
匹配GPU编程架构的直流故障筛选算法设计
2017-05-22 02:44:54温柏坚谢恩彦刘明波
电力自动化设备 2017年5期
温柏坚 ,谢恩彦 ,刘明波
(1.华南理工大学 电力学院,广东 广州 510640;2.广东电网有限责任公司电力调度控制中心,广东 广州 510600;3.国电南瑞科技股份有限公司,江苏 南京 211106)
0 引言
静态安全分析用来校验电网中输变电设备退出运行后的系统运行状态,一般要求满足N-1校验,完整的N-1校验需要对电网中所有N个设备进行开断和潮流分析,计算量巨大[1]。为了缩短分析时间,最常用的技术手段是采用多CPU核进行并行计算加速,中国电科院在4路×4核CPU配置的服务器上对10000节点电网只取得了不到4的加速比,远小于总核数16,这主要是由于内存带宽饱和(内存墙)问题。解决上述内存墙问题需要部署多个具有独立物理内存的计算节点,这将大幅增加系统费用、机房空间和计算功耗[2-3]。
2007年起,GPU逐渐被应用于通用科学计算,随着NVIDIA公司推出了统一编程架构CUDA(Compute Unified Device Architecture)和第3代专用计算卡,GPU已经成为最重要的高性能计算HPC(High Performance Computing)硬件之一[4]。和多核 CPU 相比,GPU的特点是浮点计算能力和内存带宽高,以NVIDIA K20型GPU和Intel Xeon E5-2690型CPU为例进行对比,GPU的单精度和双精度浮点计算峰值分别为CPU的18倍和6倍,GPU的内存带宽为CPU的4倍,但GPU的价格和功耗仅比CPU分别高10%和70%。
目前,GPU在石油勘探、大规模集成电路仿真、有限元分析等领域已实现了工程应用,电力系统中GPU的研究主要集中在暂态稳定分析和潮流计算2个领域,其中又特别聚焦于大规模稀疏线性方程组求解上。文献[5-13]对LU分解、共轭梯度迭代、多波前等经典求解方法进行了GPU加速研究,相对于各自开发的CPU串行算法取得了显著加速比,缺点是这种比较方法对CPU算法的性能比较敏感,更为客观的方法是同时给出绝对计算时间。CUDA官方手册指出GPU编程无法做到硬件透明,必须结合GPU软硬件特点进行充分优化才能发挥硬件能力,但已有的电力领域GPU算法文献鲜有结合GPU架构进行优化设计的[14]。
为了减少分析时间,实用化的静态安全分析程序都包括严重故障集筛选和只针对严重故障集进行的详细潮流分析2个步骤,一般而言,严重故障集筛选过程占整个静态安全分析时间的25%~30%,由此可见,加速故障集筛选过程是加速整个静态安全分析的重要环节,具有工程意义。本文首先介绍了基于直流潮流模型的故障筛选算法,然后对GPU的软硬件架构特点进行了详细剖析,基于此提出了GPU算法设计在任务分配、数据交互、线程分配、内存访问4个方面应遵循的通用设计准则,最后对GPU加速的故障筛选算法进行了详细设计和优化,提出了一种匹配GPU软硬件架构的并行直流故障筛选算法。
1 基于直流潮流模型的故障筛选算法
本节引入基于直流潮流模型的故障筛选算法,并对其进行工程优化。
1.1 算法模型
故障筛选关注功率越限,所以一般采用直流潮流模型来进行分析,相关公式主要包括[1]:

其中,B为去除平衡节点的节点电纳阵,X=B-1为节点电抗阵,B为稀疏阵,X则为稠密阵;P和θ分别为节点有功注入向量和电压相角向量,θ(i)为向量θ的第i个分量,文中所有向量都遵循同样的表达方式;下标i和j分别为支路的首、末节点编号;xij、Pij分别为支路电抗和支路有功。
设电网在基态断面下发生开断故障,可推导出式(2)的增量表达式为:

