
一种改进的面向移动数据安全检测的文本分类模型*
2017-05-16 08:27冯晓荣麦松涛
网络安全与数据管理 2017年8期
冯晓荣,林 军,麦松涛
(工业和信息化部电子第五研究所 软件质量工程研究中心,广东 广州 510610)
一种改进的面向移动数据安全检测的文本分类模型*
冯晓荣,林 军,麦松涛
(工业和信息化部电子第五研究所 软件质量工程研究中心,广东 广州 510610)
随着移动互联网应用的不断普及,移动终端承载了大量的数据交互业务与应用,移动数据的安全问题日益凸显。基于C4.5决策树算法对移动数据进行文本分类检测,实现恶意代码分析。传统的C4.5文本分类模型中,测试属性选择未考虑属性之间的影响,因此提出了一种改进的基于Boosting算法的C4.5决策树文本分类模型。该模型在衡量被测属性最优弱假设的重要性时,引入Boosting的权重系数,每次迭代计算结束后,自适应调整权重值,在降低特征子集属性冗余度的同时,提高了分类模型的鲁棒性。实验结果表明,改进的文本分类模型在检测率和分类准确率上均有一定程度的提高。
恶意代码;文本分类;C4.5决策树;Boosting算法
0 引言
近年来,随着移动互联网、物联网、云计算、大数据技术的迅猛发展,全球数据量呈现爆发式增长。由于移动终端承载了大量的数据交互业务与应用,移动数据的安全问题日益凸显,移动终端设备也成为攻击者的主要目标之一。如何在海量数据中对安全威胁进行快速识别与分类,成为当前信息安全研究亟待解决的问题。
移动终端是大量互联应用与服务的承载体,目前主要通过对移动终端设备安全能力检测及移动应用程序的恶意行为检测来实现数据安全保障。然而,这些安全防护方法都存在较大的局限性,基于移动终端设备的安全能力检测一般局限于移动终端系统本身,而移动应用程序的检测主要采用病毒库的特征匹配,需要随时更新病毒库,无法满足移动大数据应用的多样性和实时动态特性。
在移动互联网应用背景下,针对移动数据应用的主要攻击是面向移动终端设备,包括窃取移动终端上的信息、远程控制移动设备等,其中,大量恶意攻击行为通过HTTP请求实现。例如,在移动终端通过HTTP访问请求注入SQL语句恶意代码,实现DNS欺骗、ARP欺骗,窃取用户敏感信息。在服务器端通过HTTP传递请求内容的方式将用户敏感信息上传至服务器,泄露大量隐私数据。
在大数据应用环境下移动终端数据的信息安全检测中,机器学习主要应用于解决数据分类问题、知识表示及规则提取、搜索问题和增强学习等方面。其中,利用机器学习技术解决数据的分类,区分异常数据和正常数据,为移动大数据的分析提供前提条件。
本文根据已有的参考文献中提出的主流文本分类算法的特征[1],结合移动数据的特性,综合考虑各种算法在移动数据分析中的优缺点和局限性,提出了一种基于AdaBoost思想的改进型C4.5决策树文本分类模型,通过对HTTP请求数据的特征属性进行选择、特征向量化,形成训练样本和测试样本,输入到分类算法中进行模型训练、文本分类和结果验证,从查准率、误检率和准确率三个方面进行比较分析,为今后的文本分析研究提供理论基础。
1 C4.5决策树算法
1.1 特征提取
