
对等结构的混合集群的层次化存储策略研究
2017-04-24 10:24:49涂超凡张启飞陈应庄张昱昶刘二腾干红华张尉东郑贤榕
计算机应用与软件 2017年4期
涂超凡 张启飞 陈应庄 张昱昶 刘二腾 干红华 张尉东 白 凡 郑贤榕
1(浙江大学软件学院 浙江 宁波 315048)2(北京大学电子工程和计算机科学系 北京 100871)3(西北大学电子工程和计算机科学系 美国 埃文斯顿 60201)4(浙大网新中央研究院 浙江 杭州 310030)
对等结构的混合集群的层次化存储策略研究
涂超凡1张启飞1陈应庄1张昱昶1刘二腾1干红华1张尉东2白 凡3郑贤榕4
1(浙江大学软件学院 浙江 宁波 315048)2(北京大学电子工程和计算机科学系 北京 100871)3(西北大学电子工程和计算机科学系 美国 埃文斯顿 60201)4(浙大网新中央研究院 浙江 杭州 310030)
随着分布式存储系统的规模迅猛增长,能耗问题日益凸显。在存储集群混合低能耗节点已成为解决能耗问题的重要途径之一。针对如何在对等结构的混合集群中区别使用不同类型存储节点的问题,在一个对等结构分布式系统ZDFS上设计并实现了一种基于对等结构的层次化存储策略——虚拟节点分层重映射(VHR)。该策略不影响对等结构的高拓展特性,使系统可自动区分使用不同类型存储节点,可操作性强。实验在真实X86和ARM混合集群上进行。实验表明,VHR实验组运行良好,充分发挥了不同类型存储节点的优势,在性能降低不明显的情况下,整体能耗水平降低了44.8%。
存储系统 对等结构 混合集群 层次化
0 引 言
2020年的全球的数据量将从2013年的4.4 ZB 扩展到44 ZB[1],爆发增长的数据量必然伴随急剧增加的存储需求。业界对大规模存储系统进行了具体的实践,比如Google公司的GFS[2]、Amazon的Dynamo[3]以及开源的HDFS[4]。存储系统的规模迅猛增长使得存储系统的能耗问题日趋严重。一些大型存储系统的能耗占到整个数据中心能耗的三分之一以上[5-6]。相关人员在存储系统节能领域做了相关大量研究,主要可以分为软件节能技术与硬件节能技术两类[7]。
软件节能技术通过创造时机让设备、节点进入低能耗状态从而节能。Gurumurthi等人使磁盘依据负载 调整转速从而降低能耗[8];Harnik等人规律性地关闭周期性空闲的存储节点以此降低能耗[9];Leverich等人改变某种分布式存储系统的数据副本放置方法从而关闭空闲节点,降低9~50%系统能耗[10];Pinheiro等人把数据分为原始和冗余两种并放置到不同位置,关闭空闲节点实现能耗下降[11]。