进一步可推导出:

其中,X0、θ0和P0分别为基态断面下的节点电抗阵、电压相角向量和节点有功向量;ΔX、Δθ和ΔP为开断故障后相关量的增量。
具体计算步骤为:预先求出特定电网的基态电抗阵X0,由于对特定电网只需计算1次,X0的计算时间不计入算法总时间;由支路追加法求出电抗增量阵ΔX,由负荷和发电机开断情况求出ΔP;将ΔX、ΔP代入式(5)求出电压相角增量Δθ,再代入式(4)求出θ;将θ代入式(3)计算支路功率,并检查是否越限。所述支路追加法的计算公式如下[1]:

其中,ei和 ej为标准正交基;X0(i,j)为电抗矩阵 X0的第i行、第j列元素;Δxij为追加支路的电抗,支路断开时追加负值电抗。
1.2 工程优化
式(4)—(6)是以矩阵形式表达的理论模型,工程上会对其进行优化来减少浮点计算量,具体可分成支路开断和发电机开断2类情况来讨论。
当首、末节点编号为i和j的支路发生开断时,只有电抗阵X0发生增量变化ΔX,节点有功增量ΔP=0,利用M的稀疏性,式(5)可以化简为:
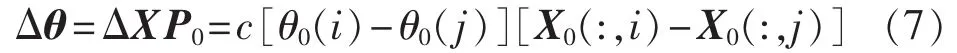
其中,X0(:,i)为由矩阵 X0的第i列构成的向量,其他类似。
当节点编号为i的发电机或负荷发生开断时,电抗增量阵ΔX=0,节点有功的增量变化ΔP=[0,…,ΔPi,…,0],ΔP中只有元素 ΔP(i)=ΔPi,其他元素都为0,再利用M的稀疏性,式(5)可以化简为:
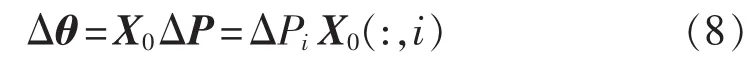
其中,ΔPi为发电机或负荷开断之后的有功跌落量。
综上所述,直流故障筛选算法已被化简为式(7)和式(8)所示的稠密向量计算,非常适合采用GPU来进行加速。
2 GPU算法设计的通用准则
本节对GPU的软硬件架构特点进行详细剖析,在此基础上提出GPU算法设计的通用设计准则,具体包括任务分配、数据交互、线程分配、内存访问4个方面。
2.1 CPU和GPU间的任务分配准则
2007年,NVIDIA公司发布了CUDA,将GPU视作一种CPU的通用协处理器,通过C语言编程即可调用GPU上的大量计算资源。
CPU和GPU拥有各自明显的优缺点,具体如下:CPU硬件的设计以延迟优化为目标,目的是尽快完成单位计算任务,片上资源被大量用于流水线和高速缓存,所以擅长处理复杂逻辑,缺点是片上浮点计算资源较少;GPU硬件的设计以吞吐优化为目标,目的是在单位时间内完成更多浮点计算,片上资源大量被用于浮点计算,所以优点是浮点计算峰值和带宽高,缺点是不擅长处理复杂逻辑。
按照两者的优缺点,确定CPU和GPU之间的任务分配准则如下:CPU负责控制程序的总体流程和执行不可并行的计算;GPU则专门负责可并行化的浮点计算任务,例如向量和矩阵操作。
2.2 CPU和GPU间的数据交互准则
CPU和GPU之间通过PCIe总线来交互数据,PCIe是中低速总线,实测数据表明在图1所示CPU+GPU异构计算架构中,当CPU采用页锁定内存进行数据交互时,PCIe 2.0总线的单向传输速度大约为3 GByte/s,相较于CPU端大约为50 GByte/s的内存带宽,GPU端的内存带宽大约为200 GByte/s,PCIe总线速度明显小于内存带宽;当CPU采用分页内存进行数据传输时,PCIe 2.0的单向传输速度下降为1.5 GByte /s。
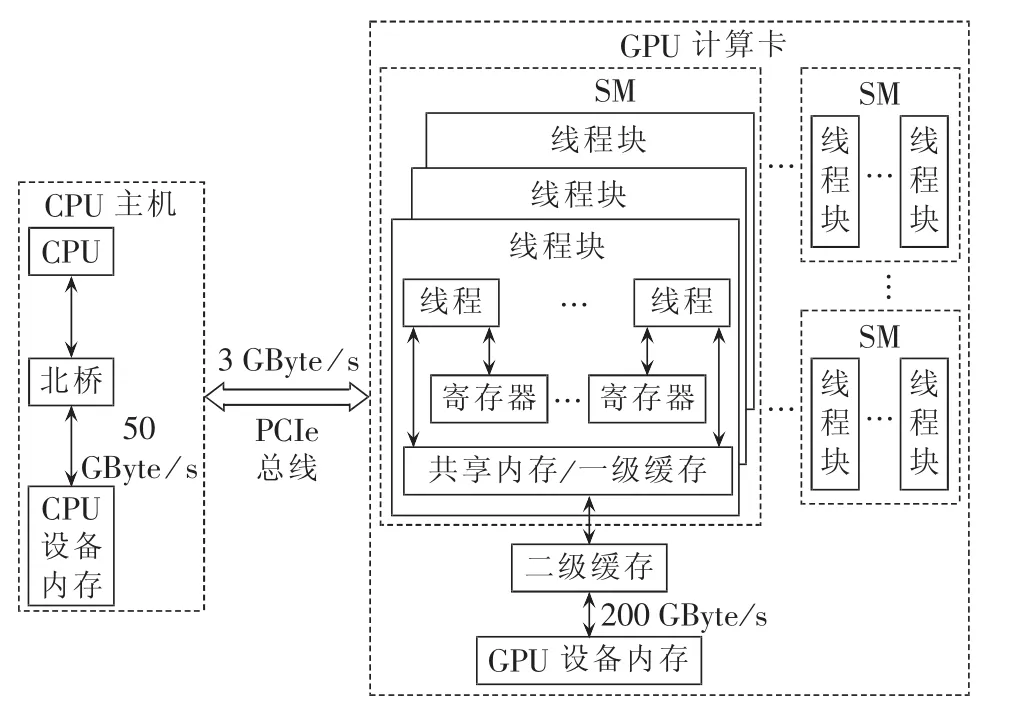
图1 CPU+GPU异构计算架构Fig.1 Heterogeneous computing architecture based on CPU plus GPU
