
基于Hadoop分布式支持向量机球磨机大数据建模
2017-06-05 09:34高学伟付忠广孙力张刚沈阳工程学院仿真中心辽宁沈阳036华北电力大学电站设备状态监测与控制教育部重点实验室北京006
河北大学学报(自然科学版) 2017年3期
高学伟,付忠广,孙力,张刚(.沈阳工程学院 仿真中心,辽宁 沈阳 036;.华北电力大学 电站设备状态监测与控制教育部重点实验室,北京 006)
基于Hadoop分布式支持向量机球磨机大数据建模
高学伟1,2,付忠广2,孙力1,张刚1
(1.沈阳工程学院 仿真中心,辽宁 沈阳 110136;2.华北电力大学 电站设备状态监测与控制教育部重点实验室,北京 102206)
大数据时代环境下,火电厂大量数据被存储到数据库中而不能被充分利用,由于双进双出钢球磨煤机系统的复杂性,很难建立其准确的机理数学模型,为此提出一种基于大数据挖掘的建模方法.首先分析影响磨煤机料位的因素,提取现场海量的实际运行数据,在Hadoop平台下利用K-Means聚类算法删除离群点,利用主成分分析法(PCA)降维完成属性约简,然后在MapReduce架构上采用分布式支持向量机(D_SVM)建立模型,实现计算并行化.结果表明,采取该方法提高了建模效率,所建立的模型具有很高的精确度,且具有很好的泛化能力,该模型可以用于表征实际料位的特性.
双进双出磨煤机;Hadoop平台;分布式支持向量机;K-Means聚类;主成分分析
磨煤机是火电厂的主要辅机耗电设备,其料位很难直接测量,双进双出钢球磨煤机系统内部过程复杂,是一个强非线性,有时滞和不确定性的系统.当前火力发电厂热力系统的建模方法主要有机理建模和实验建模2种,而双进双出钢球磨煤机很难用比较全面地反应各参数间内在关系的准确机理模型来解释.文献[1]利用BP人工神经网络作为数据挖掘工具,对双进双出球磨机的煤粉磨制过程进行数据挖掘建模,并得到设备实际运行状态的验证,但其建模精度并不高.文献[2-4]通过提取现场数据针对于普通球磨机和中速磨煤机及其制粉系统的建模研究,文献[5]与文献[6]利用现场实验数据,采用改进后的最小二乘支持向量机算法建立双进双出钢球磨煤机直吹式制粉出力的软测量模型.文献[7-9]利用BP人工神经网络建立了磨煤机功率和出力的数学模型,对双进双出磨煤机的工作参数进行了计算,取得较好精度.文献[10]在建立双进双出磨煤机机理模型的基础上建立了神经网络模型,并求得混合模型,利用粒子群算法优化神经网络权值从而提高模型的精确度.
大数据时代环境下,火电厂装配着庞大的DCS、SIS等系统,机组的大量实际运行数据以及热力设备状态参数被存储到实时数据库及历史数据库中.这些海量数据蕴涵了丰富的、有价值的知识和规律,可以用于火电厂决策管理、指导操作人员优化运行、故障诊断以及过程控制等方面[11],但这些知识和规律现在并没有被充分的利用,造成了数据资源的巨大浪费.
针对机理建模和实验建模过程中存在的问题,海量的运行数据不能充分利用,所以利用大数据技术,通过采集历史运行数据库中的数据,建立燃煤发电厂主要热力设备或控制过程的数学模型,成为该专业领域研究的一个新的方向[12].本文采取大数据建模方法,从燃煤发电厂海量实际运行数据中提取信息,与Hadoop平台的Mapreduce架构相结合,在云计算的环境下建立双进双出钢球磨煤机动态数学模型,该模型的成功建立为下一步磨煤机料位的精确控制以及制粉系统的优化运行打下良好的基础.
