
基于社会化网络的长期搭乘共享个性化推荐方法
2017-04-24 10:25:08仲秋雁李岳阳
计算机应用与软件 2017年4期
仲秋雁 李岳阳 初 翔
(大连理工大学管理与经济学部信息管理与信息技术研究所 辽宁 大连 116024)
基于社会化网络的长期搭乘共享个性化推荐方法
仲秋雁 李岳阳 初 翔
(大连理工大学管理与经济学部信息管理与信息技术研究所 辽宁 大连 116024)
在汽车、住宿等服务行业中,与共享服务配套的个性化推荐方法的研究不足,降低了用户体检。以搭乘共享问题为例,考虑位置、社交、费用三方面因素,提出URLP(Users Recommendation Based on LBSNs and Payment)方法为用户推荐长期合作对象。该方法首先基于用户行为矩阵计算车主与乘客的位置相似度,其次通过历史交易数据学习建立基于位置的社交信任网络,然后根据近期交易记录拟合用户的车费偏好函数,最后综合三类因素的影响自适应地产生推荐列表。实验结果表明URLP方法具有良好的准确率。虽然URLP方法以汽车共享为例提出,但方法同样可被应用于众包快递和配送等领域。
搭乘共享 个性化推荐 基于位置的社会化网络 TF-IDF
0 引 言
Uber和Airbnb两家公司的崛起,让其共性商业模式——共享经济成为全球最热商业模式。共享经济指民众公平、有偿的共享一切社会资源,彼此以不同的方式付出和受益,共同享受经济红利[1]。拼车是目前一种典型的空车资源有偿共享模式,指私家小汽车驾驶人与其他人共乘出行,通过减少小汽车空座率达到减少小汽车出行量和道路需求等目的的集体行为[2]。类似的商业模式还有众包快递,被称为“快递版”Uber。搭乘共享平台迅速发展,但是与平台配合的推荐系统却刚刚起步,相关研究也较少。本文以上班族通勤拼车为例,以基于位置的社会化网络LBSNs(Location-based Social Networks )为推荐框架,提出一种适合长期搭乘共享问题的个性化推荐方法——URLP方法。
对于拼车问题,很多学者采用数学分析的方式研究用户最佳拼车策略。Friginal等认为在个人与个人的拼车过程中会应用到以下三中技术:谈判机制、谈判平台和社交网络[3]。Boukhater和Huang把拼车路线选择作为一种组合优化问题,根据自定义的适应度函数,用遗传算法为用户寻找拼车路线最短的最优拼车方案[4-5]。Knapen和Hartman研究长期需求的拼车问题,建立拼车用户选择的图论模型,其中Hartman用真实数据验证了其模型的有效性[6-7]。采用数学方法建模对以后的研究有很大借鉴作用,但大部分模型都只考虑位置远近对于用户选择的影响,模型过于理想,离实际应用有一定距离。拼车用户选择问题的另一种研究方式是仿真方法。在图论模型基础上,Hussain和Knapen选择不同“谈判机制”,计算机仿真观察不同机制下用户行为[8-9]。Galland建立基于Agent的交流模型,用Agent档案文件和社交网络开始交流模型进行仿真,最后用Flanders 的真实数据验证模型的有效性[10]。仿真研究可以在无法大规模实体演示的情况下,模拟现实情景,得出科学结论,但往往忽视了个体的差异性,现实生活中每个用户对于拼车对象的选择会因为个人社会背景、习惯等而大相径庭。因此,有必要根据不同用户特点,为其推荐不同对象进行搭乘。
