
一种基于视觉词袋模型的图像检索方法
2017-04-24 10:25:07汪友生王雨婷
计算机应用与软件 2017年4期
金 铭 汪友生 边 航 王雨婷
(北京工业大学电子信息与控制工程学院 北京 100124)
一种基于视觉词袋模型的图像检索方法
金 铭 汪友生 边 航 王雨婷
(北京工业大学电子信息与控制工程学院 北京 100124)
为了提高图像检索的效率,提出一种基于视觉词袋模型的图像检索方法。一方面在图像局部特征提取算法中,使用添加渐变信息的盒子滤波器构造尺度空间,以保留图像更多的细节信息,另一方面在特征表达时仅计算一次特征点圆形邻域内的Haar小波响应,避免了Haar小波响应的重复计算,并在保证描述子旋转不变性的同时做降维处理。同时,以改进k-means对特征库聚类构建加权的视觉词典,基于概率计算的方式选取k-means初始聚类中心,降低了传统k-means聚类效果对初始聚类中心选择的敏感性。实验结果表明该方法比传统方法具有更高的效率,特征提取速度提高48%左右,查准率提高2%以上。
图像检索 视觉词袋模型 局部特征提取 特征聚类
0 引 言
与图像的全局特征相比,图像的局部特征在面对复杂背景、噪声干扰较大、光照条件变化、存在多个事物和语义复杂等场景时都能更好地描述图像,近年来广泛使用于图像处理任务中[1-5]。直接使用局部特征进行图像分类、图像检索时,由于图像库中每一幅图像所检测到的特征点数目不统一,并且常用局部特征如SIFT、SURF、DAISY特征等都是高维特征[6-9],每幅图像都由多个不同的高维特征表示,逐一匹配计算相似性时效率很低。为了解决上述问题,文献[10]首先将视觉词袋模型BoVW(Bag of Visual Words)运用到图像处理领域。视觉词袋模型将图像库中所有图像特征提取后聚类成为k个视觉单词,将每幅图像以各个单词出现频率表示为k维向量[11-12]。这样可以很好地解决不同图像提取出的局部特征不统一的问题,并且能将多幅图像用一定量的视觉单词表示,节约空间,处理方便,可扩展性强,可以很大程度上提高多图像处理任务的效率。
视觉词袋模型效率的高低取决于图像特征的选取。比如采用SIFT的改进算法SURF,其处理速度比SIFT提高了三倍左右[7]。然而SURF算法用积分图像和盒子滤波代替高斯滤波,虽然提高了速度,但也损失了图像中的细节信息[7,13-14];SURF描述子生成时,需要先计算一次圆形邻域的Haar小波响应得到特征点的主方向,再计算一次方形邻域的Haar小波响应以得到64维向量,这样的重复计算过程对SURF的效率有很大影响[7,15]。
为此,本文提出一种基于视觉词袋模型的图像检索新方法,使用改进的SURF算法提取图像特征,以改进k-means算法聚类建立词袋模型,基于此词袋模型实现图像检索,提高图像检索的效率。
