
Environmental Sound Event Detection in Wireless Acoustic Sensor Networks for Home Telemonitoring
2017-04-09 05:52:16HyoungGookKimJinYoungKim
China Communications 2017年9期
Hyoung-Gook Kim, Jin Young Kim
1 The Dept. of Electronics Convergence Engineering, Kwangwoon University, Seoul 01897, Rep. of Korea
2 The Dept. of Electronics and Computer Engineering, Chonnam National University, Gwangju 61186, Rep. of Korea
I. INTRODUCTION
Wireless sensor networks (WSNs) are largescale wireless networks that consist of numerous nodes equipped with different sensors,such as magnetic sensors, cameras, microphones, etc. Such networks are supported by recent advances in low-power wireless communications technology as well as the integration of various functionalities in silicon,including sensing, communication, and processing. Therefore, WSNs are suitable to monitor and to interact with the physical environment and have been used for environmental monitoring [1], industrial and manufacturing automation [2], health-care [3], and military applications [4].
Acoustic signals contain a significant amount of information generated by sound sources, and this information can be used to describe and understand human and social activities. For this reason, acoustic monitoring related to sound event detection (SED)on WSNs has received a significant amount of attention over the last few years. Wireless acoustic sensor networks (WASNs) [5] consists of a certain number of microphones distributed over a given area to provide accurate spatial coverage of a sound scene, i.e., they increase the probability of having a subset of microphones close to a sound source, yielding higher quality recordings.
However, various factors may affect the service quality of WASNs. Due to the noisy sensed data of sensors and the wireless channel noise, it is difficult to guarantee accurate detection, especially when detecting multiple events. The wireless communication medium is also unreliable, and packets can collide or be lost. When numerous microphones are used, some channels will have a lower signalto-noise ratio (SNR) than others, depending on the distance from each of the microphones to the sound source. As such, an advanced approach is needed to select channels with a high sound quality to improve the accuracy of SED.
The aim of SED is to temporally identify sound events in a recording collected from a real-world auditory scene and to give each event a label from a set of possible labels.In everyday situations, most sounds that reach our ears originate from multiple sound sources, and the overlapping patterns of such acoustic events are unknown, so mixed or polyphonic sound detection is much more challenging than monophonic detection.
In recent years, deep neural networks(DNNs) [6-7] have achieved great success in various machine learning tasks and have also been applied to SED. Further improvements have been obtained with alternative types of neural network architectures, including convolutional neural networks (CNNs) [8], recurrent neural networks (RNNs) [9] and long short-term memory recurrent neural networks(LSTM-RNNs) [10]. LSTM-RNN works well on sequence-based tasks with long-term dependencies. However, gated recurrent neural networks (GRNNs) [11] have been shown to have comparable performance to LSTMRNNs in various applications, especially in sequence modeling, but with lower computational costs. Hence, multi-label GRNNs have been proposed for polyphonic acoustic event classification [12]. More recently, spatial and harmonic features from multi-channel audio have been successfully applied to LSTM-RNN and have shown considerable improvements over using only mono-channel audio [13].
In this paper, we capture and process sound signals in a WASN to improve home environmental monitoring. The contributions of the proposed system are as follows. (1) We propose a framework for SED in a WASN that includes signal estimation at a sink, reliable channel selection, and polyphonic SED to realize sound-based home monitoring. (2) During signal estimation, the packet loss due to multihop routing paths in wireless transmissions are recovered using sink-based packet loss concealment to improve the signal quality. (3)To improve the computational efficiency for distant SED without sacrificing performance,we use an approach to select reliable channels using a multi-channel cross-correlation coefficient. The two channels that are selected are then used for SED. (4) To efficiently classify overlapping sound events, spatial and spectral-domain noise-reduced features from the two-channel audio are used as high-resolution spectral inputs to train bidirectional GRNNs,which provide fast and stable convergence compared to LSTM-RNN.
The outline of this paper is as follows.In Section II, the proposed SED system in a WASN is explained. Section III presents the experimental results, and Section IV provides the conclusions and suggestions for further study.
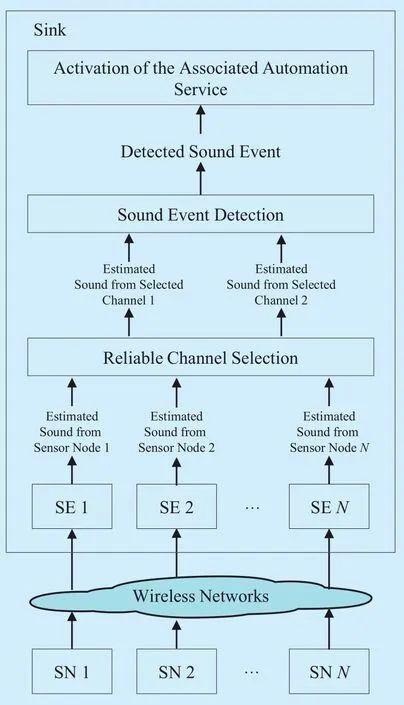
Fig. 1 Architecture of the proposed system
II. PROPOSED SOUND EVENT DETECTION IN A WASN
Figure 1 illustrates the structure of the proposed home monitoring system based on a wireless sensor network. The system targets polyphonic SED by using several wireless acoustic sensor nodes and a sink. The sink is mainly composed of four modules, including signal estimation, reliable sensor channel selection, SED, and activation of the associated automation service. The wireless sensor nodes simultaneously capture sounds generated in a room, and each sensor node can be equipped with a small microphone array. In this paper,we used only a single microphone for each sensor node.
