
ODPS平台下的电力设备监测大数据存储与并行处理方法
2017-05-16 01:08:11朱永利宋亚奇王刘旺
电工技术学报 2017年9期
朱永利 李 莉 宋亚奇 王刘旺
(华北电力大学控制与计算机工程学院 保定 071003)
ODPS平台下的电力设备监测大数据存储与并行处理方法
朱永利 李 莉 宋亚奇 王刘旺
(华北电力大学控制与计算机工程学院 保定 071003)
计算性能是制约电力大数据应用(基于大数据的故障诊断、预测等)的关键问题。利用分布式存储、并行计算加速此类数据密集型应用是目前较有效的手段。尝试利用阿里云开放数据处理服务(ODPS)存储并加速电力设备监测大数据分析过程。以变压器局部放电(PD)数据相位图谱分析(PRPD)为例,提出了适合高采样率、时序性强的局部放电信号数据存储方法。采用ODPS扩展MapReduce模型(MR2)设计了“Map-Reduce-Reduce”方式的PD信号宏观特征提取方法,提出了并行化PRPD分析算法(ODPS-PRPD),实现了大量PD信号的并行基本参数提取、统计特征计算与放电类型识别。在实验室中构造了4种放电模型并采集了大量PD信号,分别在ODPS平台上和实验室自建的Hadoop平台上进行了性能评估和成本分析。实验分析和结果表明,ODPS-PRPD将大量的中间过程数据(PD谱图数据等)一直保存在内存中,相比自建Hadoop MapReduce平台性能明显提升,并在数据可靠性、服务可用性以及成本方面具有明显优势。
电力大数据 公有云 开放数据处理服务 扩展MapReduce模型 局部放电 局部放电相位图谱分析
0 引言
近年来,随着信息化与电力系统深度融合以及物联网技术的快速发展,智能化电力一次设备和常规电力设备的在线监测都得到了较大发展并成为趋势,监测的广度和深度在不断加强,监测数据的体量日益庞大[1]。传统监测装置和监测系统大多对采集数据就地处理再将“熟数据”上传到监测中心。但从国际监测领域的发展趋势而言,采集数据的处理已开始从就地监测装置向远方监控系统上移,如GE公司对于众多汽轮发电机组的监测,近期采用了监测装置的存储与处理能力弱化、监测中心的存储与处理能力提升的方式,有利于上层应用软件的及时更新[2]。鉴于高速光纤数据网和无线传输已在电力行业广泛普及,下一代电力设备远程监测系统需要获取和传输的数据主流应当是原始监测数据。
大数据蕴含大价值。大数据的存在引导人们研究“数据密集型”的应用系统[3],与大数据交互,识别新模式,发现新规律。“数据密集型”计算的性能直接与数据规模相关,大数据计算面临着前所未有的技术挑战[4]。近年来,并行与分布式计算系统(多核计算、网格计算、云计算等)以及并行编程模型(MapReduce、MPI等)在加速数据密集型计算中扮演着重要角色,典型的技术包括Google MapReduce[5]、Hadoop[6]、Swift[7]、DataCutter[8]、DryadLINQ/Dryad[9,10]、并行数据库(如Vertica、Teradata等)[11,12]、AWS Cloud[13]、阿里云开放数据处理服务(Open Data Processing Service,ODPS)[14]等,它们已经在商业、金融、互联网以及生物计算、工业监测等许多领域承担着数据密集型应用的计算任务。
在电力行业,Hadoop大数据处理技术凭借其高可靠性和优越的并行数据处理能力越来越受到学术界和企业界的重视。基于Hadoop的应用研究广泛而深入,包括状态监测大数据存储[15-17]、电力用户消费数据分析[18]、信号去噪[19]、数据压缩[20]、电能质量数据快速分析[21]、状态监测数据聚类分析[22,23]、配电网数据分析[24]、基于云平台的并行电磁计算[25]等。本文在前期的研究中,在实验室自建了Hadoop平台,开展了输变电设备状态监测数据存储优化、数据并行分析等方面的研究,遇到的主要问题和面临的技术挑战主要包括:
1)硬件限制:大多数学者的前期研究中,均采用了自建的Hadoop平台,存储和计算资源有限。
2)并行程序框架限制:Hadoop的MapReduce在每一轮操作之后,数据必须存储到分布式文件系统上或者HBase,接下去的Map任务执行了冗余的IO操作,导致性能下降。
3)受规模、维护方面的影响,数据可靠性、服务可用性降低。
4)前期需要购买大量硬件,成本较高。
