
模糊加权多视角可能性聚类算法
2017-04-24 10:39:38王振辉夏鸿斌
计算机应用与软件 2017年4期
王振辉 夏鸿斌
(江南大学数字媒体学院 江苏 无锡 214122)
模糊加权多视角可能性聚类算法
王振辉 夏鸿斌
(江南大学数字媒体学院 江苏 无锡 214122)
受益于独有的可能性聚类特性,较之传统FCM、k-means等基于类均值方法,PCM拥有更佳的聚类效果和抗噪性能。但PCM为传统单视角聚类算法,其在面对新兴多视角聚类场景时,往往效果欠佳。为解决此问题,基于PCM,提出一种新型的称为模糊加权多视角可能性聚类WCo-PCM算法。WCo-PCM显著优点在于其具备对各视角的自适应加权。有关UCI数据集的实验结果表明该算法较传统聚类算法及多视角聚类算法更具抗干扰性,有着更佳的聚类性能。
可能性聚类 多视角聚类 模糊加权 抗干扰性
0 引 言
模糊C均值聚类算法(FCM[1-2])是模糊聚类算的鼻祖,它不仅产生较早,且算法简洁、经典。随着社会的发展,FCM算法固有的一些缺陷也慢慢凸显。例如,FCM算法对初始聚类中心敏感、抗干扰性能较差、常会收敛到局部极小值。FCM算法规定各个样本划分到各个类的隶属度之和为1,但这样的规定对于噪声点及例外点来说,并不合适。理想状态下,噪声点及例外点在划分的过程中是不应该赋予其一定的隶属度[3-4],一旦赋予其隶属度,则会影响最终的聚类结果。对于该情况,可能性聚类(PCM)算法不再规定各样本隶属度之和必须等于1,使得噪声和例外点在聚类过程中的隶属度被赋予一个较小值, 从而使其对聚类结果的影响变小,最终增强了聚类算法的抗噪性也提升了算法的聚类性能。然而,传统的可能性聚类方法无法适应目前新兴的应用场景(即多视角模式识别场景)。随着大数据时代的到来,数据结构呈现复杂化、高维度等特征,多视角数据的出现也如雨后春笋,比较经典的多视角数据集有手写体数据集、WebKB网页数据和ORL人脸数据[5]等。多视角数据集能将不同视角的信息有效的结合起来,针对多视角数据进行分析学习能够更好地把握规律、找准信息。近年来,许多专家学者提出了针对多视角数据进行聚类分析的方法,如Bickel等人提出了多视角聚类算法[6-7],S.Bickel等人提出了CoEM算法[8],Cleuziou等人提出了CoFKM算法[9],文献[10]将混合模型引入到多视角聚类分析中,从而提出了基于混合模型的多视角聚类算法。传统多视角聚类算法在具体聚类分析时简单的认为每个视角提供给聚类分析的贡献率是一样的,这并不符合实际情况。因为往往多视角数据中,会出现一个或多个视角的数据的聚类性能优于其他视角,一个或多个视角的聚类性能较差的情况。而将所有视角一视同仁,则会降低优良视角贡献率,提升较差视角贡献率,导致无法获取最好的聚类结果。针对以上情况,本文致力于提出一种新颖的具有视角加权能力的多视角可能性聚类方法。
