
基于标签与评分个性化课程推荐算法
2017-06-05 09:07古奋飞
长春工业大学学报 2017年2期
古奋飞
(安徽新华学院 信息工程学院, 安徽 合肥 230088)
基于标签与评分个性化课程推荐算法
古奋飞
(安徽新华学院 信息工程学院, 安徽 合肥 230088)
首先根据课程的标签对课程进行聚类,找到相似度高的课程;其次根据学生对课程的已有评价和课程的聚类结果对未选课程进行评分预测,构建无缺失的课程评价矩阵,在此基础上再次对课程进行相似度计算,找到相似度较高的K项向目标用户进行推荐。通过实验验证,本算法与基于标签协同过滤算法以及基于评分推荐算法相比,具有更准确的推荐效果。
标签; 评分; 课程推荐; 聚类
0 引 言
随着Web2.0不断发展,个性化推荐不仅在电子商务、社交等领域应用广泛,而且在个性化学习领域中也有一定的应用[1]。目前,在很多领域中的推荐系统均是根据用户的历史行为和商品的各自属性,并利用互联网技术向目标用户推荐感兴趣的信息。随着互联网的不断发展,教育行业也发生了巨大转变,由传统的教学方式转变成“互联网+”时代,出现了Coursera、Mooc等开放式教学平台。为了更好地开展高校教育改革,教师学生可以充分利用网络资源和各种学习平台,方便高效地进行教学。因此,如何根据用户的学习能力、知识结构等合理地推荐适合用户的课程是目前的研究热点。文中提出基于标签聚类和课程评分对用户进行个性化课程推荐。
1 推荐算法
目前在个性化推荐方面主要有基于项目、基于用户、基于协同过滤以及一些混合推荐方法,这些推荐方法在电商、社交等平台应用较为成熟,同时也适合个性化学习的领域。
1.1 传统的推荐算法
从推荐系统的发展历程来看,传统的推荐算法有基于关联规则的推荐算法、基于人口统计学的推荐算法以及基于内容的推荐算法[2]。基于关联规则的推荐算法主要的例子就是“啤酒-尿不湿”的经典事例。这是根据用户在购买尿不湿的同时,总是购买啤酒等商品。根据关联规则的相关算法,得出这两个商品是有关联的。当然这种关联规则是通过大量数据进行处理得到的。基于人口统计学的推荐机制[20]是一种简单实用的推荐算法,也即为基于用户的推荐算法。其主要思想是根据用户的基本属性,包括年龄、性别、兴趣爱好等计算用户之间的相似度,然后将相似度高的推荐给目标用户,在社交平台中主要采用此类算法。基于内容的推荐算法是出现最早的推荐系统[3],也即为基于项目的推荐算法。随着网络信息“爆炸式”增长,很多系统中的物品信息要比用户信息多得多,从而提出了基于项目的推荐算法,其思想是通过未被选的项目与已被选的项目之间的相似度进行推荐,此类算法比较适用于电商行业。通过以上传统的推荐算法表明,个性化推荐系统给人类的生活、学习以及工作带来了巨大变革。那么在高校的教育中也同样需要个性化推荐技术,特别随着“信息爆炸”时代的诞生,学生如何有针对性地根据个人的兴趣特点、学习基础、学习能力等特性,方便快捷地得到自己想学习的课程,从而大大减小学生学习的盲目性,提高学习效率尤为重要。文中主要根据传统推荐算法的启发,设计一个适用课程推荐的推荐算法。
以上介绍的传统推荐算法在实际应用中虽然都起到良好的推荐效果,但是随着大数据的产生,这些推荐算法很难实现个性化推荐。
1.2 协同过滤推荐算法
传统的推荐算法只是单纯地根据用户或项目的相似度来进行推荐,具体是根据用户的特征和项目特征的相似度来进行推荐的。随着互联网的不断发展,为了让用户在海量数据中得到想要的数据,Web更加注重用户的历史行为和用户评分,因此协同过滤的推荐得到广泛应用。协同过滤算法是利用用户的历史行为来判断用户或项目的相似性,从而将一个用户喜欢的而好友用户并没有关注的项目推荐给好友。协同过滤算法主要包括基于用户和基于项目两种。
1.2.1 基于用户的协同过滤算法
基于用户的协同过滤推荐算法是分析用户对项目的历史行为或评分,通过相应的相似度计算公式计算用户之间的相似性,从而形成相似用户的“邻居”集。根据该“邻居”用户进行推荐。
基于用户的协同过滤推荐又称为最近邻(Nearest-Neighbor)协同过滤推荐或者K最近邻法(K-Nearest-Neighbor, KNN)[4],具体算法步骤如下:
步骤1:数据初始化。数据初始化主要是将用户对项目评分数据进行初始化。构建用户与项目的关系矩阵,即为评分矩阵,同时去除冗余项目。用户评分项目见表1。