总而言之,构建“数据密集型”的电力大数据应用系统,需要协调很多计算和存储资源,高效地接入和保存大范围、多尺度的监测数据,并使系统长时间保持安全可靠的运行状态,这对数据存储与分析平台提出了较高的性能要求,而自建Hadoop平台不易满足。
公有云计算平台以按需租用的方式,将用户从硬件采购、组网、平台搭建、系统软硬件维护中解脱出来,将存储资源、计算资源以Web Service的方式封装,并对外售卖,使用户可以专心于构建系统的业务逻辑。由于有庞大的研发和维护团队,目前商业阿里云平台在存储容量、计算性能、可靠性、扩展性、可维护性等诸多方面已远远超出许多学者或团队自建的云平台。
本文尝试利用阿里云ODPS存储并加速电力大数据分析过程。利用ODPS的扩展MapReduce模型(MR2)设计了“Map-Reduce-Reduce”模式的局部放电(Partial Discharge,PD)信号宏观特征提取方法,实现了海量PD信号的并行统计特征计算与放电类型识别。实验结果表明,本文方法相比于Hadoop MapReduce在计算效率上明显提升,并在数据可靠性、服务可用性以及成本方面具有明显优势。
1 ODPS开放数据处理服务
开放数据处理服务ODPS是阿里云提供的海量数据处理平台。主要服务于批量结构化数据的存储和计算,数据规模达PB级别。ODPS目前已在大型互联网企业的数据仓库和BI(Business Intelligence)分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等领域得到大规模应用。
ODPS相对于自建Hadoop平台,优势主要体现在两方面。首先,ODPS具有弹性伸缩的特性。每次计算任务使用的硬件资源随处理的数据量不同自动伸缩,这使得并行任务的执行性能非常平稳;其次,ODPS提供了扩展MapReduce模型MR2,可以在Reduce后面直接执行下一次的Reduce操作,而不需要中间插入一个Map操作。可以支持Map后连接任意多个Reduce操作,比如Map-Reduce1-Reduce2-…Reducen,每一次Reduce的输出,作为下一次Reduce的输入,中间结果始终保持在内存中,形成高效的处理链路。另外,ODPS还具备易扩展、免维护、低成本等诸多优势,适合用于电力设备监测大数据的存储和处理。
ODPS的生态圈完整,包含数据上传下载通道、SQL及MapReduce等多种计算分析服务接口,其功能组件如图1所示。
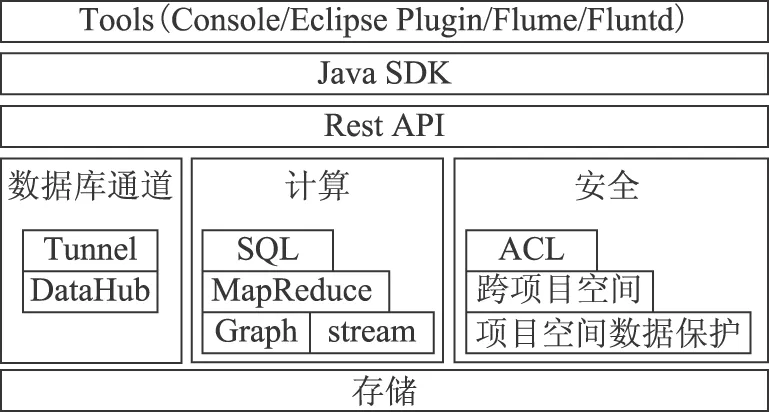
图1 ODPS框架和功能组件Fig.1 Framework and functional components of ODPS
2 PD数据存储与PRPD并行分析
2.1 PRPD分析及改进
局部放电相位图谱分析(Phase Resolved Partial Discharge,PRPD)将多个工频周期内监测所得的局部放电参数(放电次数n、视在放电量q或放电幅值及放电所在相位φ)折算到一个工频周期内,计算其统计规律性,获取放电谱图,统计放电特征,用于模式识别。
针对局部放电波形相位信息n-q-φ参数的提取,传统方法多采用固定阈值(纵阈值)对信号幅值进行判断来确定是否存在放电,即鉴幅法。鉴幅法虽然简单,但结果也很粗糙,易对振荡的放电脉冲重复计数,因此,本文对此提出一种改进方法,在信号时间轴上增加另一种阈值(横阈值)来度量放电间隔,避免重复计数,另外,对上述两种阈值提出采用最大类间方差[26]根据波形特征进行自适应计算,算法过程描述见表1。
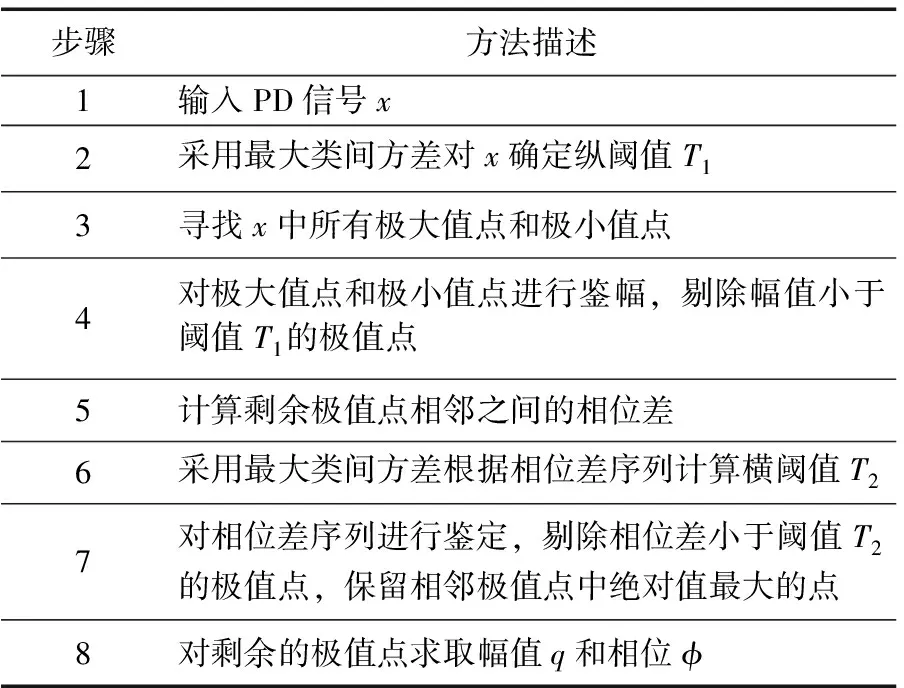
表1 基于改进鉴幅法的n-q-φ参数提取
局放监测采样速率高,数据量大,提取n-q-φ参数过程、计算谱图过程以及模式识别过程计算复杂度高。传统PRPD分析在单机环境下执行,受存储容量和处理能力限制,只能在采集到若干越限的放电信号数据后进行就地分析,把分析结果再上传监测中心,监测中心就无法收集并保存局部放电监测原始数据。因此,本文试图基于ODPS平台建立电力设备监测中心的数据存储和分析平台,解决局放监测大数据存储的问题。然而,监测中心需要收集众多的电力设备的监测数据(包括放电信号),为此必须找出快速的数据并行分析方法。
2.2 基于ODPS的并行PRPD分析整体流程
为了应对多监测源和大数据量的挑战,本文设计实现了在ODPS平台并行化的PRPD分析,其整体流程如图2所示。
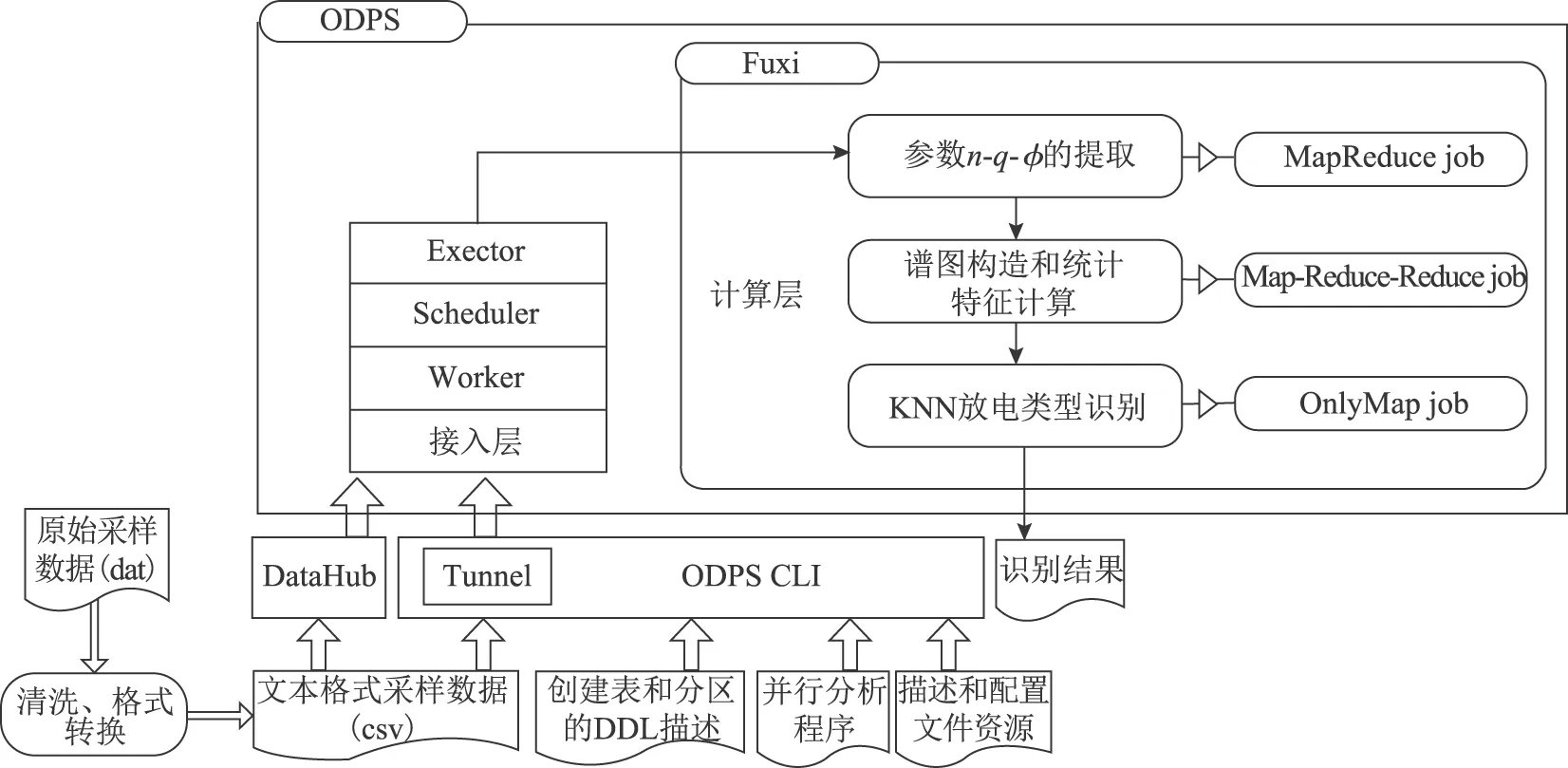
