
海量雷达数据异常轨迹分析
2017-03-29 05:37孟凡君管志强
电子科技 2017年1期
孟凡君,曹 伟,管志强
(南京船舶雷达研究所 人力资源部,江苏 南京 210000)
海量雷达数据异常轨迹分析
孟凡君,曹 伟,管志强
(南京船舶雷达研究所 人力资源部,江苏 南京 210000)
针对敌对伪装目标潜入我重点海域进行敌对活动时,难以利用民用手段或雷达特性区分识别的问题。通过分布式并行处理积累的雷达数据,总结各类目标活动规律,能够分析对比发现伪装目标。针对雷达数据的海量特性,使用分布式处理框架Hadoop处理原始雷达数据,生成轨迹知识库,并以知识库为基础利用异常轨迹分析算法判断轨迹是否异常。结果表明,该方法大约3天实现了全年雷达数据的异常轨迹分析,并能通过增加节点进一步提升分析速度。
雷达数据;分布式存储;并行处理;异常轨迹
各类敌对伪装目标通过不安装AIS设备或利用伪装AIS,潜伏进入我重点海域进行侦查监视等敌对活动,利用民用识别手段或雷达特性难以区分此类目标[1]。而通过分析雷达数据[2]中的雷达航迹和AIS数据记载的各类目标运动轨迹[3-4],总结各种目标活动规律,能够从中发现其中的伪装或异常目标,提高我方指挥员的判情识别能力。雷达数据持续产生,各基站单日雷达数据超过百万条,达到GB级,各年数据量超过TB级,常见的异常轨迹检测算法如TROAD算法[5-6]在如此大数据量下都会产生巨额分析时间。如何高效地从海量的雷达数据中发现目标运动规律,分析出异常轨迹是一个亟待解决的难题[7]。
为完成对海量数据的异常分析,本文选取了并行处理框架Hadoop[8-10]搭建雷达数据处理平台。依靠HDFS和HBase实现了海量雷达数据分布式存储[11-14],通过MapReduce实现了海量雷达数据的并行处理,发现目标的运动规律,并以此为基础利用异常轨迹分析算法分析目标轨迹是否异常。
1 数据处理流程
雷达数据的处理流程如图1 所示。
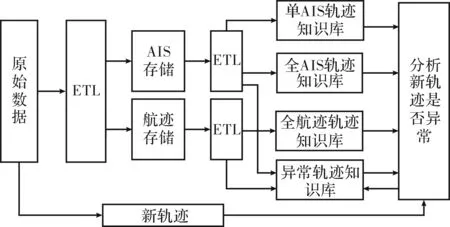
图1 数据处理流程图
首先利用Hadoop清洗、整理原始数据,分别将AIS数据和航迹数据抽取、转化、加载(ETL)到AIS存储和航迹存储中。其次考虑数据的特点及应用,分别对AIS存储和航迹存储进行并行处理生成单AIS轨迹知识库、全AIS轨迹知识库、全航迹轨迹知识库。最后,利用异常轨迹分析算法以及3个知识库的历史轨迹规律,判断所有轨迹是否异常。
2 雷达数据存储设计
雷达数据和轨迹规律都需要存储在HBase中,主要分为基础数据存储和轨迹知识库[15]。
2.1 基础数据存储
基础数据存储包含了所有的有效数据,并将单个目标单日的数据集合确立为一个对象集中存储,是目标轨迹提取以及规律分析的基础,分为AIS存储和航迹存储。
2.2 轨迹知识库设计
轨迹知识库存储了经分析处理得到的目标运动规律,是异常轨迹分析必备的对比知识库。
2.2.1 全AIS轨迹知识库
全AIS轨迹知识库从时间、位置坐标、运动属性、身份属性4个方面描述全体AIS目标的整体分布规律,为判断新航迹信息是否异常提供目标分布规律。存储时以“时间+航速+航向+国籍”为行键,其结构如表1所示。

表1 全AIS轨迹知识库结构表
2.2.2 全航迹轨迹知识库
全航迹轨迹知识库从时间、位置坐标、运动属性、关联AIS信息4个方面描述全体航迹目标的整体分布规律,主要描述无关联AIS的民用小目标和军事目标在各类维度条件下的整体时空分布规律,用于判断无关联AIS航迹轨迹是否异常。其结构如表2所示。

表2 全航迹轨迹知识库结构表
2.2.3 单AIS轨迹知识库
单AIS轨迹知识库从时间和位置坐标两方面描述单个AIS目标的航行规律,通过计算某一AIS目标轨迹与库中目标航行线路相似度判断新轨迹是否异常,通过计算新航迹轨迹与库中目标航行线路相似度判断疑似MMSI号。一个目标有唯一MMSI号,并集中行驶于多条航行路线,因此,对目标航行线路以“MMSI+ID”为行键存储,其结构如表3所示。