硬件节能技术是指通过引入低能耗设备降低系统能耗。比如Szalay等人将SSD应用在辅助节点上,关闭普通节点以降低能耗[12];Hamilton构建适用于低能耗Athlon处理器的服务器机架结构以降低能耗[13];Vasudevan等人使用嵌入式芯片和快速闪存构建了一个7倍于普通机器能效的存储集群[14]。近年来,随着ARM的快速发展,搭载ARM的低能耗存储节点得以应用。Facebook公司在Open Vault冷区存储中使用一个4核ARM处理器驱动了15块硬盘,降低了系统能耗[15];Baidu公司开发了支持X86和ARM节点混合部署的云存储系统,存储密度提升了70%,TCO降低了25%[16]。
在存储集群混合低能耗节点已成为解决能耗问题的重要途径之一。目前进行混合节点的研究实践主要是基于主从结构,主从结构的分布式存储系统存在扩展性差、单点故障等问题。高扩展特性的对等结构的分布式系统如Dynamo[3]、Ceph[17]等受到日益重视,而对等结构的系统一般采用定位算法替换了传统的查文件分布表机制,这也带来了如何在对等结构的混合集群中区别使用不同类型存储节点的问题。针对这个问题,本文在一个对等结构分布式系统ZDFS[18]上进行了混合集群的层次化存储的研究。
1 ZDFS
ZDFS使用和Dynamo[3]相似的一致性哈希算法。ZDFS有三个主要组件:DataNode存储所有数据;Client暴露存储接口给上层应用,直接向DataNodes集群发起数据读写请求;Monitor负责维护存储节点集群全局信息,处理节点加入和离线事务。系统结构如图1所示。
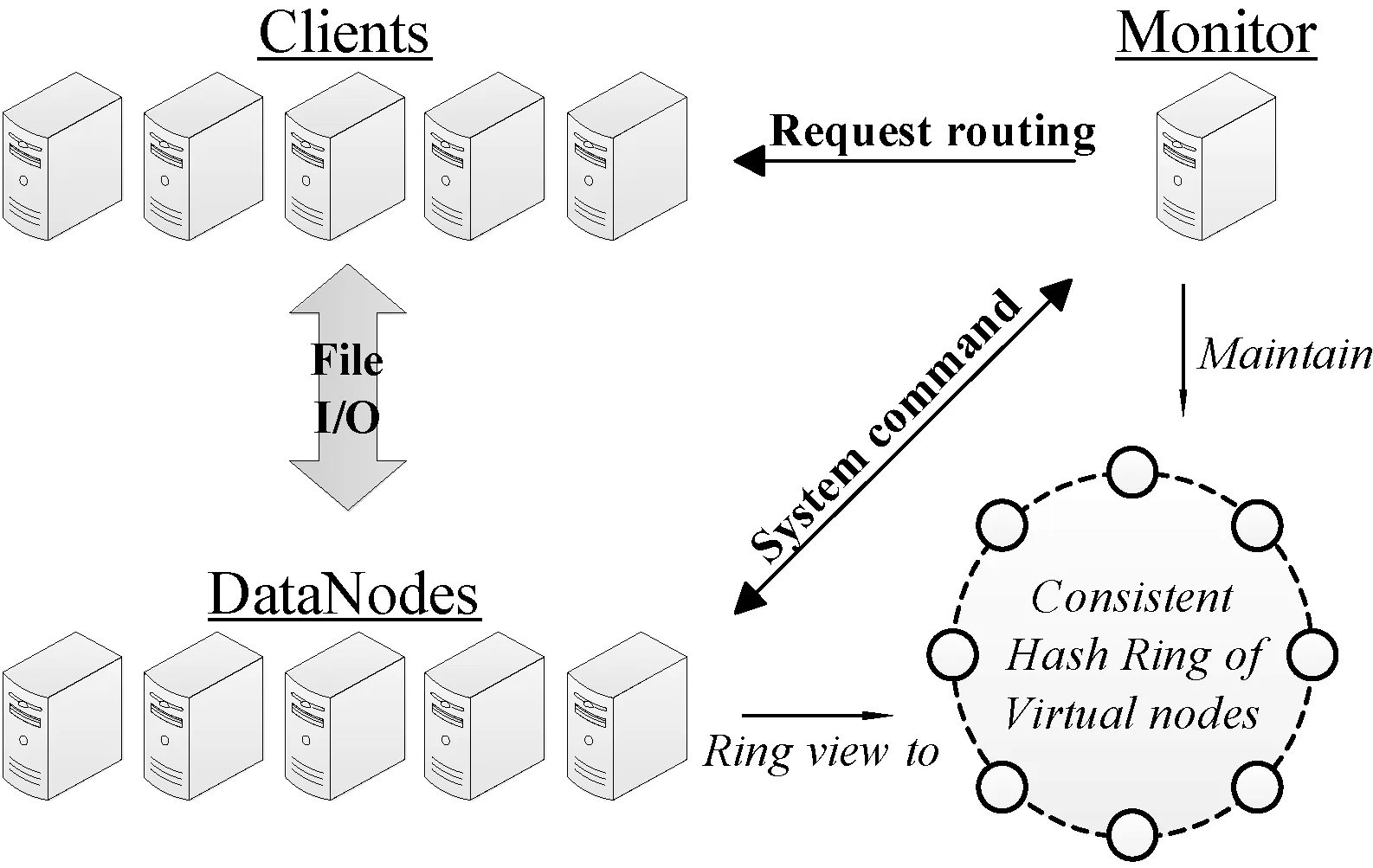
图1 系统结构
ZDFS中有虚拟节点概念,如图2所示。其中,该数据文件存储到Vnode c所对应的DataNode上。
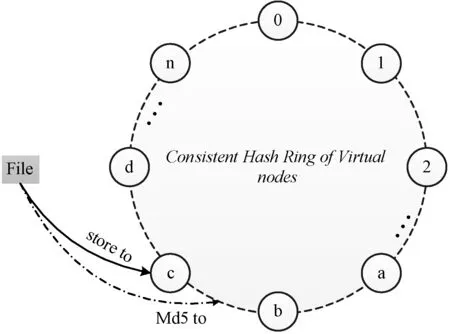
图2 一致性哈希环
与Ceph[17]数据寻址方式相似,ZDFS的Client仅仅使用不定期更新的少量本地元数据,即可确定存放File的DataNode地址,如表1所示。
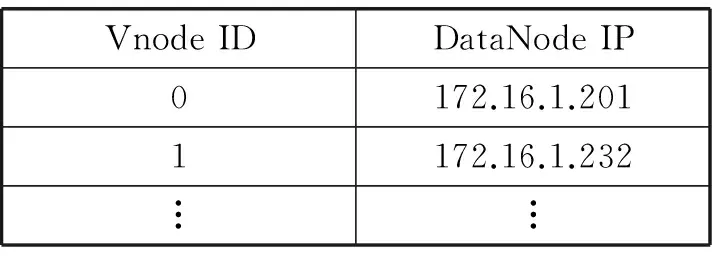
表1 虚拟节点路由表