图2 并行PRPD分析整体流程Fig.2 Process of parallel PRPD analysis
分析流程主要包括3个过程:①基本参数n-q-φ的提取;②谱图构造和统计特征计算[27];③放电类型识别。本文选择K近邻(K-Nearest Neighbor,KNN)方法[28]进行放电类型识别。KNN算法的基本思想是:如果一个样本在特征空间中的K个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,算法原理如图3所示。
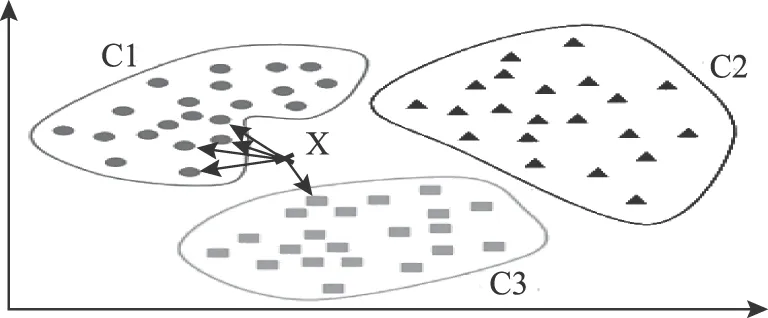
图3 KNN原理示意图Fig.3 KNN algorithm for classifying objects
KNN方法主要依赖周围特征相似的有限样本,不需要事先学习建立模型,在新样本增加时不需要对旧模型进行新一轮的更新学习,可有效避免模型再学习带来的停机成本。KNN在实现上易于实现数据拆分和数据并行,非常适合采用MR2模型在ODPS上实现。分析过程的输入来自ODPS表和资源,输出结果存储于ODPS表。
ODPS使用表存储数据。PD信号采样数据(二进制dat文件)在上传至ODPS前,需要转换成文本文件格式(csv文件)。如果数据规模较大,可采用Hadoop MapReduce批量转换,以提高转换性能。
ODPS数据接入层对用户云账号进行身份验证,请求处理器(Worker)将并行PRPD实例(Instance)提交给调度器(Scheduler),调度器把Instance分解成多个计算任务(Task),并生成Task工作流——DAG图(Directed Acyclic Graph)。作业执行管理器(Executor)获取Task,生成分布式作业描述文件,并提交计算层完成计算任务。
2.3 存储模式设计
ODPS以表(Table)为基本单元存储数据,这与Hadoop的文件系统(HDFS)以文件为单位存储数据有较大的差别,表的模式不能直接套用HDFS文件的格式,需要重新设计存储模式。
在Hadoop下以HDFS文件存储PD数据时,数据的格式不受限制,格式的解析也是自定义实现,非常灵活。比如,在图4a中,PD数据文件按行存储采样数据,每行以设备的ID和采集时间作为主键,后面是一个工频周期的采样数据(本文中含80万个采样点)。在使用MapReduce执行分析任务时,可以将一行数据作为Map函数的输入,在Map内完成统计分析。

图4 数据存储模式设计Fig.4 Design of storage scheme
然而,ODPS表的列数和表格单元的数据类型存在限制,列的数量不能超过1 024列,表格单元的数据类型目前仅支持5种数据类型(Bigint,Double,String,Boolean,Datetime)[14],因此无法在一行内存储80万个采样值。本文设计采用多行的方式存储采样数据,并根据设备ID和采集日期设置分区列实现PD数据的存储,如图4b所示。分区列的作用是实现按列快速访问,根据设备ID和采样日期设计了2层分区。ODPS支持根据分区列,快速定位到该分区的数据,因而可以有效提升访问性能。
图4b、图4d、图4f分别表示PD信号采样数据、基本参数n-q-φ和放电谱图的ODPS表模式。其中,基本参数n-q-φ的存储以一个工频周期为单位,存储放电幅值和放电相位。不同工频周期内,放电次数不同,因此需要将放电幅值和相位分多行存储。放电谱图数据在Hadoop MapReduce实现中,需要存储到磁盘存储,而ODPS-PRPD由于支持多个Reduce的串联,所以谱图数据是在内存中缓存的,提升了整体的执行性能。在图4f中,设计了5列的表记录放电谱图。SampleID表示用于完成一次特征计算的谱图数据的编号(本文实验中,选用50条谱图数据进行一次宏观特征统计,被选中的谱图数据将具有相同的SampleID),在计算特征的Map任务中,作为输出时的key。
图4g表示统计特征的存储模式,包含正负半周期谱图偏斜度Sk、陡峭度Ku、局部峰点数Pe、互相关系数Cc等。
2.4 ODPS-PRPD算法实现
2.4.1 MapReduce 任务链
基于ODPS扩展MapReduce模型MR2,设计了并行PRPD分析算法ODPS-PRPD,实现了海量PD信号的并行基本参数提取、统计特征计算与放电类型识别。ODPS-PRPD各个子过程通过不同形式的MapReduce任务完成并串联,构成分析任务整体,其MapReduce任务链如图5所示。

