
一种改进的短文本流主题演化模型
2017-05-16 08:28:08赵晓东柳先辉
网络安全与数据管理 2017年8期
林 特,赵晓东,柳先辉
(同济大学 电子与信息工程学院,上海 201804)
一种改进的短文本流主题演化模型
林 特,赵晓东,柳先辉
(同济大学 电子与信息工程学院,上海 201804)
在线主题模型基于先时间离散后主题建模的思想,存在文本流切分带来的模型无法平滑过渡的问题,同时时间片大小的选择对在线话题的抽取质量影响显著。提出了一种新的在线短文本流主题演化模型Online-BTOT。模型在遗传计算方法上进行了改良,不仅考虑时间片上的总体主题强度对遗传权重的影响,也将时间片上主题强度的变化纳入先验参数的计算中。同时,为了得到主题强度在时间片上的连续变化和克服短文本的稀疏性,在单时间片上结合了TOT模型和BTM模型。通过在微博短文本语料上与OLDA模型和OBTM模型的对比实验,证明Online-BTOT模型能够有效地分析在线短文本流的主题演化。
主题演化;短文本;Online-BTOT;主题模型
0 引言
随着互联网愈发倾向移动化,新的信息交互方式,比如微博、微信、朋友圈,公众号等社交网络和自媒体已成为公众日常生活须臾不可离的一部分。新的交互方式塑造了轻量化和高频率的新形式的移动交互语言——短文本。短文本规模庞大,基于其上的话题演化分析能够有效地从冗杂的文档集中提取话题按时间顺序的发展演化过程,从而帮助公众分析话题在强度和内容上随时间的变化。因此,短文本的话题演化研究具有重要的应用背景。
近年来,概率主题模型在文本挖掘领域受到广泛的关注和研究。BLEI D M等人提出的LDA(Latent Dirichlet Allocation)模型[1]基于词袋假设,认为文档是由特定的隐含主题序列生成的,奠定了主题模型的基础。本质上,传统的主题模型在主题抽取方面隐式基于文本层面的词共现现象。然而,短文本在文本层面上的稀疏性致使传统的主题模型在短文本的隐含主题抽取的准确性普遍不高。为了克服稀疏性, Yan Xiaohui等人提出的BTM(Biterm Topic Model)模型[2]通过显式地对共现词对建模,同时将文本层面的词共现现象扩大到整个文本集层面,从而克服了短文本的稀疏性,主题抽取的准确性较传统主题模型有显著提高。
借助主题模型,通过引入时间信息,研究话题随时间的演化,是当前主题演化的研究热点。研究者们提出的方法大致分为两类。一是先主题抽取后离散,反映主题在时间上的强度变化的TOT(Topic Over Time)模型[3]和记录主题内容和强度演化信息的DTM(Dynamic Topic Model)模型[4]都属于此范畴,由于需要全局建模,不适合在线文本流分析。二是按时间先离散,OLDA(Online-LDA)模型[5]通过遗传计算的方法将历史分布作为当前时间片的先验参数,从而具备在线处理的能力。但时间片大小的选择、遗传权重的确定对话题抽取质量影响显著。
针对短文本的稀疏性问题和在线主题模型存在的问题,本文采用按时间先离散方法的同时在每个时间片上引入每篇文本的时间信息,结合BTM和TOT模型的思想建模主题强度在时间片上的连续变化,从主题强度和主题强度变化两方面改善在线主题模型在主题遗传度上的计算方法。
1 相关工作
1.1 BTM模型
BTM模型由Yan Xiaohui等人提出,基于共词频率愈大愈倾向于同一个主题的思想,不同的是,模型模拟词对的产生过程,通过整合整个文档集的词对克服文本稀疏性。假设α和β是模型的Dirichlet先验。文本集词对的产生过程可以描述如下:
(1)对于每个主题,从参数β的Dirichlet分布中采样φk~Dir(β),采样K次;
(2)对于整个文本集,从参数α的Dirichlet分布中采样θ~Dir(α),采样1次;
(3)对于每个词对b,从θ多项分布中采样词对主题z~Multi(θ),从φk多项分布中采样两个词wi和wj。
1.2 OLDA模型