本文提出的WCo-PCM算法的改进策略主要包含以下两个方面:(1) 针对传统的可能性聚类算法无法适应新兴的多视角模式识别应用场景,本文提出了基于多视角的可能性聚类算法;(2) 传统的多视角聚类算法在具体进行聚类分析时,总是会简单地认为各视角的重要性是相同的。实际上,多视角数据中各个视角数据的聚类性能参差不齐,如若将各个视角数据的重要性一视同仁,那么最终的聚类结果必将受那些具备较差聚类性能的视角所影响而变得不理想。对于这些问题,本文将多视角聚类机制与视角模糊加权机制引入到传统的PCM算法中,最终形成了模糊加权多视角可能性聚类算法(简称WCo-PCM算法)的目标函数式。本文提出的WCo-PCM算法能够适用在多视角模式识别场景,还可以自适应分配各视角权值,从而提高算法的聚类精度。
1 可能性聚类(PCM)算法
针对FCM算法要求每个样本属于所有类的隶属度之和为1所带来的弊端,可能性聚类(PCM)算法[11-12]于1993年应运而生。PCM算法不再对隶属度进行任何限制,直接去除了FCM算法中规定的各样本属于每类的隶属度之和为1的限制。PCM算法赋予了噪声及例外点较小的隶属度值, 降低了噪声及例外点对整个聚类过程的影响,最终增强了算法的聚类性能。
1.1 PCM算法基本原理描述
给定数据集 ,则PCM算法的目标函数式表示如下:
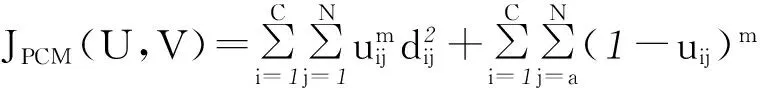
(1)
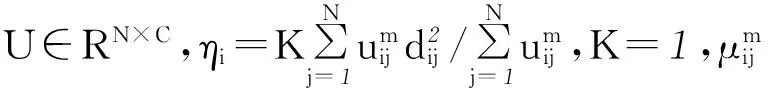
观察式(1),PCM算法目标函数式的第一项为FCM算法的目标函数式,其作用是要求所有样本点到聚类中心的距离值的平方和尽可能小;PCM算法目标函数式的第二项的作用是使隶属度uij尽可能大,防止某些噪声点及例外点的隶属度为整个聚类结果带来干扰,以增强算法的抗干扰性。
最小化目标函数式(1),得到最优解时中心点V以及隶属度U的迭代公式如下:
(2)
(3)
上述两式均满足m>1,i=1,2,…,C。由于模糊指数的取值m对聚类结果的影响较大,因此如何确定合适的m值对PCM算法的具体应用至关重要。模糊指数m在聚类分析时的影响主要表现在以下两方面:(1) 模糊指数m取值越小,则PCM算法越接近于硬划分HCM算法;(2) 模糊指数m取值越大,得到的空间划分就越不清楚,类之间的界限就越不清晰,导致最终获取的聚类结果也不理想。根据文献[13]给出的参数选取的理论结果,本文m取2。