图5 ODPS-PRPD MapReduce任务链Fig.5 ODPS-PRPD MapReduce job chain in detail
2.4.2 格式转换
格式转换是为了将采样数据上传至ODPS表而做的数据预处理。格式转换的任务是将二进制的特定格式的采样数据(dat文件)转换成ODPS CLI tunnel能够识别的文本格式。
2.4.3 统计参数n-q-φ提取
提取基本统计参数n-q-φ,需要对采样数据全表进行扫描,找到放电过程,并记录放电相位和幅值。可以并行对不同的数据分块进行扫描,各个扫描任务之间不需要交互,适合用MapReduce实现。
Mapper函数对逐条输入的采样数据,根据预先设定的纵向阈值进行数据筛选,并将大于阈值的采样点输出至Combiner。Combiner是本地(与Mapper在相同的节点)执行的汇总,对Mapper的输出结果集合,寻找极值点,并输出至Reducer进行汇总。Combiner有效地分担了Reducer的数据汇总工作,并且减少了Reducer所在节点传输的数据量,可以有效提升并行计算过程的速度。
Reducer函数负责汇总由Combiner输出的极值点,并使用预先设定的横向阈值进行极值点的筛选。如果两个极值点距离“很近”(相位差小于横向阈值),则认为是同一次放电。输出的结果存储于ODPS表。统计参数n-q-φ并行计算的过程如图6所示。

图6 统计参数n-q-φ并行提取Fig.6 Parallel extraction of statistical parameters n-q-φ
2.4.4 谱图构造和统计特征计算
该过程接收n-q-φ表的数据作为输入,计算放电谱图和统计特征。为了加快计算速度,设计了Map-Reduce1-Reduce2模式的计算过程,使谱图数据作为中间结果缓存在ODPS分布式内存中,而并非保存至ODPS表中,节约了磁盘读取的开销。Reduce1和Reduce2的连接使用了ODPS提供的Pipeline完成。
1)Mapper函数。
将360°的工频周期均匀划分相窗,对M个工频周期的PD信号叠加,按正负半周期,分窗进行统计分析,输入输出接口见表2。本文实验中,1个工频周期含80万个点(360°),相窗的数量取200,则每个窗的宽度为4 000个点(800 000/200=4 000);M取50,意味着统计1 s(5020 ms=1 s)的放电情况。M值越大,周期越长,统计意义就越明显。

表2 谱图计算的Mapper函数
Mapper输出记录的key采用了SampleID+WinID的组合方式,这使得用于同一次统计分析(相同SampleID)且相窗编号相同的记录被发送至同一个Reducer1,避免了在Reducer1中区分不同的相窗,加快了Reducer1计算速度,并降低数据倾斜的概率(MapReduce job链中某一环节承担了较重的计算任务,成为性能瓶颈)。
2)Reducer1函数。
分正负半周期计算放电量相位分布谱图qave-φ和放电次数相位分布谱图n-φ,输入输出接口见表3。
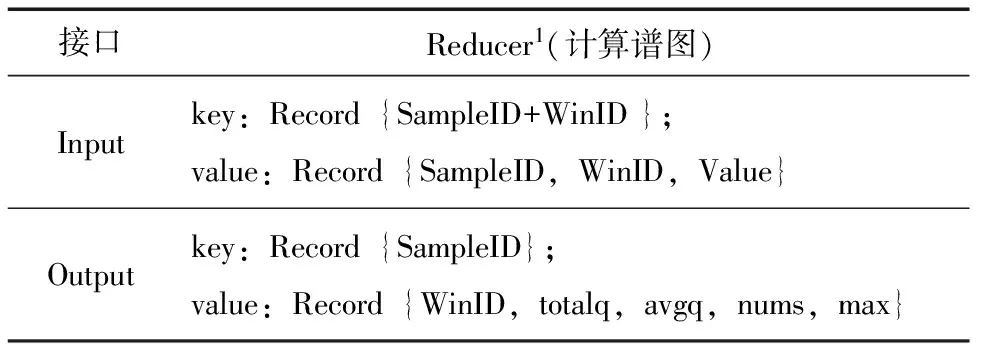
表3 谱图计算的Reducer1函数
如果取200个窗,M取50,则qave-φ是200列的表,每列代表1个窗,窗的编号可以取1,2,3,…,200。每列的值就是该窗内的放电量。50条n-q-φ数据,统计得到1条qave-φ数据。由于需要分别统计放电量峰值、放电总量和平均放电量,按照上述存储结构,就需要多张表;而且列数太多(达到200列,则1行记录较长),不利于数据并行,因此采用了图4f的存储方式,有利于数据处理的灵活性和并行性。n-φ的计算过程仅需将放电幅值改为放电次数即可。
3)Reducer2函数。
按照正负半周期,分别统计谱图的偏斜度Sk、陡峭度Ku、局部峰点数Pe、互相关系数Cc等统计特征,输出15维的放电特征向量,输入输出接口见表4。偏斜度反映了谱图形状相对于正态分布形状的偏斜程度,定义为
(1)
式中,φi为相窗i的相位;μ为均值;σ为标准差。
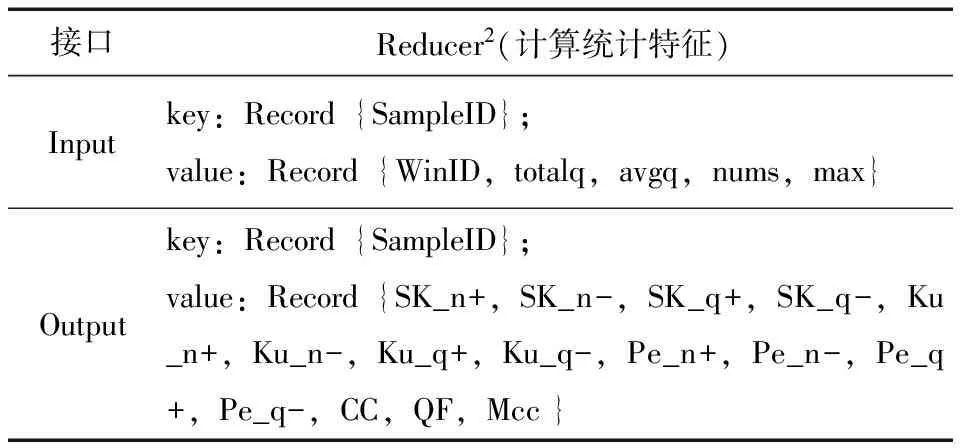
表4 统计计算的Reducer2函数
陡峭度反映了谱图形状相对于正态分布形状的突起程度,定义为
(2)
其他特征量的定义公式见文献[27]。如果严格按照特征量的计算公式,则需要对谱图数据进行两遍扫描。第1遍扫描,统计计算出放电量以及放电次数的均值、方差;第2遍扫描,计算Sk等统计特征。在程序实现上,可以对计算过程进行优化,将统计特征的计算公式进行展开化简,使公式中的均值、方差展开为∑的形式,则可以通过一次扫描实现特征的计算。