表1 用户评分项目表
步骤2:最近邻居集的形成。根据上述关系矩阵来计算用户之间的相似度。根据相似度值的大小排序形成目标用户的最近“邻居”集。用户相似度计算最常见的方法有3种:余弦相似性、相关相似性和约束Pearson相关系数[5]。此外,还有很多基于此3种算法的改进计算方法。
1)余弦相似性(Cosine Similarity)。余弦相似性是根据向量来进行计算的,其实每个用户对所有项目的评分可以被看做是该用户的一个n维向量R(R11,R12,…,R1v),没有评分的项目默认其评分值为零,通过两个用户的向量之间余弦夹角来计算某两个用户的相似度。其值越接近1,说明这两个用户的相似度越高。具体公式如下:
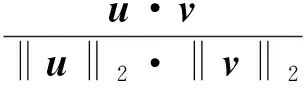
式中:Iu,v----用户u,v共同评分的项目集合;
Ru,i,Rv,i----分别表示用户u,v对于项目i的评分;
Iu,Iv----分别表示用户u,v所评分的项目。
2)相关相似性(Correlation Similarity)。相关相似性也称Pearson系数相关性,根据以上用户-项目的关系矩阵,可以利用Pearson系数相关性来计算某两个用户的相似性。根据Pearson系数的相关定义,某两个用户之间相似性的具体公式如下:
式中: Iu,v----用户u、v的共同评分项目集合;
Ru,i,Rv,i----用户u、v对于项目i的评分;
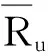
3)约束Pearson相关系数。用户u、v之间的约束Pearson相关系数是在相关相似性基础上改进所得,其定义为:
式中:Rmed----系统评分区间的中值,不同系统的Rmed值是不相同的,取值为1~5。
步骤3:预测评分及产生推荐结果。通过相似度的高低可以获得目标用户u的“邻居”集,即为N(u)={u1,u2,…,uk}。然后根据其“邻居”集中的用户对项目进行预测评分,将评分高的项目推荐给目标用户[24]。评分预测计算公式如下:
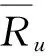
(4)
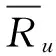
1.2.2 基于项目的协同过滤算法
基于项目的协同过滤推荐[6]与基于用户的协同过滤推荐具有一定相似性。它主要是根据用户对项目的偏好及评分,通过项目的相似性来进行推荐[7]。
基于项目的协同过滤推荐算法的实现过程也分为3个步骤:数据初始化,最近邻居集的形成,预测评分及产生推荐结果。具体步骤如下:
步骤1:数据初始化。数据初始化与基于用户的协同过滤推荐算法一样,主要是根据用户-项目的评分情况形成一个n维的向量矩阵。其实该矩阵是个n*m的矩阵,具体如下:
步骤2:最近“邻居”集的形成。最近邻居集的形成主要是通过项目之间的相似性计算得到的。具体方法也可以采用余弦相似性、Pearson系数相关性等方法。
1)余弦相似性。基于项目的协同过滤算法是将每个项目评分看作n维用户空间上的向量,项目间的相似性是通过两个向量间夹角的余弦值进行计算的。设对项目i和j都有评分的用户集合为Ui,j,向量i、j分别表示项目i和j在用户集合Ui,j上的评分,则项目i和项目j之间的余弦相似性为:
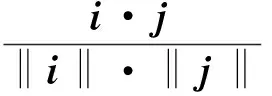
2)修正的余弦相似性。直接用预先公式计算项目间的相似性方法忽略了用户评分尺度不一致的因素,可以通过减去相应用户对所有已评分项目的评分均值的方法解决,这种方法称为修正的余弦相似性。
式
中:Ru,i,Ru,j----分别表示用户u对于项目i、j的评分;

3)Pearson系数相关性。项目i和项目j之间的相似性也可以通过Pearson相关系数进行计算,具体公式如下:
式中:Ru,i、 Ru,j----分别表示用户u对于项目i、j 的评分;
步骤3:预测评分及产生推荐结果。由步骤2得到目标项目i的最近邻居集N(i)={i1,i2,… ,ik}之后,就可以通过最近邻居集预测目标用户对于目标项目的评分,最终根据预测结果将评分得分高的项目推荐给目标用户[8],评分预测公式如下
2 基于标签与评价的课程推荐算法