在机器识别分类算法实现中,数据特征向量化是前提条件。对于一个特征集F={f1,f2…,fn},描述特征子集的二进制向量为S={S1,S2…,Sn},其中Si∈{0,1},i=1,2,…,n。Si=1表示第i个特征被选择,Si=0表示第i个特征未被选择[2]。由于特征集中包含很多冗余特征与不相关特征,导致数据属性的维度增加,提高了数据计算的时间复杂度和空间复杂度,降低了分类模型的泛化能力。通过过滤的方法进行特征选择,选择出与类别相关性最大且具有最小冗余特征的子集,从而达到最优分类效果。
1.2 C4.5决策树基本原理
基于机器学习的文本分类方法是将数据根据预先定义的类别,按照一定的规则进行自动化分类,实现数据挖掘。在移动互联网环境下,使用文本分类算法对移动数据进行安全检测,将移动终端本身及移动应用的安全威胁进行有效分类,能够自适应地学习正常数据和异常数据行为模式,从而涵盖更大的安全检测范围,具有重要的研究意义。
在机器学习中,决策树作为一个分类预测模型,代表对象属性与对象值之间的映射关系。树中的每个节点代表某个对象,每个分叉路径代表某个可能的属性值,每个叶节点对应从根节点到该叶节点所经历的路径所表示的对象值,基于数据产生决策树的机器学习方法依托于分类、训练上的预测树,根据已知预测归类未知数据。决策树是一种多级分类的思想,目前已有的算法包括ID3、C4.5、CART算法等[3]。ID3是决策树基础算法,自顶向下地贪婪搜索遍历可能的决策树空间构造决策树,使用统计测试确定每一个实例单独分类训练样例的能力,分类能力最好的属性作为判定树根节点的测试属性。基于C4.5决策树算法建立在ID3算法的基础上,用信息增益率选择特征属性,解决多值偏向问题。在树构造过程中进行剪枝,完成对连续属性的离散化处理以及对不完整属性的处理能力和产生规则等功能。
根据已有的ID3算法,基于信息增益的基本原理,C4.5算法通过计算信息增益率,选取信息增益比最高的属性作为样本的测试属性,创建一个节点并为每个属性创建分支划分样本[4]。
2 改进的安全检测文本分类模型
2.1 C4.5决策树改进算法
C4.5决策树算法根据信息增益率选择属性,从一个无次序、无规则的实例中归纳一组采用树形结构表示的分类规则。信息增益率为信息增益和分割信息量的比值,信息增益越大,则类属性对该属性的依赖性越大,因此,该属性作为测试属性的期望值越大。
假设以属性A的值为基准对样本分割,训练数据D用分裂信息SplitInfo作为初始信息量划分成对应于属性A的有m个输出的m个划分信息。属性A具有n个不同的取值{a1,a2,…,an},如果用属性A将样本集S划分为{S1,S2,…,Sn}共n个子集,则属性A对S进行划分的信息增益率为:
(1)
其中,
(2)
最佳属性子集能够对分类预测产生最好的效果,子集中的属性与类属性关联度最大,同时属性之间的冗余度相对较小。C4.5算法考虑了属性与类属性的关联度,但是属性之间的关系尚未考虑。特别是对于数据属性及其取值较多的情况,不同属性之间可能存在一定的联系,若属性之间的关联度过高,属性的冗余度过大,则会影响属性子集的有效性,导致系统鲁棒性较差。
在该改进的算法模型中,将属性与其他属性之间的关联度引入属性A的信息增益率度量。属性A与其他属性之间的信息增益如式(3)所示:
Gain(AF)=∑f∈F(H(A)-H(A|f))
(3)
其中,Gain(AF)为其他属性对属性A的信息增益之和,表示属性A与其他属性的关联度;F是不包含属性A的非类属性集合;f是非类属性且f∈F。式(4)表示其他属性对属性A的信息增益平均值。
