
基于Hadoop的交通数据分析系统
2017-04-21 00:44杨臣君杨卓东
电子科技 2017年4期
杨臣君,张 欣,杨卓东
(贵州大学 大数据与信息工程学院,贵州 贵阳 550000)
基于Hadoop的交通数据分析系统
杨臣君,张 欣,杨卓东
(贵州大学 大数据与信息工程学院,贵州 贵阳 550000)
为了保证交通数据处理的实时性和存储的扩展性,文中设计并实现了一种交通大数据分析系统,其中Hadoop平台利用MapReduce并行分布式计算对车辆数据进行统计分析;另一个Storm平台利用其流计算组件对实时路况进行分析,两个模块协同作用,能对缓解城市交通拥堵起到一定的作用。通过测试表明,系统可靠性较高、计算速率快,能达到支持决策的作用。
交通数据; Hadoop; MapReduce; Strom;支持决策
随着我国智能交通的快速发展,许多技术手段已达到国际领先水平。但是,问题和困境也逐渐凸显,从各城市的发展状况来看,交通数据资源的深层次价值还未得到有效挖掘:除了交通数据的感知和采集有限,还对存在于不同机构管理系统中的海量数据没能共享运用、高效分析,对交通情况缺少判断预测,对影响交通通畅的因素分析不明确,总体上来看,目前智能交通的发展无法满足民众的交通信息服务的需求[1]。大数据分析逐渐成为缓解城市拥堵的关键技术,面对这些跨平台、跨系统的交通数据,先进的大数据工具能将海量、零散、异构的数据整合在同一个中心,形成一个关联密切的数据链,在此前提下能深度挖掘交通数据多维度关系,对交通势态进行预判,可以提高城市交通管理水平[2-4]。
1 Hadoop分布式并行计算框架
1.1 Hadoop
Hadoop分布式计算框架包含能存储超大型数据集的HDFS(分布式文件系统),在进行数据处理时,Hadoop首先将数据切分成多个block多副本存储在HDFS上,然后将数据进行切分再分发到集群子节点上进行分布式并行计算。Hadoop计算框架具有扩展性好、可靠性强、效率高、容错性强、成本低的特点,并提供界面友好的管理页面,并得到了广泛应用。
1.2 Hadoop体系架构

图1 Hadoop生态系统图
Hadoop生态系统的基本体系如图1所示,最底层是HDFS分布式文件系统,它能存储大量非结构化数据,给上层提供计算资源。MapRedece分布式并行计算框架,并能将计算任务分部到多个节点上最后写入磁盘保存,Hive和Pig能使用简单的Shell语句进行MapReduce任务,Mahout中有很多现成的数据挖掘算法库供开发者使用,给大数据挖掘提供便利条件。Hbase分布式数据库具有伸缩性强、效率高、可靠性好等特点,其支持MapReduce批量写入数据,实现并行计算和数据存储的无缝结合。Zookeeper是集群数据管理工具,广泛应用于各种集群。Flume的主要功能是收集日志,还具有一些数据预处理的功能。Sqoop可利用并行的方式将Hadoop上存储的数据与传统数据库进行相互传输。Ambari是安装管理工具。
1.3 Hbase
传统数据已经无法满足大数据的读写要求,Hbase作为Hadoop生态系统中的另一个核心模块,打破了行存储的方式,采取一种分布式列存储的方式,查询规则也是通过定义列簇,列和值,使得数据库自动索引化,面向列存储数据支持动态增加,数据为空则不存储,节省了硬盘空间,每个字段的数据按照列簇存储,大幅提高查询效率。Hbase自动切分数据,支持高并发读写。这一系列优势让Hbase较好地满足了交通流数据的场景,能动态增加或减少交通数据种类,还能实时显示数据特征,达到数据实时查询的效果。
2 基于Hadoop的交通数据分析系统
2.1 交通数据分析系统框图
