
融合LDA与Word2vector的垃圾邮件过滤方法研究
2017-04-17 01:27林建洪翟建桐
网络安全技术与应用 2017年3期
◆林建洪 翟建桐 徐 菁
融合LDA与Word2vector的垃圾邮件过滤方法研究
◆林建洪1翟建桐2徐 菁1
(1.浙江鹏信信息科技股份有限公司 浙江鹏信 310000;2.中国移动通信集团浙江有限公司 中国移动 310000)
在传统垃圾邮件过滤技术的基础上,提出一种融合LDA主题模型和Word2vector模型的文档向量,并将LDA主题模型得到的不同维度的文档——主题矩阵、Word2vector模型得到的词向量以及融合的文档向量作为支持向量机和逻辑回归的特征输入,通过8组对照实验的效果分析得到:融合的文档向量结合支持向量机模型的准确率最高,能够对垃圾邮件进行精准过滤,降低了垃圾邮件对个人以及社会的危害。
LDA主题模型;Word2vector;垃圾邮件;支持向量机
0 引言
随着互联网的发展,电子邮件成为人们日常生活、工作必不可少的应用。电子邮件由于其便捷、经济等特点成为互联网最广泛的应用之一,但也因为其成本低廉、传播快速的特点反而被垃圾邮件的制作者所利用。垃圾邮件广义上来讲就是未经收件人允许而发送的带有商业广告等不良信息的邮件。垃圾邮件不仅会使受害人遭受财产损失,更会造成计算机网络资源的浪费,危害互联网的发展。有鉴于此,需要一种精准、高效的方法对垃圾邮件进行判断并过滤,为电子邮件用户提供一个安全、纯净的环境。
1 文献综述
垃圾邮件是指收件人事先没有提出请求或无法拒绝或隐藏发件人个人信息的含有虚假信息、不良信息、营销广告等对收件人有害的邮件[1]。
国内外对于垃圾邮件过滤技术的研究较早,主要的过滤方法有:基于黑白名单的过滤、基于邮件头的过滤以及基于内容的过滤。其中,基于内容的过滤主要是指对邮件文本内容进行分析与判断,相较于其他两种过滤方法有较高的准确率。随着研究的深入,基于内容的过滤技术被划分为两类:基于规则的过滤器以及基于机器学习的算法过滤。基于规则的过滤器主要采用决策树输出的规则或粗糙集等对邮件头、邮件内容进行分析,判断邮件是否为垃圾邮件,该方法简单、高效,但是垃圾邮件的规则变化多且快,该方法不能实时适应垃圾邮件的变化,不够灵活。基于机器学习的算法过滤方法本质上是文本二分类的方法,对文本量化后采用机器学习分类方法对文本进行分类,该方法相较于基于规则的过滤方法有更高的准确率,能够通过学习不断变化的垃圾邮件的特征对判断模型进行优化更新。表1为国内外学者对于基于内容的垃圾邮件过滤技术的研究,分别从研究视角、过滤技术两个方面进行的总结。
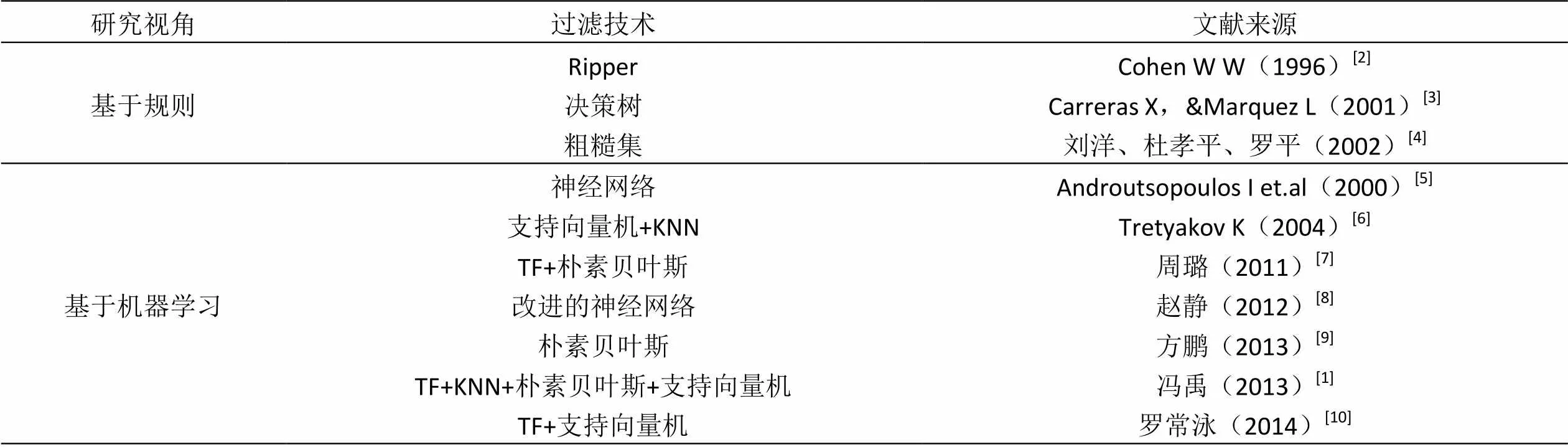
表1 基于内容的垃圾邮件过滤研究汇总
从已有的研究来看,目前还有以下几点可进一步深入研究:
(1)当前的研究主要集中于文本分类算法,对文档向量主要采用TF或者TF-IDF进行量化。由于文本分类涉及到的特征维度过高,因此需要对文档向量进行降维或者精简处理,提取有效的特征。
(2)在日常的生活工作中,邮件已是必不可少的一种工具,由于在工作中,用户每天都需要查收邮件,因此对垃圾邮件过滤技术的准确性以及时效性有更高的要求。
(3)深度学习是模拟人脑分析学习行为的神经网络,深度学习是目前热门的算法领域,因此可以将深度学习的算法应用到垃圾邮件过滤中。
本文在已有的研究基础上,通过融合LDA主题模型以及目前热门的深度学习算法Word2vector得到能精简、完整、全面反映邮件文本内容的文档向量,再通过对比逻辑回归以及支持向量机的分类效果,选择最优模型,提高垃圾邮件过滤算法的准确率。
2 相关技术与理论基础
2.1 文档表达
(1)向量空间模型
向量空间模型(Vector Space Model,VSM)是将所有需要研究的文档进行分词后提取关键词,并在同一个向量空间中表示出来。因此每篇文档就能表示为由一些分量组成的向量,分量具体的取值通常采用TF-IDF值表示。