The microphone at each sensor node receives mixed or polyphonic sounds, and the recorded mixed sound is encoded and transmitted as sound packets to the sink over the wireless links of the network, which can induce packet loss. When each sound packet arrives at the sink, it is decoded into a signal frame, and lost packets are recovered using packet loss concealment during signal estimation. Next, the set of microphones with the signals that are most highly correlated is chosen among the multiple microphone channels to improve the computational efficiency and achieve better performance. Finally, signals from two selected channels are used for environmental SED, which labels the detected sound event as important information to be monitored by the user or to activate an associated automation service.
2.1 Signal estimation at the sink
The major role of the WASNs is to sense and deliver data to the sink node. However,WASNs are associated with packet loss, which gets worse through multi-hop routing paths in wireless sensor networks. Sink-based signal estimation is needed to reduce packet loss.
The goal of signal estimation is to estimate the signal in real time while recovering lost packets due to multi-hop routing paths in wireless transmissions. Figure 2 presents a flow chart of an algorithm for the signal estimation at the sink for data over the WASN.
When an i-th packet of each microphone arrives at the sink from the sensor nodes, the sink strips the packet information and adequately places the packet in the packet buffer.The packet buffer releases packets for decoding at a regulated speed, thereby reducing system delay. Each signal frame is decoded from the packet buffer and stored in a signal frame buffer. For signal decoding, the G.722.2 voice codec [14] is used.
If the i-th signal frame is present from the signal frame buffer, then the root mean square(RMS) is computed directly on the received audio signal frame for signal activity detection. The signal frame with an RMS value less than the defined threshold will be treated as background noise or silence. Here, the threshold is obtained by averaging ten signal frames from the beginning. If the signal frame’s RMS value exceeds the threshold, the signal frame will be treated as sound or as a speech signal.
If the i-th signal frame is absent from the signal frame buffer, the packet is declared as lost. To recover lost packets, packet loss concealment is performed based on a recursive linear prediction (LP) analysis and synthesis [15].
If the number of lost packets is smaller than the defined packet loss threshold, the short packet loss concealment generates a synthesized sound using the excitation signal repetition of the previous received signal and overlap-add between the subsequent frame and previous frame. If consecutive packets are lost, then the previous synthesized signal is recursively input to an LP filter to generate a new smooth excitation signal and is gradually muted for the duration of the loss period to alleviate metallic artifacts and improve the sound quality.
If both the i-th signal frame and the (i-1)-th signal frame are present in the signal frame buffer, the i-th signal frame is entered directly into the reconstructed signal frame buffer. On the other hand, if the i-th signal frame is present in the signal frame buffer, the (i-1)-th signal frame is lost and two signal frames include sound or speech, “merging and smoothing” is initiated. By merging and smoothing, two signal frames in a transition region are smoothly interpolated to alleviate the discontinuity between the i-th signal frame and the (i-1)-th substituted signal frame.
2.2 Reliable channel selection from multi-channel audio
Depending on the distance between each microphone and the sound event source, some channels will have a lower signal quality than others, especially when a large microphone sensor is used. The SED system may benefit strongly if the signal with the highest quality is used for recognition or event detection. Several techniques commonly referred to as channel selection (CS) [16] have been proposed to find such a signal.
In this paper, we use a signal-based CS method with a multi-channel cross-correlation coefficient (MCCC) [17] to improve the computational efficiency for distant SED without sacrificing performance. The basic idea of this approach is to treat the channel that is uncorrelated with the others as unreliable and to select only a subset of microphones with the most correlated signals. The channel can be selected before the signal enters the classification part of the SED system, so recognition is made only once.
Our channel selection algorithm is summarized as follows:
Step 1. First, M channels with the packet loss at less than the defined loss threshold and a signal RMS value greater than the energy threshold are selected from the multi-channel microphones.
Step 2. The time delays of the M-channel signal are estimated using the generalized cross-correlation with phase-based weighting (GCC-PHAT) [18] due to our need for computational efficiency and robustness in the presence of noise and reverberation. The GCC-PHAT between two microphones i and j is computed as follows:
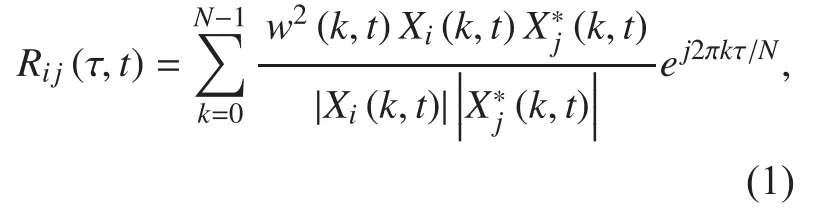
where X(k,t) are the fast Fourier transform coefficients of the k-th frequency at time frame t and w is a weighting function for the spectrum. PHAT weighting is computed as follows:
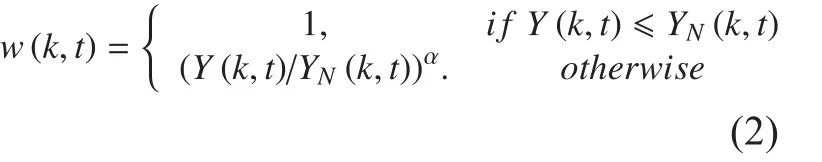
This weighting places equal importance on each frequency band. The weighting function gives greater weight to regions in the spectrum where the local SNR is the highest. Let Y(k,t) be the mean power spectral density for all microphones at a given time and YN(k,t) be a noise estimate based on the time average of the previous Y(k,t). The time delay of arrival(TDOA) [19] is estimated as ∆τij=argmaxRij(τ)because Rij(τ) is expected to have a global maximum at the location of the correlation peak magnitude τ=∆τij.