目前,LBSNs推荐框架流行于各种基于位置服务的研究。LBSNs是一种把地理位置信息作为一种新动态的社交网络[11],它不仅意味着把地理位置信息附加到已经存在的社交网络中,也可能是由地理位置较近的人群组成的社交圈构成的新的网络结构[12]。LBSNs中群体行为的研究已经获得例如智能交通系统、推荐系统等领域的关注[13]。基于LBSNs推荐的一个特点是推荐对象的“位置关联性”[14]。Zheng和Liao把用户到过某位置的次数作为该用户对该位置的隐性评分,寻找近邻用户,从而为用户推荐位置相近的朋友[15-16],Griesner等通过矩阵分块算法考虑上下文为用户做出个性化的地点推荐[17]。对于LBSNs推荐中的冷启动问题,Gao等根据距离和社交关系把用户分为四类改进朴素贝叶斯方法来预测用户出现在某位置的“可能性”,缓解了一般位置推荐中初始数据稀疏的问题[18]。已有的基于LBSNs推荐框架的研究在计算位置相似度时并不直接考虑两个位置的经纬度,大都采用改进协同过滤算法、朴素贝叶斯方法等间接方式处理。在搭乘共享问题中,位置作为用户偏好而不是被推荐项目,因此对多样性要求低对准确度要求高,需要直接处理位置数据,上述方法并不适用。基于以上分析,本文选择改进基于内容的推荐算法计算用户位置相似度。
1 问题界定
通勤拼车用户有两个特点:有长期拼车需求,拼车时间地点相对固定。因此,通过用户历史拼车记录学习其偏好并做出推荐是可行的。拼车过程中,很多软件是由需要拼车的乘客发布拼车需求,车主抢单,所以本文站在车主的角度,为车主推荐合适的拼车乘客。当然,稍作调整后该方法也可以为乘客推荐合适的车主。本文选取位置、社交、车费补贴进行用户偏好学习理由如下:
(1) 拼车过程中不论是车主或者乘客最关心的都是在自己计划出行的时间内,路线的匹配程度,越是“顺路”,则车主和乘客拼车的可能性越大。故选取带有时间参数的位置作为用户偏好进行学习。
(2) 由于上班族拼车为长期需求,故在拼车过程中,车主和乘客会建立一种基于地理位置的“朋友”关系,甚至可能其中就有原来本就认识的邻居或同事。一位车主可能和与他上下班顺路的多位乘客拼车,一位乘客也可能和多位车主拼车,则在某一地区会建立起一种隐性社交圈,本文认为这是一种基于地理位置的社交网络。社交会建立一种信任关系,从而影响用户的行为。故选择社交作为用户偏好进行学习。
(3) 现行拼车车费由两部分组成,油费和车费补贴。其中油费paykm根据里程数决定,每次拼车油费自动计算,而车费补贴Δsubsidy相对灵活,即pay=paykm+Δsubsidy。乘客不同,相同的里程,车主可能得到不同的车费补贴。现实拼车中,有的车主只愿意搭载同路的乘客,有的车主却愿意为了更多的补贴而绕路,这会很大程度影响推荐结果。故本文只考虑会因为交易个人不同而不同的补贴部分,选择其作为用户偏好进行学习。
2 URLP方法提出
2.1URLP基本框架
