
基于Logistic增长神经网络模型的软件测试方法
2017-05-10 12:34魏霖静宁璐璐练智超王联国侯振兴
哈尔滨工程大学学报 2017年4期
魏霖静,宁璐璐,练智超,王联国,侯振兴
(1.甘肃农业大学 信息科学技术学院, 甘肃 兰州 730070; 2.南洋理工大学 生物科学学院,新加坡 639798;3.南京理工大学 计算机科学与工程学院,江苏 南京 210094; 4.南京大学 信息管理学院,江苏 南京 210093)
基于Logistic增长神经网络模型的软件测试方法
魏霖静1,宁璐璐2,练智超3,王联国1,侯振兴4
(1.甘肃农业大学 信息科学技术学院, 甘肃 兰州 730070; 2.南洋理工大学 生物科学学院,新加坡 639798;3.南京理工大学 计算机科学与工程学院,江苏 南京 210094; 4.南京大学 信息管理学院,江苏 南京 210093)
软件可靠性评估性能直接影响软件测试的工作量,本文针对软件测试工作中的故障检测和校正处理问题,提出一种基于Logistic增长神经网络的软件测试方法。该方法考虑到软件工程的多样性,利用Logistic增长曲线构建神经网络模型完成故障检测,并结合指数分布校正时间完成故障校正过程。通过两组真实失效数据集(Ohba与Wood)的试验,将所提方法与现有的软件可靠性增长模型(software reliability growth model,SRGM)进行了比较。结果显示Logistic增长神经网络模型的模型拟合效果最优,表现出了更好的软件可靠性评估性能及模型适应性。
软件测试;可靠性评估;神经网络;软件可靠性增长模型;Logistic曲线;Wood数据集; Ohba数据集;故障检测
软件开发领域中,软件测试已经引起了越来越多的关注。众所周知,软件可靠性直接影响着软件开发成本和软件质量[1-2]。软件可靠性增长模型(software reliability growth model,SRGM)为许多软件开发工作决策制定提供了必要的信息,比如说成本分析,测试时候的资源分配以及发布决策时间[3]。
软件可靠性增长模型目的在于解释软件测试过程中由于故障而产生的反应[4]。绝大部分现有的软件可靠性增长模型都是基于假设的故障检测过程,比如完美的调试排除障碍和直接的故障纠正,这在实际工作中是不准确的。在本文提出的模型中设有更加现实的假定从而运用改良的软件可靠性增长模型。
一般而言,不同的故障检测模式可能通过利用不同的非减性均值函数获得[5]。故障检测模式的选择基于对潜在软件故障数据的模式拟合优度[6]。SRGM广泛应用于软件系统的故障相关行为。如指数型非齐次泊松过程类(non-Homogeneous poisson process, NHPP)的SRGM,结合S型 NHPP类的SRGM等[7-8]。然而,由于绝大多数的SRGM嵌入了一定的限制条件或者是假设条件,所以,根据软件工程的特性选出适当的模式通常是具有挑战性的。为了选择一种合适的模式,应该采用以下两种途径:首先是设计一条指导路线,能够为软件工程提出拟合模式;其次是在多种评估后选出最高置信度的模式。如果软件工程巨大而且复杂的话,决策过程会产生巨大的开销。为了降低这样的巨大开销,可以使用神经网络的方法,神经网络采用变换方式,能够根据实际数据适应故障处理特征。研究结果表明,神经网络模型能够用于软件故障检测[10]。