综上所述,确定数据交互的设计准则如下:尽可能减少PCIe总线上的数据传输量,必要时可以采用页锁定内存进行数据传输,也可以增加计算复杂度来减少交换数据交互量。
2.3 内核函数的线程分配准则
CUDA通过大量线程并发来共同完成复杂的计算任务,和重量级开销的CPU线程不同,CUDA线程的创建和调度都由硬件完成,其时间开销几乎可以忽略。下文将结合GPU的软硬件架构来说明CUDA线程的调度机理,在此基础之上提出线程分配的准则。
CUDA采用一种被称为SIMT(Single Instruction Multiple Threads)的软件架构,即通过在不同数据上运行大量拥有相同代码的线程来完成计算任务。如图1所示,CUDA以线程网格(thread grid)方式来组织内核函数运行,每个线程网格由大量线程块(thread block)组成,每个线程块又由若干线程(thread)构成。各个线程块之间并行执行,线程块之间只能通过全局内存进行通信;同一线程块中的每32个线程被捆绑成为一个线程束(thread warp)严格同步执行,warp其实是GPU中最小的实际执行单位,线程块中的线程可以通过共享存储器(shared memory)和栅栏(barrier)进行通信和同步。综上所述,内核函数之间存在2类并行:一类是不同线程块之间的粗粒度并行,通信代价较大;另一类是同一线程块内不同warp之间的细粒度并行,通信代价较小。
从硬件架构来看,专用GPU计算卡一般由多个流多处理器 SM(Streaming Multiprocessor)单元、二级缓存、GPU设备内存等组成。每个SM单元都拥有完整的线程仲裁机制、规模上千的算术逻辑单元ALU(Arithmetic Logic Unit)团簇、大量特殊功能单元(用于三角函数和指数函数等的计算)、寄存器和一级缓存等。当一个线程网格被启动后,其包含的线程块将被枚举并分发到SM上执行,单个线程块只能在一个SM上执行;SM上的线程束调度器(warp scheduler)负责调度和管理大量的warp,warp中线程所需的浮点计算操作将被映射到一个ALU或者特殊功能单元上执行。
GPU通过大量wrap之间的自动切换来掩盖访存延迟,当一个warp发出高延迟的内存请求之后,SM将挂起该warp,并激活其他处于就绪状态的warp,因此SM上必须具有相当数量的warp,才能充分掩盖访存延迟,并充分利用计算资源。
综上所述,GPU算法必须保证一定数量的线程块来占满所有的SM单元,同时必须保证一定数量的线程(或者线程束)来掩盖访存延迟,因此可按照以下步骤进行线程分配方式设计。
a.GPU型号确定后,查询硬件手册获取SM单元数量NSM、每个SM单元最大常驻线程数Nmax_thd_per_SM、每个SM单元最大常驻线程块数Nmax_blk_per_SM这3个参数。
b.为了保证warp数量,应充分挖掘可并行的浮点计算,并使线程总数Nthd尽量大。
c.为了保证SM的占有率为100%,线程块大小Nthd_per_blk按下式确定:

d.为了充分利用所有的SM单元,线程块数量Nblk的配置应尽量满足下式:

2.4 GPU内存的使用准则
GPU上的存储资源可分为两大类:第一类是集成在SM单元上的寄存器、一级缓存、共享存储器等,第二类是所有SM单元共享的二级缓存和全局存储器。存储资源的优化分配和使用对算法的性能至关重要,下面主要对共享存储器和全局存储器的使用原则进行分析。
(1)共享存储器的物理位置位于SM单元内,其优点是延迟低,缺点是容量有限且只能被同一个线程块中的线程访问。当数据需要被一个线程块多次使用时,应优先考虑使用共享存储器。