1.2PCM算法迭代求解过程
结合1.1小节的推导公式,可将PCM算法的聚类过程分为以下步骤:
输入阶段 给定数据集X={x1,x2,…,xN},参数N表示样本数据的总数,参数D表示样本数据的维数。
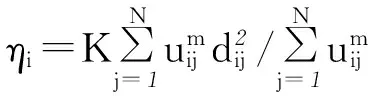
优化迭代阶段
Step1 根据式(2)计算新的聚类中心矩阵V(t);
Step2 结合Step1计算出的聚类中心矩阵V(t)以及已有的隶属度矩阵U(t),代入到式(3)求得新的隶属度矩阵U(t+1);
Step3 当满足以下判别条件J(t+1)-J(t)<ε或迭代次数t大于参数M时,算法停止。否则返回Step2进行循环迭代直到满足任意迭代终止条件。
输出阶段 算法运行结束后,输出最终的隶属度矩阵U′以及类中心矩阵V′。
1.3PCM算法亟待改进的问题
随着时代的发展,算法的应用场景也在不断变化,传统PCM算法在当今的模式识别应用场景中还存在一些问题,而这些问题主要体现在以下两个方面:
问题1 (不适用于新兴的多视角模式识别场景)传统的PCM聚类算法主要针对一些常规样本进行聚类。所谓常规样本主要是指那些只从一个角度去描述或度量一个事物的数据,常规数据样本的呈现的特征一般为:低维、简单。然而,随着时代与科技的发展,高维数、结构复杂、分布杂乱的数据集随即产生并大量出现,多视角数据在这样的背景下也相继出现。所谓多视角数据即同一个数据集可从多个角度进行描述或度量,从而获得多组不同属性的数据,多组数据结合在一起便形成了对该事物进行全面描述的一个多视角数据集[14],单、多视角数据对比示意如图1所示。多视角数据集将所有视角的信息进行了有机结合,结合有效的聚类算法则可以获得更好的聚类结果。针对多视角数据,传统的PCM算法应如何进行改进,才能有效聚类并获得较好的聚类结果。
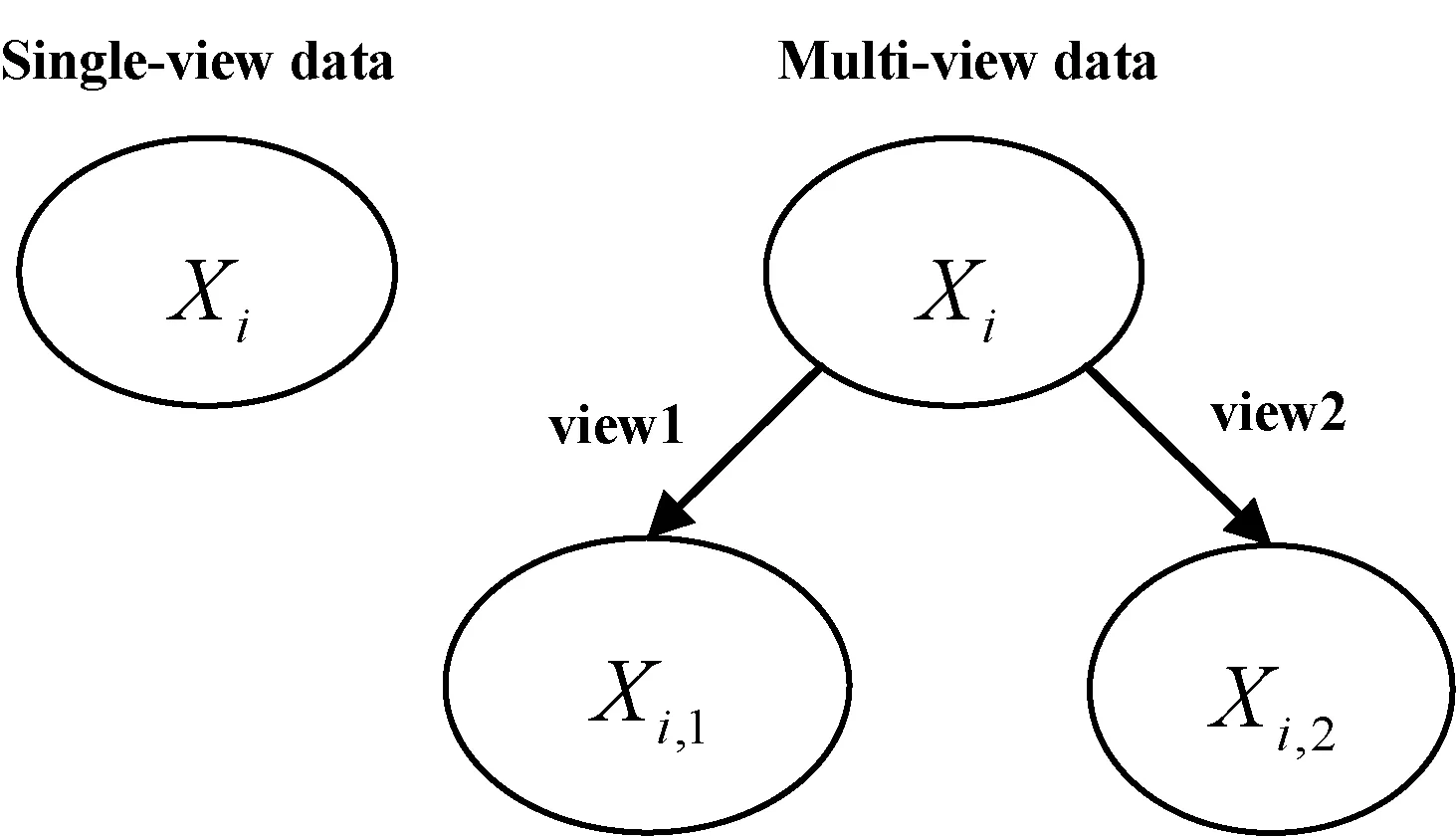
图1 单、多视角数据对比示意图