校正时间是软件测试工作中故障校正过程的一个重要指标,早期的SRGM大都不考虑故障校正时间,或者认为校正时间是固定值[11]。显然这是不切实际的。本文提出利用Logistic增长曲线[12]构建神经网络模型完成故障检测,并结合指数分布校正时间完成故障校正过程。通过两组真实失效数据集(Ohba与Wood)的试验[13],对提出方法与现有的SRGM进行了比较。
1 基于神经网络的故障检测及校正方法的提出
对基于故障检测和校正过程的软件测试问题展开研究,提出的方法分为2个阶段,基于神经网络的故障检测过程和基于指数校正时间的故障校正过程。
1.1 基于神经网络的故障检测过程
为了实现切合实际的软件测试,本文做了以下假定:1)如果故障发生,导致故障发生的错误源不能够立即被排除;2)错误校正不完善,一旦找出故障,其能被一定概率p完全修复;3)由于环境因素的不同,软件测试和运用阶段故障率也不一样;4)检测每个软件故障的次数是独立的。
在基于NHPP的故障检测模式中,累计故障次数N(t)通过速率函数(也称强度函数)λ(t)和探测故障数的期望函数m(t)=E(N(t))来定义非齐次泊松过程(NHPP),m(t)通过以下得出
(1)
神经网络是由简单的并行操作元素组成。这些元素受生物神经系统激发。实际上,网络函数主要由元素之间的关联决定。可以训练网络函数通过调整元素之间的关联值(权重)来执行特定函数。通常情况下,调整或是训练神经网络以达到一个特定的输入引出一个特定的目标输出。网络的调整基于对输出与目标值的比较,直到网络输出与目标值匹配。在监督式学习中尤为典型,许多此类的输入/目标对被采用来训练网络。在各种领域应用中,神经网络被训练以执行复值函数,包括模式识别、鉴定、分类、视像以及控制系统。
神经网络属于学习机制,根据已知数据能够接近任何非线性连续函数。神经网络由以下三个主要的成分组成:
神经元:每一个神经元能够接收一个信号,然后进行处理,最后生成一个输出信号。图1描述了一个神经元,f代表处理输入信号和生成输出的激活函数;xi代表上一层中神经元的输出;wi代表上一层神经元关联权重。
网络体系结构:最常见类型的神经网络体系结构称为前馈网络,如图2所示。这种体系结构由三个显著层组成:一个输入层,一个隐藏层和一个输出层。值得注意的是,圆圈表示神经元,以及跨层神经元的连接称为关联权重。
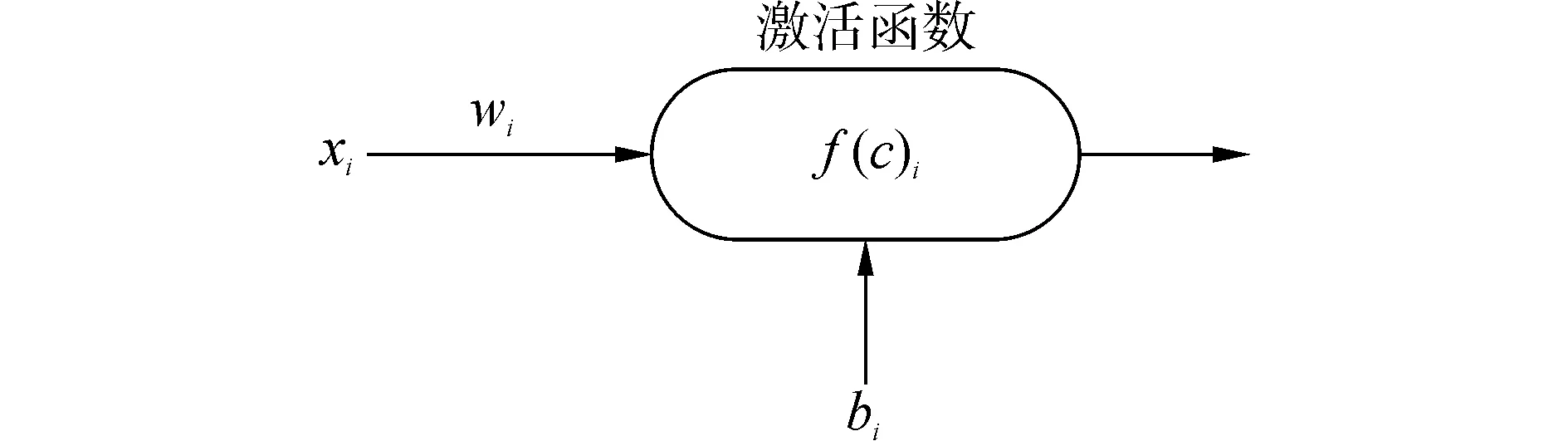
图1 关于神经元的图解Fig.1 Diagram of neurons
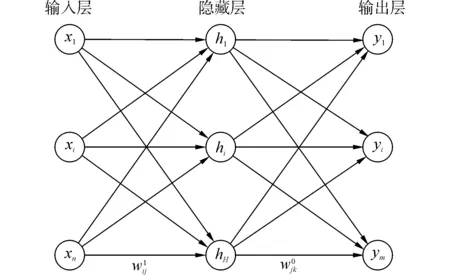
图2 前馈网络结构Fig.2 Structure of feed forward network
学习算法:这种算法描述了调整权重的过程。在学习过程中,网络权重被调整以减少与标准答案相比的网络输出误差。反向传播算法为运用最广泛之一,在这种算法中,网络权重根据输出层反向传播误差反复训练。
运用神经网络的目标是粗略估算能够接收矢量X=(x1,x2,…,xn)和输出矢量Y=(y1,y2…,ym)的非线性函数。
(2)
所以定义网络为Y=F(X)。Y的组成由以下公式得出
(3)
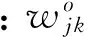
(4)