2.4.5 放电类型识别
本文采用KNN算法进行放电类型的识别。样本用15维统计特征表示,样本距离的度量采用欧氏距离。KNN算法需要计算未知样本和训练集中已知类别样本的距离。待识别数据集以ODPS表的形式分布式存储于多个节点,训练集以ODPSResource的形式常驻内存。目前,ODPSResource的上限是512MB,如果训练集超出此范围,可以采用“分而治之”的思想,把训练集垂直切分成多分临时表,把切分后的每份数据作为Resource加载到内存中,使用MapJoin的方式和测试集进行连接计算,选出最邻近的N个样本,判别放电类型。
在实现上,需要分为2个MapReduce完成(两个MapOnly作业,均不需要Reduce过程),KNN并行化过程如图7所示。
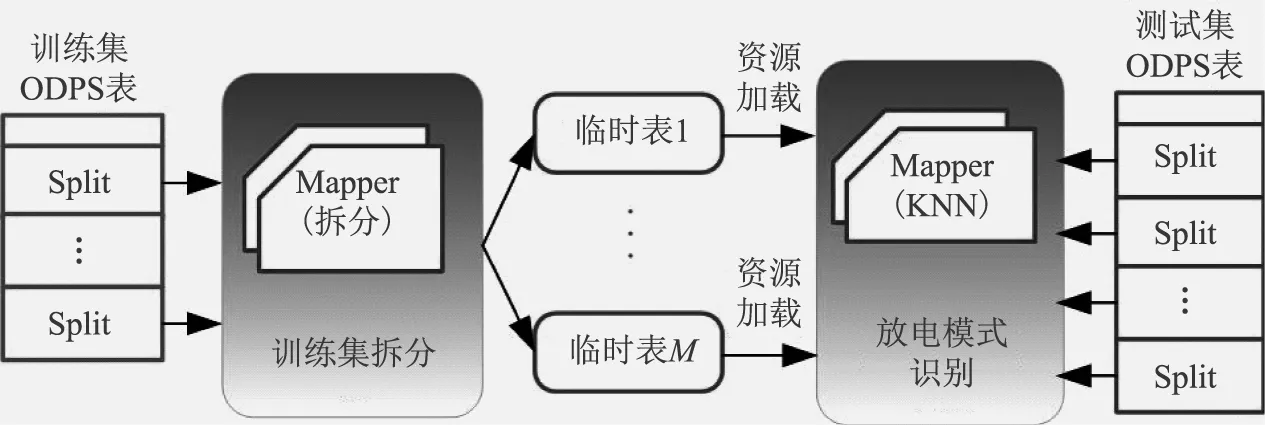
图7 并行化KNN算法Fig.7 A parallel form of KNN
Mapper(KNN)函数首先循环加载训练集资源,计算测试样本与训练样本的距离,选出最近的N个,输出类别,输入输出接口见表5。
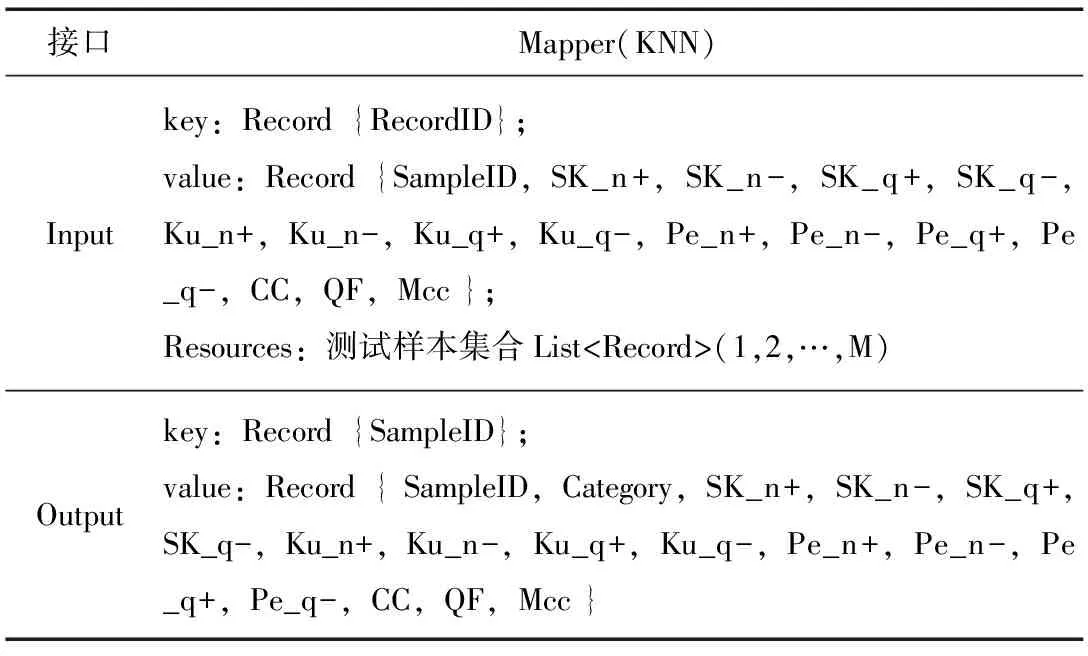
表5 KNN识别的Mapper函数
3 实验分析
3.1 放电实验数据获取和数据预处理
在实验室完成了电晕放电、悬浮放电、气泡放电和油中放电实验。局部放电信号采集仪器采用TWPD-2F局部放电综合分析仪,其最大采样频率为40 MHz,而信号采集传感器的有效频带为40~300 kHz。
为验证ODPS-PRPD算法性能和算法执行性能的稳定性,选取了不同大小的数据集,见表6。其中,数据集1x表示1倍数据,包含50个文件(50条局部放电数据),本文选用50条局部放电数据进行一次统计特征的提取。
数据预处理包括本地存储、格式转换、清洗和数据上传。采集的局部放电数据以二进制文件(dat)存储,每个文件含1个工频周期(20 ms)的采样数据,大小为6251 kb,含4通道,每通道80万个采样值。上传至ODPS之前,需要将二进制文件转换成文本格式(csv)文件。使用CLI Tunnel工具进行数据上传至ODPS表。使用自建Hadoop平台完成格式转换,性能如图8所示。
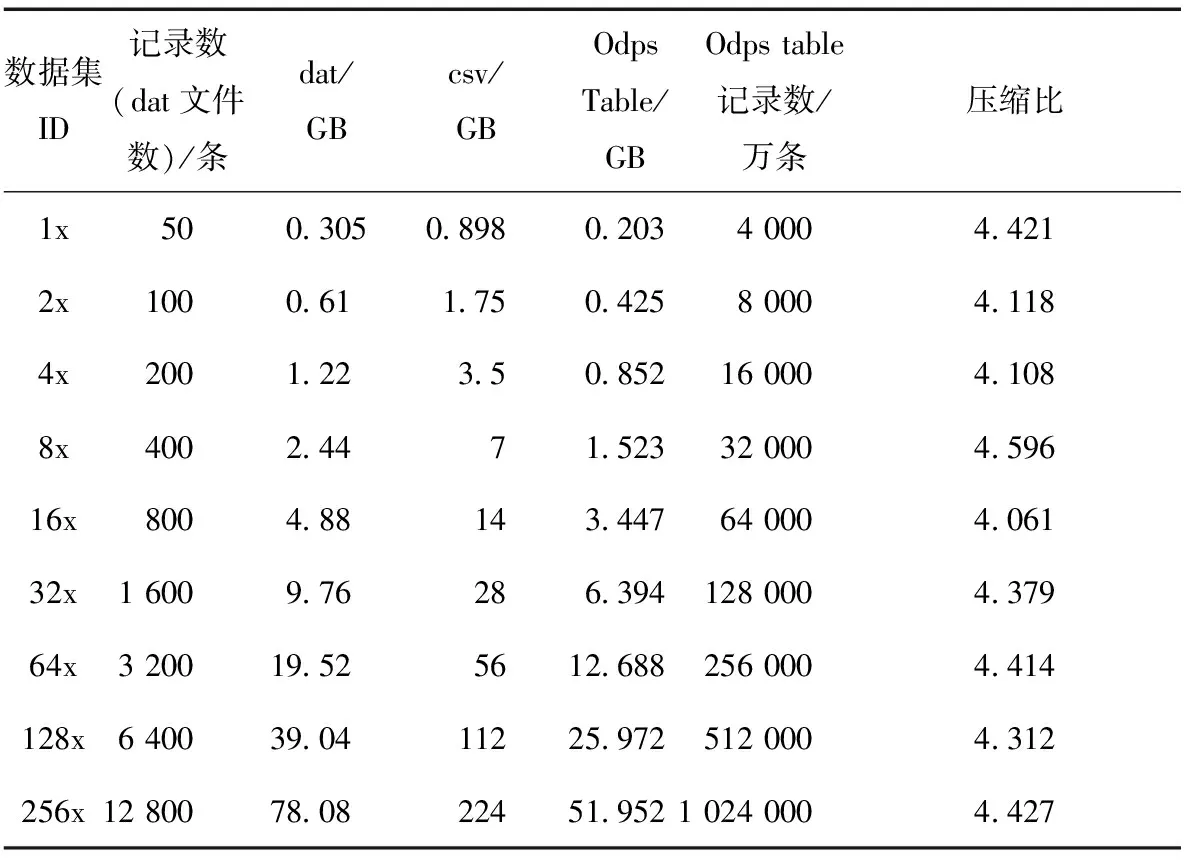
表6 数据集
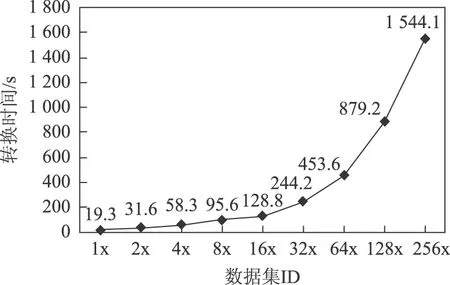
图8 格式转换性能Fig.8 Performance of format conversion
使用CLI Tunnel工具将csv格式数据上传,上传的性能与客户端主机的网络状况直接相关。笔者使用教育科研网,在学校实验室上传数据至ODPS平台,上传速度如图9所示。
CLI Tunnel默认执行压缩上传,不同数据规模的压缩比如图10所示。目前,ODPS使用的压缩算法压缩比根据数据类型的不同可达到2~5倍。本文中实验数据,当规模达到224 GB(csv文档)时压缩比为4.427。
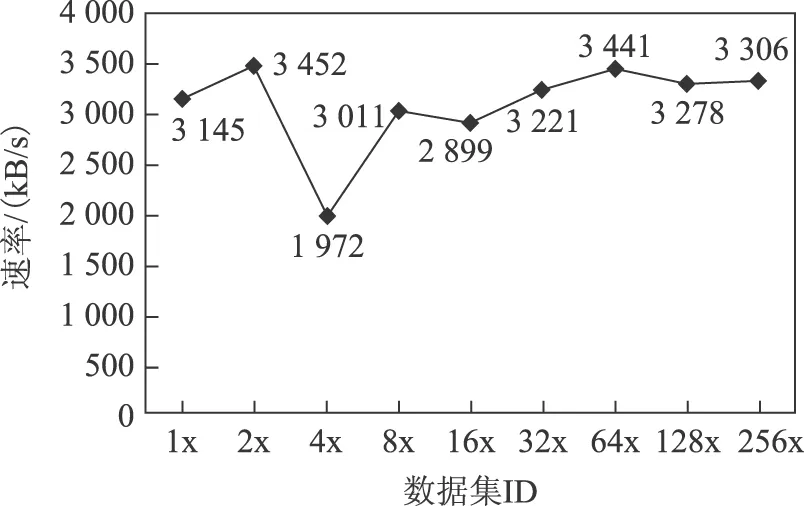
图9 数据上传性能Fig.9 Performance of data upload
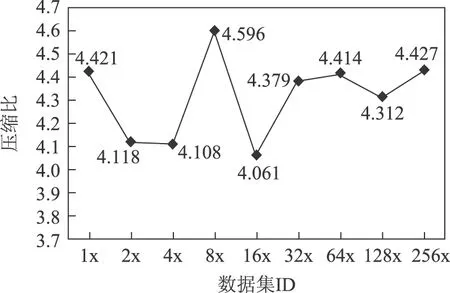
图10 数据压缩比Fig.10 Data compression ratio
3.2 实验平台硬件、软件配置
分别在单机环境下、实验室自建的Hadoop平台下和ODPS平台下完成PRPD分析,平台软硬件配置参数见表7。
ODPS数据处理能力随着数据量变化弹性伸缩。用户不能在执行计算任务之前看到平台硬件配置的详单(多少个计算节点、多少个CPU参与、使用的内存容量等)。但是在每次计算任务结束之后,通过监控界面可以看到为本次计算任务分配的硬件资源列表详单,见表8。用户需要按照使用的存储容量和计算量支付费用。
3.3 计算性能对比分析
分别在单机环境下、实验室自建的Hadoop平台下和ODPS平台下完成PRPD分析(分别命名为S-PRPD、Hadoop-PRPD、ODPS-PRPD),测量算法执行的时间、使用的硬件资源(CPU、内存)、并行的粒度(map、reduce任务数),并进行性能对比,结果见表9。运行时间对比如图11所示。本文的单机环境是指一个Data node,配置见表7。