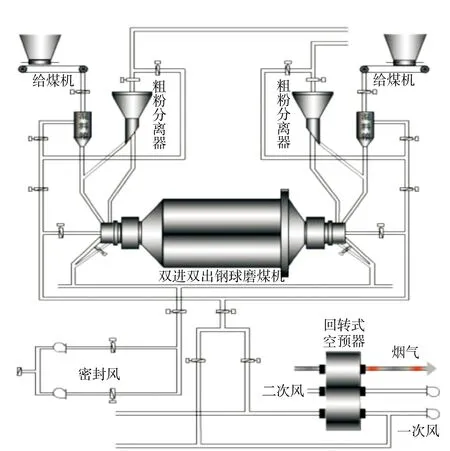
图1 双进双出磨煤机制粉系统示意Fig.1 Schematic diagram of double inlet and double outlet coal mill system
1 问题描述与特征提取
以某350MW机组BBD4360型双进双出钢球磨煤机为研究对象,其制粉系统如图1所示,原煤仓中的原煤通过两侧给煤机,经过混料箱进入磨煤机筒体,在筒体内研磨成煤粉,煤粉经过一次风干燥并携带进入粗粉分离器,经分离后合格的煤粉直接进入锅炉炉膛燃烧,颗粒较大的煤粉经回粉管返回磨煤机重新研磨.料位直接反映磨煤机进出口煤量的平衡状态,是影响磨煤效率的关键因素,电厂运行人员主要通过调整给煤量以及入口一次热风和冷风量来实现制粉系统的控制,完全是根据个人的运行经验,很难达到制粉系统的精确控制.而影响料位的因素还有很多,通过分析运行过程中DCS画面主要监测和调整的参数,根据理论研究和运行经验选取磨煤机料位作为建模输出变量,选取磨煤机左右两侧的给煤量,入口一次风量及风压,磨煤机电流和出口温度,以及旁路一次风量等11个变量通过数据预处理作为模型的输入变量.从SIS系统数据库中提取20 974条记录,作为下一步数据挖掘建模的原始数据.
2 数据预处理
球磨机生产运行过程中的工作环境恶劣,原始运行数据库中易存在异常的数据,且各个参数间相互耦合,相互影响,具有强相关性,若将以上11个变量均作为模型的输入,将严重影响建模速度,所建立的SVM模型复杂,且容易出现过拟合问题.针对所采集的磨煤机原始数据,首先采用基于MapReduce框架的K-Means聚类算法进行聚类分析,采取欧氏距离作为距离函数,计算每个样本数据到聚类中心的距离,找出离群的样本数据点,达到删除异常值的目的.然后采用主成分分析法对数据进行规约降维,将降维后的数据作为下一步模型的输入,减少模型参数的同时,能够避免过拟合,降低模型复杂度.
2.1 K-Means聚类算法
数据预处理中的异常检测是用来发现不与其他的样本对象强相关的部分,而聚类分析是用来查找局部强相关的样本对象组,因此可以用聚类分析来进行离群数据点的检测[13].
K-Means聚类较好地局部性使它能很好地被并行化,Hadoop系统是一个分布式存储和并行计算系统,MapReduce框架通过有效管理和调度集群的节点来实现并行化程序的执行和数据处理[14],用MapReduce实现K-Means算法并行化主要分为3个阶段[15]:首先是生成簇过程的并行化,各个从节点分别读取分布存储在各自节点的数据集,生成簇集合,用若干簇集合生成第一次迭代的全局簇集合,重复这个过程直到满足结束条件;然后用之前得到的簇进行聚类操作,数据点在map阶段读出位于本地的数据集,输出每个点及其对应的簇;最后combiner 操作对位于本地包含在相同簇中的点进行 reduce 操作并输出,得到全局簇集合,按照最终的聚类中心划分数据.
由于数据量巨大且篇幅有限,本文仅以输入变量中的左侧给煤量为例,如图2所示为左侧给煤量的离群点检查示意图.