因为神经网络近似函数可以当作嵌套函数f(g(x)),它能应用于软件可靠性模型,由于后者旨在建立一种能够解释软件故障行为的模式。即,如果从一个平常的SRGM中获得复合函数形式,那么可以为软件可靠性构建一个基于神经网络的模型。在本文中,使用Logistic增长曲线模型[12]。这种模型的均值函数由以下公式求得
(5)
式中:a、b、k皆为正实数。
通过用e-c替换k,从均值函数中可以轻易求得如下复合函数:
(6)
值得指出的是,均值函数m(t)是由以下函数组成:

(7)
(8)

(9)
所以,得出:
(10)
现在,通过基本的前馈网络(图2),从神经网络角度求得了复合函数;但如图3所示,网络在每层中仅只有一个神经元。隐藏层输入和输出分别由以下两个公式求得
(11)
(12)
式中:f(x)代表隐藏层中的激活函数。输出层的输入与输出分别为
(13)
(14)
如果设定激活函数为
(15)

(16)
移除输出层中的偏离率,得出如下结果:
(17)
所以,我们由Logistic增长曲线构建神经网络模型。
基于神经网络模型的故障预测步骤为:1)通过定义偏离率和处处可微的激活函数,由Logistic增长曲线构建神经网络模型,并估测模型参数;2)通过系统的时间间隔数据和故障累计次数,利用反向传播算法训练网络;3)训练网络后,将测试时间反馈给网络,输入为训练网络后给定时间内预见的故障次数。

图3 每层中带单个神经元的前馈神经网络
Fig.3 Feed forward neural networks with a single neuron in each layer
1.2 故障校正过程
由于故障只有在检测之后才可以被排除,所以认定故障校正过程与故障检测过程相关联会更为合适。故障校正过程被假定为时滞的故障检测过程。文献[8]中故障检测通过非齐次泊松过程(NHPP)建模,故障校正与故障检测间存在恒定的时滞。用Δ(t)来表示延迟时间。这种延迟可以建模为确定性或随机变量,也可以与时间相关[14]。通过均值函数mc(t)建模故障校正过程,可以通过m(t)和Δ(t)得出。
1.2.1 恒定校正时间
假设每一个检测到的故障需要同样的时间来校正,也就是说Δ(t)=Δ。所以,给定故障检测率λ(t),故障校正的强度函数可以通过如下公式求得:
(18)
所以,故障纠正过程均值函数可以由以下公式求得
(19)
1.2.2 时间相关的校正时间
故障检测与故障校正之间的时滞可以与时间相关。当检测的故障越难以校正,校正时间就会变得更长,在这种情况下,假设时滞为
(20)
式中:α和β为需要预估的参数,所以校正率和均值函数分别为
(21)
(22)
1.2.3 指数分布校正时间
通常情况下,确定性的校正时间是不现实的。软件校正时间与人类这个不确定的因素密切相关。另外,系统测试中检测到的故障并不相同,而且显示序列是随机的。所以本文用随机变量建模校正时间会更为现实。
众所周知,校正时间大概是遵循一个指数分布[15]。因此,我们假设每一个检测到的故障校正时间是遵循指数分布的随机变量Δt·expμ。于是得出校正率与均值函数分别为
(23)