如图1所示,首先由用户信息和交易记录抽取用户-费用、用户-位置、用户-用户矩阵。根据用户-费用、用户-位置矩阵,可以建立车主(car)、位置与时间(p,t)、乘客(pas)关系,其中车主和乘客统称为用户。每个用户有一个费用记录(pay),即乘客付出过的车费或车主得到的车费。根据用户-用户矩阵及上述用户与位置、时间关系,可以建立一个基于位置的社会化网络。最后根据用户-位置-时间-费用关系及基于位置的社会化网络,计算用户间位置相似度、信任值、费用偏好度,应用自适应方法调节三部分比重,产生推荐列表。
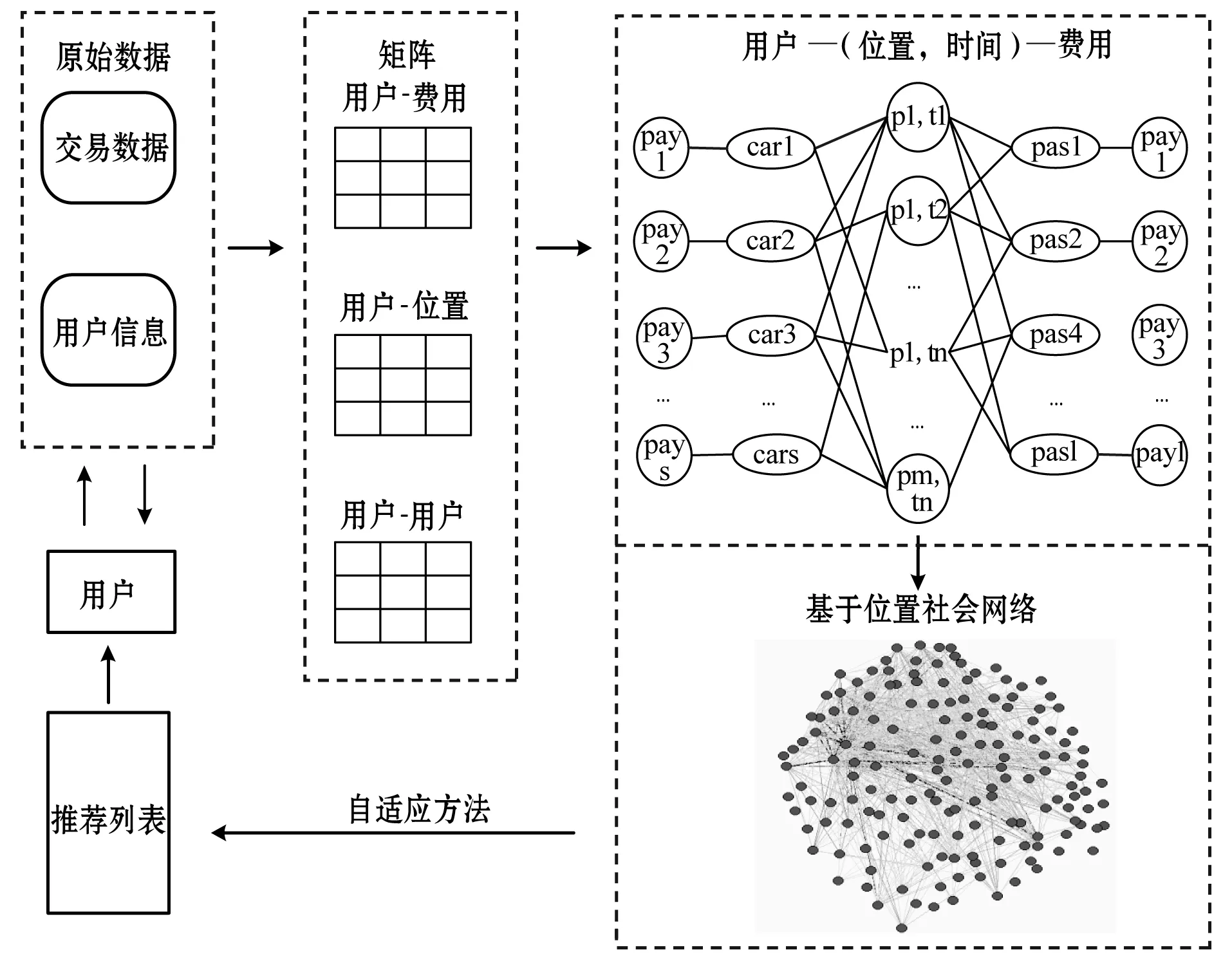
图1 研究框架
2.2 符号描述
由于拼车的车主和乘客的数据集的组成相同,故把车主和乘客统称为用户。对车主出行路线的描述采用化线为点的方式,由起点每隔x(x根据具体实例及推荐精度要求选取)米选取一点,直至终点,则车主的路线化为位置点集。对于乘客的路线,由于乘客较为关注的是在什么地点上车和在什么地点下车,故只选取起点和终点作为其位置点集。对时间的处理,每隔y(y根据具体实例及推荐精度要求选取)分钟化为一组,则每个位置点对应一个时间分组。
例如,已知车主路线和乘客路线,假设x取500,y取30。对于车主路线,由起始点p0、出发时间t0开始,每隔500米记录一点(pi,ti),pi用经纬度表示,ti为经过pi的时间点,对应属于某一时间分组。例如:一点((121.540 143,38.873 345),0725),其中前一项表示一点东经121.540 143度,北纬38.873 345度,0725表示7:25。假设0725对应时间分组2 (7:00-7:30),则该点数据可被表示为((121.540 143,38.873 345),2)。
同理处理乘客路线,不同之处是乘客位置只记录起始点和终点。用上述方法处理路线数据,然后就可以根据位置点集进行位置相似度计算,具体计算步骤见2.3.1节。
2.2.1 符号表示
URLP方法中使用的符号含义如表1所示。
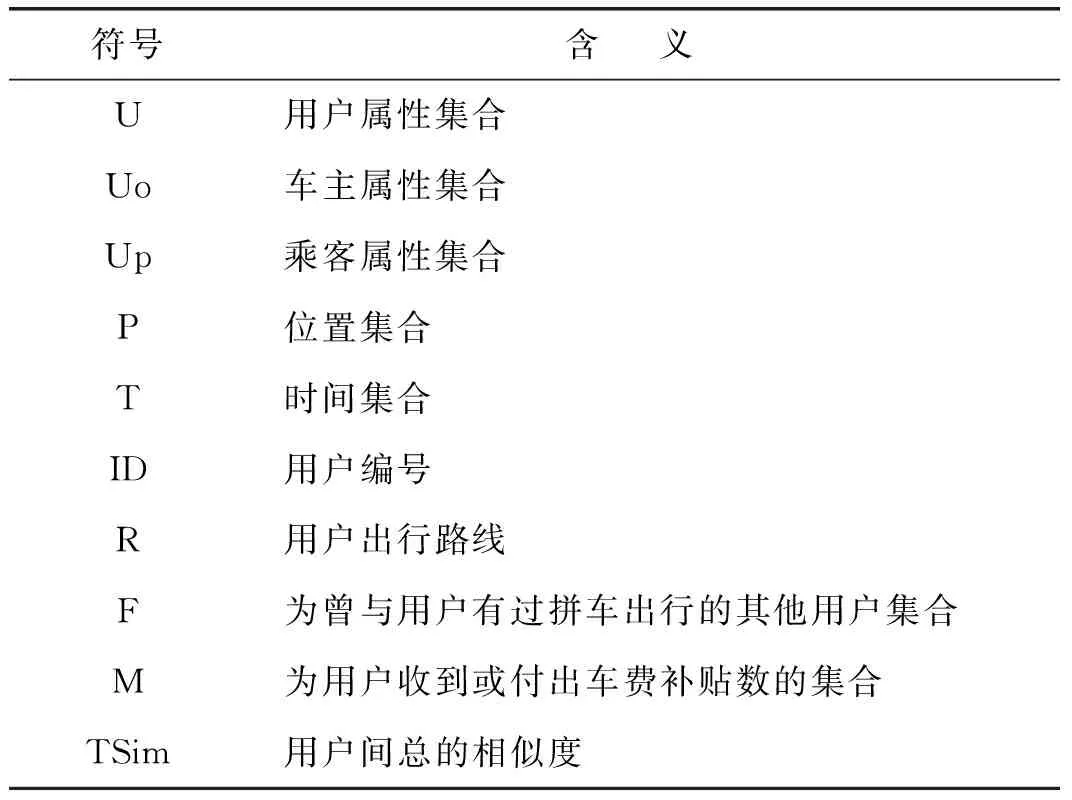
表1 符号及含义
2.2.2 集合定义
定义1 对于用户k的每次出行,其路线Rk都可以用位置和时间表示:
Rk=(Pk,Tk)
(1)
其中,Pk表示用户k有近期出行记录的位置点的集合,Tk表示Pk中各位置点对应的各时间段。
定义2 用户位置与时间属性用集合U表示,用户分为车主和乘客,Uo为车主属性集合,Up为乘客属性集合。则用户k的属性可以表示为:
Uk=(IDk,Rk)
(2)
定义3 根据用户k最近拼车记录,为曾与用户有过拼车出行的其他用户集合Fk表示为:
Fk=(ID,times)
(3)
其中,ID为与用户k有过拼车记录的其他用户编号集合,times为该集合中用户与用户k对应的拼车次数。
定义4 根据用户k最近拼车记录,为用户收到或付出车费补贴数的集合Mk表示为:
Mk=(pay,times)
(4)
其中,pay为用户付出或得到的车费补贴数的集合,times为该集合中对应车费补贴数在最近历史记录中出现的次数。
2.3URLP方法实现
2.3.1 位置区域划分