2.2 主成分分析
属性规约通过属性合并创建新属性维数,或者直接通过删除不相关的属性维数来减少数据维数,从而提高数据挖掘效率.主成分分析 (PCA,principal component analysis) 算法是将多个指标转化为几个少数综合指标,识别最重要的几个特征,可以降低数据的复杂性,适用于数值型数据的约简,是一种基于多元统计分析的特征提取和数据降维算法[16].其基本原理是在有一定相关关系的n维参数的m组数据样本点所构成的数据阵列的基础上,通过建立较小数目的综合变量,使其更集中地反映原来n维参数中所包含的变化信息,通过数据集的协方差矩阵及其特征值分析,可以求得主成分的值,通过将数据乘上最大的前N个值的特征向量转换到新的空间,从而达到属性规约的目的.
本文采用PCA算法对上述经过离散点检测后的数据再进行属性规约,达到数据降维的目的.经过 PCA降维后的运行结果如图3所示.
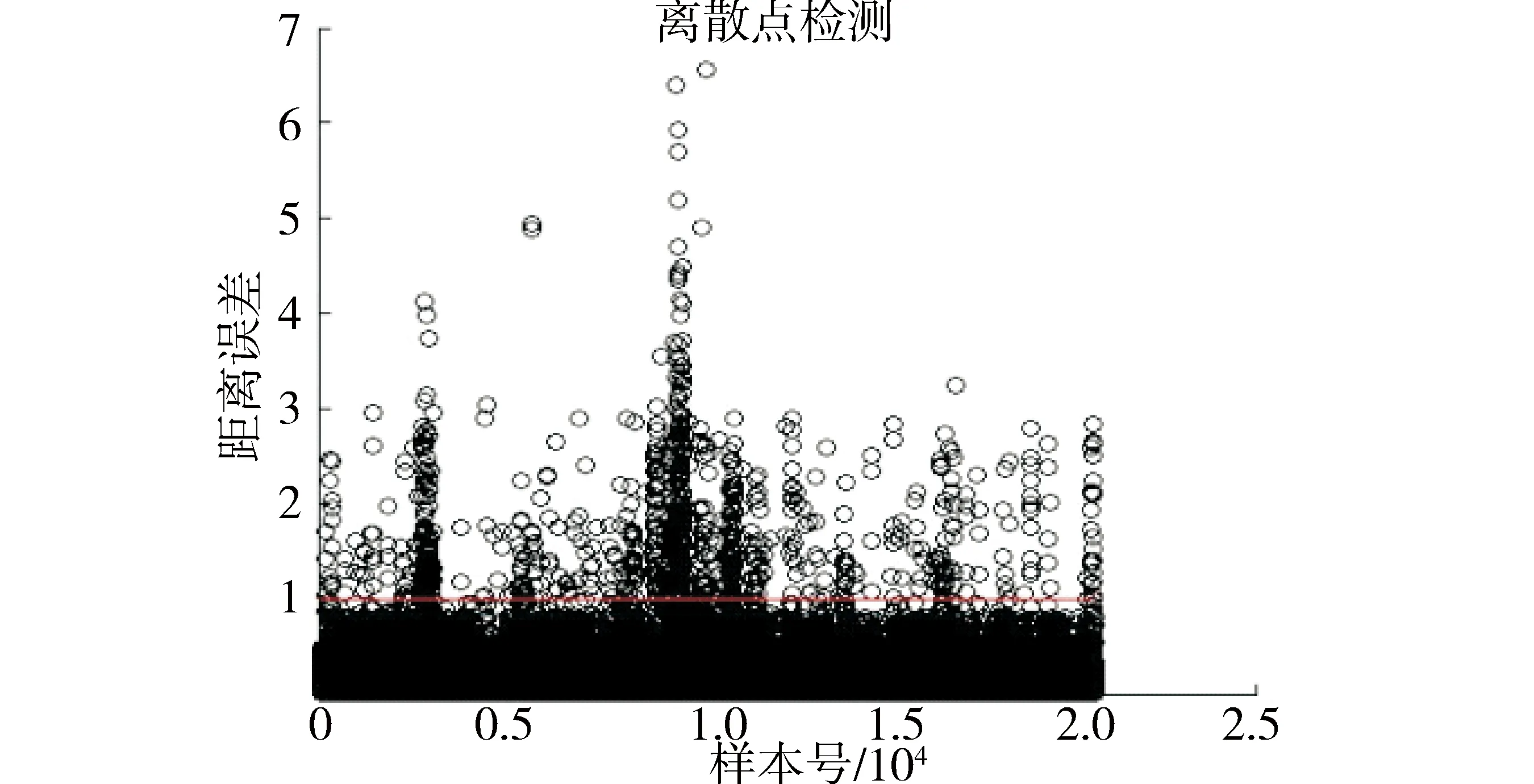
图2 基于K-Means聚类的离散点检测Fig.2 Discrete side inspection based on K-Means clustering
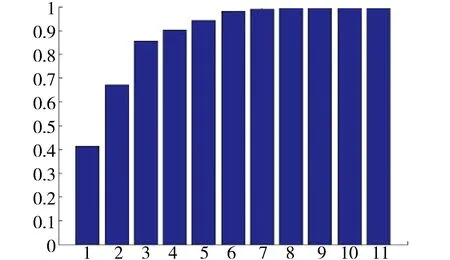
图3 主成分分析累积贡献率Fig.3 Cumulative contribution rate of PCA
从图3中分析结果可以看出,前4个主成分的累积贡献率达到90.24%,因此选取前4个主成分时,四维数据占了原始数据的90%以上的信息,而数据的维数却大大降低了.