TF-IDF是由词频(Term Frequency)和逆文档频率((Inverse Document Frequency)两部分组成,TF即某一个词在该文本中出现的频率,IDF为该词在整个语料库中出现的频率。TF-IDF的计算方法就是将两部分相乘,具体计算公式如下:
(2)词向量
本文所指的词向量主要是指Distributed Representation这种低维度的向量,通过语料库的训练将每一个词表示为形如[0.792,−0.177,−0.107,0.109,−0.542,...]的50至200维的向量。不同于传统的One-hot Representation词向量,这种低维词向量可以使词义相近的词在向量距离上更近并且避免了维数灾难。
2.2 文档分类算法
(1)逻辑回归
逻辑回归(Logistic Regression)是机器学习中的一种二分类模型,在线性回归的基础上运用了sigmoid函数,该函数的表现形式为:。考虑具有p个独立变量的向量,设条件概率为根据观测量相对于某事件发生的概率,通过极大似然估计训练函数的参数值,得到判别模型。
(2)支持向量机
支持向量机(Support Vector Machine,SVM)通过核函数将非线性可分的数据映射到更高维,使得非线性可分变为线性可分。SVM的目的是要找到一个线性分类的最优超平面使得不同类的相邻点之间的距离最大,距离越大则表示分类效果越好。
3 融合LDA与Word2vector的算法
3.1 LDA主题模型
LDA是由Blei D M等人于2003年提出的基于三层贝叶斯概率的无监督的主题发现模型,该模型的特点是结构清晰、计算高效,适合大规模的文本建模。该模型包含文档、主题、词三层结构,文档由主题组成,主题又由词组成,文档——主题服从Dirichlet分布,主题——词服从多项式分布。具体的生成步骤为:首先选择一个主题向量θ,确定每个主题被选择的概率,接着从主题分布向量θ中选择一个主题z,根据主题z的词概率分布生成一个词,重复上述过程直到遍历文档中的每一个词。
LDA的核心公式见公式(2),其中α、β代表评论与主题、主题与词的Dirichlet分布的超参数,θ为潜在主题在目标评论文档中所占的比重,z代表评论的潜在主题,w代表潜在主题z和主题——词分布条件下的词向量,N为评论字数的集合,M为评论的集合。
3.2 Word2vector模型
Word2vector于2013年由Google的研究员发布,是一种用于深度学习的词向量生成工具。Word2vector本质上是利用了神经网络语言模型并对其进行了简化,在保证效果没有特别大的变化的前提下提高了计算复杂度。该模型常用的算法有两种:CBOW(Continuous Bag-of-Words Model)和Skip-gram(Continuous Skip-gram Model)。文本所利用到的算法为Skip-gram,该算法的主要目的为在已知当前词Wt的前提下预测该词的前c个上下文词Context(Wt),Context(Wt)的公式如下:
3.3 融合LDA与Word2vector的算法
训练LDA主题模型可得到的文档——主题矩阵,通过该矩阵将每一篇文档D用m个潜在主题构成的向量表示,得到LDA文档向量,形式为:。而通过Word2vector模型训练可以得到n维词向量,假设一篇文档由k个关键词组成,则可以通过求词向量平均值的方式得到Word2vector文档向量,的计算公式为:
从LDA以及Word2vector两种算法的原理中不难发现:LDA主题模型所得到的文档向量中的取值为潜在主题的分布,反映的是文档的大致信息,特征粒度较粗;Word2vector模型所得到的文档向量为词向量的平均值,反映的是关键词的信息,特征粒度较细。通过两者的融合可以反映一篇文档“粗”和“细”两方面的特征,使得文档的信息更加全面。文本采用向量串联的方式进行融合,将m维的LDA文档向量与n维的Word2vector文档向量进行串联,最终得到m+n维融合的文档向量,具体表现形式为:
进一步,将文档向量中的分量作为n+m个特征,这些特征为第3节中提到的逻辑回归以及支持向量机的输入,通过对两个模型的训练效果的评估,得到最优分类模型。
4 实验
4.1 实验设计
本文的实验数据来源于开源数据网站——数据堂,共获取1300条邮件文本数据,其中800条数据被标注为正常邮件,500条数据被标注为垃圾邮件。通过编写scala程序对邮件文本进行分词、去停用词处理。
在构建LDA模型前首先将分词抽取出构建词袋,然后通过使用向量空间模型(Vector Space Model,VSM)将评论文档转化为文本向量,再对词袋中的特征词使用常用的TF-IDF函数进行转换量化,从而构造出由邮件文本形成的文档-词频矩阵。将该矩阵作为LDA模型的输入,得到文档——主题矩阵,该矩阵中,每一个文档都有对应的主题向量,在本文中统一称为LDA文档向量。
不同于LDA建模,Word2vector建模前不需要对文档的分词进行TF-IDF量化,可直接赋予每个关键词一个随机数,通过Skip-gram算法的计算得到每个分词的词向量,将文档对应的分词的词向量的均值作为文档向量的具体取值,在本文中统计称为Word2vector文档向量。
在得到两个文档向量后,通过串联的方式将文档向量融合,作为逻辑回归以及支持向量机的特征输入,分别对比两个分类模型的准确率以及特征融合后的效果,评估融合算法的合理性并得到最优分类模型。准确率的计算公式如下:
其中a代表被准确分为垃圾邮件的样本数,b代表被错误分为垃圾邮件的样本数。
4.2 实验结果分析与总结
在LDA以及Word2vector建模过程中,将主题数的维度分别设置为100和200,将词向量的维度设置为100。为了能够更好地对比实验效果,本文共设置了8组实验,分别为:100维LDA文本向量+支持向量机、100维LDA文本向量+逻辑回归、100维Word2vector文本向量+支持向量机、100维Word2vector文本向量+逻辑回归、200维融合的文本向量+支持向量机、200维融合的文本向量+逻辑回归、200维LDA文本向量+支持向量机、200维LDA文本向量+逻辑回归。
通过LDA建模得到的文档——主题矩阵如下表所示:

表2 前5个100维LDA主题分布
通过Word2vector建模得到的文档向量如下表所示:

表3 前5个100维Word2vector文档向量
将两个模型得到的文档向量进行融合,得到200维的融合文档向量,如下表所示:

表4 前5个经过融合的文档向量
8组实验的准确率如下表所示,可以得到以下结论:
(1)从两个文本分类模型的效果来看,支持向量机模型都优于逻辑回归,这与逻辑回归的特点一致,当特征空间很大时,逻辑回归的性能会变差,而支持向量机的优点就在于能够处理大型特征空间。因此本文选择支持向量机为最佳文本分类模型。
(2)从LDA与Word2vector两个模型的支持向量机分类效果来看,100维的Word2vector文本向量构建的模型准确率为91.66%其效果优于100维的LDA文本向量构建的模型的准确率(88.88%)。由此可以得出特征维度更细的Word2vector模型具有更准确的分类效果。
(3)由于融合后的文本向量变为200维,因此本文设置了200维的LDA文本向量与之对比。从实验效果来看,融合后的模型在准确率上有显著的提升,达到了97.22%,效果远优于200维LDA文本向量以及Word2vector文本向量构建的模型,由此可以得出结论:LDA+Word2vector+支持向量机为最优模型,在垃圾邮件过滤上有很好的效果。

表5 8组对照实验准确率
5 结束语
本文在已有的垃圾邮件过滤技术研究的基础上,对LDA主题模型得到的文档——主题向量和Word2vector得到的词向量进行串联,得到融合后的文档向量,将文档向量分别作为支持向量机和逻辑回归分类模型的输入,对比两者的效果。经过8组对照实验准确率的对比,最终选择LDA(100)+ Word2vector(100)+支持向量机为垃圾邮件过滤的最优模型。该模型不仅对传统研究遇到的高维特征向量进行了精简,还融合了机器学习和深度学习算法,提高了算法的准确率,为后续垃圾邮件过滤方法的研究提供了新的思路。