ZDFS预设每个数据有3份拷贝。Monitor将三个连续的虚拟节点放置在三个不同的DataNode上,在此基础上,DataNode将依据后继节点规则进行数据备份,如图3所示。
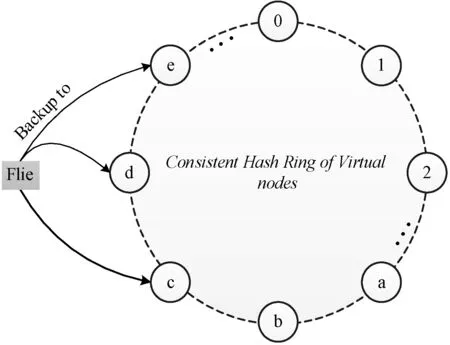
图3 三副本备份机制
2 虚拟节点分层重映射
ZDFS是作为大规模的分布式系统设计,ZDFS分布式系统具有良好的可拓展性,在ZDFS上进行混合节点集群层次化存储研究主要有以下原因:
(1) 冷区数据量很大
系统的高可靠性要求使得其采用了3副本备份机制,而备份数据却不常使用。系统容量与存储机器规模成正相关,这意味着需要部署更多的存储节点来满足系统的存储需求,极大地增加了系统能耗。
(2) 层次化存储是数据中心提升效率的必然要求
在存储节点集群中混合不同的结构、性能的节点,若不加以区别利用,可能增加系统延迟,带来不稳定性因素,以及高性能类别节点的硬件优势将不能得到充分发挥。
本文用HighNode和LowNode分别表示两种不同类型的物理存储节点。策略是在HighNode上优选使用高能耗高性能处理器和高速存储介质,LowNode上优选使用低功耗处理器和普通存储介质。表2是ZDFS下混合集群执行层次化混合和无层次化混合情况下两种物理存储节点的功能。
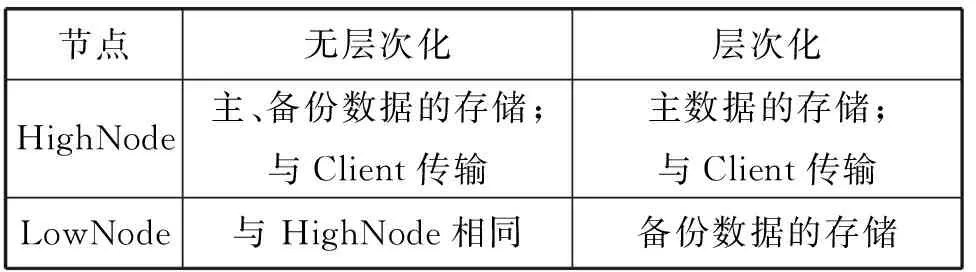
表2 不同类型节点的功能
无层次化策略下的后继节点规则可以表式为:
{vnode(i)_next=vnode(i+1)(i为小于N的自然数,N为虚拟节点总数);vnode(i)_next=vnode(0)(i等于N-1时)}
层次化混合下的LowNode和HighNode功能不同,ZDFS系统必须区分使用这两种不同类别的存储节点。但ZDFS使用了一致性哈希算法替换了传统的主从结构中的文件分布表,系统无法通过查表区分不同类别的节点。为应对这个问题,本文提出了一种对等结构下区别使用不同类型节点的层次化存储策略——虚拟节点分层重映射VHR,系统无需查表即可自动区分使用不同类型的存储节点,且不影响系统的高拓展性。
由于本文的混合集群中只混合了两种类型节点,将虚拟节点分类为奇数类虚拟节点和偶数类虚拟节点。设定将所有奇数虚拟节点映射到LowNode集群,所有偶数虚拟节点映射到HighNode集群,如图4所示。
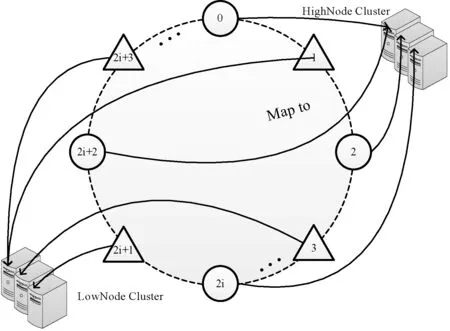
图4 奇偶虚拟节点分别映射不同类型节点集群
