
基于关联规则挖掘算法的商场购物篮分析与建模仿真研究
2017-05-15 08:28李文娟
湖北第二师范学院学报 2017年2期
李文娟
(定西师范高等专科学校, 甘肃 定西 743000)
基于关联规则挖掘算法的商场购物篮分析与建模仿真研究
李文娟
(定西师范高等专科学校, 甘肃 定西 743000)
结合一个商场购物篮的数据集,通过理论分析、实例验证,介绍关联规则挖掘过程及Apriori算法,运用顶尖数据挖掘平台TipDM中的Apriori算法进行建模仿真实验,挖掘出商场购物篮事务集的强关联规则,为商场进行市场定位、商品定价、新商品采购等决策提供帮助,也对指导未来的超市商品分组布局与促销活动提供帮助。
支持度;置信度;关联规则挖掘;Apriori算法;建模仿真
商场以获得最大的销售利润为目的。了解顾客的购买习惯和偏爱,有助于他们制定正确的营销策略。只有对商场销售数据进行分析,才能了解顾客的购买特性,并根据发现的规律而采取有效的行动。只有分析商场销售商品的构成,才能发现不同类别商品的共同特征及规则,并进而通过这些规则对商场的市场定位、商品定价、新商品采购等进行决策。
1 关联规则挖掘
1.1 支持度和置信度
表1为一个购物篮的数据集,每一组数据ti表示不同的顾客一次在商场购买的商品集合。

表1 购物篮交易项目
假如有一条规则:奶酪→牛奶,那么同时购买奶酪和牛奶的顾客比例是1/7,而购买奶酪的顾客当中也购买了牛奶的顾客比例是1/4。这两个比例参数是很重要的衡量指标,在关联规则中分别称作支持度(Support)和置信度(Confidence)。支持度为1/7表示在所有顾客当中有1/7同时购买了奶酪和牛奶,它反映了同时购买奶酪和牛奶的顾客在所有顾客当中的覆盖范围;置信度为1/4表示在买了奶酪的顾客当中有1/4的人买了牛奶,它反映了可预测的程度,即顾客买了奶酪之后有多大可能性买牛奶。
在数据挖掘中,所有商品集合I={牛肉,羊肉,牛奶,奶酪,靴子,衣服}称作项目集合,每位顾客一次购买的商品集合ti称为一个事务,所有的事务T={ t1,t2,…,t7}称作事务集合,并且满足ti是T的真子集。一条关联规则是形如“A→B”的蕴含式,它满足:A,B是I的真子集,并且A和B的交集为空集。其中A称为前件,B称为后件。对于规则A→B,则有:
支持度P(A|B)=(A,B).count/T.count
(1)
置信度P(B|A)=(A,B).count/A.count
(2)
其中(A,B).count表示T中同时包含A和B的事务的个数,A.count表示T中包含A的事务的个数。对于支持度和置信度,需要正确地去看待这两个衡量指标。一条规则的支持度表示这条规则的可能性大小,如果一个规则的支持度很小,则表明它在事务集合中覆盖范围很小,很有可能是偶然发生的;如果置信度很低,则表明很难根据A推出B。根据条件概率公式:P(B|A)= P(A|B)/ P(A)可知,对于任何一条关联规则,置信度总是大于或等于支持度。
1.2 关联规则挖掘过程
关联规则挖掘总体过程主要包括两步:
(1)根据最小支持度找出事务集合T中所有的频繁项目集。
(2)由频繁项目集和最小支持度产生强关联规则。
如何迅速高效的找出T中所有频繁项目集,是关联规则挖掘的核心所在。关联规则挖掘总体过程如图1所示。