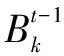
(1)
历史信息的遗传使各个时间片中推断出的主题可以自动对齐,同时通过DJS距离度量算法:
(2)
计算邻近时间片上的主题相似度,从而发现新主题。
2 改进的短文本流主题演化模型
2.1 Online-BTOT模型
单时间片上,模型隐含主题的抽取不仅受词共现的影响,还受到时间戳信息的影响。文本时间戳信息是连续的,为了避免离散化,时间戳信息将被标准化以满足0~1上的Beta分布。模型模拟了短文本集中词对和时间戳的产生过程。模型的概率图模型如图1所示。
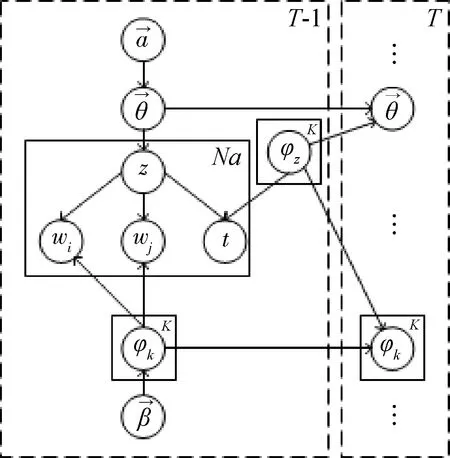
图1 Online-BTOT概率图模型
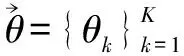
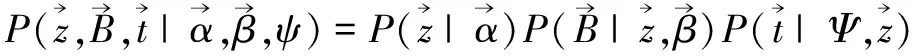
(3)
2.2 参数估计
(4)
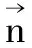
(5)
(6)
(7)
(8)
2.3 遗传计算
为了将历史文本估计得到的主题强度和主题强度的变化都作为先验知识纳入到当前时间片的先验参数计算中,本文提出了一种新的采用积分形式的遗传权重计算方法,概率图模型如图1所示。
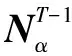
(9)
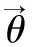
(10)
(11)
3 实验
本文通过抓取2015-11-12至2015-11-19新浪微博平台上的总计6 051 518条微博作为话题演化和分析的实验数据集。以OLDA和OBTM(Online-BTM)两种主题演化模型作为参照,对本文提出的模型的有效性进行验证。OBTM采用了Yan Xiaohui的开源代码,OLDA采用了GibbsLDA++的开源实现。实验均在搭载OS X系统,配置4 GB内存和Intel Core i5 1.5 GHz CPU的硬件环境下进行。实验参数K通过调优,选取50,初始值设定为50/K,β初始值设定为0.005,Gibbs采样迭代频次设定为100次,遗传系数λ取经验值0.6,同时Online-BTOT的遗传窗口设定为4。
预处理阶段:以1天为时间单元切分数据集,通过nlpir分词工具对微博做分词处理,过滤@开头的词和停用词,然后过滤词数<2的微博,经过上述处理后再去除语料中总词频<10的词,最后再次过滤词数<2的微博。通过预处理,有效微博数减少至5 441 333条,平均每天微博数量为680 166条。
3.1 话题抽取的准确性
本文采用了主题关联性指标Topic Coherence[6]衡量主题的准确性。直观得,如果一组词属于同一个话题,那么在同一篇文档中,它们共现的频次相应地会较高。Topic Coherence正是基于这个思想,定义如下:
(12)
其中D(v)表示词v至少出现了一次的文档频次,D(v,v′)表示词v和词v′同时至少出现了一次的文档频次,V(t)表示主题下t最可能出现的前M个词组成的列表。Topic Coherence指标越大,话题的准确性越高。
为了评估所有K个主题的话题准确性,每个时间片上三种模型均取K个Topic Coherence指标的均值:
(13)
实验取M=5,计算得到的Topic Coherence均值如图2所示。
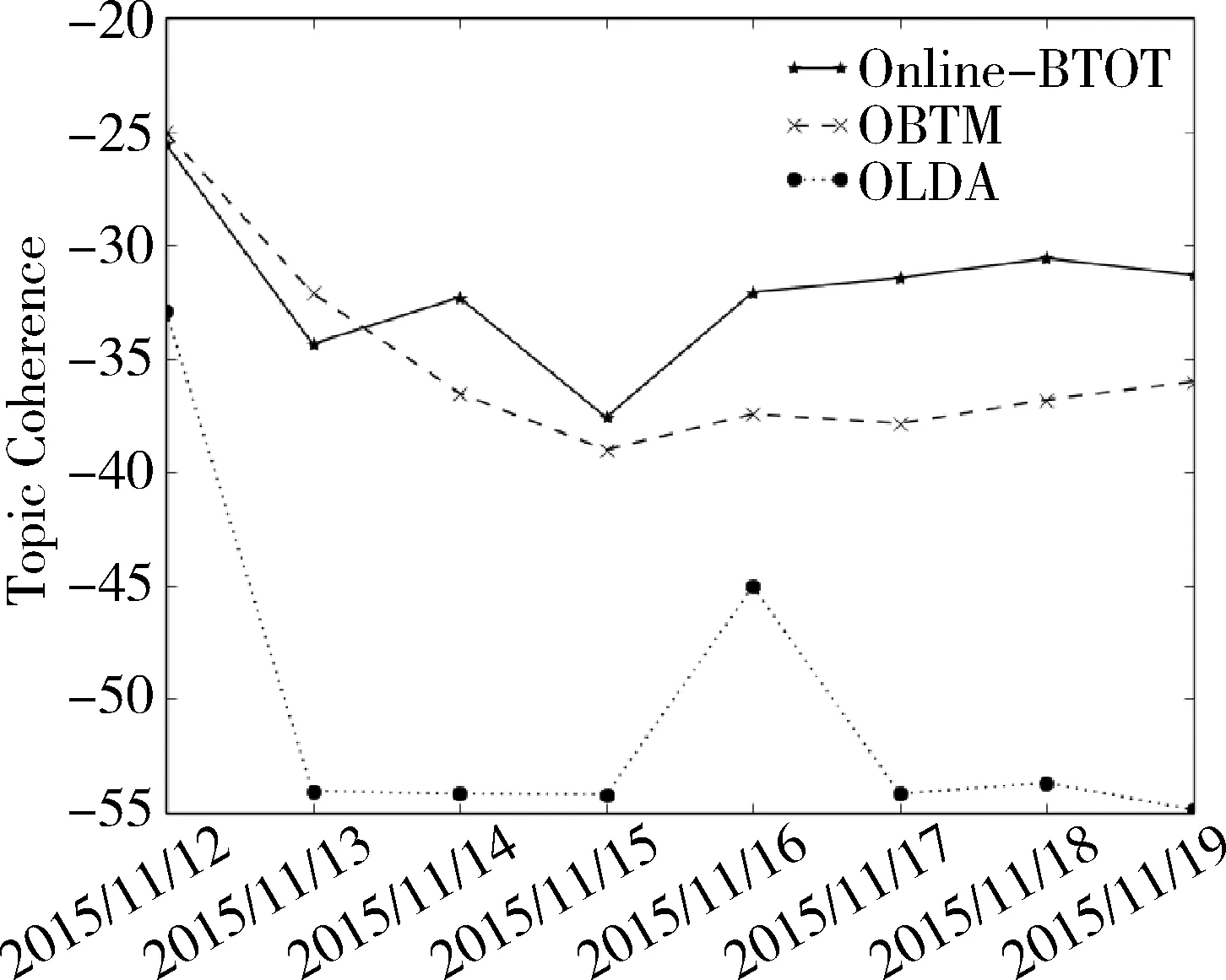
图2 主题关联性指标Topic Coherence均值(K=50, M=5)
实验结果与定性分析预期的结果一致,OLDA由于稀疏性,对于短文本的话题抽取准确性要明显低于OBTM模型和Online-BTOT模型,同时随着时间推移,Online-BTOT模型的准确性普遍高于OBTM模型,这得益于Online-BTOT模型在切面上的平滑过渡和遗传计算方法上的改良。