URLP方法针对长期短途用户做出推荐,故相似度高的用户必然位于同一区域。为了降低方法复杂度,首先根据要为之推荐的那名车主的位置,划分一个适当大小区域,抽取该区域所有乘客数据进行推荐。也就是说,每为一名车主推荐都根据该车主位置进行一次用户群划分。具体区域划分规则需要根据城市大小、交通状况等做具体分析。例如,为大连市某区车主A推荐时,根据大连市大小、交通状况,可以以A常签到位置连线为中心线东西各扩充2 km,选择常签到位置在这个区域的乘客作为待选用户进行下步计算。在以下步骤中认为用户常活动区域相同,为具有上下班拼车可能的潜在用户群。
2.3.2 基于位置的相似度计算
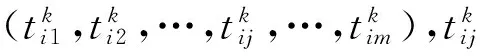
步骤2 根据文本挖掘中提取文章关键词的技术TF-IDF方法处理用户k的路线集合R。
(5)
(6)
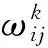
(7)
步骤3 对于经过TF-IDF技术处理过的用户属性集合Uk=(IDk,Rk),其中:
Rk=(pk1,pk2,…,pki,…,pkn)
(8)
(9)
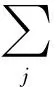
(10)
(11)
步骤4 对用户k位置向量Rk进行标准化处理:
(12)
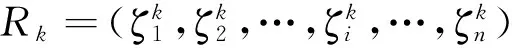
步骤5 根据文献[19]中证明的基于位置的相似度算法,基于本模型特点进行修改后,车主x与乘客y基于位置的相似度:
(13)
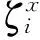
2.3.3 基于用户间隐性社交网络的信任值计算
车主与乘客进行一次拼车,相当于进行了一次“交流”或者“合作”,从而建立一种隐性社交圈。“合作”次数多的用户间会更加熟悉,对于各自习惯、守时程度等都有较好适应性,从而建立一种信任关系。根据最近历史记录中用户的拼车记录,建立用户间社交网络,为车主个性化推荐“合作”次数多的乘客可以提高推荐的满意度。特别注意,这里的历史记录时间为近期(具体时间段根据具体实例选取),因为用户间的信任可能随着时间发生转移。本文用户社交网络为一个稀疏的无向非加权网络,且包含多个连通子网,但不考虑“朋友”的“朋友”这种间接关系对于推荐的影响。考虑到仅有过一次“合作”的用户间可能不存在这种信任。仅有的一次“合作”可能为偶然且相互并不满意,所以没有出现第二次“合作”。在数据预处理时将所有大于0的“合作”次数减1。在计算用户的相似性时,为凸显“合作”次数的影响,本文使用了平方根函数来处理使其值在[0,1]区间,常见的处理函数还有指数函数、线性函数和对数函数等。这里我们不给予详述,可参考文献[20]。则用户x与用户y的信任值为:
(14)
其中,timesxy车主x和乘客y的近期合作次数。
2.3.4 用户关于车费补贴偏好的计算
另一个对于拼车出行有影响的是车费补贴多少。有的车主愿意免费搭载顺路的乘客,有的车主却愿意为了获得较高的车费补贴而绕路。因此,为了提高推荐满意度,需要根据车主近期记录中对于车费补贴多少的偏好来决定为车主推荐哪些乘客。根据边际效益递减原则[21],可以选取或根据历史数据拟合合适函数,描述用户对于车费补贴的偏好。用户对于车费补贴多少的偏好值MP可表示为:
(15)
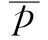