(24)
2 实例验证
本文运用了两组真实的失效数据集Ohba与Wood集合,对提出的方法进行了统计学分析和模型拟合分析。如文献[13]所述,这两组真实的数据集均包含三类数据, 包括测试时间、测试工作量以及探测缺陷数,是软件可靠性模型性能比较测试的经典实例。两个失效数据集均选取记录长达20周的数据,与现有常用的两种NHPP类SRGM[8-9]进行了可靠性比较。
2.1 参数估算


表1 模型参数估算数值
选用3种常用的评价准则[14-15],对模型拟合结果进行评价,分别为:均值误差平方和(式(25)),回归曲线方程的相关指数(式(26))相对误差图(式(21))。
(25)

(26)
式中:yave表示yi的均值,RSq的数值越靠近1,可靠性评估性能越好。
(27)
RE曲线越靠近x轴,可靠性评估性能越好。
2.2 结果与分析
表2列出了各模型在两组失效数据集上的模型拟合结果。
表2 不同模型的模型拟合结果对比
Table 2 Comparison of model fitting results of different models

模型OhbaWoodMSERSqMSERSqLogisticSRGM114.030.98921.450.978指数威布尔SRGM112.310.99013.220.985本文方法98.860.9938.920.990
从Ohba数据集上的拟合结果可以看出,相比于实验中的其他两种SRGM,本文提出方法的拟合结果最好,MSE数值最小为98.86,RSq数值最接近1为0.993。图 4显示了对于Ohba数据集而言,在这两个模型和本文方法中探测故障数均值的拟合值对比情形。可以看出,提出方法的拟合曲线与实际观测数值曲线的整体契合度较高。图5显示了三种方法在Ohba数据集中每个数据点上的RE曲线对比,显然提出方法的RE曲线最接近于x轴。
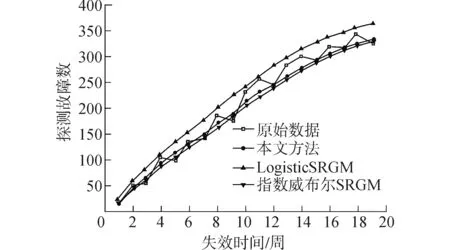
图4 Ohba数据集上的累计故障发生数量拟合结果Fig.4 拟合 Results of cumulative failure occurrence on Ohba data set

图5 Ohba数据集上的RE结果Fig.5 RE on Ohba data sets
从Wood数据集上的拟合结果可以看出,相比于实验中的其他2种SRGM,本文提出方法的拟合结果最好,MSE数值最小为8.92,RSq数值最接近1为0.990。图6显示了对于Wood数据集而言,在这两个模型和本文方法中探测缺陷数均值的拟合值对比情形。可以看出,提出方法的拟合曲线与实际观测数值曲线的整体契合度较高。图7显示了三种方法在Wood数据集中每个数据点上的RE曲线对比,显然提出方法的RE曲线最接近于x轴。

图6 Wood数据集上的累计故障发生数量拟合结果Fig.6 Results of cumulative failure occurrence on Wood data set

图7 Wood数据集上的RE结果Fig.7 RE results on Wood data sets
本文提出的基于神经网络的软件可靠性测试方法在两组数据集上的拟合效果均是最优的,显著优于对比模型, 从而证明提出方法在模型评估性能上具有很好的有效性及适用性。此外,为了验证基于指数分布校正时间的故障校正处理方法的性能,在第一个阶段(基于神经网络的故障检测过程)后,分别使用恒定校正时间、时间相关校正时间和指数分布校正时间来实现故障校正处理,图8显示了三种方法在Ohba数据集中每个数据点上的RE曲线对比,显然使用指数分布校正时间方法的RE曲线最接近于x轴。

