
柴油机万有特性拟合方法对比及评价
2017-05-22 02:24王磊
汽车实用技术 2017年17期
王 磊
(安徽江淮汽车集团股份有限公司,安徽 合肥 230601)
引言
中国目前是近3000万的全球最大汽车市场,无论是乘用车商用车都是充分竞争的行业。车辆销售的成功往往是综合能力的成功。动力传动系统开发在传统汽车开发中投入占比最高。如何最大程度发挥其价值是各 OEM的硬功夫。正是由于竞争激烈且开发成本高,各细分市场都是整车争夺的阵地。外加鸡蛋不能放在同一篮子里的缘故,一机多车,一车多机是目前汽车市场极为普遍的现象。
动力传动系统匹配技术伴随研究深度满足实际应用后,其汽车及大总成间的平台化机车匹配就显得尤为重要。通过技术的边界去挖掘产品的边界是提升产品价值,降低开发成本的重要方法。
目前国内动力匹配应用 AVL-cruise等商业软件较为普遍,其产品精度也能满足一般用户需求且简单易学,因此应用广泛。但随着油耗需求的不断提升,动力匹配越来越精细化,原来一体化的部件被逐渐细分,这在仿真建模过程中必不可少。商业软件部分建模效果不佳,因此重新构建动力传动系统匹配软件亦有其应用价值。发动机万有特性则是动力传动系统匹配中最重要的部分。
本文主要通过对某柴油机万有特性案例,应用常见万有特性拟合方法,给出万有特性拟合数据评价方法,找到精度较高的最佳拟合分析方法。
1 常见分析方法
最小二乘法线性回归由于计算简单易行,在工程中应用极为广泛。下述均基于此方法进行分析:
1)基本拟合因变量分为转速n和扭矩T。分析方法分为因变量(n,T)和(1,n,T)两种。
2)转速n和扭矩T由于计算精度问题,确定是否改变单位大小或取对数。
3)万有特性整体非线性,是否采用分域拟合方法。
4)拟合阶次确定为多少最佳。
综上所述,数据分析方法在以上四个分析方向基础上组合,即变量阶次按二元一次、二元二次、二元三次、三元一次、三元二次共5类;数据量级按原数据、全部取对数、全部数据除10、转速除100/扭矩油耗除10共4类;区域法按不分区、按转速扭矩中值分区、按油耗最低处转速扭矩分区共3类,总计共60种拟合方法,共180个拟合数据。
2 数据评价方法
不同数据拟合计算相应转速n和扭矩T输入条件下油耗be。
1)相关系数及标准差分析:分析试验数据及拟合数据相关系数R²、残差的标准差s(ε);
2)最大误差及平均误差分析:计算残差绝对值与试验值之比,找出最大误差及平均误差。最大可接受误差为3%。
3 数据分析及评价
1)万有特性原始数据
出于保密原因,原始数据无法完全展示。此处展示最大油耗、最小油耗及样本量数据。

表1
样本从900rpm-2600rpm中10处转速9处扭矩条件下取样本数据,总体样本量90。
2)分析评价

图1
上图中横坐标为不同变量不同阶次方法,纵坐标为误差,折线为不同数据量级及分区法条件下数据。由上图数据可知:a)增加因变量1的三元数据与二元数据拟合结果完全相同,此方法确定无效;b)拟合阶次越高,精度越高。