Step 3. Once the time delays of the M-channel signal are estimated based on the PHAT,the time-aligned signal can be obtained according to follows:
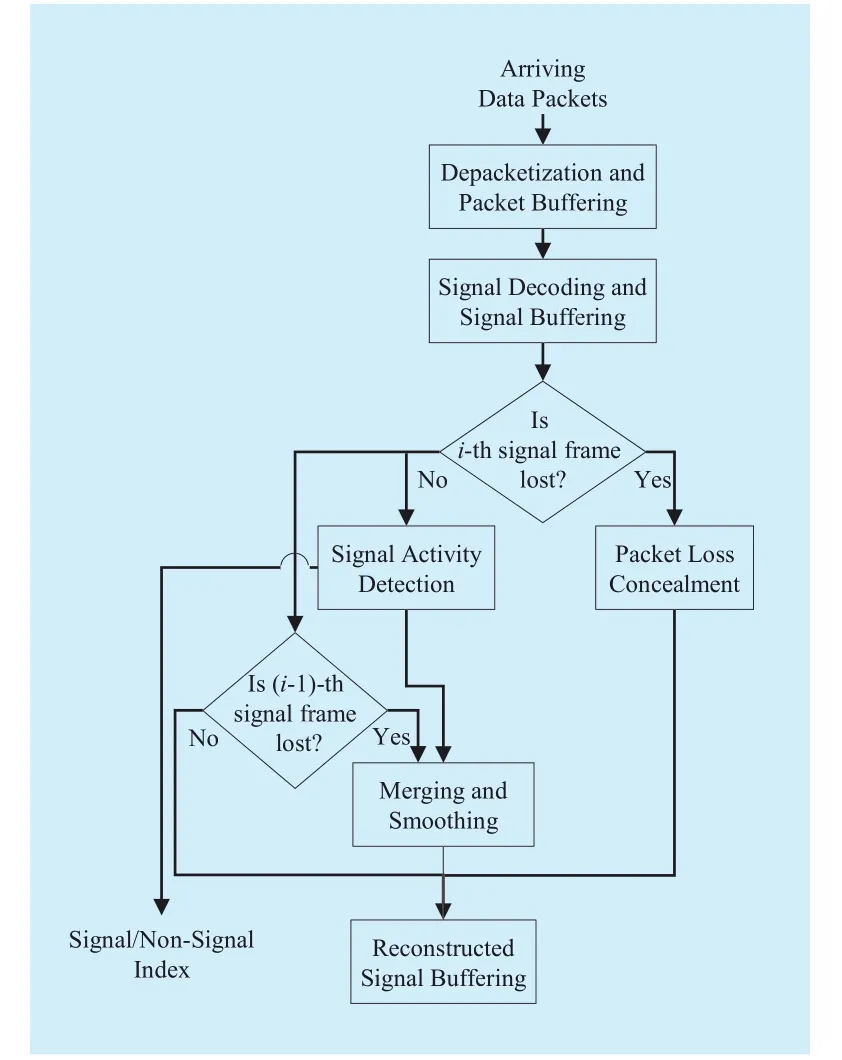
Fig. 2 Flow chart of the signal estimation
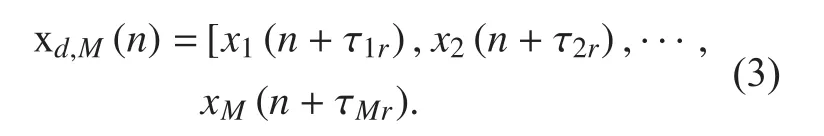
Next, MCCC [14] is computed with two channels as follows:
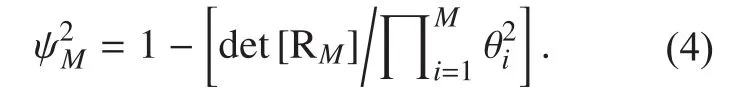
Using the spatial correlation matrix, which is expressed as follows:
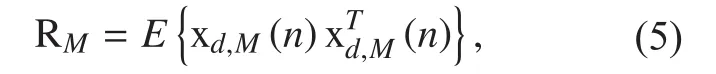
where det[.] denotes the determinant andis the i-th diagonal component of spatial correlation matrix RM. The MCCC can be readily to be equivalent to the cross-correlation coefficient normalized by the energy in the case of M = 2.
Step 4. We choose a set of channels with the maximum MCCC as follows:
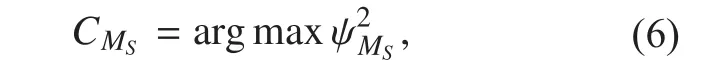
where CMsprovides the largest MCCC among all possible combinations and MSis the selected channels out of M microphones. The largest MCCC search method is performed with 500 milliseconds of sound data from the beginning by iteratively reducing the number of search candidates from M to MS. Specifically, we ignore the channel that provides the smallest MCCC and keep the remaining channels for the next step. This process is repeated until we obtain the desired number of channels, MS.Clearly, at least two channels must be retained so that the correlation can be evaluated.