表3 单AIS轨迹知识库结构表
2.2.4 异常轨迹知识库
异常轨迹知识库描述某一类异常轨迹的坐标分布和出现的时间规律,通过计算新目标轨迹与库中异常轨迹相似度判断新轨迹所属异常轨迹类,获取轨迹出现规律。通过对所有异常轨迹聚类分析处理,将其分为若干类异常轨迹,给每类异常轨迹分配ID,并以“ID”为行键,其结构如表4所示。

表4 异常轨迹知识库结构表
3 轨迹知识库生成
3.1 全AIS轨迹知识库生成
视AIS存储为一个六维数据集,在确立国籍、时间、航速、航向4个维度的情况下,将所有经纬度坐标信息存储到同一个矩阵内,经处理得目标分布日规律。所有矩阵构成AIS信息多维数据集,对日规律按月上卷得目标分布月规律。算法如下:
(1)Hadoop将AIS存储切分,并将每个分片交给各数据节点(DataNode)上的Map Task处理;
(2)Map阶段。各Map Task从输入分片中解析出数据,并将其转换为键值对<行键1,经纬度>,其中,行键1 为“日期+航速+航向+国籍”;
(3)Reduce阶段。利用Hash函数将Map输出按其键值分块,复制于各Reduce Task,合并Map输出,将相同键的“经纬度”坐标合并到一个矩阵中,并按年平均,所得“矩阵”的每一位数值为该日期对应坐标内目标出现频率即全AIS历史轨迹分布日规律;
(4)Map阶段。将知识库中日规律分配于各Map Task,并将其转换为键值对<行键2,矩阵>,其中,行键2 为“月份+航速+航向+国籍”;
(5)Reduce阶段。各Reduce Task合并Map输出,将相同键的“矩阵”相加,得到“矩阵*”即AIS历史轨迹分布月规律,将其存储到全AIS轨迹知识库中。
3.2 全航迹轨迹知识库生成
全航迹轨迹知识库生成原理与全AIS轨迹知识库类似,Map后键值对为<日期+航速+航向+关联AIS信息,经纬度>,存储时以(日期(月份)+航速+航向+关联AIS信息)为行健。
3.3 单AIS轨迹知识库生成
单AIS轨迹知识库的生成分为两部分:获取轨迹和轨迹聚类分析。对每一个MMSI号目标分别执行这两步。
3.3.1 获取轨迹
对应的MapReduce并行实现算法为:
(1)Map阶段:各Map Task从输入分片中解析出数据,并将数据中行键包含指定MMSI的数据转换为键值对<行键,经纬度>;
(2)Reduce阶段。各Reduce Task合并Map输出,将相同键的值合并,并用矩阵表示,得新键值对<行键,矩阵>。
3.3.2 轨迹聚类分析
轨迹聚类分析合并相似轨迹形成航行线路,流程图如图2所示。
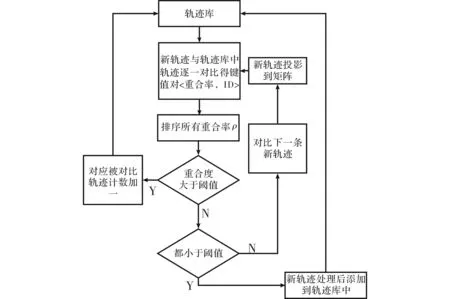
图2 轨迹聚类分析流程图
(1)准备阶段。将第一个键值对的矩阵中轨迹膨胀并去重,添加到轨迹库,该轨迹ID为1,计数1,并保存日期;
(2)对比阶段。将下一个键值对对应矩阵与轨迹库中矩阵按ID对比,得键值对<重合率,ID >。重合率ρ表示两矩阵对应位均非零的元素个数占库中矩阵非零元素个数的百分比;
(3)判断阶段。分析各键值对<重合率,ID>,若重合率不小于阈值ρ0,则单AIS轨迹库中该ID对应计数加1,添加日期;若所有键值对重合率均<ρ0,则将新轨迹膨胀去重化后添加到单AIS轨迹库中,并计数1,保存日期。判断下一键值对,转步骤(2);
