
基于大数据和机器学习的微博用户行为分析系统
2017-04-26 22:13章博亨刘健朱宇翔吴帆程维
电脑知识与技术 2017年6期
章博亨+刘健+朱宇翔+吴帆+程维


摘要:网络舆论对一个社会的发展有着不可忽视的作用,因此不免会有因“网络舆情”控制網民的思想动态从而发生极端事件的可能。故此,笔者研究分析了国内外大数据、机器学习等相关技术的发展现状及未来趋势。在结合国内外的理论研究成果及相关技术的基础上,融合Spider、Spark、Machine Learning、Spring MVC等多种技术,设计与实现了基于大数据和机器学习的微博用户行为分析系统。该文在对系统进行详细分析的基础上,实现了系统中的三个主要实体:Spider、Spark、web服务器,并对大范围或定向数据抓取、自然语言处理、实时处理推送、NB训练、Apriori训练、FP-Growth训练、注册登录、情感分析等功能进行了实现。整个系统利用Scrapy爬虫框架自定义实现多线程和分布式的数据抓取与存储,并在Spark上离线训练NB、Apriori、和FP-Growth机器学习算法并且进行实时计算处理,与Hdfs 、Scrapy爬虫 、Hbase和Oracle数据库不断进行交互,进而改变爬虫抓取方式获得定向的更详细的用户信息来进行深入分析,最终形成针对用户行为的一个能进行自我学习的评判体系。通过Spring MVC技术开发高效的服务器端、Bootstrap、Echarts美化前端展示。最后对基于大数据和机器学习的微博用户行为分析系统进行测试,该系统能够完成预期的功能目标。
关键词:Scrapy;Spark;NB;Apriori;FP-Growth;Spring MVC
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)06-0212-02
1 概述
本作品运用业界流行的Spark分布式大数据平台,自底向上设计并实现了一整套基于大数据的微博用户行为分析系统。从分布式数据存储、大规模网络数据分析到实时数据可视化均采用spark框架搭建,构建了一套完整的网络安全云监控平台。综合数据及内容数据,使网络安全监控不再单一化。本作品的主要研究内容如下:
1)构建了分布式多进程Python爬虫,并以此为基础实现了高效的多节点实时数据收集方法,通过该方法对微博用户行为数据进行收集,并通过hdfs、hbase、oracle进行数据的存储格式转换。
2)通过算法建模不断进行机器学习,综合使用字典判别、自然语言理解、人工智能判别及文本倾向性判别等方法,重点研究了中文语言处理的基础方法,其中包含文本断句、文本分词、词性分析等,完成采集到信息的初步处理,并且测试中其正确率至少能达到97%。
3)搭建了基于Spark分布式大数据平台,以MapReduce模型为主的Spark计算平台和流式计算为主的Spark Streaming实时分析平台。系统实现了以分布式的多进程python爬虫为数据源的采集方法,实时分析统计数据并能发现危险网络行为。
4)采用spring+spring mvc+mybatis为框架搭建web端,研究设计了实时推送数据的Web服务器,直接通过WebSocket服务器将信息推送到Web端,能够取得轻量级的良好效果。直观地展示网络数据以及网络危险行为的情况。针对网络用户发布、转发等内容则将用户正负倾向比例、热点信息,时间趋势变化等结果直观展示,起到辅助决策的作用。
2 系统总体设计
根据云平台网络安全分析的技术特点及需求,结合现实情况,本文构建了基于云构架的大规模网络数据分析系统的详细设计,平台架构如下图所示,主要包括数据收集层,数据计算处理层,展示层和数据存储层。
2.1 数据采集层
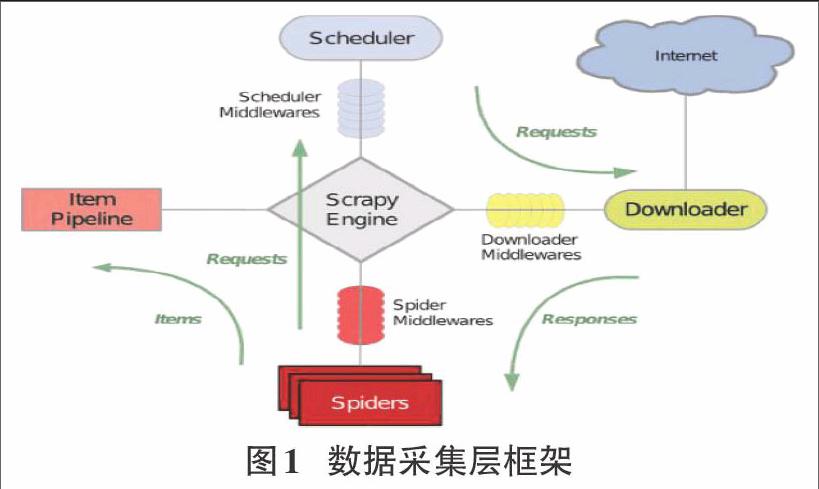
采用python编写网络爬虫,Scrapy框架使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
数据处理流程:
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为:
1)引擎打开一个域名,蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL
2)引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度
3)引擎从调度那获取接进行爬取的页面
4)调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器
5)当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎
6)引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理
7)蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求
8)系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系
2.2 数据计算处理层
数据计算处理层主要包括离线批处理模块、实时处理模块。
1)离线批处理模块