交通大数据分析系统框图如图2所示,整个构架由4个大模块组成:资源模块(RS)数据库模块(DB)、服务器模块(Server)和客户端模块(Client)。最底层是资源采集,其中包括历史数据和实时数据,采集数据的设备也根据不同需求分类。数据持久化层是Hadoop的HDFS,在此之上进行MapReduce分布式计算,同时可以利用数据挖掘工具Mahout进行数据挖掘分析。将一些地点编码对应地点,设备编码对应地点等映射关系存入MySQL便于Webapp传递给前端页面显示,将需要实时查询的数据存入设计好列簇和Rowkey的Hbase,Hbase自动索引的机制使查询速度相较于传统数据库大幅提高,HIVE进行数据分析,它能将类SQL语句转化成MapReduce作业,例如查询出过车辆最高的几个路口,违法频次高发地段等,使用此技术都能方便的实现。在服务端利用Springmvc接收数据与前台交互。前端使用Ecahrts和Bootstrap进行图表的绘制,使用Leaflet进行地图图层的渲染。

图2 交通数据分析系统架构图
在交通大数据的场景下,此架构根据不同的需求提供了数据离线和在线分析两种计算服务,其中MapReduce离线处理框架用于交通模型的建立和大规模车辆行为轨迹挖掘,Storm流计算平台克服了Hadoop平台无法有效在线处理数据的不足,它提供的输入流组件Spout将数据传输给Blot进行计算任务,同时创建新的流作为下一个Blot的输入流,实现数据实时处理。并且对交通流数据进行可变长预测,数据最终以报表的形式显示在前端页面,提供决策支持[5]。
2.2 交通大数据处理流程
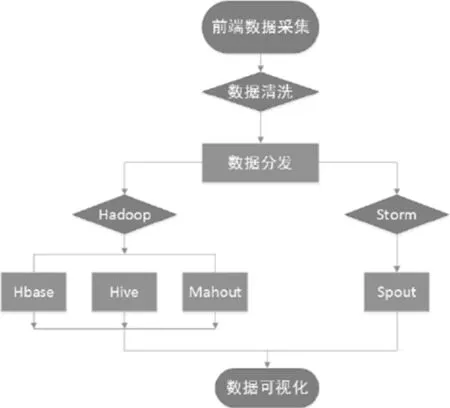
图3 交通大数据处理流程图
交通大数据处理流程如图3所示。 交通大数据处理的整个流程可以分为数据采集、数据预处理、数据分发、数据存储、数据处理(挖掘)和结果呈现。
数据采集:包括传统数据库中历史数据、各种设备采集的数据以及网络数据。
数据预处理:将交通大数据结果数据清洗,规范统一管理,同时保证数据的完整性和可靠性。
数据分发:根据不同需求将数据存入HDFS或者Strom,以便进行离线分析或在线计算。
数据存储:存储在HDFS中的数据通过使用MapReduce计算框架的IO开销较大,但保证了数据处理的稳定性。存储在Storm流式集群中的数据在进行数据处理时采用全内存计算,这意味着实时计算对内存的开销较大。
数据处理:其中Hadoop模块主要利用MapReduce对数据进行统计或者挖掘以满足用户需求[6-7],Storm利用Spout将数据传递给Blot进行数据处理的同时Blot形成新的结果成为另一个Blot的输入。
结果呈现:主要是将结果分析过的数据显示在前端页面,这部分根据不同场景的需要设计图表和功能。
3 系统性能测试
如图4所示,此系统前端页面在地图上标记发光圆圈表示路口,在右侧图表模块显示分析结果,第一行是每天对应各个时段的过车数,第二行是每天对应各地区车辆数,在中间列出查询框。
在智能交通监控系统的搜索框中输入地点,在日历控件中输入时间则可得到如图5所示的每天对应各时段的车数、每天各个地区的过车数、右下角是省内省外车辆比例的饼状图。每天数据有300~1 000万,从数据处理到结果呈现仅用时1 s。

图4 查询界面

图5 查询结果图
4 结束语
通过实现该系统,分布式并行计算和流式计算能很好地满足交通大数据的应用需求,既能进行离线数据分析,又能将交通状况实时反映出来[8-11],下一步的工作是将异构的交通数据进行数据挖掘,找出数据之间深层次的价值,为缓解交通拥堵和交通案件的侦破提供有力的决策支持[12-14]。
[1] 王珊,王会举,覃雄派,等.架构大数据:挑战现状与展望[J].计算机学报,2011,34(10): 1741-1751.