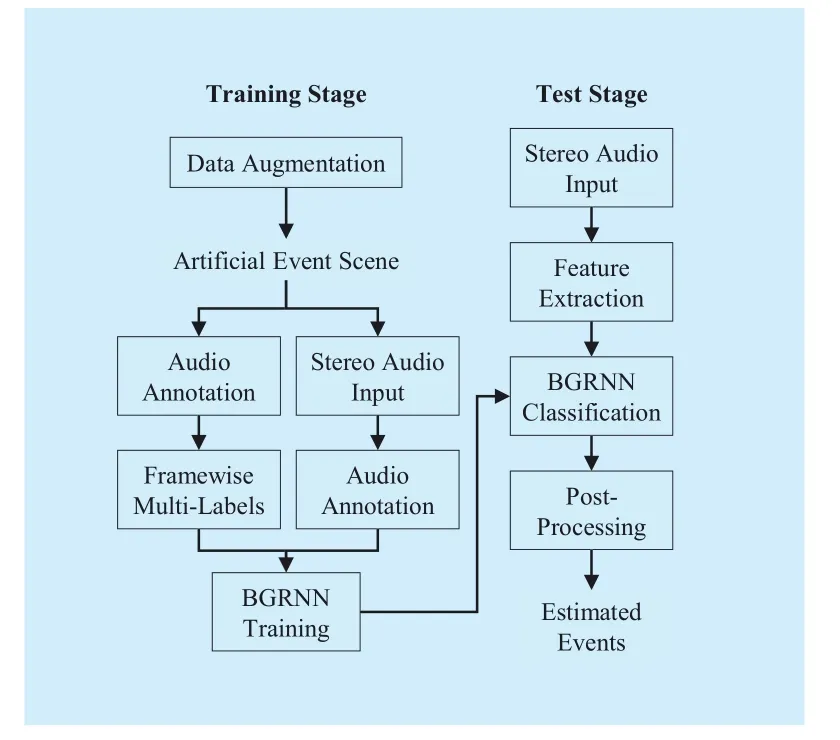
Fig. 3 Framework of the training and testing procedure for the proposed SED system
2.3 Sound event detection
SED aims to label temporal regions within the audio, within which a specific event class is active, by estimating the start and end of each event in a continuous acoustic signal. Figure 3 shows the process flow of the proposed SED system composed of a training stage and a test stage.
First, during the training stage, data augmentation using noise-mixing and pitch-shifting is performed to generate artificial sound event scenes that are used to train the classifier in order to deal with the data sparsity problem.Second, we compute the acoustic features in each frame for each of the two channels that are selected. Third, the acoustic features extracted from the two-channel audio are concatenated and used to train the bidirectional GRNNs (BGRNNs). During the test stage, we conduct acoustic event classification by inputting high-dimensional acoustic features from multi-channel audio into the trained BGRNNs.Similar to method by Mesaros et al. [20], we post-process the events by detecting contiguous regions and neglecting events smaller than 0.1 seconds as well as ignoring consecutive events with a gap smaller than 0.1 seconds.
Humans only have two ears yet can analyze an auditory scene in multiple dimensions.However, various types of noise exist in real life recordings, which makes it difficult to correctly detect sound events. As such, we extract two sets of features including a noise-reduced spectrogram and TDOA from the two-channel audio, as shown in the section 2.2. All features are extracted at a hop length of 20 ms to provide consistency across features.
To extract the noise-reduced spectrogram,each sound signal x(t) is transformed into a complex spectrogram X(k,t) using the shorttime discrete Fourier transform. The noise is estimated by extrapolating the noise from frames where a sound event signal is believed to be absent. These frames are detected via signal activity detection, which is applied to sink-based signal estimation. The reverberation time in each room is applied to estimate the reverberation. The estimated noise and reverberation are then subtracted from the input magnitude spectrogram to enhance the signal.Finally, the enhanced magnitude spectrogram is normalized using a logarithmic operation.State-of-the-art feature extraction techniques,including Mel-frequency cepstral coefficient(MFCC) or Mel-filter bank features, in acoustic event detection tend to provide broad characterizations but end up reducing details that are critical to deal with overlapping signals.On the other hand, a high-resolution spectrogram has more details and is more sparse [21].Therefore, we use log magnitude spectrograms as useful features to detect overlapping sounds.
For polyphonic SED, we use a multi-label BGRNN that has a relatively simplified architecture alternative to LSTM-RNN. In a BGRNN, each hidden layer is split into two separate layers, and in contrast with GRNN,one layer reads the training sequences forwards and the other one backwards.
LSTM uses three gates to control the information flows of the internal cell unit, whereas the gated recurrent unit (GRU) of the BGRNN only uses two gates: an update gate z and a reset gate r. The update gate controls the information that flows into memory while the reset gate controls the information that flows out of memory. Similar to the LSTM unit, the GRU has gating units that modulate the flow of the information inside the unit, however without a separate memory cell. Mathematically, the process is defined by (7) to (10).