(4)MapReduce并行阶段。当轨迹库中轨迹数目达到N时,开启并行处理。由Hadoop将轨迹库数据分于各Map Task,生成键值对<重合率,ID >。按重合率排序键值对,执行判断操作。
将每个MMSI号对应的轨迹库中不同轨迹存入单AIS轨迹知识库“MMSI+ID”行“路线轨迹”列中,并按月将轨迹计数除以总轨迹数得该轨迹占总轨迹百分比存入“轨迹占比”列,将该轨迹出现过的日期存入“日期”列。分别计算每个MMSI号的历史轨迹,生成单AIS轨迹知识库。
3.4 异常轨迹知识库生成
异常轨迹知识库生成分成3大部分:首先利用异常轨迹分析算法分析全部雷达数据获得所有异常轨迹;其次利用轨迹聚类分析方法将异常轨迹聚类,发现相似轨迹出现规律;最后将每一类轨迹存储到“轨迹”列中,“日期”列存储出现过的日期。对日期按月统计求各月出现次数占总次数的百分比,得该类异常轨迹出现月规律,存储到“规律列”。并在“备注”列中保存该类异常轨迹出现过的MMSI号、国籍等信息作为备用。
4 异常轨迹分析
异常轨迹可以根据是否有MMSI号分为两类,分析目标轨迹是否异常流程如图3所示。
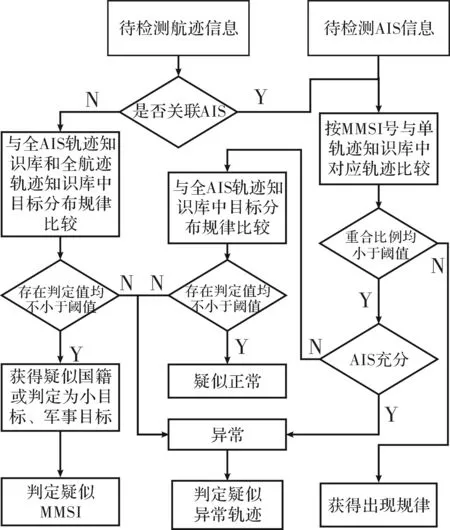
图3 新轨迹异常分析流程图
(1)对于无关联AIS航迹信息。首先根据其出现日期、航速、航向等,分别在两个全轨迹知识库中找到对应时段的目标分布并逐个对比,计算轨迹平均频率和重合率,方法如下:轨迹的平均频率为
(1)
轨迹重合率为
(2)
其中,新目标轨迹用坐标表示为(G1,G2,…,Gz);Gi表示一个坐标,其在目标分布中出现的频率为pi;pi为零的个数为n;z为轨迹坐标总个数。判定异常频率的阈值为p0,异常重合率的阈值为μ0。
1)若存在轨迹分布满足p≥p0且μ≥μ0,则判定目标轨迹正常,进一步判断:若该目标分布为全AIS目标轨迹分布,可获得目标疑似国籍,与单AIS轨迹知识库中的航行线路逐条对比,获得疑似MMSI号及航行规律;若该轨迹分布为无关联AIS全航迹轨迹分布,判定为疑似小目标或军事目标;
2)若不存在轨迹分布满足p≥p0且μ≥μ0,则判定目标轨迹异常,可与异常轨迹库中的轨迹逐个对比,寻找疑似已归类异常轨迹,并查找该类轨迹的出现频率和更多历史轨迹信息。
(2)对于AIS信息或关联AIS的航迹信息,首先与单AIS轨迹知识库中该MMSI号下对应月占比>10%的航行路线依次对比。
1)若重合比例均小于一定阈值 ,在单AIS轨迹知识库不充分的情况下,与全AIS轨迹知识库中对应的目标分布对比,如果存在轨迹分布满足p≥p0且μ≥μ0,则疑似正常,否则均判定为异常轨迹,与异常轨迹知识库中的轨迹逐条对比,寻找该轨迹曾经的出现规律,并查找该轨迹历史信息,获取更多轨迹信息;
2)若存在重合比大于一定阈值,则取相似度最高的轨迹为目标疑似航行线路,并获得该轨迹出现的频率。
分析疑似MMSI和异常航迹时需要并行处理。
5 实验结果分析
实验数据为某雷达基站2014年全年的AIS数据和航迹数据。
5.1 异常目标发现
通过对2014年雷达数据的分析,共发现1 464类异常轨迹。分为以下两个场景。
场景1 使用单AIS目标轨迹知识库。
图4中的轨迹均是MMSI号为210296000目标的航行轨迹,其中粗线为主要航行线路分布,圆圈中细线仅有一小部分与常见航行线路重合,经计算p=19%,为异常轨迹。