3.2 话题内容演化
同一个话题随着时间的推进,话题的侧重点会有所偏移,反映到主题模型上,就是主题-词概率分布会发生变化。表1展示了巴黎恐袭子话题IS极端组织话题在连续时间片上的概率最高的前10个词。可以看到IS极端组织话题开始时与巴黎恐袭关联,在17日开始与俄罗斯空难关联,在19日开始与中国公民被绑架杀害关联。

表1 IS极端组织话题14日至19日话题内容演化
通过Jensen-Shannon距离公式计算主题之间的关联度,可以定量分析话题在内容上的演化。图3所示为Online-BTOT模型从2015-11-12日开始#5主题相邻时间片的主题距离计算结果。可以看到14日的主题距离明显高于其他时间点,此时主题发生了变化(出现了巴黎公布袭击事件)。同时可以看到在17日和19日主题距离有小幅的增长,正好对应了前面提到的话题在内容上的演化。
4 结论
Online-BTOT模型通过引入主题强度在时间片上的变化特征优化在线主题模型的遗传权重计算,同时在单时间
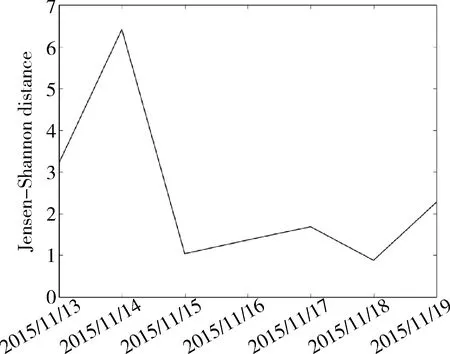
图3 相邻时间片#5主题Jensen-Shannon距离变化
片上引入时间信息参与主题建模,提高了话题抽取的准确度,有效改善了时间片大小选择不当和文本流切分造成的在线话题抽取质量不高的问题。模型基于Gibbs采样算法,如何将模型拓展到多线程环境是下一步要努力的方向。
[1] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3): 993-1022.
[2] Yan Xiaohui, Guo Jiafeng, Lan Yanyan, et al. A biterm topic model for short texts[C].Proceedings of the 22nd International Conference on World Wide Web, ACM, 2013: 1445-1456.
[3] Wang Xuerui, MCCALLUM A. Topics over time: a non-Markov continuous-time model of topical trends[C].Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2006: 424-433.
[4] BLEI D M, LAFFERTY J D. Dynamic topic models[C].Proceedings of the 23rd International Conference on Machine Learning,ACM, 2006: 113-120.
[5] AlSUMAIT L, BARBARD, DOMENICONI C. On-line LDA: adaptive topic models for mining text streams with applications to topic detection and tracking[C].2008 Eighth IEEE International Conference on Data Mining,IEEE,2008: 3-12.
[6] MIMNO D, WALLACH H M, TALLEY E, et al. Optimizing semantic coherence in topic models[C].Proceedings of the Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2011: 262-272.
An improved model of topical evolution for short texts
Lin Te,Zhao Xiaodong,Liu Xianhui