表7 云平台配置参数

表8 ODPS计算任务详单示例
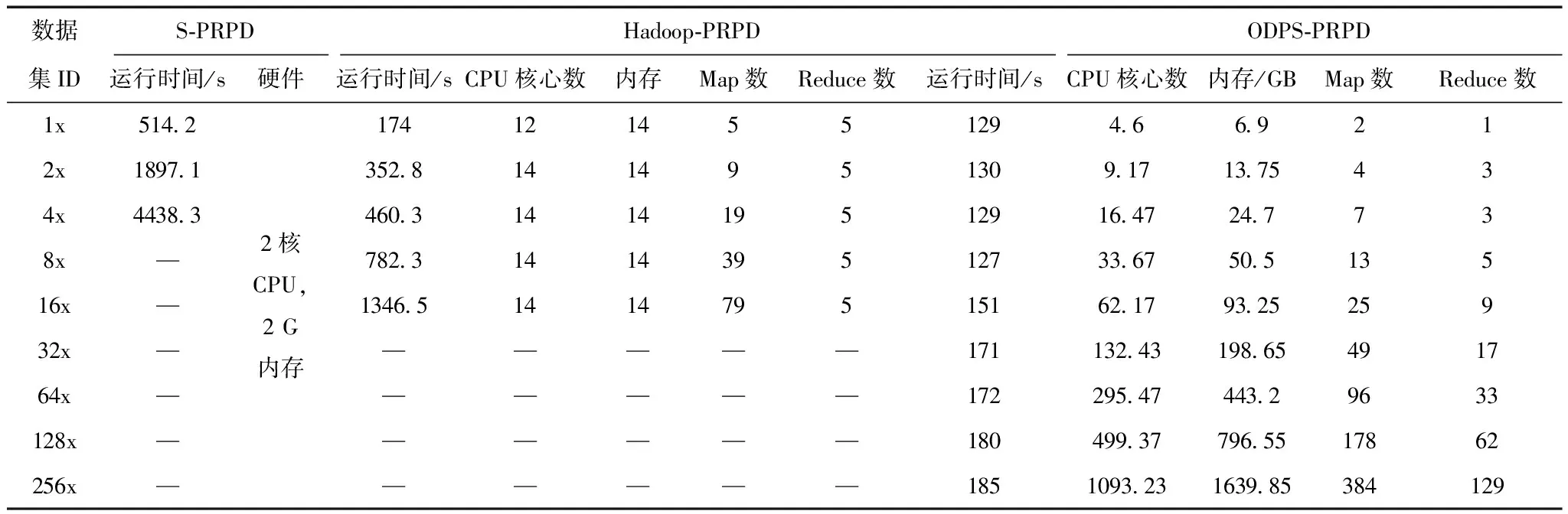
表9 运行时间、硬件参数、并行粒度对比
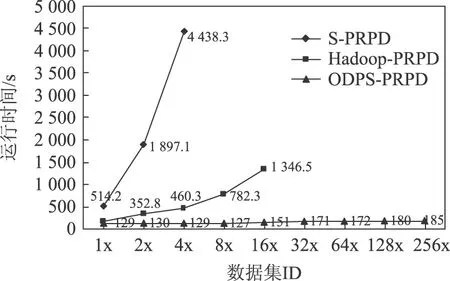
图11 PRPD运行时间Fig.11 PRPD time cost
在图11中,S-PRPD算法在单机环境下运行,执行时间随数据量增加急剧增长。只完成了4x数据集的分析任务(更大数据量耗时太长)。
Hadoop-PRPD算法在自建Hadoop平台下执行。受存储容量和计算性能影响,实验只完成了16x数据集的分析任务,算法执行时间缓慢增长。图12为PRPD硬件资源消耗,图13为PRPD并行粒度,图12和图13 的纵坐标均采用以10为底的对数坐标轴。由图12和图13可以看出,算法在处理4x数据集时CPU核心数(14)与map任务(19)(体现并行粒度)数接近,达到较好的匹配,系统硬件资源已经全部使用;在执行16x数据集分析时,map任务数已达到79,已远远大于CPU核心数(14),大量的map任务是串行的,已经超出了平台的计算能力,无法胜任更大规模的计算任务。
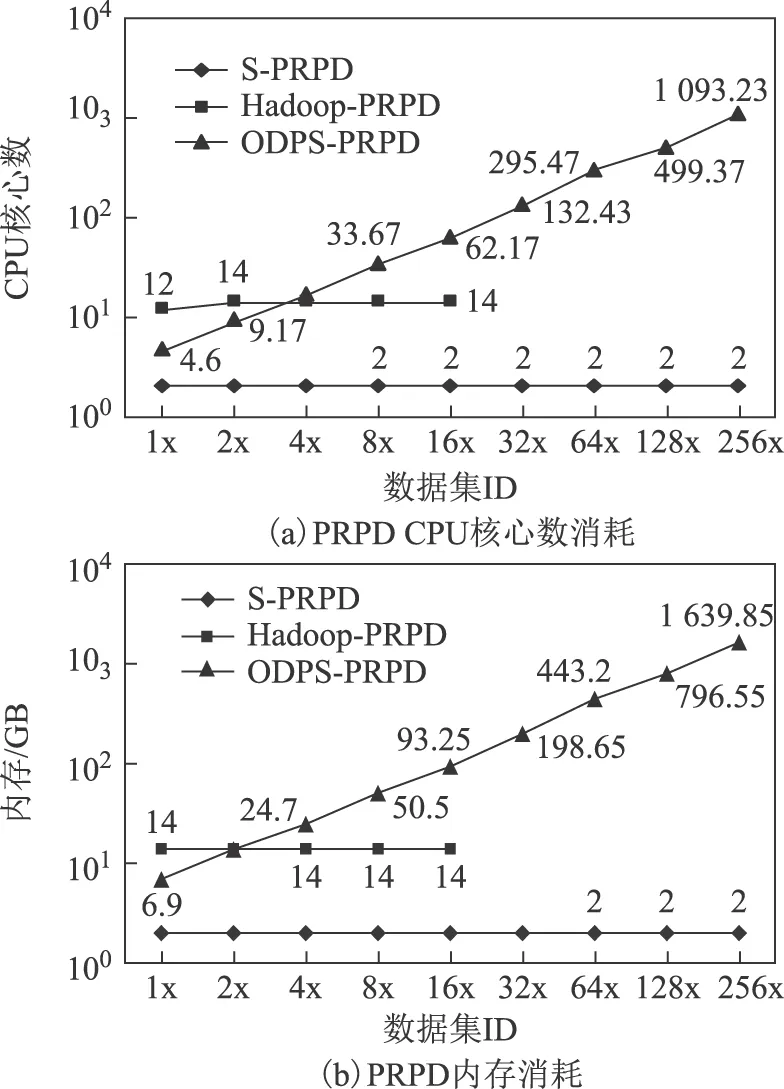
图12 PRPD硬件资源消耗Fig.12 Hardware resources consumption of PRPD
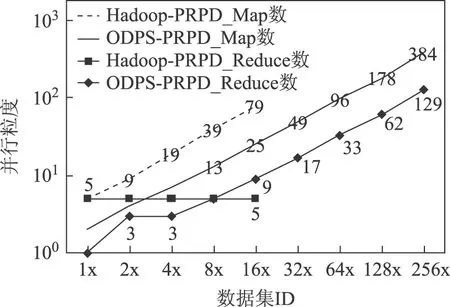
图13 PRPD并行粒度Fig.13 Parallel granularity of PRPD
ODPS-PRPD算法运行在ODPS平台下,完成了256x数据集的分析(还可以更大,可支持PB级数据),运行时间平稳,在数据规模成倍增长情况下,整体运行时间增长很少或不增长,甚至,在分析8x数据集时出现负增长。主要归因于ODPS硬件的弹性伸缩,如图11所示。
从图12可以看出,随着数据规模的增长,ODPS-PRPD使用的硬件资源总体呈现线性增长的趋势。数据规模越大,为其分配的硬件资源越多,但也不是严格的线性关系。ODPS为并行任务分配的硬件资源有一个复杂的算法实现,目前阿里云尚未公开,使用者暂不能控制资源的分配。虽然底层细节对用户透明,但是这种弹性伸缩的性质还是能够强有力的为大数据分析助力。在表9中,当数据规模达到51 GB(256x)时,使用的CPU核心数达到了1 093,内存达到了1 639 GB,才能保证任务在185 s内完成,这种硬件条件是目前大多数自建数据处理平台难以达到的。
对表9的1x和2x数据集的PRPD进行分析可知,ODPS-PRPD算法消耗的硬件资源少于自建Hadoop平台,但仍获得了更优的性能,主要原因之一是ODPS-PRPD在统计特征提取子过程中使用了改进的MR2模型,在计算谱图和统计特征中,大量的中间数据一直保留在内存中,省去了读写磁盘的时间开销,统计特征子过程的运行时间对比如图14所示。
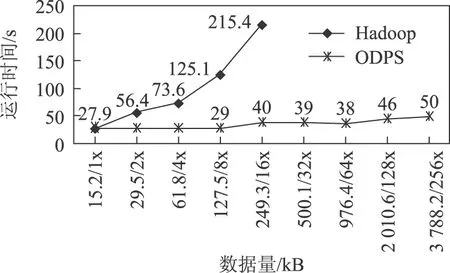
图14 统计特征提取子过程运行时间Fig.14 Run time of statistical feature extraction sub-process
另外,ODPS也对MapReduce任务进行了系统级的优化,使ODPS-PRPD性能优于Hadoop-PRPD。当数据规模大于2x数据集时,ODPS-PRPD运行时间远低于Hadoop-PRPD,主要原因是使用硬件资源的增长。
图15对比了ODPS-PRPD各分析阶段的运行时间。可以看出,在整个分析过程中,第1个阶段统计参数n-q-φ提取过程占用的时间比例最高,平均占比达到70%。主要原因是第一阶段处理的数据最多,之后计算出的统计数据规模较小,所以后续的分析过程执行时间较短。
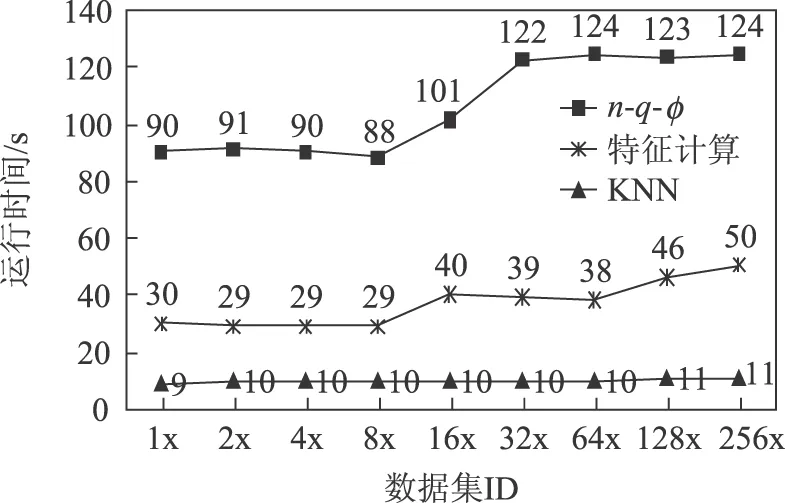
图15 ODPS-PRPD子过程运行时间Fig.15 Run time of ODPS-PRPD sub-process
综上,相对于大多自建Hadoop集群,ODPS的高性能主要归因于以下3个方面:①硬件资源。在执行任务时,ODPS可以根据待处理的数据规模弹性调整硬件资源分配。②并行度。由于硬件资源(CPU、内存)的弹性扩展,使得在处理大数据集时,并行任务数(Map数)也可以有效增长。③并行编程模型。优化的MR2模型使得Reduce的中间结果始终保持在内存,节约了大量的通信和磁盘I/O开销。