为提高高校学生的学习兴趣和学习质量,并更好地让学生适应社会需求,改变高校传统的由学校为学生定制的课程体系,文中提出基于标签与评分相结合的方法,给学生推荐其感兴趣、符合度高的课程,进而提高学习效果。
2.1 基于标签聚类
标签是目前推荐系统中广泛使用的技术,尤其在电子商务、社交等平台具有很好的推荐效果。文中主要将其应用到课程推荐之中,每一门课程在发布时都设置好标签,课程标签的规定应根据课程和用户学习的特征进行设置。包括课程专业度、适合人群、难易程度等具体属性。
由于在实际教学中课程数量太多,而对于每一个用户来说,选择课程的数量是有限的,因此,构成学生和课程矩阵是非常稀疏的,进而单一根据标签属性实现推荐效果肯定不佳。文中首先根据课程的标签对课程进行聚类。具体如下:
1)构建课程与课程标签的矩阵,见表2。
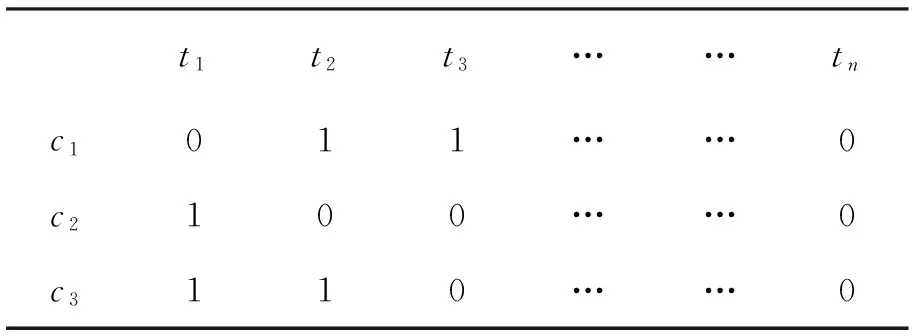
表2 课程-标签矩阵
2)所有课程表示为Cn,即Cn(c1,c2,c3,…,cn),根据上述矩阵关系计算课程之间的相似度,对课程进行聚类。课程的聚类结果可以表示为CI(I=1,2,…)。

上述推荐方法其实属于基于标签的协同过滤算法,利用该思想可以实现在一个聚类中的课程被推荐,同时也考虑其它聚类中与目标课程相似度最高的几门课程也可以被推荐。
2.2 基于用户评分
很多课程类网站是利用用户的学习数量和课程的评分来体现用户的兴趣,评分一般在[0~10]之间,根据这两个因素,文中将这两项进行综合计算课程评分,分值越高,说明该课程的受众面和课程质量非常不错。具体公式如下
式中:Su,i----用户对课程i的选择数量;
Ru,i----用户对课程i的评分。
通过式(9)可以计算课程i的综合评分Scorei。
2.3 基于标签和评分的课程推荐算法
根据2.1和2.2分析描述,文中将以上两种思想进行了结合,通过标签思想对课程进行聚类,然后通过用户对课程的综合评分可以实现每个聚类中相似度较高且评分较高的课程作为推荐对象,从而让推荐效果既符合专业度,又符合学生兴趣度。具体思路如下:
1)构建用户与课程的评分矩阵。
2)为了解决稀疏矩阵的问题,文中将根据课程所属的聚类类别以及综合评分对未评分的课程进行评分预测,从而解决该矩阵的稀疏性,其公式如下:
3)通过预测评价,所有课程都有了预测评分,此时再一次计算课程之间相似度,公式如下:
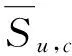
3 算法实验及分析
3.1 数据
提出了基于标签和评分的混合型的算法思想,为了验证算法的推荐准确度,选取了某高校2014届和2015届学生在本科就读期间的所有选课记录数据,共1 980人,课程数量为200,按照学校培养目标要求,每个学生至少要选40门课程,每个学生在学习完成之后,要有所评价。针对这些实验数据,将其分为训练集和测试集两部分,其中训练集占90%,测试集占10%。
3.2 实验步骤
1)根据以上数据记录进行数据预处理,消除一些标签过少的数据和冗余数据,通过课程与课程所列标签构建课程与标签矩阵R。
2)结合R矩阵,根据课程的标签计算课程之间的相似度,表示为sim(i,j),根据相似度对课程进行聚类,总结出相似度较高的课程,分别形成相应的课程集合CI。
3)构建用户与课程的评价关系矩阵,根据聚类结果将相似的课程放置相邻列,这样根据相似课程使学生对没有评价的课程进行评价预测,方便操作。
4)根据式(11)对没有被评价的课程进行评价预测。
5)结合聚类和预测后的矩阵,再次计算课程的相似度,选出评价较高K项作为目标用户的TOP-N推荐集。
3.3 结果分析
为了进一步验证预测评价的误差,文中采用广泛使用的平均误差(Mean Absolute Error, MAE)的评价标准进行衡量,MAE值越小,推荐的质量就越高。MAE计算公式如下:

Ru,i----实际评价。
通过实验改变最近邻K的数值,MAE的变化情况如图1所示。
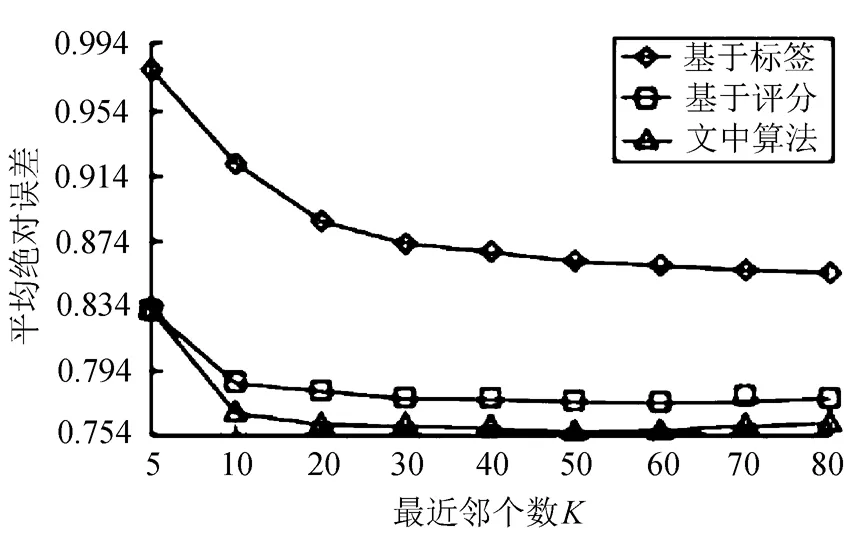
图1 平均绝对误差与最近邻个数K的关系
从图1可以看出,随着K的数目的增加,MAE的值越来越小,因此本算法得到的推荐质量是最高的。
4 结 语