图1 关联规则挖掘总体过程
图1中T为输入的事务集合,第一步根据搜索算法找出频繁项目集,第二步的算法从频繁项目集中产生有用的关联规则,最后输出挖掘出的关联规则集合。用户可以通过指定支持度和置信度的最低阈值min_sup和min_conf,根据公式(1)和(2),要想找出满足条件的关联规则,首先必须找出这样的集合F=A∪B,它满足:
F.count/T.count≥min_sup
(3)
其中,F.count 是T中包含F的事务的个数,然后从F中找出这样的蕴含式A→B,它满足:
(A,B).count/A.count≥min_conf
(4)
1.3 关联规则挖掘算法
最著名的关联规则挖掘算法是Apriori算法,该算法使用一种称为逐层搜索的迭代方法,其中k-频繁项目集用于探索(k+1)-频繁项目集。首先,通过扫描事务数据库,累计每个项的计数,并收集满足最小支持度的项,找出1-频繁项目集,该集合记为L1。然后,使用L1找出2-频繁项目集,记为L2,使用L2找出L3,如此下去,直到不能再找到k-频繁项目集。找出每个Lk需要一次事务数据库的完整扫描。具体实现步骤如下:
步骤1 频繁项目集的生成过程。
首先要做的是找出1-频繁项目集,这个很容易做到,只要循环扫描一次事务集合统计出项目集合中每个元素的支持度,然后根据设定的支持度阈值进行筛选,即可得到1-频繁项目集。图2给出Apriori算法和它的相关过程的伪代码。

图2 挖掘关联规则发现频繁项集的Apriori算法
步骤2 在步骤1得出的频繁项目集中找出满足条件的关联规则。
一旦由步骤1生成满足条件的频繁项目集,就可以直接由它们产生强关联规则。根据公式(2),可以如下描述产生关联规则:
(1)对于每个频繁项目集l,产生l的所有非空子集。
1.4 Apriori算法实例验证
假如有项目集合I={牛奶I1,面包I2,薯片I3,果汁I4,奶酪I5},如表2所示,有事务集T。设定minsup=3/7,minconf=5/7。以Apriori算法为例来说明具体流程。

表2 事务数据库
1.4.1 生成频繁项目集
步骤1 生成1-频繁项目集。
{I1},{I2},{I3},{I4},{I5}
步骤2 生成2-频繁项目集。
根据1-频繁项目集生成所有的包含2个元素的项目集,任意取两个只有最后一个元素不同的1-频繁项目集,求其并集,由于每个1-频繁项目集元素只有一个,所以生成的项目集如下:
{I1,I2},{I1,I3},{I1,I4},{I1,I5}
{I3,I4},{I3,I5}
{I4,I5}
计算它们的支持度,发现只有{I1,I2},{I1,I3},{I1,I4},{I2,I3},{I2,I4}的支持度满足要求,因此求得2-频繁项目集:{I1,I2},{I1,I3},{I1,I4},{I2,I3},{I2,I4}。
步骤3 生成3-频繁项目集。
因为{I1,I2},{I1,I3},{I1,I4}除了最后一个元素以外都相同,所以求{I1,I2},{I1,I3}的并集得到{I1,I2,I3},{I1,I2}和{I1,I4}的并集得到{I1,I2,I4},{I1,I3}和{I1,I4}的并集得到{I1,I3,I4}。但是由于{I1,I3,I4}的子集{I3,I4}不在2-频繁项目集中,所以需要把{I1,I3,I4}剔除掉。然后再来计算{I1,I2,I3}和{I1,I2,I4}的支持度,发现{I1,I2,I3}的支持度为3/7,{I1,I2,I4}的支持度为2/7,所以需要把{I1,I2,I4}剔除。
同理可以对{I2,I3},{I2,I4}求并集得到{I2,I3,I4},但是{I2,I3,I4}的支持度不满足要求,所以需要剔除掉。因此得到3-频繁项目集:{I1,I2,I3}。
1.4.2 生成强关联规则
以3-频繁项目集为例,其生成关联规则的过程如下:
对于集合{I1,I2,I3},先生成1-后件的关联规则:
(I1,I2)→I3,置信度=3/4;(I1,I3)→I2,置信度=3/5;(I2,I3)→I1,置信度=3/3。(I1,I3)→I2的置信度不满足要求,所以剔除掉。因此得到1-后件的集合{I1},{I3},然后再以{I1,I3}作为后件。(I1,I3)→I2的置信度=3/5不满足要求,所以对于3-频繁项目集生成的强关联规则为:(I1,I2)→I3和(I2,I3)→I1。
2 建模仿真
2.1 建模工具
采用顶尖数据挖掘平台TipDM中的Apriori算法进行关联规则挖掘。TipDM平台能从各种数据源获取数据,建立各种不同的数据挖掘模型,能够满足各种复杂的应用需求。TipDM的典型应用场景包括:智能营销、模式识别、信用等级、故障诊断、风险评估、欺诈预警等。
2.2 模型输入
模型数据的输入有两部分:建模样本数据和建模参数,建模参数的设置见表3所示。