1 视觉词袋模型
建立视觉词袋模型的步骤主要包括三部分:图像特征提取、视觉词袋学习以及利用视觉词袋量化图像特征,并由词频表示图像。首先对图像库中所有的图像提取局部特征,存入特征库。要求选取的特征对图像的代表性强,并且提取速度快。本文使用改进的SURF特征,其比SURF特征对图像更具代表性,并且提取效率更高。然后统计图像数据库中的所有特征,用聚类算法聚类结果组成词袋。为了使聚类结果更稳定,本文使用改进的k-means聚类算法,采用一种基于概率的方式来选取初始聚类中心,削弱初始聚类中心选择随机性对聚类效果的影响。最后将一幅图像映射到视觉词袋,根据视觉词袋中每个单词在这幅图像中出现的频率,将每幅图像表示成k维向量。不同图像带给人的视觉效果不同,所包含的视觉单词种类及频率也应不相同,但相近的图像包含的视觉单词及频率是相似的,根据这个原则可以通过计算k维向量之间的距离来计算图像之间的相似度,实现图像检索任务。考虑到不同的视觉单词对一幅图像的描述作用不同,图像表示时不区别对待每个视觉单词,会对图像检索的效果有所影响,所以在这里用加权的视觉词典来表示图像。本文使用视觉词袋模型进行图像检索的流程如图1所示。

图1 检索流程图
2 一种改进的图像局部特征提取算法
建立视觉词袋模型,首先要提取图像特征。SIFT算法因其具有较强的匹配能力和鲁棒性而被广泛应用,但它计算复杂、实时性差,用于图像检索时导致用户体验变差。与SIFT相比,SURF算法在尺度空间生成时使用了积分图像和盒子滤波,将图像与高斯二阶微分模板的卷积过程简化成了简单的积分图像盒子滤波运算,降低了SIFT算法的复杂度,提高了特征点检测和匹配的实时性,但同时由于盒子滤波对高斯二阶微分模板的简化损失了图像细节信息,而降低了匹配准确度。并且,SURF特征描述子表达时计算了两次Haar小波响应,一定程度上影响了算法的效率。为此,本文使用添加渐变信息的盒子滤波模板[13-14],该模板与SIFT和SURF的9×9滤波模板比较如图2所示。可以看出,与SURF盒子滤波模板相比,本文算法模板与SIFT的高斯二阶微分模板更加接近,并且模板仍由简单的矩形框构成,保证算法在高效运算的同时保留图像的细节信息。将滤波模板中矩形框的四个顶点标上字母,每个字母代表相应点的积分图像值,设三个不同方向模板的面积分别为Sxx、Syy、Sxy(Sxx=Syy),三个方向盒子滤波的响应值为Dxx、Dyy、Dxy,则:
(B+F-D-E+K+N-L-M)+(-1)×
(E+H-F-G+I+L-J-K)+(-2)×
(G+J-H-I)
(1)
(B+F-D-E+K+N-L-M)+(-1)×
(E+H-F-G+I+L-J-K)+(-2)×
(G+J-H-I)
(2)
(3)

图2 SIFT、SURF、本文算法滤波模板比较