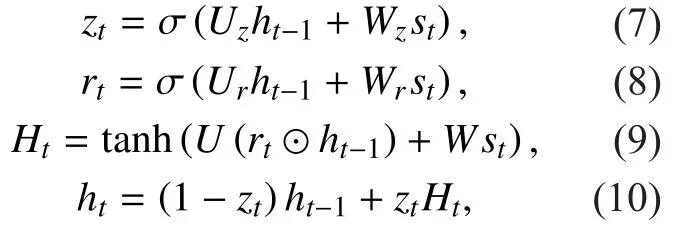
where st, ht, and Ht, denote current input, activation, and candidate activation, respectively.W, σ(·), and ⊙ are input-to-hidden weight matrix, element-wise logistic sigmoid function,and element-wise multiplication.
Equation (7) describes the update gate, (8)represents the reset gate, (9) calculates the candidate activation, and (10) shows how the output htis calculated. The activation of the GRU at time t is a linear interpolation between the previous activation and the candidate activation. The reset mechanism helps the GRU use the model capacity efficiently by allowing it to reset whenever the detected feature is no longer necessary. The update mechanism helps the GRU capture long-term dependencies.Whenever a previously-detected feature, or the memory content, is considered to be important for later use, the update gate will be closed to carry the current memory content across multiple time-steps [11].
III. EXPERIMENTS AND RESULTS
In this subsection, the performance of the proposed approach with real life audio is evaluated. The subsections below contain the data set used for our evaluation, the experimental setup, and a description of the performance observed when using the proposed approach.
3.1 Experimental setup
The living area used in our experiments consists of a 30 m2apartment. The rooms are equipped with sound sensors, and the sensors are located as follows. 6 microphones are distributed in every room (kitchen, hall, living-room, sleeping-room, shower-room and toilet). Real sounds are recorded with sound sensors from various everyday environments.The data set consists of a total of 1600 recordings, and each of them are 5 to 15 minutes long. The total duration of the recordings is 18000 minutes. Recordings were done using a 16 kHz sampling rate and 24 bit resolution.The sound corpus contains 10 sound classes:door banging sounds (223 samples), baby crying sounds (172 samples), walking sounds(320 samples), door locking sounds (82samples), dish falling sounds (93 samples),glass breaking (105 samples), falling objects sounds (120 samples), screams (87 samples),telephone or door bell ringing (75 samples),human talking voice (323 samples), etc. For each mixture, randomly selected samples from the event classes are added to the mixture by introducing a random time delay, adding a sample to the mixture and repeating this until the end of the mixture. Among the annotated frames, the polyphony percentage of the test set is given in table 1. By doing this for each class, a mixture is obtained with time-varying polyphony. The mixed or polyphony samples are randomly distributed with 60% in the training set, 20% in the validation set and 20%in the test set.

Table I Polyphony level versus data amount percentage for the annotated frames in the test set
A test bed is setup for the SED in a WASN.The test-bed consists of one sink node and 36 sensor nodes. All nodes are uniformly placed along a straight line. The sink is put at one end of the line, and the other end of the node serves as the data source that generates the packet. Other nodes only serve as forwarding nodes. The transmission power is set to 0 dbm,resulting in a transmission range of about 4 meters. The wireless frequency is set to 890 MHz, with a bandwidth of 38.4 kbps. The packet size is fixed at 36 bytes, resulting in a maximal capacity of 133 packets per sec (pkt/s) per link. The packet generation rate is 0.5 pkt/s to simulate the WASN connections with different random traffic loads, including a delay (25~80 ms), jitter (40~300 ms) and packet loss (2~10%). For the experiments in this paper, we used an 8% packet loss rate.
To implement the SED system on the WASN, several experiments were conducted to find the most suitable setup. For several experimental setups, the SE (signal estimation),CS (channel selection), 2 (two-channels),NR (noise reduction), ST (spectrogram), ME(Mel-band energy) are used.
The performance of the proposed system was then compared to those of different classifiers with different features, as follows:
1) Baseline (BL): The baseline system uses 20 static, 20 delta and 20 acceleration MFCC coefficients extracted on one-channel audio. Before the feature extraction,SE and CS are performed, and NR is not applied. A Gaussian mixture model(GMM) consisting of 16 Gaussians is then trained for each of the positive and negative values of the class.
2) Proposed Method (PM): The PM is composed of SE, CS, NR2, ST2, TDOA, and BGRNN. After SE and CS, two-channel NR-based feature extraction is performed.From each frame for each of the two channels, noise-reduced 512 log-magnitude spectrogram values are extracted, and 1 TDOA value per frame is extracted using two-channel audio. The BGRNN has an input layer with 40 units (each reading one component of the feature frame) and three hidden layers with 200 GRU units.3-layer BGRNNs are initialized with orthogonal weights and rectifier activation functions. The output layer has one neuron for each class. The network is trained using back-propagation through time with binary cross-entropy as a loss function.Regarding the training procedure, we extend the on-the-fly shuffling routine in two ways: (1) we drop frames with a probability of 50% and (2) use smaller permuted sequence batches.
3) Method 1 (M1): M1 is composed of SE,CS, NR, ST, TDOA, and BGRNN. Instead of the two-channel features of M1,one-channel features per frame are applied to the BGRNN classifier. After SE and CS, NR-based 512 log-magnitude spectrogram and 1 TDOA value per frame are extracted. In order to obtain one-channel audio signal, the signals of the two channels are averaged.