上述离散点检测过程可以提高模型输入输出数据的质量,提高模型精度,属性规约过程可以降低数据维数从而缩减建模所需要的时间,使数据更好地满足下一步的建模过程.
3 分布式支持向量机(D_SVM)建模
面对海量数据进行大数据建模,传统的数据挖掘方法以及机器学习算法很难做到在可接受的运算时间内完成建模任务,而在Hadoop云计算平台上构建分布式支持向量机算法(D_SVM,Distributed support vector machine),该算法是基于MapReduce 分布式计算框架的,与传统SVM算法相比,其在处理大数据集上具有很高的加速比,且可扩展性较好,应用D_ SVM算法,可以高效的完成大数据的训练寻优建模任务[17-19].
基于Hadoop 云平台的D_SVM算法与传统单机 SVM 算法在训练时间上相比较,当训练样本较少时,D_SVM 算法的训练时间与单机 SVM 算法相比相差不太多,但是随着训练数据样本记录条数的增加,单机SVM 算法的训练时间呈现指数级的上升趋势,当训练数据集的样本数目相同的情况下,单机的 SVM 算法在训练时间上要远远高于基于Hadoop 云平台的D_SVM 算法,且随着训练样本数目的增多,时间增加越明显,对比效果如图4所示.
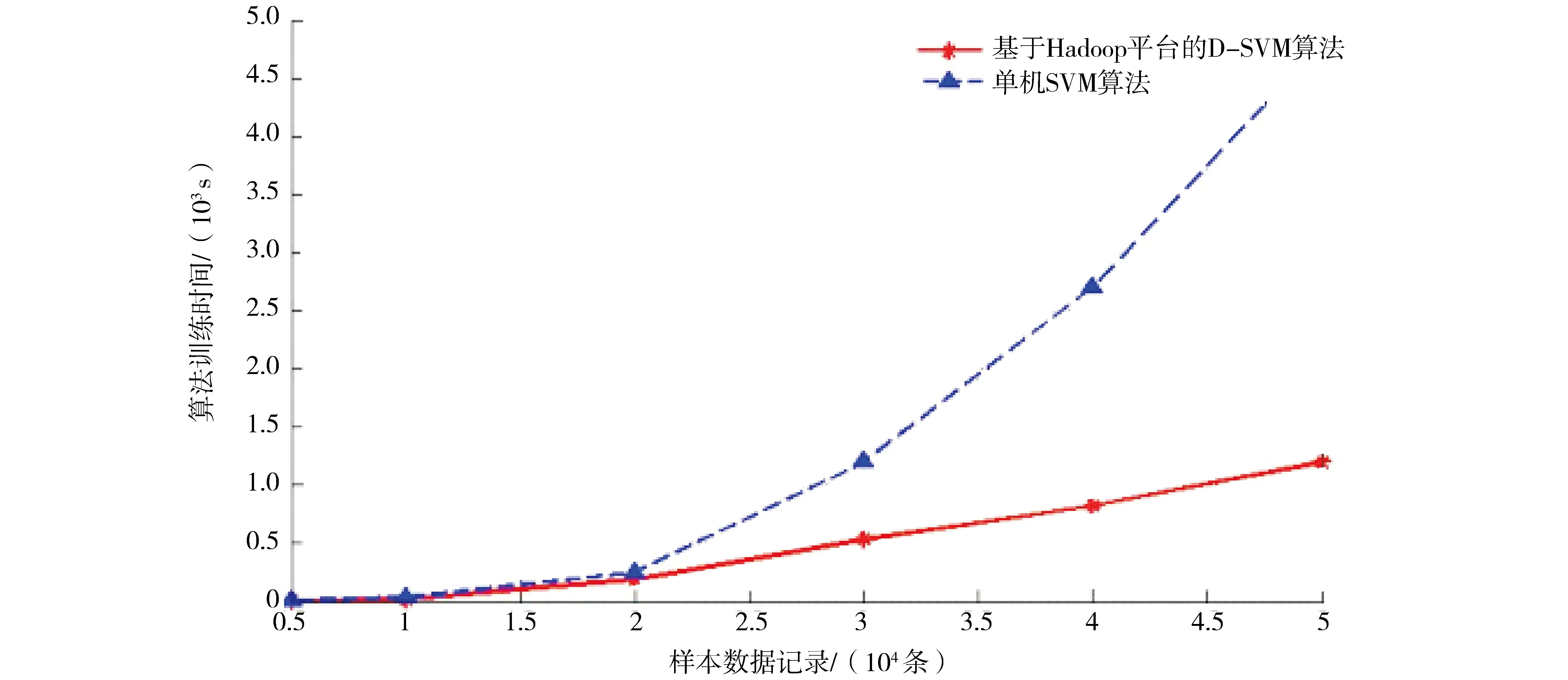
图4 单机SVM算法与基于Handoop平台的D_SVM算法训练时间对比Fig.4 Comparison of training time between single machine SVM algorithm and D_SVM algorithm on Hadoop platform
基于 Hadoop 云平台D_SVM 算法的实现过程如图5所示,其主要过程首先向Hadoop云平台提交作业,然后通过用户自定义的 map 函数和 reduce 函数实现来Map过程和 Reduce过程,最后输出结果[20].而用支持向量机回归实现模型的建立和评价,可分为以下4个步骤,如图6所示.
本文选择经过数据预处理之后19 186条数据记录,随机选取18 000条数据作为训练集,剩下的1 186条数据作为测试集对模型进行评价.由于各变量变化区间差异很大,建模前先对数据进行归一化,转化公式为