问题2 (各视角的权值默认均分与实际不符) 传统的多视角聚类算法在具体进行聚类分析时,总是会简单的认为各视角的重要性是相同的。实际上,多视角数据中各个视角数据的聚类性能参差不齐,如若将各个视角数据一视同仁,那么在最终决策后得到的聚类结果必将被那些具备较差聚类性能的视角所影响,导致最终的聚类结果不理想。针对传统多视角聚类算法存在的弊端,如何对各视角进行动态加权成为了亟需解决的问题。如图2所示,第1、2、n-1个视角的聚类效果并不理想,各个类别的数据总存在重叠的情况。而第n个视角的聚类效果则很好,即各个类别的数据距离较远,不存在重叠的情况。在对各个视角进行加权时,我们很容易想到赋予聚类效果好的视角较大的权值,聚类效果较差的视角较低的权值。

图2 各视角聚类效果示意图
2 模糊加权多视角可能性聚类算法
针对1.3小节中提出的两个问题,以PCM算法作为基础模型,在本部分将提出本文的主要算法,即具备多视角聚类能力的模糊加权多视角可能性聚类算法WCo-PCM。
2.1 目标函数
首先针对问题1在经典PCM算法上引入多视角协同学习机制使其获得多视角聚类的能力如下:
(4)
尽管式(4)已使得PCM算法获得了多视角聚类的能力,但其对于各个视角的权重确是均衡的。这使得该算法仍然会面临1.3小节中问题2所述之挑战从而造成最终聚类效果不佳的结果。为了解决此问题,本文进一步在式(4)的基础上融入视角模糊加权机制,得到了最终的具备视角模糊加权多视角可能性聚类算法(WCo-PCM)目标函数式为:
(5)
其中,各参数需满足以下的约束条件:
式中,C为聚类的类别总数,N为样本总数,R为视角总数,α是分歧项占比重系数,uij,r为第r个视角数据的第j个样本属于第i个类中心的隶属度,wr为第r个视角的权值,τ为模糊指数(一般取2),ηi,r为第r个视角的惩罚因子。
上式所构之WCo-PCM算法不仅具备了多视角协同聚类的能力,同时还可以根据各视角的聚类特性对各视角的聚类结果进行自适应的加权处理,并利用最终获取的加权结果W=[w1,w2,…,wR]T,进一步使用下式得到具备全局性划分结果的最终的隶属度矩阵U′:
(6)
利用式(6)获取得到的加权意义下的隶属度矩阵U′,在去模糊后即可获取较之传统单视角聚类方法更佳的多视角聚类效果。
2.2 优化迭代参数的相关推导
为了对各参数进行优化学习,本文仿照经典PCM算法的迭代优化策略,仍利用拉格朗日法则,求得目标函数式(5)的最优解,得到聚类中心、隶属度、视角权值表达式如下:
1) 聚类中心表达式
(7)
2) 隶属度表达式
(8)
3) 视角权值表达式
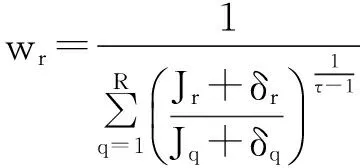
(9)
其中:
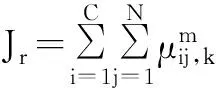
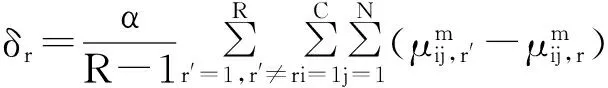
2.3WCo-PCM算法描述