其中,Sxx、Syy、Sxy的大小可以根据模板的大小直接得到,而字母代表的积分图像值可通过查积分图像值表得到。由上述过程可知,SURF模板对大块区域赋单一值进行处理,而改进的模板在矩形区域里填入了渐变的值,使处理过程更近似于高斯二阶模板滤波过程,保留了更多的图像细节信息,并且滤波计算仍然很简单,计算量没有大的增加。
构造尺度空间时,将9×9模板作为尺度空间金字塔中的初始层(由于每一层的响应长度为模板大小的1/3,即初始层的响应长度l0=3),并在每一层都采用与SURF算法一样的模板大小,如图3(a)所示。模板大小变化时,给盒子滤波器中填充渐变值遵守初始层响应为模板大小的1/3的原则,先将颜色最深的地方填充后,再填充渐变值。图3(b)为yy方向盒子滤波模板大小由9×9变为15×15的示例。
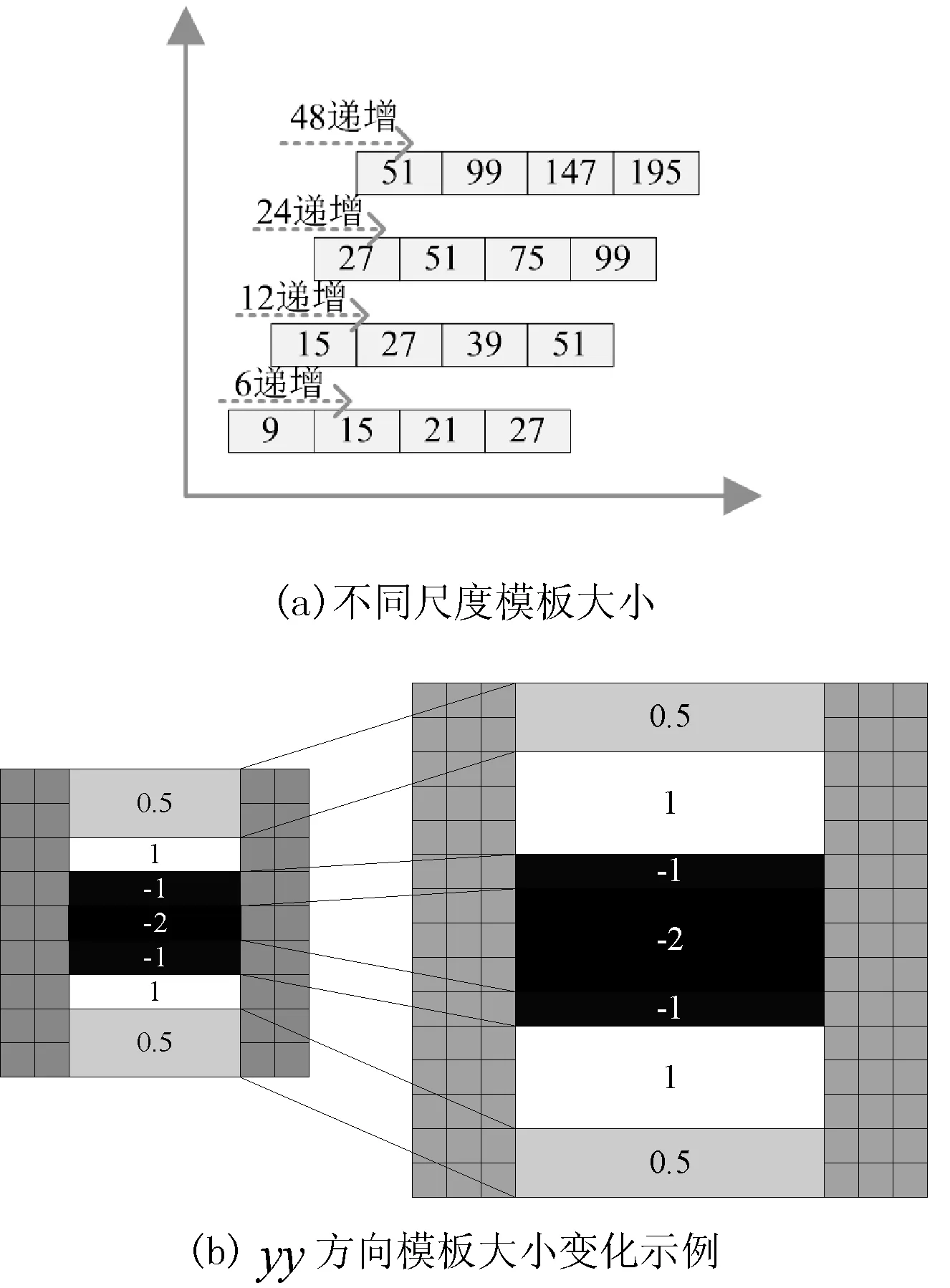
图3 不同尺度模板大小变化
得到不同大小的模板后,图像尺寸不变,用不同大小的模板与图像进行卷积,构成三维尺度空间。在三维尺度空间中,每个3×3×3的局部区域里,使用非最大值抑制将像素点与其周围的26个像素点进行比较来检测极值点,并记下极值点的位置作为特征点。
在传统SURF特征描述子计算时,为了保证算法的旋转不变性,通过计算特征点周围圆形邻域内Haar小波响应的大小,确定每个特征点描述子的主方向;接下来又需要计算一次特征点周围方形邻域内的Haar小波响应,得到64维的特征向量。这样的重复计算势必对算法的效率有所影响。本文对每一个特征点,以特征点为圆心,以10S(S为样本所处空间的尺度值)为半径作圆形邻域,在该圆形邻域内统计Haar小波响应值,能同样实现局部特征描述子的计算和表达。具体做法是:以尺寸为2S×2S的Haar小波模板对圆形邻域内图像进行处理,计算邻域内所有特征点在x、y方向的Haar小波响应,并赋给每个向量不同的高斯权重,权重与距离成正比,越靠近圆心(贡献值越大)的特征点赋值权重越大。以一个圆心角为π/4的扇形旋转遍历整个圆形邻域,如图4所示,共有8个扇形窗口,每一次滑动到一个窗口内时,统计该窗口内Haar小波响应值的和。设dx、dy分别代表水平和垂直方向的Haar小波响应,mi为方向矢量,θi为方向矢量的角度,则:
(4)
(5)
(6)
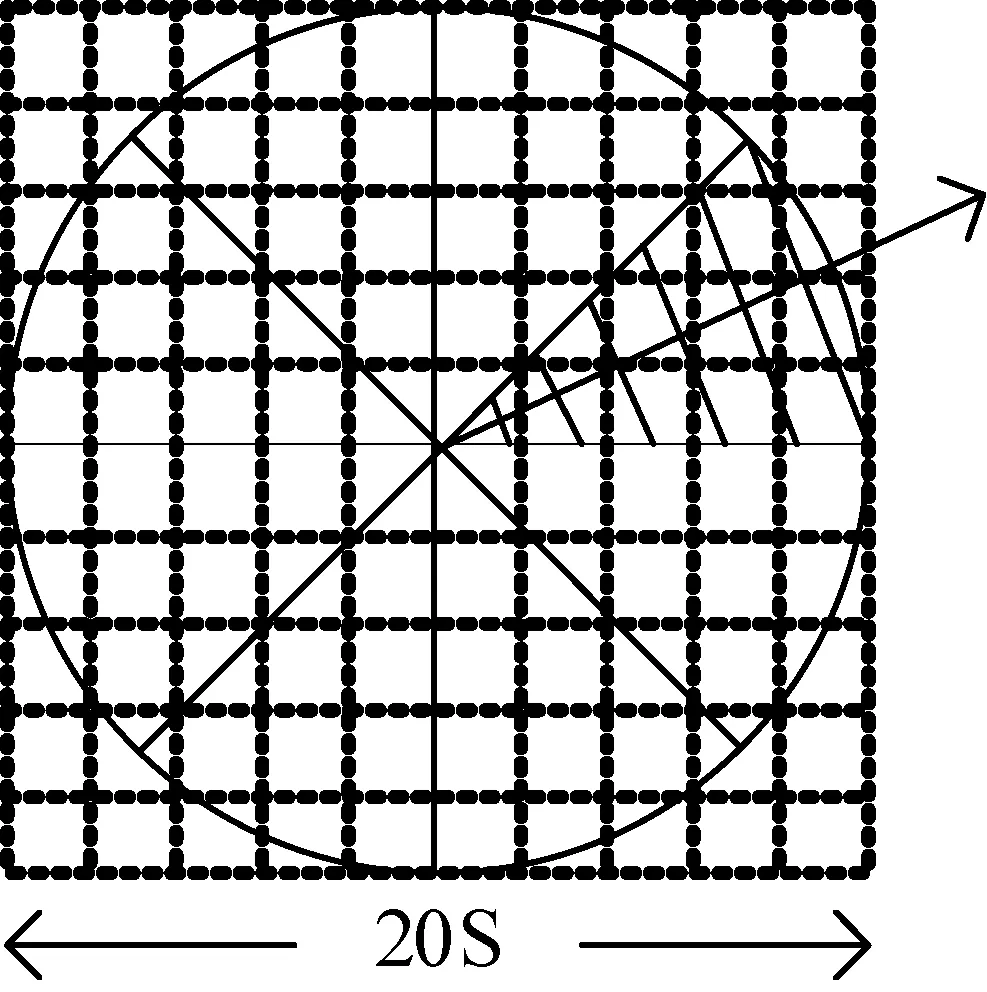
图4 本文算法特征表达
为了保证描述子的旋转不变形,比较得到的8个窗口的mi矢量的模值,按从大到小的顺序排序,排第一位的(矢量最长)mi的方向为特征点的主方向;按照mi值序列的顺序,将对应的8个Vi矢量排列,得到8×4=32维的特征描述子。改进的局部特征描述子由原算法的64维变成了32维,并且避免了Haar小波响应的重复计算,提高了算法效率。生成描述子时,从主方向开始按照mi值递减的顺序生成特征向量,主方向的权重最大,从而保证了旋转不变性。