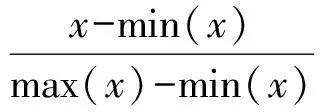
(1)
其中,x为输入数据原始值,x′为原始数据映射到[0,1]空间内的值,max(x)、min(x)分别为x在整个数据空间上的极大值和极小值.
支持向量机回归核函数类型的选择对模型的性能影响很大,本文选择RBF核函数,其表达式为
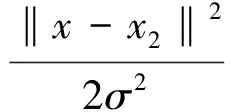
(2)
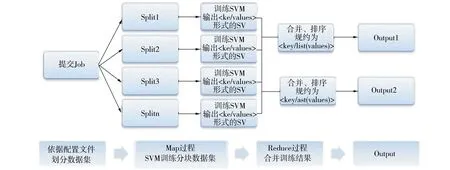
图5 基于Hadoop云平台的分布式SVM算法的Map和Reduce过程示意Fig.5 Schematic diagram of Map and Reduce process of distributed SVM algorithm based on Hadoop cloud platform

图6 支持向量机回归建模流程示意Fig.6 Schematic diagram of modeling process
支持向量机建立模型需要寻找最优的惩罚系数C和核函数参数g,本文利用网格搜索交叉验证方法进行寻优得到全局最优解.在寻优过程中C和g相互独立,便于进行并行化运算,所以可以利用MapReduce对模型进行训练.首先将所有的C和g写入文件中,每行一组参数上传到Hadoop云平台上,然后将训练集作为输入,所有的C和g参数对读入到list中,在Map阶段,把输入样本数据作为value,list中每组C和g参数对作为key输出,在Reduce阶段,Hadoop按照key排序,将key相同的数据放在同一机器上,把解析出来的参数以及整理好的数据进行训练,输出最优的C和g参数对,然后利用最优的C和g训练模型.本文输出的惩罚系数C为0.35,核函数参数g为4.73,所建立的预测模型的预测值和真实值对比如图7所示,然后利用测试集测试所建立的模型,测试结果如图8所示.从图7、8中可以看出训练集和测试集的均方误差MSE分别为0.007 5和0.008 9,这表明所建立的模型正确率很高,而决定系数R2分别为0.862和0.806,表明模型同样具有非常好的泛化能力.所以上述建模方法完全可以用于燃煤电厂球磨机动态模型的建立.