相应的后继节点规则设定为:
{vnode(2j)_next=vnode(2j+1);vnode(2j+1)_next=vnode(2j+3)(j为小于N的自然数,2N为虚拟节点总数)}
从上可知,主数据存放在HighNode集群中;备份数据存放在LowNode集群中.当设定Monitor只向Client发送偶数虚拟节点的路由表信息,LowNode集群将对Client不可见。
接下来探讨虚拟节点分层重映射的细节,用数学抽象描述了其中的两个重要部分。
2.1 节点加入流程
系统获取新加入存储节点,记为p,然后执行节点加入流程,其使用:
算法1 节点加入算法
a) 平均化收集预分配的虚拟节点,放入收集容器集合φ;
b) 选取元素i,其中i∈φ,更新i对应的物理存储节点映射归属,即R(i)=p;
c) 迁移对应物理存储节点下至p,即D(i)=p;
d) 更新存储节点与i有关的逻辑前驱和后继关系;
e)φ=φ-{i},如果φ不为空,执行步骤b),否则完成。
实现上,步骤a)主要是对对应类型的虚拟节点总数进行回收,得到回收节点集合φ,ZDFS提出了不同的存储节点标记为不同的存储域,数据的各个备份要保证放在不同的区,保证某区的存储节点宕机时,能从其他备份区中恢复。因而,具体策略实现上,回收再分配时需保证逻辑相邻两个虚拟节点不能映射至相同的物理存储节点;
步骤b)中,R(i)=p关系函数为虚拟节点x的映射主机。Monitor更新φ的映射关系至p,并协调p建立相应的存储目录区。
步骤c)中,D(i)=p关系函数为虚拟节点i对应存储的数据所存储的主机为p,Monitor协调φ集合对应的物理存储主机,将数据迁移至p,并更新(删除)数据的对象。
步骤d)中,告知并更新其他存储节点的前驱和后继的映射关系,保证数据的备份机制的实施。
2.2 节点离线流程
若p出现宕机情况,系统删除该物理节点,然后执行节点离线流程,其处理使用:
算法2 节点离线算法
a) 获取p节点所分配的虚拟节点集合φ;
b) 选取元素x,其中x∈φ,将x节点分配至新的物理节点q;
c) 分别迁移x的逻辑第一前驱px1和第二前驱px2对应的物理节点数据至q的x目录下的第一二拷贝区;
d) 更新的逻辑前驱及后继关系;
e)φ=φ-{x},如果φ不为空,执行步骤b),否则完成。
实现上,步骤b)把虚拟节点p重映射到相同类型的存储节点,和节点加入流程一致,需确保逻辑相邻两个虚拟节点不能映射至相同的物理存储主机;步骤c)将确保在新的物理存储节点q成为p节点的替代节点之前,已经完成迁移存储节点的之前存储数据。