综上所述,本文的特征提取算法对图像表达能力更强,并且提取特征时间更短,更适合于图像检索。
3 加权视觉词典生成
按照上述步骤得到图像库中所有图像特征后,按照传统词袋模型构造的步骤,应当用k-means聚类算法对所有特征进行聚类。但k-means算法聚类性能的好坏依赖于k个初始中心点的选择,当k个初始中心的位置在数据空间中分布不均匀时,将导致收敛迭代所需的次数增多,甚至陷入局部最优,而得不到准确的聚类结果。为了减少初始聚类中心对聚类性能结果的影响,选择初始聚类中心时必须遵从一个原则:初始的聚类中心之间的距离应当尽可能远[16-18]。基于这个思想,结合本文上述工作,使用改进的k-means算法对特征聚类生成视觉词典,具体步骤如下:
步骤1 从特征数据集S={s1,s2,…,sm}中随机选取一个种子点c,作为一个初始聚类中心;
步骤2 对于数据集S中的每一个点,计算它与最近聚类中心的距离D(si,c),其中i≤m;
步骤3 按照式(7)计算下个点被选为聚类中心的概率,选择概率最大的点作为下一个聚类中心c;
(7)
步骤4 重复步骤2和步骤3,直到得到k个初始聚类中心:C={c1,c2,…,ck};
步骤5 计算数据集S中非聚类中心的对象到k个聚类中心的欧式距离,根据距离将它们分配到最相似的类中;
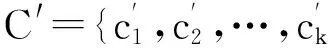
步骤7 不断重复步骤5和步骤6,计算直到标准测度函数收敛至最小值,标准测度函数的计算公式如式(8):
(8)
步骤8 步骤7得到的k个聚类中心定义为k个视觉单词,k个视觉单词共同构成视觉词典。
以这种计算概率的方法选择初始聚类中心,避免了经典k-means的初始聚类中心随机性对聚类效果带来的影响,使生成的词典对图像数据库更具有代表性。
由于不同的视觉单词对一幅图像的描述作用是不同的,图像表示时不区别对待每个视觉单词,会对图像检索的效果有所影响。所以在这里使用tf-idf加权方法,用加权的视觉词典来表示图像。tf-idf是信息检索领域常用的一种权重机制,其思想主要是基于统计方法。tf指词频(TermFrequency),如果某个视觉单词在一幅图像中出现的频率tf高,并且在其他图文件频率(InverseDocumentFrequency),如果在图像库中包含视觉单词w的图像很少,则w的idf值越大,说明视觉单词w具有很好的区分能力,应当增大它的权重。根据以上规则,用带有权重的视觉词典将图像库中的N幅图像表示为向量,图像In表示为:Wn=[wn1,wn2,…,wnk]T,其中:
wj=tfnj×idfnjn=1,2,…,Nj=1,2,…,k
(9)