4 结论
给出一种大数据建模方法,利用燃煤电厂实际运行数据,通过数据挖掘方法,建立了制粉系统球磨机的动态数学模型.采用并行的K-Means聚类算法删除离散值,采用主成分分析法完成属性约减,保证了模型输入数据质量,从而提高了建立模型的效率和精度.采用基于Hadoop云计算平台的D_SVM算法对模型参数寻优过程进行并行化操作,可以大幅缩短建模过程中的训练时间.建立的最终模型正确率较高,泛化能力强,可以很好地反映磨煤机的动态运行特性,为下一步磨煤机精确控制以及制粉系统的优化运行打下了良好的基础,从而可以达到提高制粉系统出力以及磨煤机节能的目的.
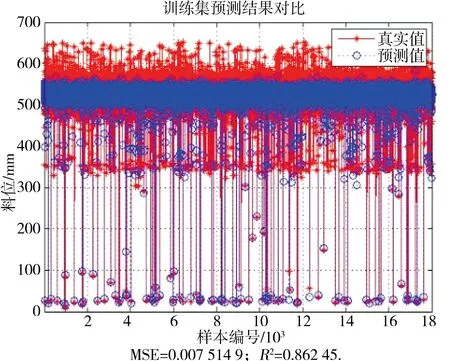
图7 训练集预测结果对比Fig.7 Comparison of training set prediction results
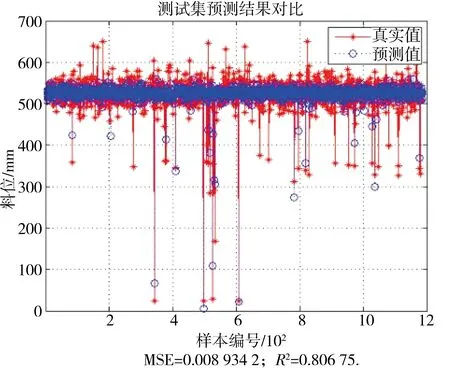
图8 测试集预测结果对比Fig.8 Comparison of test set prediction results
[1] 刘福国.基于数据挖掘的钢球磨煤机运行特性建模和优化[J].煤炭学报,2010,35(5):850-854.DOI:10.13225/j.cnki.jccs.2010.05.035. LIU F G.Performance modeling and optimization of ball mill based on data mining [J].Journal of China Coal Society,2010,35(5),850-854.DOI:10.13225/j.cnki.jccs.2010.05.035.
[2] 张小桃,倪维斗,李政,等.基于现场数据的中速磨煤机动态建模研究[J].热能动力工程,2004,19(6):614-616.DOI:10.3969/j.issn.1001-2060.2004.06.016. ZHANG X T,NI W D,LI Z,et al.A study of the dynamic modeling of a medium speed pulverizer based on on-site data[J].Journal of Engineering for Thermal Energy and Power,2004,19(6):614-616.DOI:10.3969/j.issn.1001-2060.2004.06.016.