2.3.5 自适应产生推荐列表
总相似度的计算综合了位置、社交、车费补贴对用户行为的影响:
(16)
3 实验与结果分析
3.1 实验数据
本文实验数据来自志愿者,数据分为GPS数据和拼车数据两部分。数据预处理时需根据车主位置划分合适大小区域,选取该地区所有乘客作为备选,整理车主和该区域乘客路线及交易数据输入URLP方法,最后形成推荐。则实验应该选择一个固定区域。本文实验选择大连市白领较多的某区。在该地区选择100名拼车软件常用用户(10名车主,90名乘客),使用Google开发的手机软件My Tracks记录其60个工作日上下班时间段(6∶30-8∶30与16∶30-19∶30)GPS记录,该部分记录用于进行路线匹配,计算用户间关于位置的相似度。整理志愿者手机上实验期间,上下班时段拼车记录,用于挖掘用户间社交关系及对车费补贴偏好。
3.2 评价标准
本文推荐列表的形成采用推荐系统常用的Top-N方法[22]。实验中按 80∶20 的比例将用户拼车数据随机地分为训练集和测试集。用训练集中数据学习用户偏好做出推荐,如果测试集中车主与推荐列表中任一乘客有过拼车记录,认为推荐成功。为了确定URLP方法中最佳∂值并评价该方法,本文使用了对于推荐列表顺序敏感的平均准确率MAP(Mean Average Precision)和平均排序倒数MRR(Mean Reciprocal Rank)两个评价指标;为了将URLP方法与传统协同过滤推荐算法对比,使用了对列表长度敏感的准确率(Precision)评价指标。
3.2.1 平均排序倒数

(17)
其中,rankij表示为第i位车主推荐时推荐成功的排位为j,M为需要为之推荐的车主数量,N为推荐列表长度。
3.2.2 准确率与平均准确率
准确率衡量推荐的乘客有多少是准确的,即被车主接受的,用来衡量推荐的整体质量。平均准确率MAP是每个相关文档被检索后准确率的平均值的算术平均值[23]。当我们给车主x推荐拼车乘客,那么推荐列表最前面的最好应该是正确的推测。因此,我们使用MAP去强调高排名的相关用户。对于一个测试集,令R(i)是根据训练集数据为车主做出的推荐列表,T(i)是车主在测试集上的行为列表。准确率Precision:
(18)
平均准确率MAP:
(19)
其中,M为需要为之推荐的车主数量,ri表示为车主i推荐的乘客中被接纳的数量,Precisioni@k是车主i的推荐列表中排名为k的乘客的准确率。
3.3 实验步骤及结果分析
首先,我们根据收集的用户手机端数据,分析用户每天上班时间与下班时间。当每天早晨,用户位置发生较大位移开始记为其出发时间,每天下午,用户位置发生较大位移为其回家时间。选取其中一天,绘成散点图如图2所示。
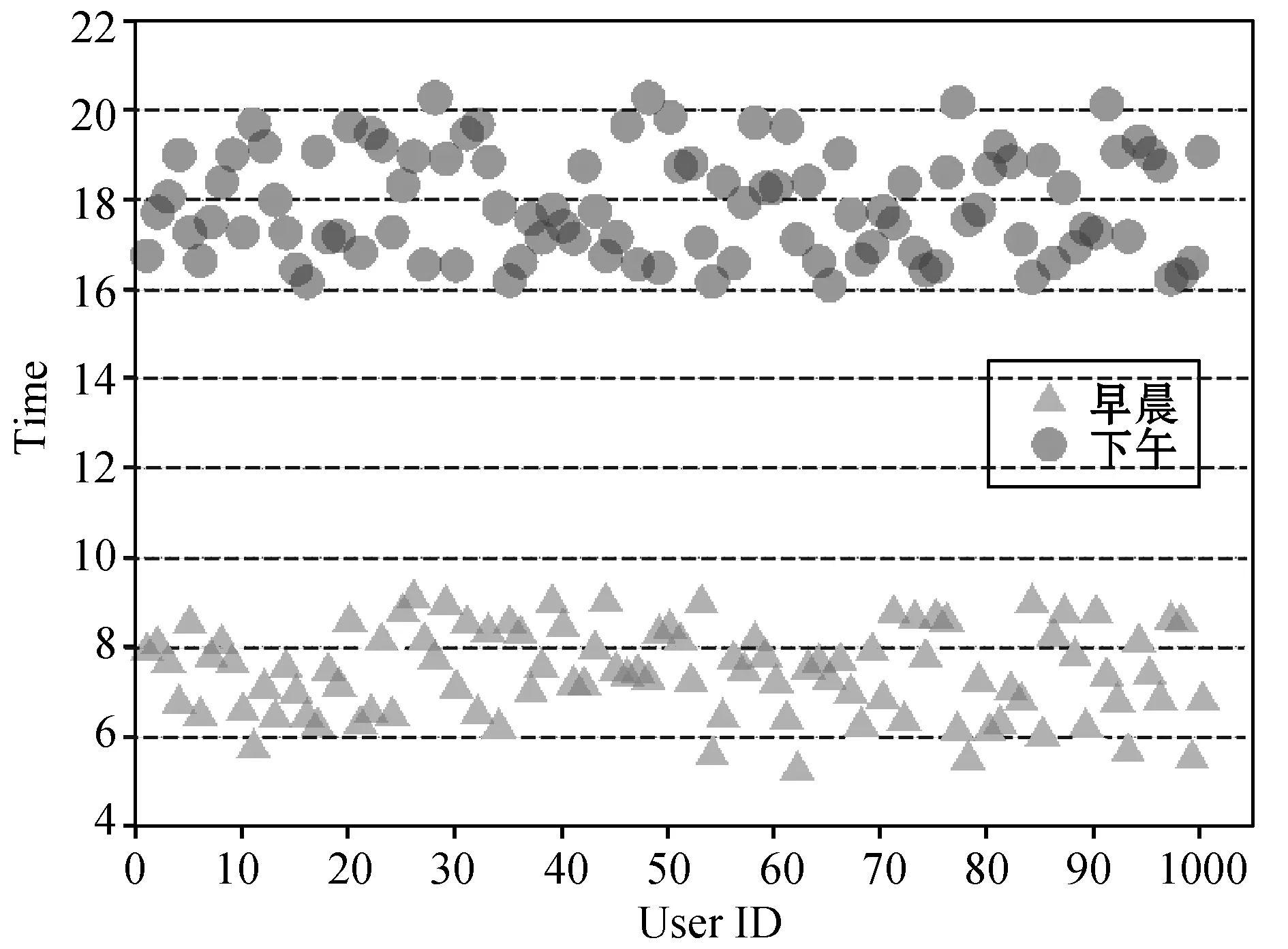
图2 用户每日上下班时间
由图2可以发现,用户早晨出行时间集中在6:30-8:30,下午出行时间集中在16:30-19:30。符合上班族拼车时间段较固定的预想。
为了测试URLP方法的有效性,实验前提出三个问题:
Q1:URLP方法中,∂如何影响推荐准确度?
Q2:如果仅考虑位置或者仅考虑社交和车费补贴,推荐效果如何?