表3 Apriori关联规则建模参数
建模样本数据见表1和表4,为了说明问题,仅选择了部分样本进行建模。
表4 预处理后购买记录
2.3 仿真过程
建模仿真过程如图2所示。
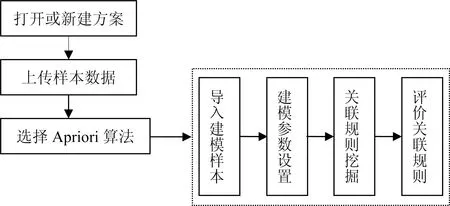
图2 仿真过程示意图
仿真过程说明如下:
(1)登录TipDM平台,在方案管理页面中,新建方案或者打开一个已建方案。
(2)切换到数据管理页面,上传客户消费样本数据文件。
(3)选择Apriori关联规则挖掘算法进行模型构建。
(4)对挖掘的关联规则进行分析。
2.4 结果及分析
当设置Apriori算法的最小置信度为0.9,增量为0.05,规则条数为10,显著性水平为-1.0,最小支持度下界为0.1,最小支持度上界为1.0时,产生的项集L(1)的大小为6,项集L(2)的大小为4,项集L(3)的大小为1,挖掘出来的强关联规则如表5所示。
3 结论
通过对以上购物篮数据进行分析,发现商品之间的相关性,对于指导未来的超市商品分组布局与促销活动提供了很大帮助,也为零售商进行市场定位、商品定价以及新商品采购等进行决策提供有力帮助。
[1]Jiawei Han,Micheline Kamber,Jian Pei.数据挖掘概念与技术[M].北京:机械工业出版社,2013:160-165.
[2]刘锡铃.关联规则挖掘算法及其在购物篮分析中的应用研究[D].苏州大学,2009.
[3]陈丽芳.基于Apriori算法的购物篮分析 [J].重庆工商大学学报(自然科学版),2014,31(5):84-89.
[4]李爱凤.基于数据挖掘技术的购物篮模式研究[J].计算机应用与软件,2011,(12):156-158.

表5 挖掘出来的强关联规则
[5]黄宏本,卢雪燕.关联规则挖掘在超市销售系统中的应用及实现[J].梧州学院学报,2011,(3):59-63.
[6]刘明会,韩朝.基于关联规则Apriori算法进行购物篮分析[J].中国商贸,2014,(9):17-20.
[7]朱龙.利润约束的关联规则挖掘算法[J].华侨大学学报(自然科学版),2015,36(5):522-526.
[8]李洪燕,万新.基于关联规则分析的产品销售推荐的应用[J].四川理工学院学报(自然科学版),2013,(2).
Analysis and Modeling Simulation Research of Shopping Basket Based on Association Rule Mining Algorithm
LI Wen-juan
(Dingxi Teachers College, Dingxi Gansu 743000, China)
To set the principles of market positioning, price commodifty, purchasing new commadities for a shopping malls, the process of association rules mining and Apricri alogrithm are used in the analysis of a shopping basket data set. The conclusion is also helpful to products layout and salse promotions.
support degree; confidence; association rule mining; Apriori algorithm; modeling and simulation
2016-12-30
定西师范高等专科学校校级项目(TD2016YB04)
李文娟(1984-),女,甘肃定西人,讲师,在读工程硕士,研究方向为大数据及数据挖掘算法。
TP31
A
1674-344X(2017)2-0066-04
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
河南水利年鉴(2020年0期)2020-06-09
机电产品开发与创新(2020年2期)2020-05-07
计算机应用(2018年5期)2018-07-25
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
信息通信技术(2015年6期)2015-12-26
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
