5 结论
本文基于事件图来学习篇章主旨事件,并在事件的基础上,设计了优化函数以生成最终的标题。该方法无需标注数据和背景知识,是一个轻量级的生成方法。实验结果表明该方法是有效且有潜力的。然而,在某些情况下,单个事件仍不足以表达篇章主题,尤其是在中文领域。因此,基于事件的融合是未来需要深入研究的目标。
[1]ARNOLD H.Buss.Modeling with event graphs[C].Proceedings of the 1996 Winter Sirnulation Conference,1996:153-160.
[2]LIN Chin-Yew.Rouge:A package for automaticevaluation of summaries[C].Text SummarizationBranckes Out:Proceedings of the ACL-04 Workshop,2004:74-81.
[3]SORICUT R.MARCU D.Abstractive headlinegeneration using WIDL-expressions[J].Information Processing and Management,2007:43(6),1536-1548.
[4]DORR B,ZAJIC D,SCHWARTZ R.Hedge trimmer:A parse-and-trim approachto headline generation[C].Proceedings of the HLT-NAACL 03 on Text summarization workshop,2003,5:1-8.
[5]ZAJIC D,DORR B,SCHWARTZ R.Headline generation for written and broadcast news[R].lamp-tr-120,cs-tr-4698,2005.
[6]WOODSEND K,FENG Y S,LAPATA M.Title generation with quasi-synchronousgrammar[C].Proceedings of the 2010 Conferenceon Empirical Methods in Natural Language Processing,2010:513-523.
[7]ALFONSECA E,PIGHIN D,GARRIDO G.HEADY:News headline abstractionthrough event pattern clustering[C].Proceedings ofthe 51st Annual Meeting of the Association for ComputationalLinguistics,2013:1243-1253.
Research on News Headline Generation Based on Event Graph
SUN Rui
(School of Computer Sciences,Leshan Normal University,Leshan Sichuan 614000,China)
Automatically generating news headline is a challenging task.This paper proposes an effective unsupervised method for this task based on event graph.Given a news report,firstly,a discourse event graph is constructed for it,and then graph ranking algorithms are used to compute the salient score for each event.Then,the dependency fragment in the text as the candidate title is extracted,and a target optimization function is designed to search the final headline.Experimental results on English and Chinese datasets demonstrate that the proposed method can effectively learn the salient events based on the discourse event graph and generate headlines.
Event Extraction;Mutual Reinforcement Principle;Headline Generation
TP391
A
1009-8666(2017)04-0042-05
10.16069/j.cnki.51-1610/g4.2017.04.009
[责任编辑、校对:王兴全]
2017-01-16
孙锐(1977—),男,四川眉山人。乐山师范学院计算机科学学院讲师,博士,研究方向:自然语言处理。
猜你喜欢
通信技术(2021年12期)2022-01-25
新世纪智能(语文备考)(2020年4期)2020-07-25
海峡姐妹(2019年6期)2019-06-26
新世纪智能(语文备考)(2018年9期)2018-11-08
语文知识(2015年7期)2015-02-28
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
小雪花·初中高分作文(2009年8期)2009-11-16
小雪花·初中高分作文(2009年7期)2009-11-16