(2)全局存储器的物理位置位于SM单元外,其缺点是访问延迟高达几百个时钟周期,优点是容量大。在CUDA架构中,同一个warp中的32个线程发出的内存请求会被尽量合并来减少实际发生的内存事务,最理想的情况是warp中的32个线程读取连续内存,则最少只需要1次内存事务就可以取回所有数据;反之,如果warp中的32个线程读取存储不连续的数据,则最多需要32次内存事务才能取回所需数据。因此,除了保证足够多的warp数量来掩盖访存延迟外,全局内存使用的第一准则是尽量实现合并访问,尽量通过设计让warp中的32个线程访问连续的物理地址。
3 故障筛选GPU算法的优化设计
基于第2节提出的通用设计准则,本节对故障筛选GPU算法进行详细设计和优化。
3.1 GPU和算例参数
GPU算法的设计与硬件密切相关,所以首先明确采用的CPU+GPU混合架构计算平台的参数,并引入算例。
混合架构服务器的操作系统为Windows7,CUDA版本为6.0;CPU配置为1颗6核心Intel Xeon E5-2620,主频 2 GHz;GPU配置为1颗 NVIDIA K20。K20 GPU采用Kepler GK110架构,包含13个SM单元,单精度浮点峰值为3.52 Tflops,内存带宽为208 GByte/s;每个SM单元包含192个单精度计算核、64个双精度计算核、32个特殊功能单元[14]。
本文采用2个算例进行性能分析:算例1为MATPOWER中的case 2383 wp,节点数为2383个,支路数为2896条,发电机数为327台;算例2采用中国某区域电网,节点数为9241个,支路数为16049条,发电机数为1445台。
GPU程序和用于性能对比的CPU程序都基于第1节提出的模型编写,两者都采用单精度浮点数据格式,CPU程序采用VC编写。
3.2 任务分配和数据交互设计
基于2.1节和2.2节提出的任务分配和数据交互准则,建立如图2所示的算法总体流程。
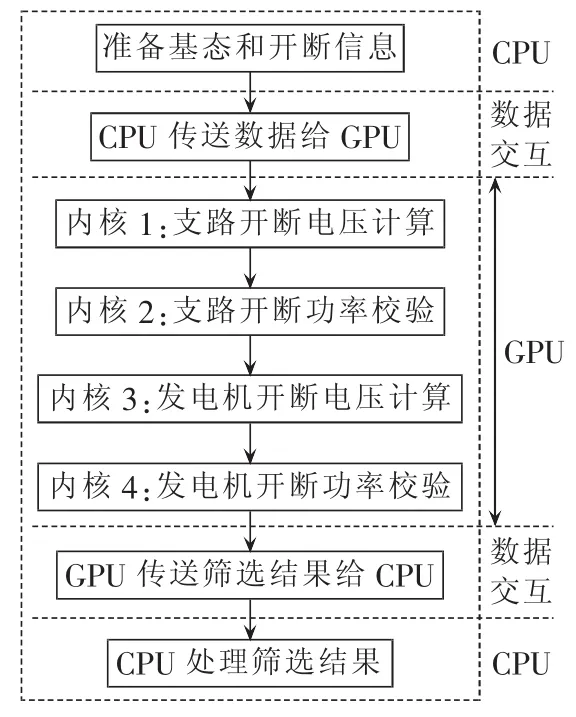
图2 直流筛选GPU算法流程Fig.2 Flowchart of GPU-based DC CS algorithm
a.由CPU负责控制程序的总体流程和不可并行的浮点计算,包括准备基态和开断信息、处理筛选结果、控制数据传输和启动GPU内核函数。
b.GPU负责可并行化的浮点计算任务,一共设计了4个内核函数来进行故障筛选,其中内核1根据式(7)和式(4)计算支路开断后的电压相角向量θ,由于各个支路开断之间没有关联,最直观的线程分配方法是内核1的一个线程计算一个支路开断;内核2根据式(3)计算支路有功,并将计算结果与限值比较判断是否越限。同理,内核3根据式(8)和式(4)计算发电机开断后的电压相角向量θ;内核4进行发电机开断的支路功率校验。
c.CPU传递给GPU的数据包括基态断面X0、θ0和P0,支路信息和发电机信息;GPU回传给CPU的数据主要包括严重故障集信息,即属于严重故障集的支路开断和发电机开断编号。算例1和算例2的基态电抗阵X0的数据存储量分别约为23 MByte和350 MByte,其他数据的存储量小于0.5 MByte。上述交互数据是故障筛选的必要数据,无法再优化压缩,但可通过页锁定内存来减少交互时间。
d.不失一般性,以内核函数1来阐述设计细节,算法1流程图见图3,其中线程总数Nthd等于支路数量Nbranch,线程块大小取Nthd_per_blk=128;线程的浮点计算量集中在计算第b条支路开断后的电压向量θb。
算例1和算例2的GPU算法加速性能见表1。

图3 算法1流程图Fig.3 Flowchart of algorithm 1

表1 GPU算法性能Table 1 Performance of GPU-based algorithm