表2
上图可知,拟合数据精度大小对比:分区 1>分区 2>原始数据。因此对于非线性万有特性数据,按照分区方法拟合,可提高其拟合精度。
由下图可知,该类型拟合数据精度均较高。其中对数拟合精度最高,计算对数拟合四个区域平均误差 0.16%,最大误差为0.98%,平均标准差0.298,标准差的标准差为0.255。
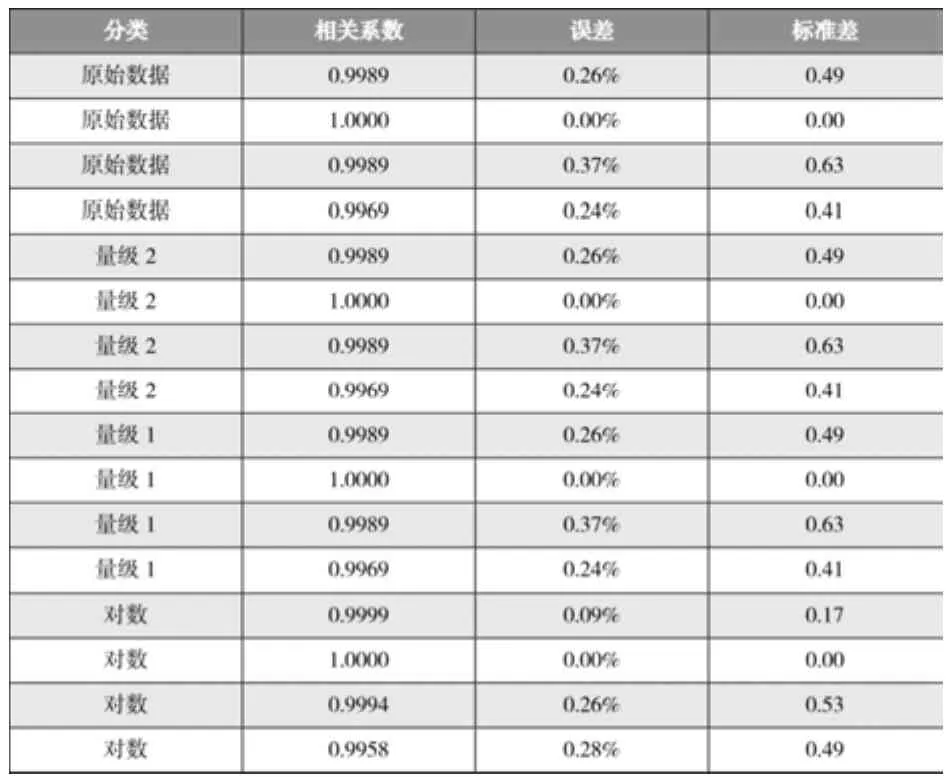
表3
4 数学模型
为了提高模型拟合精度,发动机万有特性曲线以等小时油耗量表达,即表现为发动机等小时油耗B与转速n和扭矩T的关系,类似幂
函数 ,其函数表达式如下:
,其中C0,Cij为多项式拟合系数。
分区方法:转速界限为转速最大最小值的均值;扭矩界限为扭矩最大值最小值的均值。
5 结论
1)增加定值作为变量的分析方法没有改变分析结果。
2)数学模型阶次越高拟合精度越高,但受限于计算系统精度及计算资源,选择3阶幂函数较为合理。
3)高精度万有特性拟合数据可以大大简化计算量,为整车动力匹配精度提升做出更大贡献。
参考文献
[1] 陈朝阳,赵正彩,余中桂等.汽车发动机万有特性曲面拟合的一种新方法Ⅱ.安徽工学院学报.1994,13 (2):35-40.
[2] 黄风清.基于MATLAB的发动机万有特性曲面拟合.[M]柴油机设计与制造,2014,3.
[3] 张京明,赵桂范.发动机特性计算模型在整车性能计算中的应用I-J].车用发动机.2000,3.
[4] 江发潮,陈全世,曹正清.发动机特性数值仿真方法的研究[J].车用发动机,2004,(4):32~34.
猜你喜欢
计算机技术与发展(2020年9期)2020-11-26
汽车与驾驶维修(维修版)(2020年1期)2020-04-02
汽车实用技术(2019年24期)2019-12-27
数学学习与研究(2018年14期)2018-10-29
车迷(2018年12期)2018-07-26
价值工程(2017年28期)2018-01-23
车迷(2017年12期)2018-01-18
消费者报道(2014年13期)2015-03-19
中学数学杂志(初中版)(2014年1期)2014-02-28
中学生数理化·八年级数学人教版(2008年6期)2008-09-05