该模块采用Spark编程模型,实现在大数据下(如:数个月内热门话题和用户数据)微博信息的分类和回归分析的模型训练和加强(NB、Apriori、Fp-Growth)。Matei Zaharia等人证明在Spark集群上对39GB的数据集进行迭代式的机器学习,响应时间为次秒级,这一点比Hadoop集群快10倍到20倍之间。
2)实时处理模块
该模块在Spark平台上使用Spark Steaming应用完成。Spark Steaming对数据集按时间片段分割后再以批处理的形式计算数据。由于Spark Steaming是在Spark平台构架之上,计算过程的数据交换在内存中执行,因此计算效率高可以满足实时性要求,而且两者的编程模型也非常相似,如图2所示,Spark系统和Spark Streaming系统的数据可以无缝对接,因此使用Spark生态系统同时部署离线处理系统和实时处理系统是可行有效的。
3 算法详设
3.1 基于n-Gram+的特征粒度選取分词模型
假设一个句子S可以表示为一个序列,语言模型就是要求句子S的概率P(S):
这个概率的计算量太大,解决问题的方法是将所有历史按照某个规则映射到等价类,等价类的数目远远小于不同历史的数目,即假定:
当两个历史的最近的N-1个词(或字)相同时,映射两个历史到同一个等价类,在此情况下的模型称之为N-Gram模型,也被称为一阶马尔科夫链。 N的值不能太大,否则计算仍然太大。
假设我们取词长度N最长为12。如题名“如果你的生活中突然出现一个游侠”, 进行N元切分后,结果如下:
1元组:如|果|你|的|生|活|中|突|然|出|现|一|个|游|侠
2元组:如果|果你|你的|的生|生活|活中|中突|突然|然出|出现|现一|一个|个游|游侠
……
12元组:如果你的生活中突然出现一|果你的生活中突然出现一个|你的生活中突然出现一个游|的生活中突然出现一个游侠
之后我们根据最大似然估计(MLE),语言模型的参数变为:
其中,表示在训练数据中出现的次数。
3.2 训练朴素贝叶斯模型判定用户的危险程度
朴素贝叶斯分类的正式定义如下:
① 设为一个待分类项,而每个a为x的一个特征属性
② 有类别集合
③ 计算
④ 如果,则
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
① 找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
② 统计得到在各类别下各个特征属性的条件概率估计。即
① 如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
3.3 基于Apriori频繁项集及关联规则的挖掘
Apriori原理:
1)寻找频繁项集:Apripri原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。对于之前给出的例子,这意味着如果{0,1}是频繁的,那么{0},{1}也一定是频繁的。这个原理直观上并没有什么帮助,但是如果反过来看就有用了,也就是说一个项集是非频繁集,那么它的所有超集也是非频繁的。
2)寻找关联规则:第1)中给出了频繁项集的量化定义,即它满足最小支持度要求。对于关联规则,我们也有类似的量化方法,这种量化指标成为可信度。一条规则P->H的可印度定义为support(P|H)/support(P)。
3.4 基于Apriori频繁项集及关联规则的挖掘
将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对,即常在一块出现的元素项的集合FP树。这种做法使得算法的执行速度要快于Apriori,通常性能要好两个数量级以上。
该算法只扫描两次数据即可发现频繁项集,一个元素项可以出现多次,并被存储频率。每个项集会以路径方式存储在FP树中,相似元素的集合会共享树的一部分。只有当集合完全不同时,树会分叉,其中节点连接即相似项之间的连接。
除了FP树,我们用字典作为数据结构来保存头指针表。除了存放指针外,头指针表还用来保存FP树中每类元素的总数,其中字母代表项集,数字代表项集出现频率。
参考文献:
[1] 曹艳. 基于词表和N-gram算法的新词识别实验[D]. 南京: 南京农业大学, 2007.
[2] 杨志宏. 基于条件随机场的中文分词算法改进[D]. 烟台: 海军航空工程学院, 2012.
[3] 徐荣. MRF模型在图像分割领域的发展[D]. 南京: 东南大学, 2008.
[4] 吴黎兵, 柯亚林, 何炎祥, 等. 分布式网络爬虫的设计与实现[J]. 计算机应用与软件, 2011(11).
[5] 樊嘉麒. 基于大数据的数据挖掘引擎[D]. 北京: 北京邮电大学, 2015.
[6] 冯琳. 集群计算引擎Spark中的内存优化研究与实现[D]. 北京: 清华大学, 2013.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
河南电力(2015年5期)2015-06-08
皖西学院学报(2015年5期)2015-02-28
计算机工程(2014年6期)2014-02-28
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
中学生英语·外语教学与研究(2008年4期)2008-03-18