(4)
在已有的信息增益率的基础上,通过引入其他属性对被选属性信息增益的均值,降低其他属性与备选属性之间的冗余度。改进后的信息增益率如式(5)所示,其中,w是权重系数。
(5)
在改进的信息增益率计算过程中,若备选属性A与其他属性的关联度较差,其他属性对属性A的信息增益平均值较低,该属性的信息增益率会增加,则被选定作为类属性的子属性的可能性会更大。
对于权重系数w,在形成的初始训练序列后,基于AdaBoost思想,对每个训练样本赋予相同的初始权重,在迭代递归过程中动态调整权重系数,根据权重系数构造训练集。权重系数w衡量备选属性最优弱假设的重要性,在每次迭代计算结束后,对分类错误的样本增加权重,使得在下一次迭代中更关注分类错误的样本,利用不同的训练集构造多个分类模型,通过综合打分得到优化的分类结果。在降低特征子集属性冗余度的同时,提高了分类模型的鲁棒性。
权重系数的确定及样本训练过程如下:
输入:训练数据集T,样本数n,迭代次数m;
输出:决策树序列G(x);
训练流程如下:
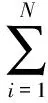
(1)初始化训练数据的权重:
D1={w11,w12,…,w1N}
(6)
其中,
(7)
(2)对于m=1,2,…,M,使用具有权值分布Dm的训练数据集基于改进的C4.5决策树进行学习,得到弱分类器。
(3)计算Gm(Ti)在训练数据集上的分类误差率:
(8)
(4)计算弱分类器Gm(t)的系数:
(9)
(5)更新训练数据的权值分布:
Dm+1=(wm+1,1,wm+1,2,…,wm+1,N)
(10)
(6)将m个弱分类器进行线性组合,得到最终分类器:
(11)
2.2 改进的安全检测文本分类模型
针对HTTP请求的移动数据安全检测文本分类模型如图1所示,检测流程包括以下几个步骤:
(1)以每个请求数据包为文本单位,将已分类的数据集分为训练数据和测试数据;
(2)数据特征选择及数据特征向量化,转化为可供机器学习的训练样本和测试样本;
(3)利用训练数据集对改进的文本分类算法模型进行训练,建立分类模型,输入测试数据,输出检测数据类别。

图1 改进的移动数据安全检测文本分类模型
3 实验与结果分析
3.1 实验数据集
文中采用HTTP请求进行模型验证分析。在移动互联网应用环境中,通过HTTP请求实现Web攻击是一种常见的攻击方式,包括SQL注入、跨站脚本攻击、Cookie篡改等恶意行为特征[5-6]。HTTP请求分为正常和异常两个类别,根据HTTP请求的数据格式和恶意特征分析,从数据结构、长度、字符等方面提取大量特征,使用基于相关的属性选择算法(CFS)对基础数据进行属性选择,再使用本文提出的改进的文本分类算法选择属性子集,对实验数据集进行分类,比较分类结果的正确率。
原始数据为CSIC2010的原始数据包,保留有效TCP数据包,过滤得到HTTP请求数据。HTTP请求格式包含请求方法URL协议/版本、请求头(Request Header)、请求正文等数据。将HTTP结构化数据部分保存为特征文本,同时,将请求内容、path和Cookie等半结构化的内容进行结构化处理。已有研究基础表明,请求内容、访问路径和Cookie一般是恶意特征集中表现位置[7]。参考KDDCUP1999数据集在安全检测方面的特征要求[8],选取长度、键值对数等有效信息保存为结构化文本数据。为了提高分类效率,首先对文本数据进行属性选择,属性集搜索算法选用Best-first Search,属性集评估算法选用CFS,提取HTTP请求的15个特征描述数据内容。具体特征如表1所示。