图8 Ohba数据集上不同校正时间方法的RE结果Fig.8 RE of different correction time methods on Ohba data sets
3 结论
本文对基于故障检测和校正过程的软件测试和维护问题进行了研究,提出一种基于Logistic增长神经网络的软件测试方法。针对软件工程需求的多样性特点,为了更好地实现故障校正提出了基于神经网络的故障检测方法。与传统的SRGM进行了比较,结果显示提出方法具有以下优势:
1)模型拟合效果更好;
2)结合了指数分布校正时间,解决了传统SRGM中校正时间恒定的问题,更好的贴合了实际应用。
3)在均值误差平方和、回归曲线方程的相关指数、相对误差3个评估指标上,均表现出更好的数值,即可靠性更高。
[1]杨波, 吴际, 徐珞,等. 一种软件测试需求建模及测试用例生成方法[J]. 计算机学报, 2014, 37(3): 522-538.
YANG Bo, WU Ji, XU Luo, et al. A software testing requirement modeling and test case generation method [J]. Journal of computer science, 2014,37(3): 522-538.
[2]王蓁蓁. 软件测试理论初步框架[J]. 计算机科学, 2014, 41(3): 12-16.
WANG Shu. The theory of software testing framework [J]. computer science, 2014, 41 (3): 12-16.
[3]张策, 崔刚, 刘宏伟,等. 软件测试资源与成本管控和最优发布策略[J]. 哈尔滨工业大学学报, 2014, 46(5): 51-58.
ZHANG Ce, CUI Gang, LIU Hongwei, et al. Software testing resources and cost control and optimal publishing strategy [J]. Journal of Harbin Institute of Technology, 2014, 46 (5): 51-58.
[4]张策, 孟凡超, 崔刚,等. SRGM中TE建模机制与模型比较分析[J]. 哈尔滨工业大学学报, 2015, 47(5): 32-39.
ZHANG Ce, MENG Fanchao, CUI Gang, et al.Compara-tive analysis of TE modeling mechanism and model in SRGM [J]. Journal of Harbin Institute of Technology, 2015, 47 (5): 32-39.
[5]张策, 孟凡超, 万锟,等. SRGM建模类别与性能分析[J]. 哈尔滨工业大学学报, 2016, 48(8):171-178.
ZHANG Ce, MENG Fanchao, WAN Kun, et al. SRGM modeling and performance analysis of category [J]. Journal of Harbin Institute of Technology, 2016, 48 (8): 171-178.
[6]赵靖, 张汝波, 顾国昌. 考虑故障相关的软件可靠性增长模型研究[J]. 计算机学报, 2007, 30(10): 1713-1720.
ZHAO Jing, ZHANG Rubo, GU Guochang. Considering the software reliability model of computer [J]. Journal of computer science, 2007, 30 (10): 1713-1720.
[7]谢景燕, 安金霞, 朱纪洪. 考虑不完美排错情况的NHPP类软件可靠性增长模型[J]. 软件学报, 2010, 21(5): 942-949.
XIE Jingyan, AN Jinxia, ZHU Jihong. Considering the NHPP software reliability growth model with imperfect debugging [J]. Journal of software, 2010, 21(5): 942-949.
[8]GARG M, LAI R, KAPUR P K. A method for selecting a model to estimate the reliability of a software component in a dynamic system[C]//2013 22nd Australian Software Engineering Conference, Melbourne, 2013: 40-50.
[9]LIN C T, HUANG C Y. Enhancing and measuring the predictive capabilities of testing-effort dependent software reliability models[J]. Journal of systems & software, 2008, 81(6): 1025-1038.
[10]张伟杰. 一种软件测试算法的改进及对比实验[J]. 科学技术与工程, 2014, 14(35): 245-248. ZHANG Weijie. A software test algorithm improvement and contrast experiment [J]. Science and technology and engineering, 2014, 14 (35): 245-248.
[11]PRIYA K, JAIN M. Reliability analysis of a software with non homogeneous poisson process (NHPP) failure intensity[J]. Journal of bioinformatics & intelligent control, 2012, 1(1): 1-19.
[12]PINHEIRO S. Optimal harvesting for a logistic growth model with predation and a constant elasticity of variance[J]. Annals of operations research, 2016: 1-20.
[13]李秋英, 李海峰, 陆民燕,等. 基于S型测试工作量函数的软件可靠性增长模型[J]. 北京航空航天大学学报, 2011, 37(2): 149-154. LI Qiuying, LI Haifeng, LU Minyan, et al. Software reliability growth model based on S type test workload function [J]. Journal of Beihang University, 2011, 37 (2): 149-154.