[3] 刘定平,肖蔚然.应用最小二乘支持向量机和混合遗传算法的制粉系统优化控制[J].动力工程,2007,27(5),728-731.DOI:10.3321/j.issn:1000-6761.2007.05.016. LIU D P,XIAO W R.Optimizing control of pulverizing system based on least square supported vector machine and hybrid genetic algorithms [J].Journal of Power Engineering,2007,27(5):728-731.DOI:10.3321/j.issn:1000-6761.2007.05.016.
[4] 胡吉.火电厂中速磨煤机制粉系统仿真建模[D].武汉:华中科技大学,2005. HU J.Simulation and modeling of medium speed mill of coal pulverizing system in power plant [D].Wuhan:Huazhong University of Science and Technology,2005.
[5] 冯磊华.双进双出钢球磨煤机直吹式制粉系统建模及控制[D].长沙:中南大学,2012. FENG L H.Modeling and control of direct fired pulverized coal injection system with double inlet and double outlet ball mill[D].Changsha:Central South University,2012.
[6] 冯磊华,桂卫华,杨锋.改进LS-SVM的直吹式制粉出力软测量建模[J].电机与控制学报,2011,15(11):79-82.DOI:10.3969/j.issn.1007-449X.2011.11.014. FENG L H,GUI W H,YANG F.Soft sensor modeling for mill output of direct fired system based on improved least squares support vector machines [J].Electric Machines and Control,2011,15(11):79-82.DOI:10.3969/j.issn.1007-449X.2011.11.014.
[7] 姚树建.双进双出钢球磨煤机优化技术应用研究[D].长春:吉林大学,2005. YAO S J.The Study of the optimization technique application on the BBD Mill [D].Changchun:Jilin University,2005.
[8] 常绿,杨涛,姚树建,等.基于神经网络和遗传算法的磨煤机结构和工作参数的优化[J].热能动力工程,2007,22(1):69-72.DOI:10.3969/j.issn.1001-2060.2007.01.017. CHANG L,YANG T,YAO S J,et al.Optimization of structural and operating parameters of a ball mill based on a neural network and genetic algorithm[J].Journal of Engineering for Thermal Energy and Power,2007,22(1):69-72.DOI:10.3969/j.issn.1001-2060.2007.01.017.
[9] 张继东,唐国华,姚树建,等.基于神经网络算法计算双进双出磨煤机工作参数的研究[J].热力发电,2007,5:23-25.DOI:10.3969/j.issn.1002-3364.2007.05.006. ZHANG J D,TANG G H,YAO S J,et al.Study on calculation operating parameters of coal pulverize wish double inlet and double outlet based on neural network[J].Thermal Power Generation,2007,5:23-25.DOI:10.3969/j.issn.1002-3364.2007.05.006.
[10] 曹侠.基于神经网络的双进双出磨煤机混合模型研究[D].沈阳:沈阳工业大学,2008. CAO X.Study on hybrid model of BBD ball mill based on neural network [D].Shenyang:Shenyang University of Technology,2008.
[11] 万祥,胡念苏,韩鹏飞,等.大数据挖掘技术应用于汽轮机组运行性能优化的研究[J].中国电机工程学报,2016,36(2):459-467.DOI:10.13334/j.0258-8013.pcsee.2016.02.017. WAN X,HU N S,HAN P F,et al.Research on application of big data mining technology in performance optimization of steam turbines[J].Proceedings of the CSEE,2016,36(2):459-467.DOI:10.13334/j.0258-8013.pcsee.2016.02.017.
[12] 高学伟,付忠广.基于大数据分析的双进双出钢球磨煤机建模研究[J].煤炭技术,2016,35(12):267-270.DOI:10.13301/j.cnki.ct.2016.12.102. GAO X W,FU Z G.Research on modeling of double inlet and double outlet ball mill based on big data analysis[J].Coal Technology,2016,35(12):267-270.DOI:10.13301/j.cnki.ct.2016.12.102.
[13] 张良均,杨坦,肖钢,等.MATLAB数据分析与挖掘实战[M].北京:机械工业出版社,2015.
[14] 黄宜华,苗凯翔.深入理解大数据:大数据处理与编程实践[M].北京:机械工业出版社,2014.