WCo-PCM算法的具体执行步骤如下:
输入阶段 给定数据集X={x1,x2,…,xN},参数N表示样本数据的总数。
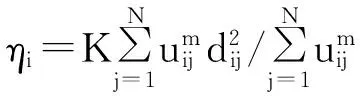
优化迭代阶段:
Step1 根据式(7)计算各视角下的新聚类中心矩阵V(t)。
Step2 结合Step1计算出的各视角下的聚类中心矩阵V(t)以及已有的各视角下的隶属度矩阵U(t),代入到式(8)求得各视角下的新的隶属度矩阵U(t+1)。
Step3 当满足以下迭代终止条件J(t+1)-J(t)<ε或迭代次数t大于参数M时,算法停止。否则返回Step2进行循环迭代直至满足上述两项终止条件之一为止。
输出阶段 算法运行结束后,根据式(6)输出最终的隶属度矩阵U′,进而根据U′得到最终的聚类结果。
3 实 验
实验使用UCI中的多视角数据集对WCo-PCM算法的聚类性能进行分析,评价指标为互信息熵NMI与芮氏指标RI,评价指标详情如下:
1) 互信息熵[15]
(10)
2) 芮氏指标[15-16]
(11)
NMI与RI的取值范围均为0到1,两个指标的取值含义均为取值越大表明算法越优越。本文的实验环境如下:采用MATLAB2014b,所有试验在CPU:Corei5,主频:3.1GHz。内存:4GB的PC上完成。
具体实验参数设置如下:(1) 最大迭代次数:M=500;(2) 迭代阈值:ε=le-3;(3) 模糊指数:τ=2,m=2;(4) 分歧项所占比例系数α取0.1。
3.1UCI真实数据实验
为了验证本算法WCo-PCM对于多视角数据集的聚类性能,本文使用UCI中的手写体数据集以及图像分割数据集IS,两数据集的具体描述如表1所示。本文实验中的对比算法主要包含两个方面:
(1) 单视角聚类算法:经典的基于模糊论的FCM算法[4]及经典的基于可能性理论的PCM算法[3];
(2) 多视角聚类算法:基于模糊C均值算法具备视角间交互式学习能力的多视角模糊聚类CoFKM算法[9]、基于EM模型利用视角间数据分布特性交互学习的CoEM算法[8]、及本文提出的模糊加权多视角可能性聚类算法WCo-PCM算法。
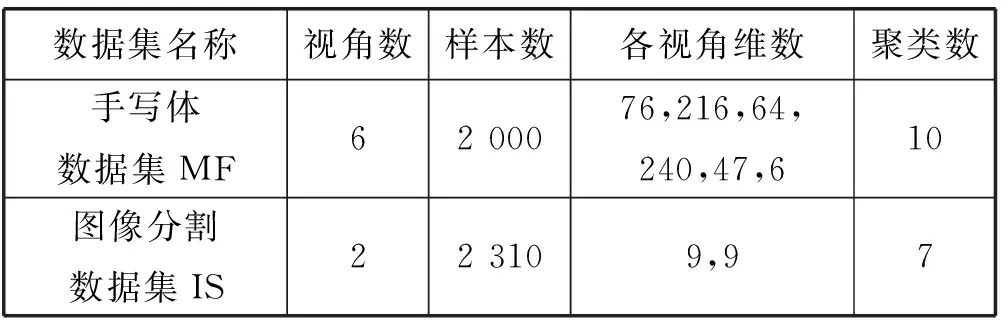
表1 UCI经典数据集描述
表中所有实验结果均是运行算法20次取均值所得,实验结果详见表2所示。
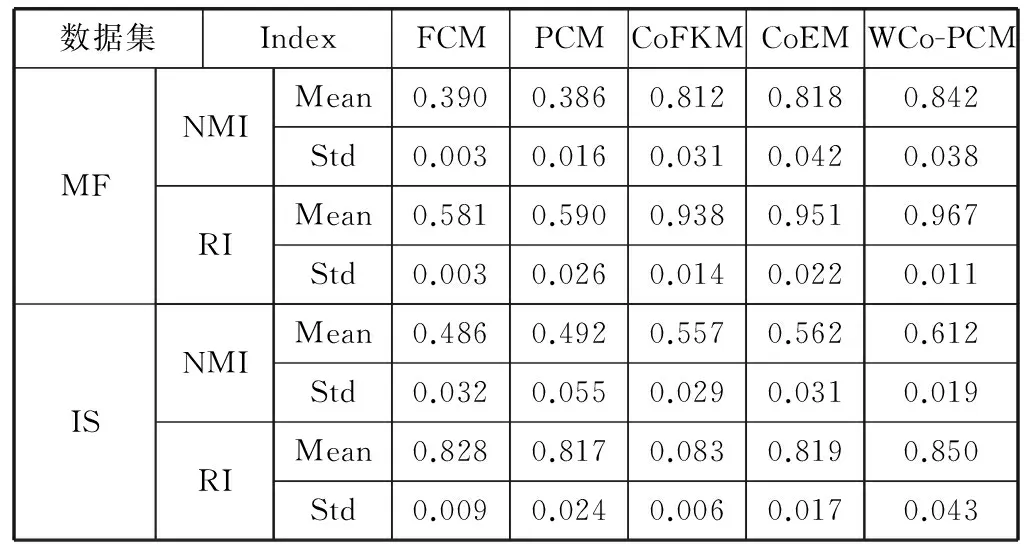
表2 各算法于所含已知信量不同的场景下之性能分析