由于邮件的定性具有一定的主观性,某些邮件对于一些用户是垃圾邮件,但对于另一些用户不是垃圾邮件,因此在判断是否为垃圾邮件时还需要结合用户的历史邮件数据、邮件的主题等信息,而本文在这方面还有不足之处,尚需更进一步的研究。
[1]冯禹.基于内容的垃圾邮件检测特征降维算法研究[D].浙江大学,2013.
[2]Cohen W W. Learning rules that classify e-mail[C]// AAAI spring symposium on machine learning in information access,1996.
[3]Carreras X,Marquez L. Boosting trees for anti-spam email filtering[J]. arXiv preprint cs/0109015,2001.
[4]刘洋,杜孝平,罗平等.垃圾邮件的智能分析,过滤及Rough集讨论[C]//武汉:第十二届中国计算机学会网络与数据通信学术会议,2002.
[5]Androutsopoulos I,Koutsias J,Chandrinos K V,et al. An experimental comparison of naive Bayesian and keyword-based anti-spam filtering with personal e-mail messages[C]//Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval. ACM,2000.
[6]Tretyakov K. Machine learning techniques in spam filtering[C]//Data Mining Problem-oriented Seminar,MTAT, 2004.
[7]周璐.基于内容的垃圾邮件过滤系统的研究[D].吉林大学,2011.
[8]赵静.基于内容特征分析的垃圾邮件过滤关键技术研究[D].山东师范大学,2012.
[9]方鹏.基于内容分析的垃圾邮件过滤技术的设计与实现[D].电子科技大学,2013.
[10]罗常泳.基于内容的垃圾邮件检测方法研究[D].浙江大学,2014.
[11]阮光册.基于LDA的网络评论主题发现研究[J].情报杂志,2014.
[12]Blei D M,Ng A Y,Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research,2003.
[13]张建华.基于LDA和词性句法规则的用户评论情感分析研究[D].广西大学,2014.
[14]董文.基于LDA和Word2Vec的推荐算法研究[D].北京邮电大学,2015.
[15]姜南.基于SVM的垃圾邮件在线过滤新方法[D].吉林大学,2013.
[16]唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J].计算机科学,2016.
猜你喜欢
客联(2022年3期)2022-05-31
承德医学院学报(2022年2期)2022-05-23
英语文摘(2021年10期)2021-11-22
中国新闻周刊(2021年26期)2021-07-27
潍坊学院学报(2020年2期)2021-01-18
疯狂英语·新阅版(2020年11期)2020-12-21
计算机与网络(2020年4期)2020-04-20
网络安全和信息化(2018年4期)2018-11-09
车迷(2018年12期)2018-07-26
信息安全研究(2016年4期)2016-12-01