[15] 张亚楠.基于Hadoop云计算平台的聚类算法并行化研究[D].包头:内蒙古科技大学,2013. ZHANG Y N.Research on parallel clustering algorithm based on hadoop cloud computing platform[D].Baotou:Inner Mongolia University of Science and Technology,2013.
[16] 齐敏芳,付忠广,景源,等.基于信息熵与主成分分析的火电机组综合评价方法[J].中国电机工程学报,2013,33(2):58-64. QI M F,FU Z G,JING Y,et al.A comprehensive evaluation method of power plant units based on information entropy and principal component analysis[J].Proceedings of the CSEE,2013,33(2):58-64.
[17] 雷学智.云计算平台下分布式支持向量机在煤炭行业分类预测应用[J].煤炭技术,2013,32(11):248-250.DOI:10.3969/j.issn.1008-8725.2013.11.130. LEI X Z.Application of distributed support vector machine based on cloud platform in coal system[J].Coal Technology,2013,32(11):248-250.DOI:10.3969/j.issn.1008-8725.2013.11.130.
[18] 牛科.基于Hadoop云平台的分布式支持向量机研究[D].太原:山西师范大学,2014. NIU K.Research of distributed support vector machine (SVM) based on Hadoop cloud platform[D].Taiyuan:Shanxi Normal University,2014.
[19] 崔文斌,温孚江,牟少敏,等.基于Hadoop的局部支持向量机[J].计算机研究与发展,2014,51 (S):116-121. CUI W B,WEN F J,MOU S M,et al.Local support vector machine based on handoop[J].Journal of Computer research and development,2014,51(S):116-121.
[20] 张奕武.基于Hadoop分布式平台的SVM算法优化及应用[D].中山:中山大学,2012. ZHANG Y W.Optimization and application of svm algorithm based on hadoop distributed platform [D].Zhongshan:Zhongshan University,2012.
(责任编辑:孟素兰)
Big data modeling of ball mill based on distributed support vector machine on Hadoop platform
GAO Xuewei1,2,FU Zhongguang2,SUN Li1,ZHANG Gang1
(1.Simulation Center,Shenyang Institute of Engineering,Shenyang 110136,China;
2.Key Laboratory of Condition Monitoring and Control for Power Plant Equipment of Ministry of Education,North China Electric Power University,Beijing 102206,China)
In the era of big data environment,a large amount of data in thermal power plant is stored in the database and cannot be fully utilized.Because of the complicated process of the double inlet and double outlet mill system,the mathematical model is difficult to build.A method of modeling based on data mining is presented.The actual operation big data which impact the coal mill material is extracted.First, theK-Means clustering is used to delete outliers,and then the principal component analysis(PCA) is used to complete attribute reduction,at last the distributed support vector machine(D_SVM) is used to build a model on the Hadoop platform in MapReduce framework for the parallel computation.The results show that modeling time is greatly reduced due to the use of the method,and the accuracy and applicability of the model are very high. Therefore the model can be used to represent the actual material properties.
double inlet and double outlet mill;Hadoop platform;D_SVM;K-Means clustering;principal component analysis
2016-04-05
沈阳工程学院科技基金资助项目(LGQN-1051);辽宁省教育厅创新团队项目(LT2015018)
高学伟(1982—),男,河北石家庄人,沈阳工程学院工程师,华北电力大学在读博士,主要从事电站机组运行优化与复杂热力系统建模仿真研究.E-mail:gxw82425@163.com
10.3969/j.issn.1000-1565.2017.03.014
TP399
A
1000-1565(2017)03-0309-07
猜你喜欢
今日自动化(2022年1期)2022-03-07
大众投资指南(2021年35期)2021-02-16
防爆电机(2020年4期)2020-12-14
中国交通信息化(2020年1期)2020-07-27
科技与创新(2018年6期)2018-03-30
现代面粉工业(2018年6期)2018-02-14
信息通信技术(2015年6期)2015-12-26
现代面粉工业(2015年3期)2015-02-23
中国粮油学报(2015年5期)2015-02-06
智能系统学报(2013年1期)2013-01-28