得到N幅图像的向量表示后,建立倒排索引表,至此视觉词袋模型建立完成。
4 实验结果及评价
4.1 图像特征提取实验
对一张图像,用SURF算法和本文算法提取特征,提取结果对比如图5所示。对图像SURF特征提取时特征点数量为1 677个,耗时1.056秒,本文算法提取时特征点数量为1 965个,耗时仅0.652秒。由于本文算法使用了与高斯二阶微分模板更接近的盒子滤波器,更多地保留了图像的细节信息,检测出的特征点更多,并且在描述子生成时只计算了一次Haar小波响应,这样虽然检测出的特征点更多,但是运行时间却缩短了。为了证明这一点,从Corel标准图像库中随机选择10幅图像,统计检测出的特征点数量和提取时间,如表1所示。

图5 特征提取对比
表1的数据表明,本文算法在提取图像特征点数量增加的同时,平均提取时间缩短了48%左右。特别是本文方法提取的特征不仅效率大大提高,而且对图像也更具代表性,在多幅图像检索任务中,更能体现出本文算法的优势。
4.2 图像检索实验
使用Corel标准图像库对本文算法进行图像检索测试,Corel图像库中有10类图像,分别为:AfricanPeople、Beach、Buildings、Buses、Dinosaurs、Elephants、Flowers、Horses、Mountains、Food,每个类别中都有100张图像。如图1中的步骤,检索时用同样的词袋构建算法将待检索图像表示为视觉单词出现频率的向量,计算该向量与图像库中各个向量的欧氏距离,按距离从小(最相似)到大返回与待检索图像相似的L幅图像。图6是一个检索示例。

图6 检索示例
在词典大小K值的选择方面,K值越大,词典中包含视觉单词数量越多,对图像库的代表性越强。测试L=10时本文算法在50、100、150、200这几种词典大小时每类的平均查准率,如图7所示。可以看出在K=200时平均查准率反而下降了,并且生成词典时K=150比K=100耗费的时间增加了将近一倍左右,所以综合查准率和检索效率,选择K=100来进行检索实验。
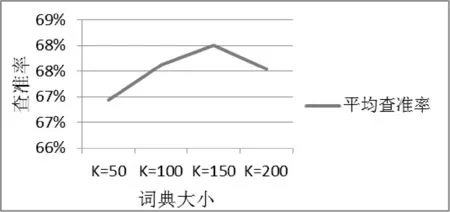
图7 不同词典大小时检索平均查准率
由于在检索过程中一般关心的都是检索返回结果中靠前的一些图像,故本文选择L=10、L=20两个参数统计实验结果。在每类图像中随机抽取20幅图像进行检索,统计每类平均的查准率,得到的结果如图8所示。
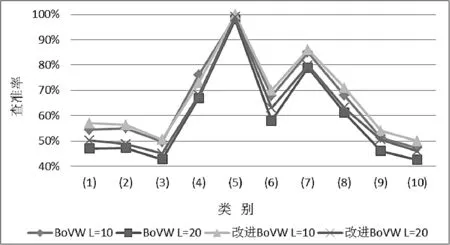
图8 不同算法检索查准率比较
