
数据挖掘技术在高校成绩分析中的应用
2017-05-30 13:08:23周国福
宁波职业技术学院学报 2017年6期
周国福


摘 要: 数据挖掘技术已经成功地运用到商业中,但是它在高等教育行业中的应用还有待于进一步深入研究。数据挖掘技术是为了从数据中识别和提取新的和潜在的有价值的知识。以福建省高校为例,利用数据挖掘技术对高校学生成绩进行了分析并建立了数学模型。提出了一种基于数据挖掘技术的学生成绩分析算法,基于学生在课程中的历史表现对学生未来成绩进行预测。同时,利用本文方法对本校水电与建筑专业的部分学生成绩抽样进行分析。结果表明:执行早期的阶段评估是有效的,对影响学生成绩因素进行分析预测,从而能够对成绩不理想的学生采取必要的补救措施,以此提升学生的学习方法,从而提高教学效率。
关键词: 数据挖掘技术; 分类; 预测; 高校学生成绩分析
中图分类号: TP 391.1 文献标志码: A 文章编号: 1671-2153(2017)06-0090-04
0 引 言
数据挖掘可用于从大量数据中提取隐藏的有用信息,常用于预测知识的模式。对省高校学生成绩的分析能够预测学生的表现,通过定期收集学生成绩的数据和信息,并进行数据处理和分析,有利于保证省高校教学质量。在教育过程中应用数据挖掘技术可以满足每个参与者在教育过程中的具体需求:根据分析结果为学生推荐有助于改善学习的材料和课程;老师可以根据反馈意见因材施教;高校的行政人员根据分析结果进行课程设置的调整等。
1 研究方法
本研究数据是通过问卷调查的形式收集的,调查对象是水电与建筑专业的学生,统计关于计算机应用基础课程的相关数据,消除不完整的数据后,样本的数量是257份。将257份有效样本作为输入,每一个样本信息的序号、属性以及取值类型如表1所示。
课程中学生成绩的分布如图1所示。图1中,横坐标是学生分数,纵坐标是人数。将成绩按照式(1)的规则进行离散化,即
分数等级=A, 95≤分数B, 85≤分数<95C, 75≤分数<85D, 65≤分数<75E, 55≤分数<65F, 分数<60 。 (1)
将输出分为两类:第一类是优秀,即分数等级为A;第二类是一般,即分数等级为B,C,D,E以及F。这两类输出的比例如表2所示。
2 数据挖掘算法
数据挖掘技术中有许多不同的分类器,但是并不存在最好的分类器,因为它们在许多方面有所不同,例如:学习率,训练数据量,分类速度,鲁棒性等。本文应用C4.5[1]和朴素贝叶斯[2]这两种数据分析算法来产生分类模型。
2.1 朴素贝叶斯分类器(NBC)
假设向量x=(x1,x2,,x3,x4,x5,x6,x7,x8,x9,x10,x11,x12)是属性向量。其中:x1是代表性别属性;x2是代表家庭人数属性;x3是代表住所与学校的距离属性;x4代表高中类型属性;x5代表绩点属性;x6代表高考成绩属性;x7代表奖学金属性;x8是课程学习时间属性;x9代表复习材料属性;x10代表使用网络属性;x11成绩重要性属性以及x12代表收入属性。C1代表输出类别中的“优秀”;C2代表输出类别中的“一般”。根据贝叶斯定理[3],可以得到以下公式:
式中:p(C1|x)是指某样本属于C1的概率;p(C2|x)是指某样本属于C2的概率。观察式(2)和式(3),只有分子部分含有变量Ck,将p(x)看成常数,那么式(1)就等价于p(Ck,x1,x2,…,x9)。于是有:
假设向量x中的属性都是互相独立的,于是有:
根据式(3)可以得到朴素贝叶斯分类器,即
2.2 C4.5
C4.5是ID3[4]算法的升级版,C4.5生成的决策树可以用于分类,为此C4.5通常被称为统计分类器。C4.5的算法如表3所示。
3 结果及分析
为了更好地了解输入变量的重要性,通常会分析输入变量在学生成绩分析预测期间的影响,对模型的某些输入变量对输出变量的影响进行了分析。使用3个测试进行测试,用于评估输入变量:卡方检验[5]、信息增益测试和增益比检验。使用以下度量来监测每个测试的结果:属性(属性名称),优点(良好度量),优点开始(偏差,即品质偏差的度量),排序(属性占据的平均位置),排序和dev(偏差,偏差取属性位置)。不同的算法提供不同的结果,即每个算法以不同的方式考虑属性的相关性。将所有算法的平均值作为属性排序的最终结果。表4为数据属性的测试结果。
由表4可以看出,属性5(即绩点)对结果的影响最大,在四项测试中效果最好。属性6,属性9和属性8对结果也有较大的影响。对结果影响最小的分别是属性1,2和3。
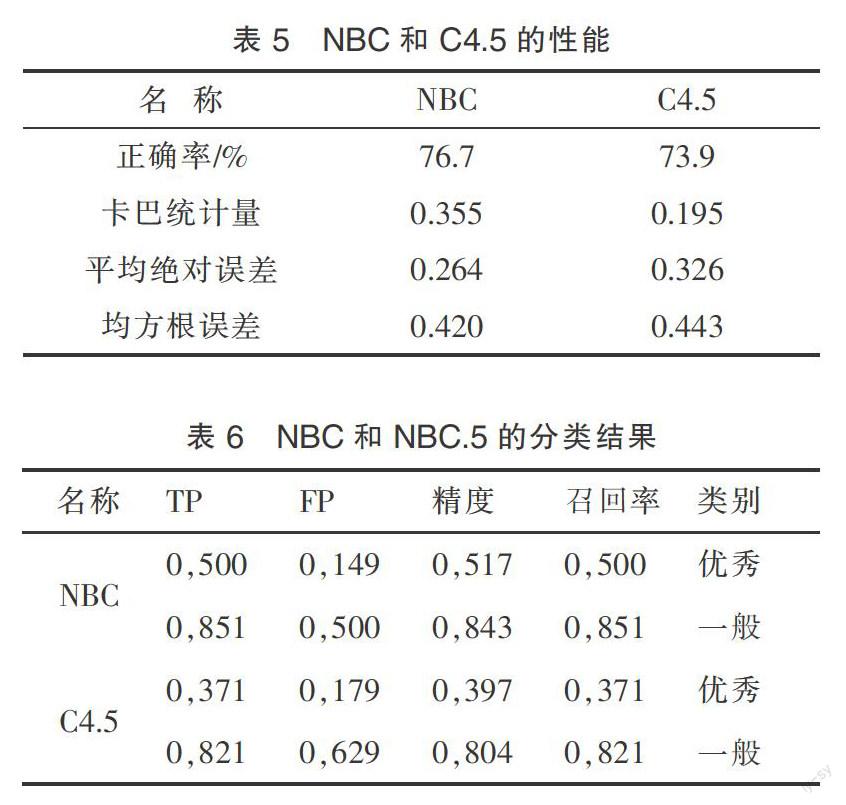
表5和表6为评估NBC算法和C4.5算法在预测学生成绩性能的结果。
由表5可以看出,NBC的正确率稍稍高于C4.5算法。NBC的卡巴统计量要远高于C4.5算法,说明了NBC的分类结果与随机分类的差异度较大,因此性能更好。同时,NBC的平均绝对误差、均方根误差小于C4.5算法,说明NBC的准确率比较高,分类的性能比较稳定。由表6可以看出,NBC的分类精度稍稍高于C4.5算法。
4 结 论
本文的目的是利用数据挖掘技术来进行省高校成绩分析模型的探讨,提出了一种基于数据挖掘技术的学生成绩分析算法,基于过去学生在课程中的历史表现的来对学生未来成绩进行预测。利用本文方法对本校水电与建筑专业的学生成绩进行分析研究,实验结果表明,朴素贝叶斯分类器表现突出。本研究基于传统的课堂环境,数据采集后应用数据挖掘技术。这种方法可以帮助老师提高学生的成绩,采取合适的措施来提高学习质量。由于学习是一个积极的过程,师生之间的交互是影响学生满意度和表现的一个基本要素。
参考文献:
[1] 黄秀霞. C4.5決策树算法优化及其应用[D]. 江南大学,2017.
[2] 王俊华,左万利,闫昭. 基于朴素贝叶斯模型的单词语义相似度度量[J]. 计算机研究与发展,2015,52(7):1499-1509.
[3] CICCHETTI D. Bayes' Theorem[M]//The Encyclopedia of Clinical Psychology. John Wiley & Sons,Inc,2015.
[4] 王永梅,胡学钢. 决策树中ID3算法的研究[J]. 安徽大学学报(自科版),2011(3):71-75.
[5] SHARPE D. Your Chi-Square Test Is Statistically Significant:Now What?[J]. Practical Assessment Research & Evaluation,2015,20:10.
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
科技创新导报(2016年23期)2016-12-23 16:08:16
中国科技纵横(2016年17期)2016-11-30 21:40:27