本文设计实现的虚拟节点分层重映射(VHR)将不同虚拟节点集合分层映射到不同类型的存储节点上,实现了在对等结构下不同类型存储节点的层次化,具有以下运行特点:
(1) 自动的混合节点集群管理
存储节点加入或离线时,系统根据其节点类型,自动分配或回收对应的虚拟节点。同时,虚拟节点的分配与回收机制在保证数据拷贝存储到互异存储节点的情况下,通过均衡算法保证存储数据在集群中的均衡化存储,具有较高的可用性。
(2) 不破坏系统的高拓展特性
在混合集群的数据迁移过程中,Monitor节点的负载很轻,只负责向某一时间加入或宕机的存储节点发送相应指令,具体数据迁移操作在存储节点之间自动独立完成。
3 实验与分析
实验在真实网络环境下进行,拓扑结构如图5所示。所有节点均在同一个局域网中。图5中包含有6台HighNode、6台LowNode、1台Monitor、1台Client。交换机采用1台TP-Link的10/100/1000M自适应交换机,能耗功率测量使用了多台TECMANTM9微型电力检测仪。
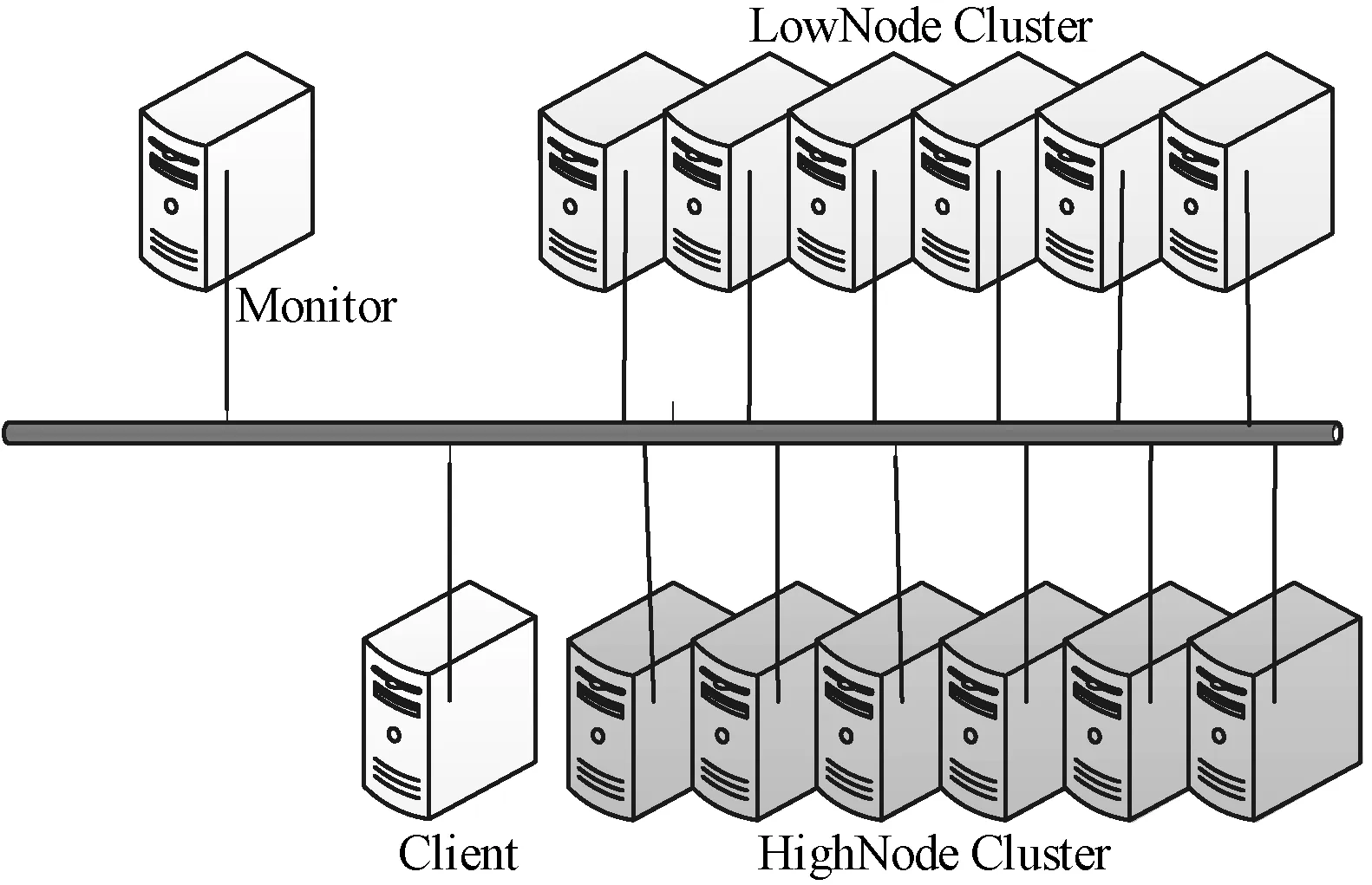
图5 系统拓扑
各个节点软件主要采用C语言编写,软件运行环境为Ubuntu14.04。实验中,HighNode运行在X86 架构的PC工作站上,LowNode运行在ARM评估板上。如表3所示。
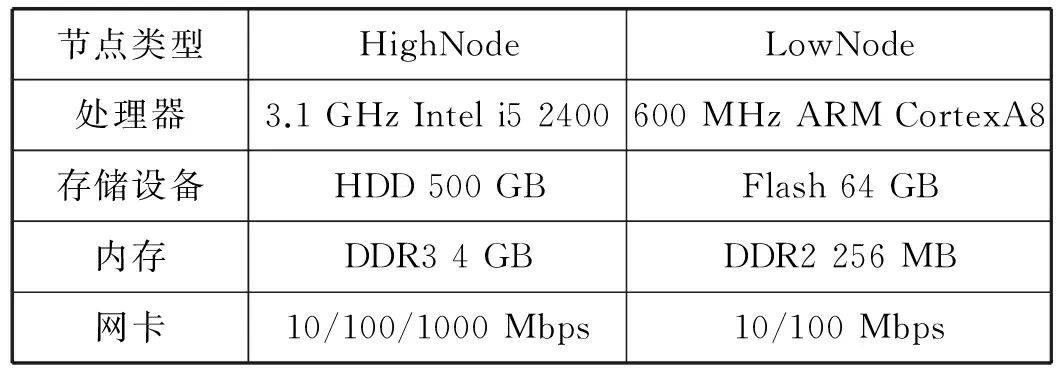
表3 硬件配置
3.1 能耗水平
实验通过对4个不同的实验组的对比测试进行,每一个实验组的配置均不相同,每一个实验组的运行时的整体能耗水平如表4所示。
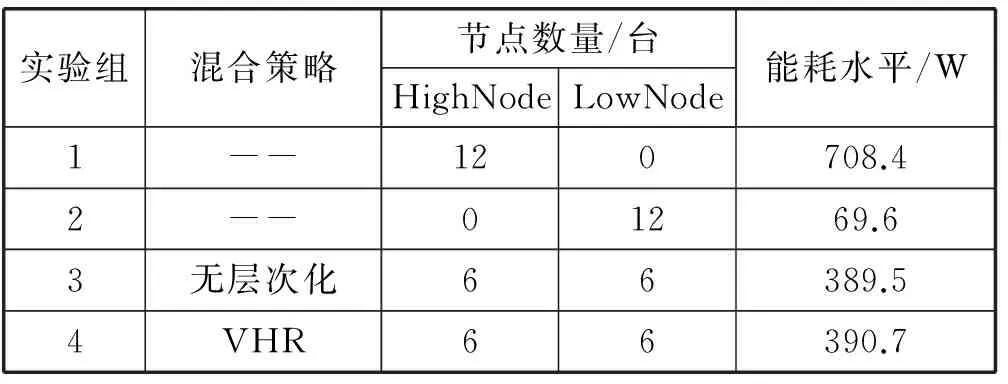
表4 不同实验组的能耗水平
实验组1中全为HighNode,故其整体能耗水平最高;实验组2的存储集群中全部部署为LowNode,故其整体能耗水平最低;实验组3和实验组4在存储集群中混合部署了相同数量的HighNode和相同数量的LowNode,整体能耗水平相近。接下来的两个小节分别进行了不同实验组的吞吐性能和文件下载用时测试。
3.2 吞吐性能
最大吞吐性能测试的文件规模为100GB,测试方式是采集Client节点的以太网端口的最大I/O数据,测试结果如表5所示。
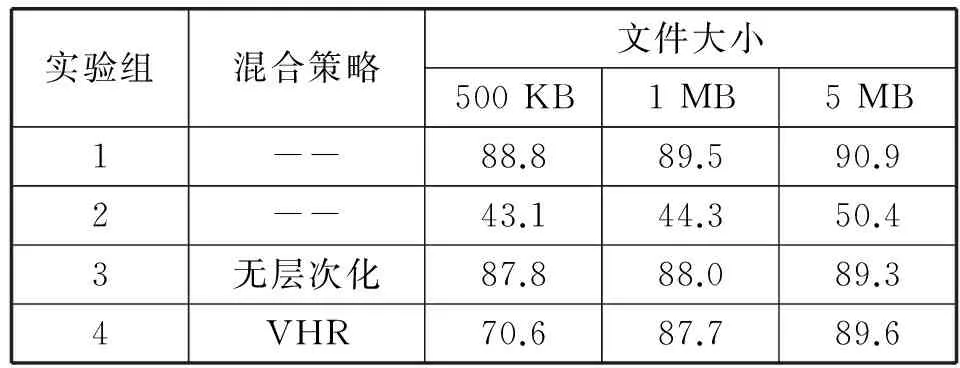