由表1可得如下结论。
(1)算例1的GPU算法总执行时间为79 ms,其中分页内存数据交互时间为17 ms(采用页锁定内存时,数据交互时间降为9 ms),约占总时间的22%;内核函数执行时间为62 ms,约占总时间的78%。CPU算法的总执行时间为196 ms,GPU算法的加速比为196 /79≈2.48。
(2)算例2的GPU算法总执行时间为2330 ms,其中分页内存数据交互时间为240 ms(采用页锁定内存时,数据交互时间降为120 ms),约占总时间的10%;内核函数执行时间为2090 ms,约占总时间的90%。CPU算法的总执行时间为9672 ms,GPU算法的加速比为9672/2330≈4.15。
3.3 线程分配优化设计
按照第2.3节提出的线程分配准则来优化算法1,具体步骤如下。
a.查询NVIDIA K20的硬件手册,获取和线程分配设计相关的参数,包括SM单元数量NSM=13,每个SM单元最大常驻线程数Nmax_thd_per_SM=2048,每个SM单元最大常驻线程块数Nmax_blk_per_SM=16。
b.为了保证warp数量,应充分挖掘可并行的浮点计算,并使线程总数Nthd尽量大。改进后的算法(算法2)流程图见图4,总体思路是将算法1中第b条支路开断后的电压向量θb计算分配给一个线程块。

图4 算法2流程图Fig.4 Flowchart of algorithm 2
c.为了保证SM单元的占有率为100%,线程块的大小按式(9)计算,Nthd_per_blk=2048 /16=128。
不失一般性,以算例2为例来分析:算法1的线程总数Nthd=Nbranch=16049个,Nthd_per_blk=128个,线程块数量 Nblk=(Nbranch+Nthd_per_blk-1)/Nthd_per_blk=126个,不满足式(10)要求的 13×16=208(个)。相比较而言,算法2的线程总数和线程块数量都扩大了128倍,远超式(10)要求,不仅提供了足够的线程块来充分利用SM资源,同时也提供了更多的线程束来掩盖访存延迟。
经测试,经过线程分配优化之后,算例2的内核函数执行时间从算法1的2090 ms下降为算法2的534 ms,获得的额外加速比为2090/534≈3.91。
3.4 内存访问优化设计
按照第2.4节提出的内存使用设计准则来优化算法2,具体步骤如下。
a.算法2中没有数据被一个线程块重复使用,所以没有必要使用共享存储器。
b.算法 2 中计算 θb(t)=θ0(t)+c[θ0(i)-θ0(j)]×[X0(t,i)-X0(t,j)]需要访问矩阵 X0的第i列和第j列元素,造成一个warp中的32个线程访问物理地址不连续的数据,且彼此间隔矩阵X0一行,此时,每个warp需要32次内存事务才能取回所需数据,属于完全不合并访问的最差情况。为了提升访存效率,修改算法2形成算法3,流程图见图5。由于电抗阵 X0为对称阵,所以有 X0(i,t)=X0(t,i)和 X0(j,t)=X0(t,j)。算法 3 中,每个 warp 中的 32 个线程访问物理地址连续的数据,即矩阵X0一行中的连续元素,属于完全合并的最佳情况,访存效率将大幅提高。

图5 算法3流程图Fig.5 Flowchart of algorithm 3
经测试,经过合并访存设计之后,算例2内核函数的执行时间从算法2的534 ms下降为算法3的68 ms,获得的额外加速比为534/68≈7.85。
3.5 效果分析
表2给出了页锁定内存数据交互、线程分配优化、内存访问优化之后的GPU算法性能。