从图8中可以看出,对于两种算法来说,返回图像数量为10张时每类的查准率都比返回数量为20张图像的查准率要高;本文改进BoVW的检索结果与原BoVW的检索结果相比,在取两种不同L值时查准率都有一定的提高,这是因为改进BoVW中的特征提取保留了图像更多的渐变细节信息,且改进k-means一定程度上提高了词袋聚类的稳定性。在类别(5)Dinosaurs中两种算法的检索效果最好,查准率几乎达到了100%,在类别(7)Flowers中查准率也达到了82.5%左右,然而因为这两种类别图像的渐变特征较少,本文特征提取算法并没有体现出很大的优势。除了在类别(4)中L=10时,本文方法比原方法查准率略有降低,在其他所有类别中本文改进算法的检索效果都要优于原算法。计算十类图像的平均查准率,在L=10时改进BoVW查准率比BoVW的查准率提高了2.2%左右,L=20时提高了4.1%左右。
5 结 语
为了提高图像检索的效率,从图像检索的关键技术入手,提出一种基于视觉词袋模型的图像检索方法。针对SURF算法提取图像特征点少、特征表达需重复计算Haar小波响应的问题,提出一种改进的局部特征提取方法,使用添加渐变信息的盒子滤波器构造尺度空间,并在特征表达时避免Haar小波响应的重复计算,同时保留了图像更多的细节信息,特征提取速度提高48%左右;通过改进k-means算法对特征库聚类构建加权的视觉词典,以概率计算的方式选取初始聚类中心,降低了传统k-means聚类效果对初始聚类中心选择的敏感性。改进的词袋比起改进前的词袋对图像库更具代表性,图像检索实验表明本算法构建词袋效率较高,同时查准率也提高2%以上。
[1] 何云峰,周玲,于俊清,等.基于局部特征聚合的图像检索方法[J].计算机学报,2011,34(11):2224-2233.
[2] 贾平,徐宁,张叶.基于局部特征提取的目标自动识别[J].光学精密工程,2013,21(7):1898-1905.
[3]KharchenkoV,MukhinaM.Correlation-extremevisualnavigationofunmannedaircraftsystemsbasedonspeed-uprobustfeatures[J].Aviation,2014,18(2):80-85.
[4] 薛峰,顾靖,崔国影,等.基于SURF特征贡献度矩阵的图像ROI选取与检索方法[J].计算机辅助设计与图形学学报,2015,27(7):1271-1277.
[5] 丘文涛,赵建,刘杰.结合区域分割的SIFT图像匹配方法[J].液晶与显示,2012,27(6):827-831.
[6]LindebergT.ScaleInvariantFeatureTransform[J].Scholarpedia,2012,7(5):2012-2021.
[7]BayH,EssA,TuytelaarsT,etal.Speeded-UpRobustFeatures(SURF)[J].ComputerVisionandImageUnderstanding,2008,110(3):346-359.