4) Method 2 (M2): M2 is composed of SE,CS, NR2, ME2, TDOA, and BGRNN.From each frame for each of the two channels, noise-reduced 20 Mel-band energy values are extracted after SE and CS. 1 TDOA value per frame is extracted using two-channel audio. The two-channel features are applied to the BGRNN classifier.
5) Method 3 (M3): M3 contains CS, NR2,ST2, TDOA, and BGRNN. Instead of the one-channel features, two-channel noise-reduced log-magnitude spectrogram features per frame are extracted. They are applied with 1 TDOA to the BGRNN classifier. However, SE is not used before CS.
6) Method 4 (M4): M4 is the concatenation of CS, ST2, TDOA, and BGRNN. Instead of one-channel features, two-channel log-magnitude spectrogram features without SE and NR are extracted per frame.They are applied with 1 TDOA to the BGRNN classifier.
7) Method 5 (M5): M5 contains CS,ME2, TDOA, and BGRNN. Instead of one-channel features, two-channel Melband energy features without SE and NR are extracted per frame. For the classifier,the BGRNN is used.
8) Method 6 (M6): M6 includes CS, ST,TDOA, and BGRNN. One-channel log-magnitude spectrogram features without SE and NR are extracted per frame and are applied with 1 TDOA to the BGRNN classifier.
9) Method 7 (M7): M7 is composed of SE,CS, NR2, ST2, TDOA, and GRNN. Instead of the BGRNN classifier of M1, a GRNN is used as classifier with two-channel features.
10) Method 8 (M8): M8 consists of SE, CS,NR, ST, TDOA, and GRNN. Instead of the two-channel features, one-channel noise-reduced log-magnitude spectrogram features after SE and CS are extracted per frame. They are applied with 1 TDOA to the GRNN classifier instead of BGRNN.
11) Method 9 (M9): M9 is composed of SE,CS, NR2, ST2, TDOA, and LSTM. Instead of a GRNN classifier of M7, an LSTM is used as a classifier with two-channel features. The LSTM-RNN has an input layer with 40 units (each reading one component of the feature frame) and two hidden layers with 200 LSTM units. The output layer has one neuron for each class. The network is trained using back-propagation through time with binary cross-entropy as a loss function.
12) Method 10 (M10): M10 is SE, CS, NR,ST, TDOA, and LSTM. Instead of the GRNN classifier of M8, an LSTM is used as a classifier with one-channel features.
We used the PyBrain Toolbox [20] to implement the LSTM and GRU. In the configuration of LSTM-RNN, GRNN, and BGRNN,the size of the input layer is changed according to the feature dimensions.
The evaluation metrics of the system performance for SED were the error rate (ER)and F-scores calculated on one-second-long segments:
1) ER measures the amount of errors in terms of the insertions (I), deletions (D) and substitutions (S). The error rate is calculated by integrating the segment-wise counts over the number of segments K, with N(k) being the number of active ground truth events in segment k.
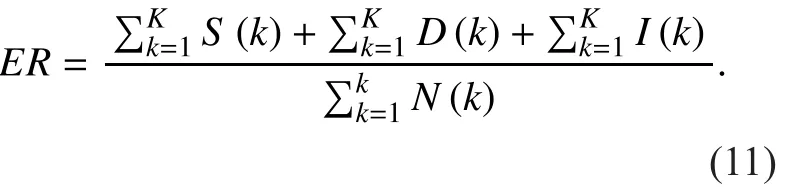
2) The F-score is a measure of a test’s accuracy. It considers both the precision and the recall of the test to compute the score. The F-score can be interpreted as a weighted average of the precision and recall, with its best value at 100% and worst at 0%.
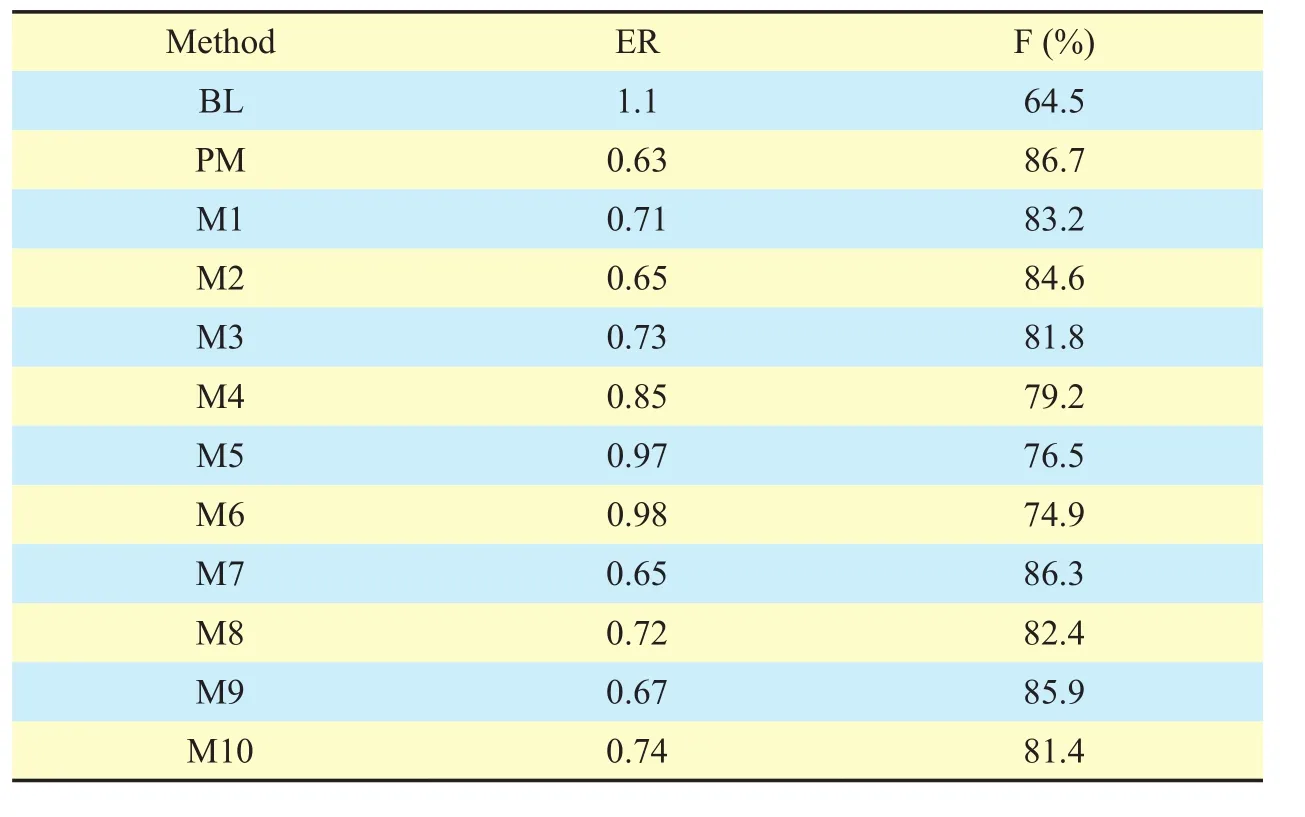
Table II Comparison of the segment-based error rate and f-score for different combinations of classifiers and features
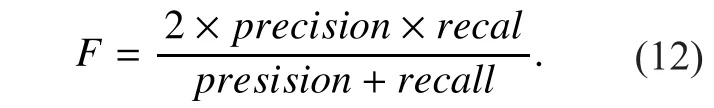
The detailed measures are explained by Mesaros et al. [22].
3.2 Results