Q3:针对以拼车为典型的资源共享平台中的用户推荐问题,与传统协同过滤算法相比,URLP方法是否更加有效?
对于Q1,首先取推荐列表长度N=10,计算不同∂取值下MRR、MAP值。

图3 ∂对MRR、MAP的影响
由图3可以看出,当∂=0时,MAP和MRR的值都较小,这说明当仅考虑社交和车费补贴时推荐效果不好;当0≤∂≤0.2,随着∂值增大,推荐结果的准确度大幅度提高,说明车主是否接受推荐的乘客与出行路线匹配度有关;当∂=0.7时,MAP和MRR取得最大值,推荐准确度最佳;当0.7≤∂≤1,随着∂值增大,MAP和MRR值减小,说明仅仅推荐出行路线匹配度高的乘客推荐效果也不好,这可能是由于有的乘客与车主虽然路线匹配度高,但是由于性别、社会背景、车费补贴等原因车主并不愿意与之拼车。当考虑社交因素时,有过多次拼车的车主和乘客,即社交关系紧密的用户间,在性别、社会背景等隐性影响拼车的方面上可以互相包容,更容易再次拼车。综上,首先可以确定在URLP方法中当∂=0.7时推荐效果最佳,其次可以初步确定考虑位置、社交、车费补贴作为用户偏好进行学习是必要的。
对于Q2,分别取推荐列表长度N为5、10、15、…、30,对比测试集计算推荐准确率,考虑下列三种情况:①仅考虑位置,即取∂=1;②仅考虑社交和车费补贴,即取∂=0;③URLP方法,考虑位置、社交和车费补贴三个因素,取∂=0.7。
由图4、图5可以看出,URLP方法准确率和召回率最高。当仅考虑位置时,即仅仅考虑路线的匹配程度,由于上述的用户的性别、社会背景等复杂不可量化因素的影响,推荐效果并不好。这是本文提出考虑其他两个因素的原因。当仅考虑社交和车费补贴时,受到拼车记录中非上班拼车记录的等原因的影响,推荐准确率比较低。我们收集的拼车记录仅仅为上下班时间段的拼车记录,但该时段也可能存在非上下班拼车,例如:根据车主历史拼车记录,在上班时段车主位置变化为由A到B,某日车主可能住在C地,则第二日其可能偶然进行了一次由C到B的拼车;车主也可能偶然进行了一次绕路较多的拼车。在仅考虑社交和车费补贴时,这种数据将大大降低推荐的准确率。本文的目的是为上下班车主推荐顺路拼车乘客,当仅考虑社交和车费补贴时,为了达到该目的,就需要排除干扰数据,故需要考虑位置因素。
对于Q3,采用常见的用社交网络改进协同过滤算法的方法TCF(Traditional Collaborative Filtering),认为与同一乘客有过拼车记录的车主为邻近用户,且拼车次数越多用户相似度越高,分别取推荐列表长度N为5、10、15、…、30对比测试集计算准确率。
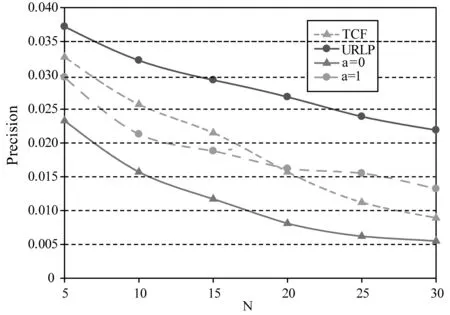
图4 不同因素对准确率影响
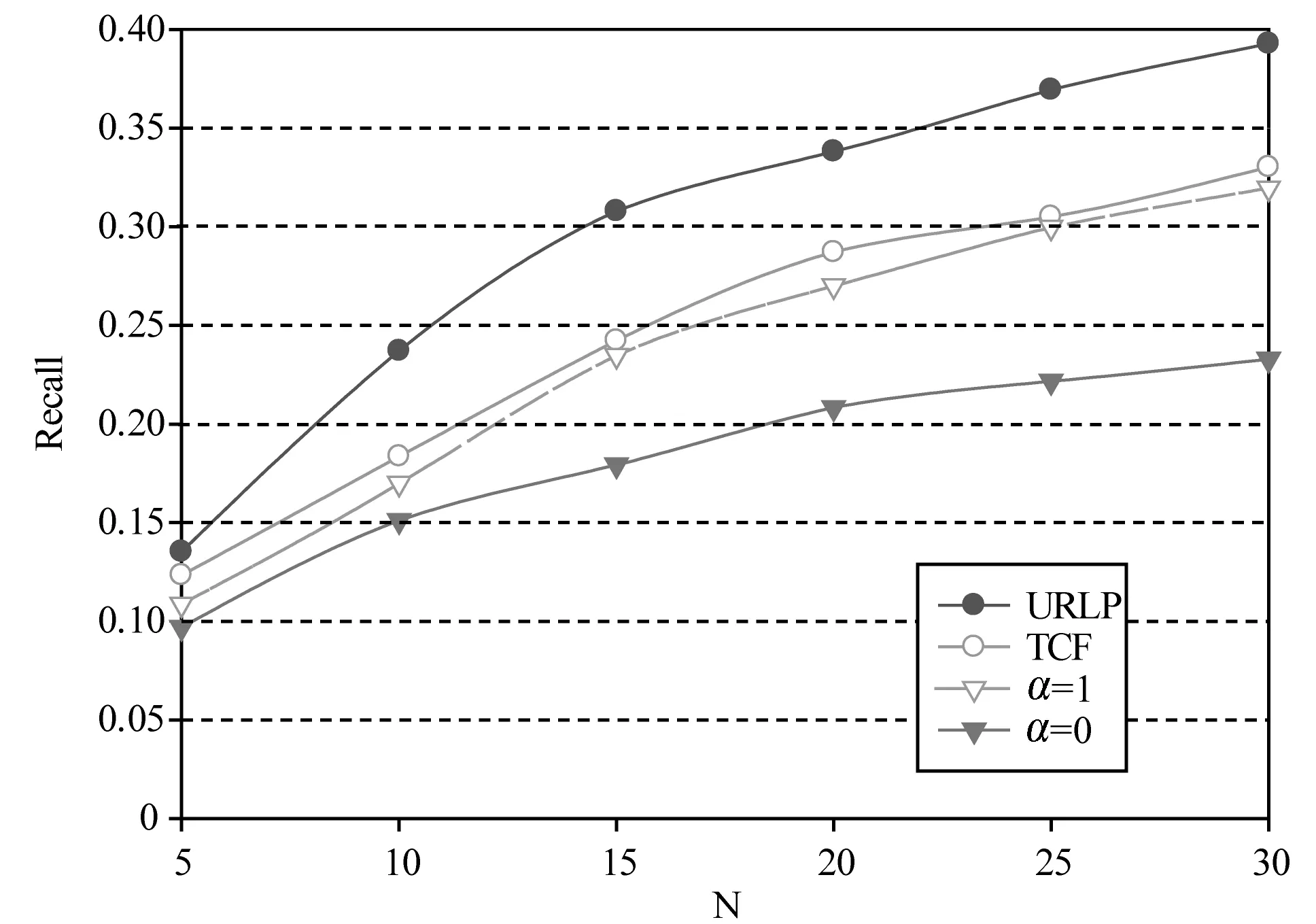
图5 不同因素对召回率的影响