提出了基于标签与评价相结合的方法在课程推荐中的研究,其效果明显较单独使用基于标签的协同过滤算法和基于评价的推荐方法在推荐准确度方面有明显提升。本算法首先采用了标签的特点对课程进行聚类,其目的可以辅助对未被预测的课程进行评价预测,同时,可以进一步利用预测的评价对矩阵的稀疏性进行改善,进而在计算课程相似度时更加准确,提高了推荐的准确度。实验证明,文中算法可以有针对性地为用户推荐合适的课程,提高用户的学习兴趣和学习质量。
[1] 汪静,印鉴,郑利荣,等.基于共同评分和相似性权重的协同过滤推荐算法[J].计算机科学,2010(2):99-104.
[2] 张亮.推荐系统中协同过滤算法若干问题的研究[D].北京:北京邮电大学,2009.
[3] 陆洲.基于标签的个性化推荐系统研究[D].长沙:湖南大学,2010.
[4] Piao C H, Zhao J, Zheng L J. Research on entropy-based collaborative filtering algorithm and personalized recommendation in e-commerce [J]. Service Oriented Computing and Applications,2009,3(2):147-157.
[5] 文俊浩,舒珊.一种改进相似性度量的协同过滤推荐算法[J].计算机科学,2014,41(5):68-71.
[6] Weng J, Lim E P, Jiang J, et al. Twitterrank: finding topic-sensitive influential twitterers[C]//Proceedings of the Third ACM International Conference on Web Search and Data Mining. [S.l.]: ACM,2010:261-270.
Personalized curriculum recommendation algorithm based on tags and ratings
GU Fenfei
(College of Information Engineering, Anhui Xinhua University, Hefei 230088, China)
Cluster analysis is carried out according to the tags of the curriculum to find the high similarity of courses. Then rating prediction for a course is completed based on the previous evaluation and cluster analysis, and the intact curriculum evaluation matrix is established. Again, similarity of the courses is calculated to findKitems for recommendation to the target users. Experiments indicate that the algorithm is more accurate for recommendation than those based on tags or rating.
tag; rating; course recommendation; cluster.
2017-02-25
安徽省重点研究项目(kj2016A303); 安徽新华学院自然科学研究项目(2015zr008); 安徽新华学院质量工程项目(2015sysxs01)
古奋飞(1982-),男,汉族,安徽无为人,安徽新华学院讲师,硕士,主要从事无线传感器网络、隐私保护、机器学习方向研究,E-mail:13966756031@126.com.
10.15923/j.cnki.cn22-1382/t.2017.2.18
TP 391
A
1674-1374(2017)02-0198-06
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年2期)2016-06-05
公民与法治(2016年10期)2016-05-17
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