通过对表2所示实验结果进行分析,可得出以下结论:(1) 对于多视角数据集,传统的单视角算法不太适用。如表2所示,无论是MF数据集还是IS数据集,FCM算法以及PCM算法的聚类性能均没有其他多视角算法的聚类性能好。实验结果表明,对于多视角数据集的聚类分析,只有用具有多视角聚类分析能力的算法。(2) 本文提出的WCo-PCM算法比其他多视角聚类算法的聚类性能更佳。因为传统的多视角聚类算法都认为所有视角对聚类分析的重要性是一样的,而这一情况与实事不符。本算法对每个视角进行了模糊加权,对于具有分歧的视角赋予了较低的权值,最终得到的聚类结果最优。
3.2 比例因子α对聚类性能的影响
WCo-PCM目标函数式里中括号内的第二项为分歧项,该项是用来惩罚那些未达成一致的视角。其中参数α的大小表示分歧项的比重大小,该项的取值对聚类性能的影响本文也做了一定的研究。图3则为比例因子α在MF、IS数据集中对聚类性能的影响的示意图。

图3 比例因子α的变化对聚类性能的影响示意图
从上面的实验结果可以看出,当比例因子α取0.1~0.2时,聚类性能最好。
4 结 语
为了使经典的可能性聚类算法能够更加有效地适用于多视角模式识别场景,本文提出了多视角的可能性聚类算法。传统的多视角聚类算法在具体进行聚类分析时,总是会简单地认为各视角的重要性是相同的。实际上,多视角数据中各个视角数据的聚类性能参差不齐,如若将各个视角数据一视同仁,那么在最终决策后得到的聚类结果必将被那些具备较差聚类性能的视角所影响,导致最终的聚类结果不理想。于是本文引入了视角模糊化理论,为各个视角动态赋予了相应的权值。通过在UCI中的多视角数据集MF、IS上进行实验,其实验结果均说明本文算法比其他经典的FCM算法、PCM算法、CoFKM算法、CoEM算法方法,不但能够有效地抵抗噪声的干扰,而且还能自适应地赋予各个视角一定的权值,提高最终的聚类精度。实验表明本文提出的模糊加权多视角可能性聚类算法能够很好地适用于多视角数据集进行聚类。
[1]ZhuL,ChungFL,WangS.Generalizedfuzzyc-meansclusteringalgorithmwithimprovedfuzzypartitions[J].Systems,Man,andCybernetics,PartB:Cybernetics,IEEETransactionson,2009,39(3):578-591.
[2] 朱林,王士同,邓赵红.改进模糊划分的FCM聚类算法的一般化研究[J].计算机研究与发展,2015,46(5):814-822.