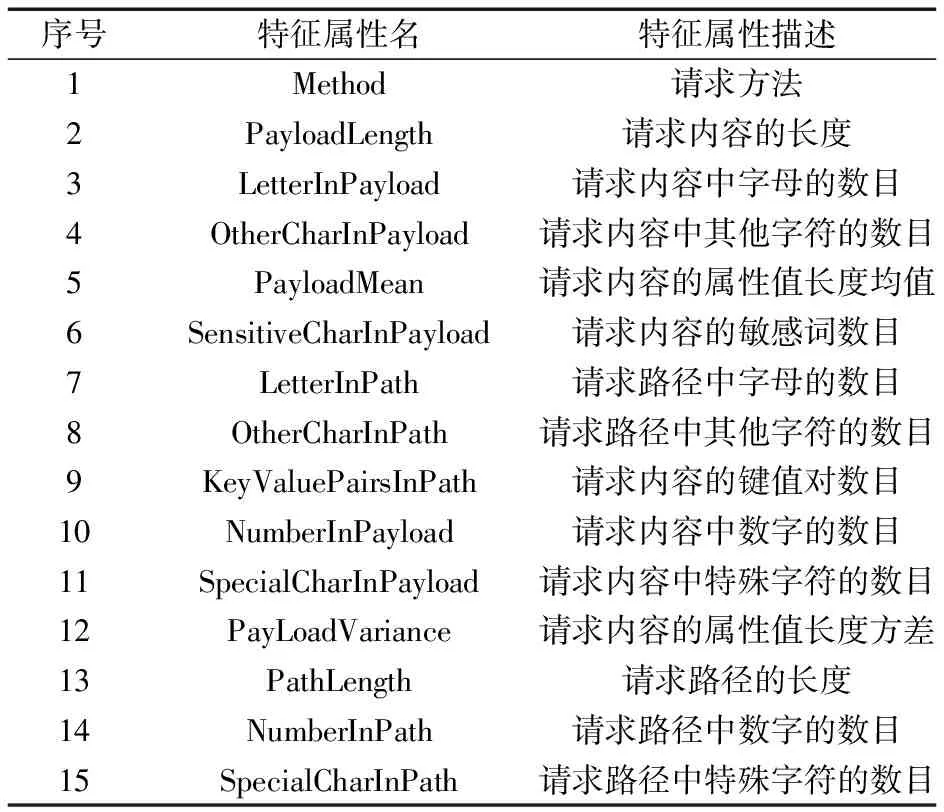
表1 数据集特征描述
3.2 评估策略
将数据包划分为正常数据和恶意数据两类,数据向量特征化之后将目标数据输入到分类算法中进行模型训练、分类测试和准确率验证。实验平台使用WEKA,迭代次数设为10次,建立10棵决策树,采用10折交叉验证。
文本分类结果使用信息检索中的查准率(TP)、误检率(FP)和分类准确率(ACC)来衡量改进算法的效果[9]。
其中:
查准率=正确分类的HTTP恶意请求个数/HTTP恶意请求总数
误检率=正常HTTP请求被误判为恶意请求的个数/正常HTTP请求总数
分类准确率=正确分类的样本数/所有测试样本数
3.3 结果分析
实验数据采用CSIC2010数据集,选取36 878条正常HTTP请求和24 668条包含恶意代码的异常HTTP请求。通过Best-first Search属性集搜索算法和CFS属性集评估算法,提取HTTP请求的15个特征描述数据内容。在选择的15个属性集上分别选用C4.5决策树算法和改进的C4.5决策树算法训练样本数据,建立分类模型。
3.3.1 小规模样本测试
为验证文中提出的改进算法的分类效率,首先进行小批量实验数据验证,选择样本数据集包含正常HTTP请求500个,异常HTTP请求500个。分类结果如表2所示。

表2 小规模样本分类结果
表2结果显示,基于AdaBoost思想的C4.5决策树分类模型适用于HTTP恶意请求检测,针对于传统的C4.5检测算法,检测率和分类准确率指标均有所改善,其中,查准率提高了1.9%,误检率降低了3.8%,分类准确率提高了2.9%。由于改进模型中增加了Boosting自适应调整权值系数过程,导致分类时间增加了12.2 ms。
3.3.2 总体样本测试
采用上述方法选取所有异常样本和正常样本HTTP请求的属性值,输入算法模型,对比C4.5算法和改进后的C4.5算法在数据集上的分类准确率,结果如表3所示。

表3 总体样本分类结果
表3结果显示,改进的C4.5文本分类模型查准率提高了1.6%,误检率降低了0.8%,分类准确率提高了1.7%,分类时间增加了45 ms。在保证分类时间影响较小的前提下提高了分类准确度。
4 结论
针对移动数据HTTP请求的恶意代码特征,本文分析了传统C4.5算法未考虑属性间影响、属性间冗余度较大、从而导致算法复杂度较高的问题,提出了一种基于AdaBoost算法的C4.5文本分类模型,并对模型进行优化和改进。通过对文本数据的特征属性进行选择并通过特征向量化形成训练样本和测试样本,输入到分类算法中进行模型训练、文本分类和结果验证,从查准率、误检率和准确率三个方面进行比较分析。实验结果证明,改进的C4.5算法具有较好的分类效果,对今后移动数据安全检测研究中分类算法的选取具有一定的理论研究和应用价值。
[1] 张福永,齐德昱,胡镜林. 基于C4.5决策树的嵌入型恶意代码检测方法[J]. 华南理工大学学报(自然科学版),2011,39(5):68-72.