表5 不同实验组的最大吞吐性能 MB/s
实验组3比实验组4在最大吞吐性能上有轻微的优势,因为实验组4的混合集群中LowNode对Client是隐藏的,LowNode不参与对Client的数据传输。随着文件大小的增加,实验组1、实验组3和实验组4的最大吞吐表现趋于一致,系统限制开始成为制约系统最大吞吐的主要因素。
3.3 下载时间
下载时间测试在每一个实验组上分别进行,Client从存储集群中选择10 GB大小的数据文件进行下载,记录所有数据全部完成下载的用时,测试结果如表6所示。

表6 不同实验组的10 GB规模的文件下载时间 s
实验组1有最短的测试结果,因其部署的节点全为HighNode;实验组2的下载用时最长,因其部署的节点全为LowNode;实验组4执行了本文的VHR混合策略,系统区分使用了不同的存储节点,在数据文件下载时,Client只与混合集群中的HighNode进行数据传输,故测试结果和实验组1相近;而实验组3执行了普通的无层次化混合,系统不能区分使用不同的存储节点,Client与LowNode进行数据传输时引起了更多时间开销。除此之外,对等结构下在无层次化混合下的文件查找、目录列表等功能如ls命令,低性能的节点将进一步增加系统延迟,给系统带来不稳定因素。
结合上文的能耗、吞吐测试结果,VHR实验组运行良好,充分发挥了不同类型的存储节点的优势,在性能降低不明显的情况下,整体能耗水平降低了44.8%。
4 结 语
针对如何在对等结构的混合集群中区别使用不同类型存储节点的问题,本文在一个对等结构分布式系统ZDFS上进行了混合集群的层次化存储的研究,设计并实现了一种基于对等结构的层次化存储策略——虚拟节点分层重映射(VHR)。该策略不影响对等结构的高拓展特性,使系统可自动区分使用不同类型存储节点,可操作性强。实验在真实X86和ARM混合集群上进行,实验表明,VHR实验组运行良好,充分发挥了不同类型存储节点的优势,在性能降低不明显的情况下,整体能耗水平降低了44.8%。本文接下来的工作包括继续优化系统,支持更多类型节点等等。
[1] Dell EMC.The Digital Universe of Opportunities:Rich Data and the Increasing Value of the Internet of Things[OL].http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm.