[2] 维克托·迈尔·舍恩伯格, 周涛. 大数据时代——生活、工作与思维的大变革[J]. 汽车纵横, 2013(3):136-138.
[3] Dean J,Ghemawat S.MapReduce: simplified data processing on largeclusters[J].Communications of the ACM, 2008,51(1):107-113.
[4] 孙彦超,王兴芬.基于Hadoop框架的MapReduce计算模式的优化设计[J].计算机科学,2014(11A) :333- 336.
[5] 陈康,郑纬.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
[6] 孙广中,肖锋,熊曦.MapReduce 模型的调度及容错机制研究[J].微电子学与计算机,2007,24(9):178-180.
[7] 郑启龙,房明,汪胜,等.基于MapReduce模型的并行科学计算[J].微电子学与计算机,2009,26(8):13-17.
[8] Yang H C,Dasdan A,Hsiao R L,et al.MapReduce merge:simplified relational data processing on largeclusters[C].Soul:Proceeding of the 2007 ACM SIGMOD International Conference Management of Data,2007.
[9] 姬倩倩,温浩宇.公共交通大数据平台架构研究[J].电子科技,2015,28(2):127-130.
[10] 覃雄派,王会举,杜小勇,等.大数据分析-RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[11] 徐子沛.大数据:正在到来的数据革命[M].桂林:广西师范大学出版社,2012.
[12] 郑启龙,王昊,吴晓伟,等.HPMR:多核集群上的高性能计算支撑平台[J] .微电子学与计算机,2008(8):21-23.
[13] 段宗涛,郑西彬,李莹,等.道路交通大数据及其关键技术研究[J].微电子学与计算机,2015(6):85-89.
[14] 陆化普,孙智源,屈闻聪.大数据及其在城市智能交通系统中的应用综述[J].交通运输系统工程与信息,2015(5):45-52.
Traffic Data Analysis System Based on Hadoop
YANG Chenjun,ZHANG Xin,YANG Zhuodong
(School of Data and Information Engineering, Guizhou University,Guiyang 550000,China)
With the great increase of traffic data in information construction project, the traditional way has been unable to guarantee the scalability of the data processing for real-time and data storage, according to this a series of problems, the design called a traffic data analysis system arises at the historic moment, the platform of Hadoop using the MapReduce of the parallel distributed computing for statistical analysis of the data of the vehicle, another platform called storm using the flow computational components for real-time traffic analysis, effective cooperation of two modules, play a good role to ease urban traffic congestion. The test shows that the system has high reliability and fast calculation speed, and it can achieve the function of supporting decision.
traffic data;Hadoop;MapReduce;Storm;supporting decision
2016- 05- 17
贵州省科技计划基金资助项目(黔科合GY字[2010]3056)
杨臣君(1991-),男,硕士研究生。研究方向:分布式并行计算。张欣(1976-),男,博士,副教授,硕士生导师。研究方向:下一代无线通信及应用等。杨卓东(1994-),男,硕士研究生。研究方向:图像处理。
10.16180/j.cnki.issn1007-7820.2017.04.039
TN911.73
A
1007-7820(2017)04-156-03
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
大众投资指南(2021年35期)2021-02-16
铁道通信信号(2019年5期)2019-10-10
时代金融(2018年15期)2018-08-28
电子技术与软件工程(2017年19期)2017-11-09
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
中国惯性技术学报(2015年1期)2015-12-19
西华师范大学学报(自然科学版)(2015年3期)2015-02-27