[3]PalNR,PalK,KellerJM,etal.Apossibilisticfuzzyc-meansclusteringalgorithm[J].FuzzySystems,IEEETransactionson,2005,13(4):517-530.
[4]BezdekJC.Patternrecognitionwithfuzzyobjectivefunctionalgorithms[M].SpringerScience&BusinessMedia,2013.
[5] 古凌岚.面向大数据集的有效聚类算法[J].计算机工程与设计,2014,35(6):2183-2187.
[6]BickelS,SchefferT.Multi-ViewClustering[C]//ICDM,2004,4:19-26.
[7]BrefeldU,SchefferT.Co-EMsupportvectorlearning[C]//Proceedingsofthetwenty-firstinternationalconferenceonMachinelearning.ACM,2004:16.
[8]BickelS,SchefferT.EstimationofmixturemodelsusingCo-EM[M].MachineLearning:ECML2005.SpringerBerlinHeidelberg,2005:35-46.
[9]CleuziouG,ExbrayatM,MartinL,etal.CoFKM:Acentralizedmethodformultiple-viewclustering[C]//DataMining,2009.ICDM’09.NinthIEEEInternationalConferenceon.IEEE,2009:752-757.
[10]TzortzisGF,LikasAC.Multipleviewclusteringusingaweightedcombinationofexemplar-basedmixturemodels[J].NeuralNetworks,IEEETransactionson,2010,21(12):1925-1938.
[11]KrishnapuramR,KellerJM.Apossibilisticapproachtoclustering[J].FuzzySystems,IEEETransactionson,1993,1(2):98-110.
[12] 范九伦,裴继红.基于可能性分布的聚类有效性[J].电子学报,1998,26(4):113-115.
[13] 宫改云,高新波,伍忠东.FCM聚类算法中模糊加权指数m的优选方法[J].模糊系统与数学,2005,19(1):143-148.
[14] 庄传志,张道强.多视角判别聚类算法[C]//2009年中国智能自动化会议论文集(第七分册).南京理工大学学报 (增刊),2009.
[15]DengZ,ChoiKS,ChungFL,etal.Enhancedsoftsubspaceclusteringintegratingwithin-clusterandbetween-clusterinformation[J].PatternRecognition,2010,43(3):767-781.
[16] 洪志令,姜青山,董槐林.模糊聚类中判别聚类有效性的新指标[J].计算机科学,2004,31(10):121-125.
MULTI-VIEW POSSIBILITY CLUSTERING ALGORITHM USING FUZZY WEIGHTING
Wang Zhenhui Xia Hongbin
(SchoolofDigitalMedia,JiangnanUniversity,Wuxi214122,Jiangsu,China)
Benefiting from the delicate mechanism of possibility clustering, PCM appears preferable performance regarding effectiveness and anti-noise, against those conventional mean-based methods such as FCM and k-mean. However, PCM still belongs to the traditional single-view clustering method, which incurs its inefficiency in the fashionable multi-view-oriented scenario. For addressing such challenge, based on PCM, a novel clustering algorithm, referred to as fuzzily weighted multi-view Co-PCM (WCo-PCM for short), is proposed in this paper. The distinctive merit of WCo-PCM lies in its self-adaptive weighting mechanism for the multiple views. The experimental studies implemented on some UCI data sets indicate that, compared with some traditional clustering approaches as well as some existing multi-view ones, WCo-PCM features better anti-interference and clustering effectiveness.
Possibility clustering Multi-view clustering Fuzzy weighting Noise immunity
2016-01-11。江苏省自然科学基金重点研究专项项目(BK2011003)。王振辉,硕士生,主研领域:人工智能和模式识别。夏鸿斌,副教授。
TP181
A
10.3969/j.issn.1000-386x.2017.04.050
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
电子测试(2017年15期)2017-12-18 07:19:27
自动化学报(2017年7期)2017-04-18 13:41:02
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
智能系统学报(2015年4期)2015-12-27 09:38:39
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
电子设计工程(2015年6期)2015-02-27 12:04:53