(College of Electronics and Information, Tongji University, Shanghai 201804, China)
Online topic model based on pre-discretizing method has smooth transition problem brought by cutting text streams and time-slice selection has significant influences on the quality of topics discovered. In this paper, we propose a novel model for modeling topics evolution in online short text streams, referred as Online-BTOT. Online-BTOT is improved in topic genetic method, which not only blends the overall topic intensity into genetic weight calculation, but also considers the topic intensity fluctuation to calculate the priori-parameters. At the same time, in order to get the fluctuation of topic intensity and overcome the sparsity of short texts, Online-BTOT integrates TOT model and BTM model in single time-slice, and finally the Online-BTOT model is formed. By comparative experiments with OLDA model and OBTM model on micro-blog corpus, Online-BTOT is proved to be effective in analysis of topics evolution in online short text streams.
topic evolution; short texts; Online-BTOT; topic model
TP181
A
10.19358/j.issn.1674- 7720.2017.08.016
林特,赵晓东,柳先辉.一种改进的短文本流主题演化模型[J].微型机与应用,2017,36(8):48-50,55.
2016-10-28)
林特(1992-),男,硕士研究生,主要研究方向:主题模型。
赵晓东(1968-),男,硕士,高级工程师,主要研究方向:模型可视化。
柳先辉(1979-),男,博士,讲师,主要研究方向:数据挖掘。
________________________
猜你喜欢
区域治理(2022年40期)2022-11-27 04:01:54
建材发展导向(2021年10期)2021-07-16 07:13:40
动漫界·幼教365(小班)(2019年10期)2019-10-28 02:04:20
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
动漫界·幼教365(中班)(2019年10期)2019-10-28 01:53:17
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
疯狂英语(双语世界)(2016年3期)2016-02-27 10:11:55
管理现代化(2016年5期)2016-01-23 02:10:11
安徽医药(2014年4期)2014-03-20 13:13:04