Table 2 depicts the experimental results for the segment-wise SED in a WASN. The experimental results of the proposed method are compared to those for baseline and for several methods, including alternative types of neural network architectures and different feature sets.
As shown in table 2, the baseline system,BL, has an event average ER of 1.1 and an F-score of 64.5%. An ideal system should have an ER of 0 and an F-score of 100%. The proposed approach, PM, significantly outperforms the baseline in terms of both ER and F. The F-score and ER of the PM for segment-based metrics are 0.63 and 86.7%, respectively. From these results, we can confirm that SE, CS, and NR provide significant help in detecting the overlapping sound events. BGRNN achieves better classification results than GMM and LSTM trained on the same SE, CS, NR, and audio features. These results are slightly higher than those of the method using GRNN.
Interestingly, we can also see that spatial and noise-reduced spectrogram features from two-channel audio show considerable improvements over just using one-channel audio when used in the same classifier. Furthermore,table 2 reports that feeding spectrogram features into the gated recurrent neural network architecture, such as LSTM and GRU, improves the classification performance compared to Mel-band energy features.
IV. CONCLUSION
In this paper, we have proposed a framework consisting of signal estimation at a sink, reliable channel selection, and polyphonic SED techniques in a WASN to realize sound-based home monitoring. The sink-based signal estimation recovered lost packets or conceals packet loss from multi-hop routing paths in wireless transmissions, and the approach to select reliable channels using MCCC increases the computational efficiency for distant SED.In the detection and classification of environmental sounds, the BGRNN classifier in combination with two-channel features performed significantly better than the GMM baseline system using mono-channel features.
In future work, we will focus on extending BGRNNs by coupling them with convolutional neural networks and deep neural networks to improve the detection accuracy of the overlapping sounds. The proposed framework will be applied to audiovisual context sensing and monitoring in wireless sensor networks for Internet-of-Things devices.
ACKNOWLEDGEMENTS
This research was supported by Basic Science Research Program through the National Research Foundation of Korea(NRF)funded by the Ministry of Education (NRF-2015R1D1A1A01059804) and the MSIP(Ministry of Science, ICT and Future Planning), Korea, under the ITRC(Information Technology Research Center) support program(IITP-2016-R2718-16-0011) supervised by the IITP(Institute for Information & communications Technology Promotion. And the present Research has been conducted by the Research Grant of Kwangwoon University in 2017.
[1] P. Sharma, “Wireless sensor networks for environmental monitoring,” Int. J. Scientific Res. Eng.Technol., vol. 1, no. 9, pp. 36–38, Nov. 2014.
[2] M. R. Akhondi, A. Talevski, S. Carlsen, and S.Petersen, “Applications of wireless sensor networks in the oil, gas and resources industries,”in Proc. Int. Conf. Advanced Inform. Networking and Appl. (AINA), Perth, Australia, 2010, pp.941–948.
[3] Y.-T. Peng, C.-Y. Lin, M.-T. Sun, and K.-C. Tsai,“Healthcare audio event classification using hidden Markov models and hierarchical hidden Markov models,” in Proc. IEEE Int. Conf. Multimedia Expo (ICME), Cancun, Mexico, 2009, pp.1218–1221.