[2] Ghemawat S,Gobioff H,Leung S T.The Google file system[J].ACM SIGOPS Operating Systems Review.New York:ACM,2003,37(5):29-43.
[3] DeCandia G,Hastorun D,Jampani M,et al.Dynamo:Amazon’s Highly Available Key-Value Store[J].ACM SIGOPS Operating Systems Review,2007,41(6):205-220.
[4] Shvachko K,Kuang H,Radia S,et al.The Hadoop Distributed File System[C]//Mass Storage Systems and Technologies (MSST),2010 IEEE 26th Symposium on.New Jersey:IEEE,2010:1-10.
[5] EPA.Report to Congress on Server and Data Center Energy Efficiency[OL].https://datacenters.lbl.gov/sites/ all/files/EPA_Datacenter_Report_Congress_Final1.pdf.
[6] Battles B,Belleville C,Grabau S,et al.Reducing data center power consumption through efficient storage[R].WP-7010-0709,NetApp White Paper,2007.
[7] Wang Y,Sun W,Zhou S,et al.Key Technologies of Distributed Storage for Cloud Computing[J].Journal of Software,2012,23(4):962-986.
[8] Gurumurthi S,Sivasubramaniam A,Kandemir M,et al.Reducing Disk Power Consumption in Servers with DRPM[J].Computer,2003,36(12):59-66.