如图4、图5所示,考虑社交因素的协同过滤方法推荐准确度比URLP方法差,但在推荐列表长度5≤N≤20时准确度高于仅考虑位置或者仅考虑社交和车费补贴;当推荐列表长度继续增加时,协同过滤方法准确度下降速率加快,说明列表增加的推荐多为无效推荐,仅仅用社交衡量用户间相似度不够准确。URLP方法召回率最高,TCF方法与仅考虑位置时召回率曲线接近,说明考虑社交和费用因素有助于提高推荐列表中被用户接受的推荐结果个数,传统协同过滤针对长期拼车问题适应性较差。URLP方法考虑因素比TCF方法更多,推荐准确率更高,也证明了考虑社交和费用的有效性。针对拼车用户推荐问题,如果想使用协同过滤方法需要考虑更多因素,有待研究者用更好方式改进传统协同过滤算法。
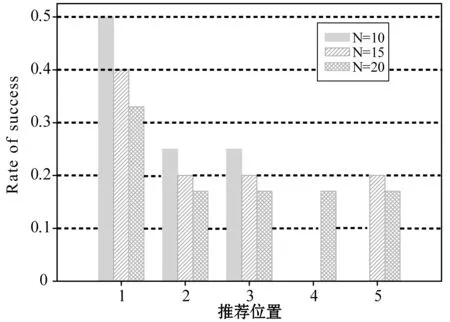
图6 不同推荐位置推荐成功率
图6为N取不同值时,推荐列表中不同位置推荐结果的接受比例。即:所有推荐表中排名第N(N=1,2,…,5)的推荐结果,与测试集对比,成功的结果占推荐列表个数的比例,某位置柱状图缺失是因为该位置没有被用户接受的结果。分析图6可以发现,列表中第一个推荐结果的接收比例最高,第二个结果其次。进一步证明了本文URLP方法对推荐结果的排名是有效的——高排名的推荐结果接受率更高。
4 结 语
本文针对搭乘共享中的长期需求,提出一种考虑用户位置、社交、费用三个偏好的个性化推荐方法,该方法可以根据用户不同,自适应改变三个因素权重,从而更好地作出推荐。通过对60个工作日通勤拼车用户的追踪获得数据,用实验验证了该推荐方法的有效性。这种推荐方法的提出,丰富了LBSNs推荐框架中路线相似度的计算方法,同时,对于拼车、众包快递等问题中信息过载问题的解决具有较大现实意义。
本文只是该研究的一小部分结果。首先对于本文选取的会影响用户行为的因素只是较重要的三个,其他因素例如用户完成订单数量、其他用户评价等都可能产生影响。如何更合理筛选影响因素、如何学习量化筛选出的因素等都是下一步需要解决的问题。其次对于本文已经选择的三个因素,如何更准确模型化也需要进一步研究。例如,如何更准确计算路线间相似度。
[1] 蔡余杰,黄禄金. 共享经济[M]. 北京:企业管理出版社, 2015: 1-15.
[2] 王茂福. 拼车的发展及其效应[J]. 中国软科学, 2010(11): 54-61.
[3] Friginal J, Gambs S, Guiochet J, et al. Towards privacy-driven design of a dynamic carpooling system[J]. Pervasive and Mobile Computing, 2014, 14: 71-82.
[4] Boukhater C M, Dakroub O, Lahoud F, et al. An Intelligent and Fair GA Carpooling Scheduler as a Social Solution for Greener Transportation[C]//2014 17th IEEE Mediterranean Electrotechnical Conference (MELECON), 2014: 182-186.