[4] M. P. Durisic, Z. Tafa, G. Dimic, and V. Milutinovic, “A survey of military applications of wireless sensor networks,” in Proc. Mediterranean Conf. Embedded Computing (MECO), Bar, Mon-tenegro, 2012, pp. 196–199.
[5] D. T. Blumstein et al. “Acoustic monitoring in terrestrial environments using microphone arrays: applications, technological considerations and prospectus,” J. Appl. Ecol., vol. 48, no. 3, pp.758–767, Jun. 2011.
[6] E. Cakir, T. Heittola, H. Huttunen, and T. Virtanen, “Polyphonic sound event detection using multi label deep neural networks,” in Proc. Int.Joint Conf. Neural Networks (IJCNN), Killarney,Ireland, 2015, pp. 1–7.
[7] E. Cakir, T. Heittola, H. Huttunen, and T. Virtanen, “Multi-label vs. combined single-label sound event detection with deep neural networks,” in Proc. 23rd Eur. Signal Process. Conf.(EUSIPCO), Nice, France, 2015, pp. 2551–2555.
[8] H. Zhang, I. McLoughlin, and Y. Song, “Robust sound event recognition using convolutional neural networks,” in Proc. IEEE Int. Conf. Acoust.,Speech, Signal Process. (ICASSP), South Brisbane, Queensland, Australia, 2015, pp. 559–563.
[9] A. Graves, A.-R. Mohamed, and G. Hinton,“Speech recognition with deep recurrent neural networks,” in Proc. IEEE Int. Conf. Acoust.,Speech, Signal Process. (ICASSP), Vancouver, BC,Canada, 2013, pp. 6645–6649.
[10] G. Parascandolo, H. Huttunen, and T. Virtanen,“Recurrent neural networks for polyphonic sound event detection in real life recordings,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Shanghai, China, pp. 6440–6444.
[11] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio,“Gated feedback recurrent neural networks,”in Proc. Int. Conf. Mach. Learning (ICML), Lille,France, 2015, pp. 2067–2075.
[12] M. Zöhrer and F. Pernkopf, “Gated recurrent networks applied to acoustic scene classification and acoustic event detection,” presented at the Detection and Classification of Acoustic Scenes and Events 2016 (DCASE2016), Budapest,Hungary, Sep. 3, 2016.
[13] S. Adavanne, G. Parascandolo, P. Pertila, T. Heittola, and T. Virtanen, “Sound event detection in multichannel audio using spatial and harmonic features,” presented at the Detection and Classification of Acoustic Scenes and Events 2016(DCASE2016), Budapest, Hungary, Sep. 3, 2016.
[14] M. Yousef and M. Fouad, “Performance analysis of speech quality in VoIP during handover,” Int.J. Comput. Sci. Inform. Security, vol. 12, no. 9,pp. 43–48, Sep. 2014.
[15] B. H. Kim, H.-G. Kim, J. Jeong, and J. Y. Kim, “VoIP receiver-based adaptive playout scheduling and packet loss concealment technique,” IEEE Trans.Consum. Electron., vol. 59, no. 1, pp. 250–258,Feb. 2013.
[16] M. Wölfel, “Channel selection by class separability measures for automatic transcriptions on distant microphones,” in Proc. Interspeech, Antwerp, Belgium, 2007, pp. 582–585.
[17] K. Kumatani, J. McDonough, J. F. Lehman, and B.Raj, “Channel selection based on multichannel cross-correlation coefficients for distant speech recognition,” in Proc. Joint Workshop Hands-free Speech Commun. Microphone Arrays (HSCMA),Edinburgh, UK, 2011, pp. 1–6.
[18] M. Brandstein and D. Ward, Microphone arrays:signal processing techniques and applications,Germany: Springer Verlag and Heidelberg, 2001.
[19] D. Pavlidi, A. Griffin, M. Puigt, and A. Mouchtaris, “Real-time multiple sound source localization and counting using a circular microphone array,” IEEE Trans. Audio, Speech, Lang. Process.,vol. 21, no. 10, pp. 2193–2206, Oct. 2013.
[20] A. Mesaros, T. Heittola, and T. Virtanen, “TUT database for acoustic scene classification and sound event detection,” in Proc. 24th Eur. Signal Process. Conf. (EUSIPCO), Budapest, Hungary,2016, pp. 1128–1132.
[21] M. Espi, M. Fujimoto, and T. Nakatani, “Acoustic event detection in speech overlapping scenarios based on high-resolution spectral input and deep learning,” IEICE Trans. Inform. Syst., vol.E98D, no. 10, pp. 1799–1807, Oct. 2015.
[22] A. Mesaros, T. Heittola, and T. Virtanen, “Metrics for polyphonic sound event detection,” Appl.Sci., vol. 6, no. 6, pp. 1–17, Jun. 2016.

- China Communications的其它文章
- An Iterative Detection/Decoding Algorithm of Correlated Sources for the LDPC-Based Relay Systems
- Homomorphic Error-Control Codes for Linear Network Coding in Packet Networks
- Polar-Coded Modulation Based on the Amplitude Phase Shift Keying Constellations
- A Privacy-Based SLA Violation Detection Model for the Security of Cloud Computing
- An Aware-Scheduling Security Architecture with Priority-Equal Multi-Controller for SDN
- A Flow-Based Authentication Handover Mechanism for Multi-Domain SDN Mobility Environment