表2 优化后GPU算法性能Table 2 Performance of GPU-based algorithm after optimization
对比表1所示优化前性能可得结论如下。
a.和分页内存数据交互相比,页锁定内存数据交互可以将数据传输时间降低一半左右,但分配页锁定内存会减少操作系统可分页物理内存的大小,因此使用过大的页锁定内存会降低系统性能。
b.经过线程分配优化之后,算例2的内核执行时间从2090 ms下降为534 ms,获得了额外3.91倍加速。
c.经过内存访问优化之后,算例2的内核执行时间从534 ms下降为68 ms,获得了额外7.85倍加速。
d.经过页锁定内存数据交互、线程分配优化、内存访问优化之后,算例2的GPU算法执行时间从2330 ms下降为188 ms,获得了额外12.4倍加速,相对于CPU算法的加速比为9672/188≈51。此外可以看出,算例2的数据交互时间约占总时间的64%,内核执行时间约占36%,数据交互时间已经成为算法瓶颈。
e.经过充分优化之后,算例1的GPU算法执行时间从79 ms下降为12.1 ms,获得了额外6.53倍加速,相对于CPU算法的加速比为196/12.1≈16.2。可以看出,无论是算法整体性能还是优化设计的效果,算例1都小于算例2,究其原因是因为算例1的规模较小,难以充分发挥GPU的硬件能力。
为了更加公平地评价GPU算法的性能,采用OpenMP技术对CPU算法进行多线程加速,每个CPU线程负责计算一部分支路开断或发电机开断,多线程算法的测试在混合架构平台的6核心Intel Xeon E5-2620上完成。表3给出了多线程算法的测试效果,对其分析如下:6线程CPU算法相对于单线程取得了4.49倍加速,但已经出现了轻微的饱和现象;即使和6线程CPU算法相比,GPU算法仍然可取得11倍加速。

表3 GPU算法和多线程CPU算法的性能对比Table 3 Comparison of performance between GPU-based algorithm and CPU-based multi-thread algorithm
4 结论
严重故障集筛选过程占整个静态安全分析总时间的25%~30%,对其采用高性能计算技术进行加速具有工程意义。直流故障筛选算法主要涉及稠密向量计算,非常适合采用GPU进行并行加速。本文研究的主要贡献如下。
a.对GPU的软硬件架构特点进行了详细剖析,基于此提出了GPU算法在任务分配、数据交互、线程分配、内存使用4个方面应遵循的设计准则。
b.基于上述GPU算法的通用设计准则,对直流故障筛选算法进行了详细设计和优化,提出了一种匹配GPU软硬件架构的并行直流故障筛选算法。9 241节点算例的绝对执行时间仅为188 ms,相对于6核心CPU算法取得了11倍加速。
本文研究表明:结合GPU软硬件架构的算法设计至关重要,提出的4个设计准则具有通用性,可被应用于其他电力系统算法的GPU加速。
参考文献:
[1]王锡凡.现代电力系统分析[M].北京:科学出版社,2003:98-104.
[2]李峰,李虎成,於益军,等.基于并行计算和数据复用的快速静态安全校核技术[J].电力系统自动化,2013,37(14):75-80.LI Feng,LI Hucheng,YU Yijun,et al.Fast computing technologies for static security checking based on parallel computation and data reuse[J].Automation of Electric Power Systems,2013,37(14):75-80.