[5] Huang S c, Jiau M K, Lin C H. A Genetic-Algorithm-Based Approach to Solve Carpool Service Problems in Cloud Computing[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(1): 352-364.
[6] Knapen L, Yasar A, Cho S, et al. Exploiting graph-theoretic tools for matching in carpooling applications[J]. Journal of Ambient Intelligence and Humanized Computing, 2014, 5(3): 393-407.
[7] Hartman I B A, Keren D, Dbai A A, et al. Theory and Practice in Large Carpooling Problems[J]. Procedia Computer Science, 2014, 32: 339-347.
[8] Hussain I, Knapen L, Galland S, et al. Organizational and Agent-based Automated Negotiation Model for Carpooling[J]. Procedia Computer Science, 2014, 37: 396-403.
[9]KnapenL,HartmanIBA,KerenD,etal.Scalabilityissuesinoptimalassignmentforcarpooling[J].JournalofComputerandSystemSciences, 2015, 81(3): 568-584.
[10]GallandS,KnapenL,YasarAUH,etal.Multi-agentsimulationofindividualmobilitybehaviorincarpooling[J].TransportationResearchPartC:EmergingTechnologies, 2014, 45: 83-98.
[11]QuerciaD,LathiaN,CalabreseF,etal.RecommendingSocialEventsfromMobilePhoneLocationData[C]//2010IEEE10thInternationalConferenceonDataMining(ICDM), 2010: 971-976.
[12]ZhengY,ZhouX.ComputingwithSpatialTrajectories[M].NewYork:Springer, 2011: 63-107.
[13]YangD,ZhangD,ChenL,etal.NationTelescope:Monitoringandvisualizinglarge-scalecollectivebehaviorinLBSNs[J].JournalofNetworkandComputerApplications, 2015, 55: 170-180.
[14]BaoJ,ZhengY,WilkieD,etal.Recommendationsinlocation-basedsocialnetworks:asurvey[J].GeoInformatica, 2015, 19(3): 525-565.
[15]ZhengY,ZhangL,MaZ,etal.Recommendingfriendsandlocationsbasedonindividuallocationhistory[J].ACMTransactionsontheWeb, 2011, 5(1): 1-47.
[16]LiaoHY,ChenKY,LiuDR.Virtualfriendrecommendationsinvirtualworlds[J].DecisionSupportSystems, 2015, 69: 59-69.
[17]GriesnerJB,AbdessalemT,NaackeH.POIRecommendation:TowardsFusedMatrixFactorizationwithGeographicalandTemporalInfluences[C]//Proceedingsofthe9thACMConferenceonRecommenderSystems, 2015: 301-304.
[18]GaoH,TangJ,LiuH.Addressingthecold-startprobleminlocationrecommendationusinggeo-socialcorrelations[J].DataMiningandKnowledgeDiscovery, 2015, 29(2): 299-323.
[19] 刘树栋,孟祥武. 一种基于移动用户位置的网络服务推荐方法[J]. 软件学报, 2014, 25(11): 2556-2574.
[20] 何鹏,李兵,杨习辉,等.Roster:一种开发者潜在同行推荐方法[J]. 计算机学报, 2014, 37(4): 859-872.
[21]RollinsK,LykeA.TheCaseforDiminishingMarginalExistenceValues[J].JournalofEnvironmentalEconomicsandManagement, 1998, 36(3): 324-344.
[22]DeshpandeM,KarypisG.Item-BasedTop-NRecommendationAlgorithms[J].ACMTransactionsonInformationSystems, 2004, 22(1): 143-177.
[23]CraswellN.MeanReciprocalRank[M].NewYork:SpringerUS, 2009: 1664-1876.
PERSONALIZED RECOMMENDATION METHOD OF LONG-DISTANCE CAR SHARING BASED ON SOCIAL NETWORK
Zhong Qiuyan Li Yueyang Chu Xiang
(InstituteofInformationManagementandInformationTechnology,FacultyofManagementandEconomics,DalianUniversityofTechnology,Dalian116024,Liaoning,China)
In the service industry such as automobile, lodging and so on, the personalized recommendation method with the sharing service is insufficient, which reduces the user’s physical examination. In this paper, take the sharing problem as an example, consider the location, social, cost three factors, proposed URLP method for the user to recommend long-term cooperation object. Firstly, the location similarity between the owner and the passenger is calculated based on the user behavior matrix. Secondly, the social network based on location is established through historical transaction data learning, and then fits the user’s fare preference function based on recent transaction records. Finally, the recommendation lists are generated adaptively according to the influence of three kinds of factors. Experimental results show that the URLP method has good accuracy. Although, URLP method to car sharing as an example, but the method can also be applied to crowdsourcing express and distribution and other fields.
Car sharing Personalized recommendation LBSNs TF-IDF
2016-02-04。国家自然科学基金重点项目(71533001)。仲秋雁,教授,主研领域:管理信息系统。李岳阳,硕士生。初翔,博士生。
TP3
A
10.3969/j.issn.1000-386x.2017.04.045
猜你喜欢
湖北汽车工业学院学报(2024年2期)2024-07-31 00:00:00
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
发明与创新·小学生(2018年12期)2018-12-29 09:05:34
发明与创新(2018年47期)2018-12-19 03:41:18
小天使·二年级语数英综合(2015年4期)2015-04-20 11:39:40
创业家(2015年5期)2015-02-27 07:53:24
创业家(2015年5期)2015-02-27 07:53:22
创业家(2015年5期)2015-02-27 07:53:21