图4 基于MMSI异常轨迹对比图
场景2 使用全AIS目标轨迹知识库或全航迹目标轨迹知识库。
图5中浅色区域为全AIS轨迹分布,深色轨迹横穿灰色区域,并有一部分处于无目标分布区域,经计算P=45且μ=13%,为异常轨迹。

图5 基于全AIS异常轨迹对比图
5.2 处理效率对比
对比集中式处理,3节点分布式处理,5节点分布式处理生成4个知识库所需时间,如表5所示。

表5 不同框架生成轨迹知识库时间对比表 /h
结论:经对比发现,3节点分布式框架处理速度略好于集中式框架,5节点分布式框架处理能力有较大提升。原因在于分布式有更多数据传输与处理,3节点分布式框架只有2个数据节点实现数据处理,5节点分布式有4个数据节点,处理能力近乎3节点的两倍。5节点分布式处理框架基本满足了异常轨迹建库的时间需求。
6 结束语
本文提出的基于Hadoop平台的分布式雷达数据处理系统实现了海量雷达数据的存储,并从中发现目标运动规律,生成目标轨迹知识库,进一步利用异常轨迹分析算法高效地实现了轨迹的异常判断,获取异常轨迹规律,为指战员判断敌对伪装目标提供了参考。此外,本文还有很多需要改进之处,一方面航迹数据和AIS数据还有很多潜在价值值得挖掘;另一方面,需要寻找更好的方法将轨迹化简合并,减少轨迹库中的目标单元。
[1] 潘家财,邵哲平,姜青山. 数据挖掘在海上交通特征分析中的应用研究[J].中国航海, 2010, 33(2): 61-62.
[2] 陈勇.一种目标航迹数据聚类挖掘分析方法[J].无线电工程, 2015(3):22-24.
[3] 孟庆鹏,章碧,骆彬. 雷达及其信号信息数据库的设计[J].雷达与对抗,2010,30(2): 60-63.
[4] 王艳军,王晓峰.AIS和北斗终端组合在船舶动态监控中的应用[J].上海海事大学学报, 2011,32(4):17-21.
[5] Sun Z,Jin H,Wang X, et al. Trajectory outlier detection: a partition-and-detect framework[C].Beijing:IEEE International Conference on Data Engineering. IEEE Computer Society, 2008.
[6] 朱钥,贾思奇,张俊魁,等. 基于Hadoop的城市交通碳排放数据挖掘研究[J].计算机应用研究,2011, 28(11):4213-4215.
[7] Yu Xu,Pekka Kostamaa,Yan Qi,et al.A hadoop based distributed loading approach to parallel data warehouses[C]. New York: Proceedings of the 2011 International Conference on Management,2011.
[8] Apache Software Foundation. Hadoop [EB/OL]. (2013-10-15)[2015-04-15]http://hadoop.apache.org.
[9] 姜文.基于Hadoop平台的数据分析和应用[D].北京:北京邮电大学,2011.
[10] 邱荣太.基于Hadoop平台的MapReduee应用研究[D].郑州:河南理工大学,2009.
[11] 于恒友,刘波,彭子平.基于HBase的输电线路综合数据存储方案设计[J].电力科学与技术学报,2014(2):58-64.
[12] 陈庆奎,周利珍.基于HBase的大规模无线传感网络数据存储系统[J].计算机应用,2012,32(7):1920-1923.
[13] 李振举,李学军,谢剑薇,等. 基于HBase的海量地形数据存储[J].计算机应用,2015, 35(7):1849-1853.
[14] 范建永,龙明,熊伟.基于HBase的矢量空间数据分布式存储研究[J].地理与地理信息科学,2012,28(5):39-42.
[15] Cheng P, An J. The key as dictionary compression method of inverted index table under the hbase database[J]. Journal of Software, 2013, 8(5):1086-1093.
The Abnormal Path Analysis of Massive Radar Data
MENG Fanjun,CAO Wei,GUAN Zhiqiang
(Human Resources Department,Nanjing Marine Radar Institute,Nanjing 210000,China)
It’s difficult to use civil means or radar characteristics to distinguish Hostile target diving our key sea areas for hostile activities. Through the distributed parallel processing of radar data, summing up the rules of various types of target activities can analyze and find the camouflage targets. In view of the massive characteristics of radar data, the distributed processing framework Hadoop is used to process the raw radar data. The path knowledge bases are generated,which is used to determine whether the trajectory is abnormal with the abnormal path analysis algorithm. The results show that the proposed method can achieve the abnormal trajectory analysis of the whole year radar data within about three days, and the analysis speed will increase by increasing the node.
radar data; distributed storage; parallel process; abnormal path
2016- 03- 13
孟凡君(1991-),男,硕士研究生。研究方向:雷达数据处理等。曹伟(1968-),男,博士,研究员。研究方向:雷达数据处理等。管志强(1982-),男,博士,高级工程师。研究方向:模式识别等。
10.16180/j.cnki.issn1007-7820.2017.01.012
TN957.52
A
1007-7820(2017)01-041-05
猜你喜欢
电脑爱好者(2020年18期)2020-09-26
青年歌声(2019年12期)2019-12-17
制造技术与机床(2019年6期)2019-06-25
北京航空航天大学学报(2017年7期)2017-11-24
电脑爱好者(2017年9期)2017-06-01
北京航空航天大学学报(2016年6期)2016-11-16
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
舰船科学技术(2015年8期)2015-02-27
读写算·高年级(2009年3期)2009-11-16