3.4 成本分析
ODPS采用租用的方式,无需自行购买硬件设备和软件,相对自建Hadoop或者其他大数据分析平台,前期投入成本极低。
ODPS以项目(Project)为单位,对存储、计算和数据下载三个方面分别计费。数据上传目前暂不收取费用。存储价格目前是0.0008元/GB/h,计算费用是0.3元/GB。计算费用中,目前仅开放了SQL的计费,执行MapReduce暂时是免费。因此,本文实验实际产生的费用只有存储费用,合计6.96元(48 h)。
考虑到未来即将开通MapReduce收费,本文按照SQL的标注计算费用。实验周期按2天(48 h)计算,执行1次ODPS-PRPD产生的费用如图16所示。
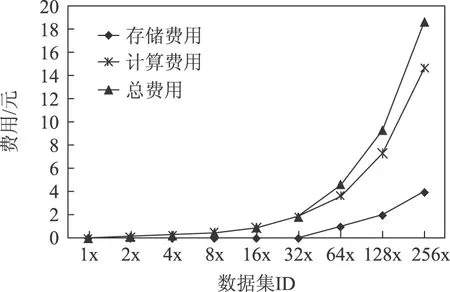
图16 ODPS-PRPD费用分析Fig.16 Costs of ODPS-PRPD
从图16可以看出,存储费用随时间呈线性增长。计算费用增长速度高于线性增长。
4 结论
利用现有大数据存储和并行处理技术,加速数据密集型应用计算速度,助力电力大数据价值释放,是电力大数据应用研究的主要目标之一。
本文基于阿里云大数据计算服务ODPS设计实现了海量变压器局部放电数据的存储方法,提出了基于ODPS扩展MapReduce模型MR2的并行化PRPD分析方法ODPS-PRPD,实现了海量 PD 信号的并行基本参数提取、统计特征计算与放电类型识别。
ODPS-PRPD利用pipeline将Map和多个Reduce过程连接起来,使大量的中间过程数据保持在内存中,相比Hadoop-PRPD节省了大量的磁盘访问开销,性能明显提升。
与自建Hadoop平台相比,ODPS的优势主要体现在:①弹性伸缩。参与计算任务的硬件资源随数据规模的增长自动增长,使计算任务的执行时间保持非常平稳的趋势。②存储容量可达PB级,计算能力弹性伸缩,在对51 GB的PD数据执行PRPD分析时,参与的CPU核心多达1 093个,内存多达1 639 GB,这是自建平台很难企及的。③成本优势。完成本文实验使用了上千颗CPU核心和上千GB的内存以及大量的磁盘存储,租金仅6.96元,即使考虑暂时未开通的MapReduce计算费用,价格也非常低廉。
考虑到数据的安全性,可以将ODPS系统部署在电力专有云平台上,以保证数据的隔离。
[1] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4):927-935. Song Yaqi,Zhou Guoliang,Zhu Yongli.Present status and challenges of big data processing in smart grid[J].Power System Technology,2013,37(4):927-935.
[2] Williams J W,Aggour K S,Interrante J,et al.Bridging high velocity and high volume industrial big data through distributed in-memory storage & analytics[C]//IEEE International Conference on Big Data(Big Data),Washington,DC,USA,2014:932-41.
[3] Han Liangxiu,Ong H Y.Parallel data intensive applications using MapReduce:a data mining case study in biomedical sciences[J].Cluster Comput,2015,18(1):403-418.
[4] Agrawal D,Bernstein P,Bertino E,et al.Challenges and opportunities with big data[J].Proceedings of the VLDB Endowment,2012,5(12):2032-2033.
[5] Rob P,Sean D,Robert G,et al.Interpreting the data:parallel analysis with Sawzal[J].Scientific Programming,2005,13(4):277-298.