[14]HUANG C Y, KUO S Y, LYU M R. An assessment of testing-effort dependent software reliability growth models[J]. Reliability, 2007, 56(2): 198-211.
[15]AHMAD N, KHAN M G M, RAFI L S. A study of testing-effort dependent inflection S-shaped software reliability growth models with imperfect debugging[J]. International journal of quality & reliability management, 2013, 27(1): 89-110.
Software testing method for Logistic growth model based on neural network
WEI Linjing1, NING Lulu2, LIAN Zhichao3, WANG Lianguo1, HOU Zhenxing4
(1. School of Information Science and Technology, Gansu Agriculture University, Lanzhou 730070, China; 2. School of Biological Sciences, Nanyang Technological University, Singapore City 639798, Singapore; 3. School of Computer Science and Engineering, Nanjing university of science and technology, Nanjing 210094, China; 4. School of Information Science and Engineering, Lanzhou University, Lanzhou 730000, China)
Evaluation of software reliability performance directly affects the course of software testing. In this paper, we investigate fault detection in software testing to improve its performance. A software testing methods based on neural network of the logistic growth was proposed. Considering the diversity of software engineering, the proposed method using the logistic growth curve to construct the neural network model in order to complete fault detection. The proposed method combines the exponential distribution correction time in order to complete the fault correction process. Through the test of two sets of real failure data sets (Ohba and Wood), the proposed method is compared with the existing software reliability growth model (software reliability growth model, SRGM). The results confirm that the model fitting effect of the proposed logistic growth neural network model is optimal, demonstrating the adaption and better performance of the software reliability assessment model.
Software testing; reliability evaluation; neural network; software reliability growth model; Logistic curve; Wood data set; Ohba data set
2016-05-31.
日期:2017-03-18.
国家自然科学基金项目(61063028,31560378);江苏省自然科学基金青年基金项目(BK20150784);中国博士后面上项目(2015M581800);甘肃省科技支撑计划(1604WKCA011);陇原青年创新创业人才项目(2016-47);2016年度甘肃省高校重大软科学(战略)研究项目(2016F-10).
魏霖静(1977-),女,副教授,博士后.
魏霖静, E-mail: wlj@gsau.edu.cn.
10.11990/jheu.201605108
TP311
A
1006-7043(2017)04-0646-06
魏霖静,宁璐璐,练智超,等.基于Logistic增长神经网络模型的软件测试方法[J]. 哈尔滨工程大学学报, 2017, 38(4): 646-651.
WEI Linjing, NING Lulu, LIAN Zhichao, et al. Software testing method for logistic growth model based on neural network[J]. Journal of Harbin Engineering University, 2017, 38(4): 646-651.
网络出版地址:http://kns.cnki.net/kcms/detail/23.1390.u.20170318.0716.014.html
猜你喜欢
计算机教育(2020年5期)2020-07-24
国学(2020年1期)2020-06-29
软件(2020年3期)2020-04-20
信息安全研究(2018年11期)2018-11-15
中国医学影像学杂志(2018年9期)2018-10-17
电子制作(2018年16期)2018-09-26
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
移动信息(2016年8期)2016-12-31
中央民族大学学报(自然科学版)(2016年1期)2016-06-27