[3]陈国良.并行计算:结构算法编程[M].北京:高等教育出版社,2003:13-17.
[4]Nvidia.CUDA programming guide[EB/OL].[2016-02-06].http:∥docs.nvidia.com /cuda /cuda-c-programming-guide.
[5]张宁宇,高山,赵欣.一种求解机组组合问题的内点半定规划GPU并行算法[J].电力自动化设备,2013,33(7):126-131.ZHANG Ningyu,GAO Shan,ZHAO Xin.GPU parallel algorithm of interior point SDP for unit commitment[J].Electric Power Automation Equipment,2013,33(7):126-131.
[6]韩志伟,刘志刚,鲁晓帆,等.基于CUDA的高速并行小波算法及其在电力系统谐波分析中的应用[J].电力自动化设备,2010,30(1):98-101.HAN Zhiwei,LIU Zhigang,LU Xiaofan,et al.High-speed parallel wavelet algorithm based on CUDA and its application in power system harmonic analysis[J].Electric Power Automation Equipment,2010,30(1):98-101.
[7]陈来军,陈颖,许寅,等.基于GPU的电磁暂态仿真可行性研究[J].电力系统保护与控制,2013,41(2):107-112.CHEN Laijun,CHEN Ying,XU Yin,et al.Feasibility study of GPU based electromagnetic transient simulation[J].Power System Protection and Control,2013,41(2):107-112.
[8]唐聪,严正,周挺辉.基于图形处理器的广义最小残差迭代法在电力系统暂态仿真中的应用[J].电网技术,2013,37(5):1365-1377.TANG Cong,YAN Zheng,ZHOU Tinghui.Application of graph processing unit-based generalized minimal residual iteration in power system transient simulation[J].Power System Technology,2013,37(5):1365-1377.
[9]张宁宇,高山,赵欣.基于GPU的机电暂态仿真细粒度并行算法[J].电力系统自动化,2012,36(9):54-60.ZHANG Ningyu,GAO Shan,ZHAO Xin.A fine granularity parallel algorithm for electromechanical transient stability simulation based on graphic processing unit[J].Automation of Electric Power Systems,2012,36(9):54-60.
[10]夏俊峰,杨帆,李静,等.基于GPU的电力系统并行潮流计算的实现[J].电力系统保护与控制,2010,38(18):100-110.XIA Junfeng,YANG Fan,LI Jing,et al.Implementation of parallel power flow calculation based on GPU[J].Power System Protection and Control,2010,38(18):100-110.
[11]杨罡,喻乐,刘明光.基于多轻量线程的电力系统潮流计算加速方法[J].电网技术,2013,37(6):1666-1670.YANG Zhi,YU Le,LIU Mingguang.A method for accelerating power flow calculation based on multiple light threads[J].Power System Technology,2013,37(6):1666-1670.
[12]陈德扬,李亚楼,江涵,等.基于道路树分层的大电网潮流并行算法及其 GPU 优化实现[J].电力系统自动化,2014,38(22):63-69.CHEN Deyang,LI Yalou,JIANG Han,et al.A parallel power flow algorithm for large-scale grid based on stratified path trees and its implementation on GPU[J].Automation of Electric Power Systems,2014,38(22):63-69.
[13]徐得超,陈勇,王伟,等.基于图形处理器的多波前潮流计算方法[J].高电压技术,2016,42(10):3301-3307.XU Dechao,CHEN Yong,WANG Wei,et al.GPU-based multifrontal methods in power flow calculation[J].High Voltage Engineering,2016,42(10):3301-3307.
[14]Nvidia.NVIDIA’s next generation CUDA compute architecture:kepler GK110[EB/OL].[2016-02-06].http:∥www.nvidia.com /content/PDF /kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.
猜你喜欢
导航定位学报(2022年2期)2022-04-11 03:17:34
能源工程(2020年6期)2021-01-26 00:55:22
铁道通信信号(2019年4期)2019-10-10 03:42:38
电信科学(2016年9期)2016-06-15 20:27:30
电测与仪表(2016年13期)2016-04-11 11:21:20
中国学术期刊文摘(2016年2期)2016-02-13 16:01:41
新乡学院学报(2015年6期)2015-11-06 08:04:55
电测与仪表(2015年18期)2015-04-12 00:45:24
电网与清洁能源(2015年2期)2015-02-28 16:03:15
电子设计工程(2015年3期)2015-02-27 12:03:45