[6] Tom White.Hadoop权威指南[M].2版.曾大聃,周傲英,译.北京:清华大学出版社,2011:260-262.
[7] Zhao Yong,Hategan M,Clifford B,et al.Swift:fast,reliable,loosely coupled parallel computation[C]//2007 IEEE Congress on Services,Salt Lake City,UT,USA,2007:199-206.
[8] Beynon M D,Kurc T,Catalyurek U,et al.Distributed processing of very large datasets with DataCutter[J].Parallel Computing,2001,27(11):1457-1478.
[9] LINQ:The LINQ project[EB/OL].2014-04-19.http://msdn.microsoft.com/netframework/future/linq/.
[10]Microsoft Research.Dryad[EB/OL].2013-12-23.http://research.microsoft.com/en-us/projects/Dryad/.
[11]Teradata.Teradata homepage[EB/OL].2013-12-23.http: //www.teradata.com/.
[12]Vertica.Vertica homepage[EB/OL].2013-12-23.http: //www.vertica.com/.
[13]Amazon.Amazon homepage[EB/OL].http://aws.amazon.com/cn/.
[14]Aliyun.大数据计算服务ODPS[EB/OL].http://www.aliyun.com/.
[15]宋亚奇,周国亮,朱永利,等.云平台下输变电设备状态监测大数据存储优化与并行处理[J].中国电机工程学报,2015,35(2):255-267. Song Yaqi,Zhou Guoliang,Zhu Yongli,et al.Storage optimization and parallel processing of condition monitoring big data of transmission and transforming equipment based on cloud platform[J].Proceedings of the CSEE,2015,35(2):255-267.
[16]Ma Yan,Guo Zhihong,Chen Yufeng,et al.Multi-sourced data storage and index construction for equipment condition assessment[C]//The 6th International Conference on Computational Intelligence and Communi-cation Networks,2014:681-685.
[17]葛磊蛟,王守相,王尧,等.多源异构的智能配用电数据存储处理技术[J].电工技术学报,2015,30(增刊2):159-168. Ge Leijiao,Wang Shouxiang,Wang Yao,et al.Storage and processing technology of the multi-source isomerized data for smart power distribution and utilization[J].Transactions of China Electrotechnical Society,2015,30(S2):159-168.
[18]Kawasoe S,Igarashi Y,Shibayama K,et al.Examples of distributed information platforms constructed by power utilities in Japan[C]//44th International Conference on Large High Voltage Electric Systems,Paris,France,2012:108-113.
[19]宋亚奇,周国亮,朱永利,等.云平台下并行总体经验模态分解局部放电信号去噪方法研究[J].电工技术学报,2015,30(18):213-222. Song Yaqi,Zhou Guoliang,Zhu Yongli,et al.Research on parallel ensemble empirical mode decomposition denoising method for partial discharge signals[J].Transactions of China Electrotechnical Society,2015,30(18):213-222.
[20]屈志坚,郭亮,刘明光,等.智能配电网量测信息变断面柔性压缩新算法[J].中国电机工程学报,2013,33(19):191-199. Qu Zhijian,Guo Liang,Liu Mingguang,et al.New variable section flexible compression algorithm for measurement information in intelligent distribution network[J].Proceedings of the CSEE,2013,33(19):191-199.
[21]曲广龙,杨洪耕,张逸.采用Map-Reduce模型的海量电能质量数据交换格式文件快速解析方案[J].电网技术,2014,38(6):1705-1711. Qu Guanglong,Yang Honggeng,Zhang Yi.A fast parallel parsing scheme for massive PQDIF files with map-reduce model[J].Power System Technology,2014,38(6):1705-1711.
[22]周国亮,朱永利,王桂兰,等.实时大数据处理技术在状态监测领域中的应用[J].电工技术学报,2014,29(增刊1):432-437. Zhou Guoliang,Zhu Yongli,Wang Guilan,et al.Real-time big data processing technology application in the field of state monitoring[J].Transactions of China Electrotechnical Society,2014,29(S1):432-437.
[23]张少敏,赵硕,王保义.基于云计算和量子粒子群算法的电力负荷曲线聚类算法研究[J].电力系统保护与控制,2014,42(21):93-98. Zhang Shaomin,Zhao Shuo,Wang Baoyi.Research of power load curve clustering algorithm based on cloud computing and quantum particle swarm optimization[J].Power System Protection & Control,2014,42(21):93-98.
[24]刘巍,黄曌,李鹏,等.面向智能配电网的大数据统一支撑平台体系与构架[J].电工技术学报,2014,29(增刊1):486-491. Liu Wei,Huang Zhao,Li Peng,et al.Summary about system and framework of unified supporting platform of big data for smart distribution grid[J].Transactions of China Electro technical Society,2014,29(S1):486-491.
[25]金亮,邱运涛,杨庆新,等.基于云计算的电磁问题并行计算方法[J].电工技术学报,2016,31(22):5-11. Jin Liang,Qiu Yuntao,Yang Qingxin.A parallel computing method to electromagnetic problems based on cloud computing[J].Transactions of China Electro-technical Society,2016,31(22):5-11.
[26]Nobuyuki O.A threshold selection method from gray-level histograms[J].IEEE Transactions on Systems,Man and Cybernetics,1979,9(1):62-66.
[27]Chang Wen-Yeau.Partial discharge pattern recognition of cast resin current transformers using radial basis function neural network[J].Journal of Electrical Engineering & Technology,2014,9(1):293-300.
[28]Cover T,Hart P.Nearest neighbor pattern classification[J].IEEE Transcations on Information Theory,1967,30(1):21-27.
(编辑 张玉荣)
Storage and Parallel Processing of Big Data of Power Equipment Condition Monitoring on ODPS Platform
ZhuYongliLiLiSongYaqiWangLiuwang
(School of Control and Computer Engineering North China Electric Power University Baoding 071003 China)
Computing performance is one of the key issues existing in the applications of big power data,such as fault diagnosis and prediction.Distributed storage and parallel computing are currently as the effective measures to accelerate the data-intensive applications.This paper describes an open distributed processing service(ODPS)from Ali Cloud,is used to store and accelerate the analytic process of monitoring big data about electrical equipment.Taking the phase resolved partial discharge(PRPD)processing of a partial discharge(PD)signal as example,a method for storing the signal with high sampling rate and time series data,and extracting the feature of the signal through the extended MapReduce model(MR2)of ODPS is proposed in this paper.The paralleled PRPD procedure(ODPS-PRPD)implements amounts of PD signals parallel basic parameters calculation and discharge type recognition,statistics features.To verify the effectiveness of the proposed method,a large number of partial discharge signals of four types from laboratory tests are respectively analyzed on ODPS and Hadoop.Because ODPS-PRPD stores the large amounts of middle data in the primary memory,its computing procedure is much faster.The results show that ODPS-PRPD has obviously better performance in data reliabltity,service anailabilty and cost than that of Hadoop.
Big power data,public cloud,open distributed processing service(ODPS),extended MapReduce model(MR2),partial discharge,phase resolved partial discharge
国家自然科学基金项目(51677072)、河北省自然科学基金项目(F2014502069)和中央高校基本科研业务费专项资金(2016MS116,2016MS117)资助。
2016-04-18 改稿日期2016-08-02
TM764
朱永利 男,1963年生,教授,博士生导师,研究方向为网络化监控与智能信息处理。
E-mail:yonglipw@163.com(通信作者)
李 莉 女,1980年生,博士研究生,研究方向为现代信号处理方法在电力系统故障诊断等方面的应用。
E-mail:haolily12@163.com
猜你喜欢
民用飞机设计与研究(2020年4期)2021-01-21 09:15:02
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子制作(2018年18期)2018-11-14 01:48:24
中学生数理化·高一版(2017年9期)2017-12-19 12:15:15
西安工程大学学报(2016年6期)2017-01-15 14:09:28
山东工业技术(2016年15期)2016-12-01 05:31:22
现代防御技术(2016年1期)2016-06-01 12:13:27
中国中医药现代远程教育(2014年11期)2014-08-08 13:23:44