[9] Harnik D,Naor D,Segall I.Low power mode in cloud storage systems[C]//2009 IEEE International Symposium on Parallel and Distributed Processing.IEEE,2009:1-8.
[10] Leverich J,Kozyrakis C.On The Energy (In)Efficiency of Hadoop Clusters[J].ACM SIGOPS Operating Systems Review,2010,44(1):61-65.
[11] Pinheiro E,Bianchini R,Dubnicki C.Exploiting Redundancy to Conserve Energy in Storage Systems[C]//Proceedings of the Joint International Conference on Measurement and Modeling of Computer Systems,2006:15-26.
[12] Szalay A S,Bell G C,Huang H H,et al.Low-power amdahl-balanced blades for data intensive computing[J].ACM SIGOPS Operating Systems Review,2010,44(1):71-75.
[13] Hamilton J.Cooperative expendable micro-slice servers (CEMS):low cost,low power servers for internet-scale services[C]//Conference on Innovative Data Systems Research,2009:1-8.
[14] Vasudevan V,Franklin J,Andersen D,et al.FAWNdamentally Power-efficient Clusters[C]//Proceedings of the 12th Conference on Hot Topics in Operating Systems.Berkeley,CA,USA:USENIX,2009:22.
[15] Open Compute Project.ARM Server Motherboard Design for Open Vault Chassis Hardware v0.3[OL].http://www.opencompute.org/wp/wp-content/uploads/2013/01/Open_Compute_Project_ARM_Server_Specification_v0.3.pdf.
[16] Anna Wang.Chinese Internet Giant Baidu Rolls Out World’s First Commercial Deployment of Marvell’s ARM Processor-based Server[OL].http://developer.baidu.com/en/events.html.
[17] Weil S A,Brandt S A,Miller E L,et al.Ceph:A scalable,high-performance distributed file system[C]//Proceedings of the 7th Symposium on Operating Systems Design and Implementation.USENIX Association,2006:307-320.
[18] Zhang Q,Zhang W,Li W,et al.Cloud Storage System For Small File Based on P2P[J].Journal of Zhejiang University (Engineering Science),2013,47(1):8-14,93.
RESEARCH ON HIERARCHICAL STORAGE STRATEGY ON P2P HYBRID CLUSTER
Tu Chaofan1Zhang Qifei1Chen Yingzhuang1Zhang Yuchang1Liu Erteng1Gan Honghua1Zhang Weidong2Bai Fan3Zheng Xianrong4
1(SchoolofSoftwareTechnology,ZhejiangUniversity,Ningbo315048,Zhejiang,China)2(SchoolofElectronicsEngineeringandComputerScience,PekingUniversity,Beijing100871,China)3(DepartmentofElectricalEngineeringandComputerScience,NorthwesternUniversity,Evanston60201,USA)4(CentralInstitute,InsigmaTechnologyCompanyLtd,Hangzhou310030,Zhejiang,China)
With the scale of distributed storage systems growing rapidly, the problem of energy consumption has become increasingly prominent, and storage cluster hybrid low-power node has become one of the important ways to solve this problem. To face the problem of how to use different types of storage nodes discriminatively, in this paper, a hierarchical storage strategy called vnode hierarchical remapping (VHR) is designed and implemented based on a P2P distributed system of ZDFS. The strategy didn’t affect the high scalability of P2P, so that the system can automatically distinguish between the use of different types of storage nodes with strong operability. Experiments are carried out on a real X86 and ARM hybrid cluster, and experiments show that the VHR works well and plays to the advantages of different types of storage nodes. Under the condition of the performance degradation is not obvious, the overall level of energy consumption was reduced by 44.8%.
Storage system P2P Hybrid cluster Hierarchical
2015-11-20。国家关键科技支撑项目(2014BAH23F03);国家环境公益项目(2013A610064);宁波自然科学基金项目(2013B10036);宁波智能交互多媒体远程教育系统项目(2013B10036)。涂超凡,硕士生,主研领域:分布式系统,物联网。张启飞,讲师。陈应庄,硕士生。张昱昶,硕士生。刘二腾,讲师。干红华,副教授。张尉东,博士生。白凡,硕士生。郑贤榕,高工。
TP3
A
10.3969/j.issn.1000-386x.2017.04.002
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:57:30
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
铁道通信信号(2016年1期)2016-06-01 12:10:17
中国教育信息化(2015年12期)2015-08-24 07:58:36
电测与仪表(2015年10期)2015-04-09 11:48:20