[8]TolaE,LepetitV,FuaP.DAISY:AnEfficientDenseDescriptorAppliedtoWide-BaselineStereo[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2010,32(5):815-830.
[9] 罗楠,孙权森,陈强,等.结合SURF特征点与DAISY描述符的图像匹配算法[J].计算机科学,2014,41(11):286-290,300.
[10]Fei-FeiL,FergusR,PeronaP.Learninggenerativevisualmodelsfromfewtrainingexamples:anincrementalBayesianapproachtestedon101objectcategories[J].ComputerVisionandImageUnderstanding,2007,106(1):59-70.
[11]AlfanindyaA,HashimN,EswaranC.ContentBasedImageRetrievalandClassificationusingspeeded-uprobustfeatures(SURF)andgroupedbag-of-visual-words(GBoVW)[C]//Technology,Informatics,Management,Engineering,andEnvironment(TIME-E),2013InternationalConferenceon.IEEE,2013:77-82.
[12]RochaBM,NogueiraEA,GuliatoD,etal.ImageretrievalviageneralizedI-divergenceinthebag-of-visual-wordsframework[C]//Electronics,CircuitsandSystems(ICECS),2014 21stIEEEInternationalConferenceon.IEEE,2014:734-737.
[13]HuangX,WangJ,ZhangM,etal.Gradual-SURF[C]//ImageandSignalProcessing(CISP),2011 4thInternationalCongresson.IEEE,2011:906-909.
[14] 张满囤,王洁,黄向生,等.Gradual-SURF算子的角点提取[J].计算机工程与应用,2013,49(10):191-194,200.
[15] 周燕,吴学文,刘娜.基于改进的SURF算法的视频总结方法[J].微型电脑应用,2015,31(10):65-68.
[16] 翟东海,鱼江,高飞,等.最大距离法选取初始簇中心的K-means文本聚类算法的研究[J].计算机应用研究,2014,31(3):713-715,719.
[17]AgarwalS,YadavS,SinghK.K-meansversusk-means++clusteringtechnique[C]//EngineeringandSystems(SCES),2012StudentsConferenceon.IEEE,2012:1-6.
[18] 赵春晖,王莹,MasahideKaneko.一种改进的k-means聚类视觉词典构造方法[J].仪器仪表学报,2012,33(10):2380-2386.
AN IMAGE RETRIEVAL METHOD BASED ON BAG OF VISUAL WORDS MODEL
Jin Ming Wang Yousheng Bian Hang Wang Yuting
(SchoolofElectronicInformationandControlEngineering,BeijingUniversityofTechnology,Beijing100124,China)
In order to improve the efficiency of image retrieval, an image retrieval method based on BoVW (Bag of Visual Words) model is proposed. On the one hand, in image local feature extraction algorithm, we use box filter with gradient information to form scale space, to retain more image details information. On the other hand, only the Haar wavelet response in the circular neighborhood of the feature point is calculated in the feature expression, which avoids the repeated calculation of the Haar wavelet response and reduces the dimension while guarantee rotational invariance. At the same time, using improved k-means clustering method to construct a weighted visual dictionary, the k-means initial clustering center is selected based on probabilistic calculation method, which reduces the sensitivity of the traditional k-means clustering to the initial clustering center selection. The experimental results show that the proposed method is more efficient than the traditional method, feature extraction speed is increased by about 48% and the precision is improved by more than 2%.
Image retrieval Bag of visual words model Local feature extraction Feature clustering
2016-03-08。金铭,硕士,主研领域:图像处理。汪友生,副教授。边航,硕士。王雨婷,硕士。
TP391.9
A
10.3969/j.issn.1000-386x.2017.04.042
猜你喜欢
科技风(2021年19期)2021-09-07 14:04:29
电子制作(2019年13期)2020-01-14 03:15:32
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
现代电子技术(2018年16期)2018-08-21 02:57:42
现代电子技术(2017年23期)2017-12-20 13:23:31
制造技术与机床(2017年10期)2017-11-28 05:20:43
计算机应用(2016年10期)2017-05-12 11:02:20
专利代理(2016年1期)2016-05-17 06:14:36
电测与仪表(2014年8期)2014-04-04 09:19:38
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