[2] 陈祎荻,秦玉平, 基于机器学习的文本分类方法综述[J]. 渤海大学学报(自然科学版), 2010,31(2): 201-205.
[3] 潘峰,基于C5.0决策树算法的考试结果预测研究[J].微型机与应用, 2016,35(8):72-74.
[4] 程骏,王健.面向移动数据安全检测的文本分类算法比较研究[J]. 无线互联科技, 2015(24):115-118.
[5] 魏浩,丁要军.一种基于属性相关的C4.5决策树改进算法[J], 中北大学学报(自然科学版),2014,35(4):402-406.
[6] SCHULTZ M G, ESKIN E, ZADOK E, et al. Data mining methods for detection of new malicious executables[C].IEEE Symposium on Security and Privacy,2001:38-49.
[7] LA POLLA M, MARTINELLI F, SAGANDURRA D. A survey on security for mobile devices[J]. Communications Surveys & Tutorials, IEEE,2013,15(1):446-471.
[8] STOLFO S J,Wang Ke,Li Weijen.Towards stealthy malware detection[M].Malware detection.Heidelberg:Springer-Verlag,2007:231-249.
[9] GARCIA S,FERNANDEZ A,HERRERA F. Enchancing the effectiveness and interpretability of decision tree and rule induction classifiers with evolutionary training set selection over imbalanced problems [J]. Applied Soft Computing,2009,9(4):1304-1314.
An improved text classification model for mobile data security testing
Feng Xiaorong, Lin Jun, Mai Songtao
(Software Quality Testing Engineering Research Center, China Electronic Product Reliability and Environmental Testing Research Institute, Guangzhou 510610, China)
With the popularity development of mobile Internet, intelligent terminals carry a large amount of data interactive business and application, thus mobile data security problem is increasingly highlighted. In the view of mobile data security detection, text classification model can be realized in the application layer to detect malicious attacks. Since traditional C4.5 decision tree has the disadvantage of no considering about interaction influence between properties in attribute selection, an improved model of C4.5 decision tree based on Boosting algorithm is put forward. The problem in measuring the properties of the optimal weak assumptions is to be solved by introducing the weight coefficient of Boosting, which would generate an adaptive adjustment weights at the end of each iteration calculation, so as to reduce the feature subset attribute redundancy and meanwhile, improve the robustness of the classification model. Experimental results illustrate that the proposed text classification model is superior to the traditional method in terms of detection rate and classification accuracy.
malware detection; test classification; C4.5 decision tree; Boosting algorithm
广东省省级科技计划项目(2015A030401023)
TP311
A
10.19358/j.issn.1674- 7720.2017.08.001
冯晓荣,林军,麦松涛.一种改进的面向移动数据安全检测的文本分类模型[J].微型机与应用,2017,36(8):1-4.
2016-11-29)
冯晓荣(1987-),女, 硕士,工程师,主要研究方向:计算机网络安全技术、移动互联网应用技术。
林军(1976-),男, 硕士,高级工程师,主要研究方向:移动通信、汽车电子等。
麦松涛(1989-),男, 硕士,工程师,主要研究方向:计算机网络安全、信息安全等。
________________________
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子制作(2016年1期)2016-11-07
