
车载通信中基于Q学习的信道接入技术研究
2017-03-29 04:52杜艾芊赵海涛刘南杰
计算机技术与发展 2017年3期
杜艾芊,赵海涛,刘南杰
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 网络基因工程研究所,江苏 南京 210003)
车载通信中基于Q学习的信道接入技术研究
杜艾芊1,2,赵海涛1,2,刘南杰1,2
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 网络基因工程研究所,江苏 南京 210003)
针对基于IEEE 802.11p协议的车载网络MAC层DCF(分布式协调功能)信道接入方法存在数据包接收率低、时延高、可扩展性差等问题,提出一种基于Q学习的CW动态调整算法-QL-CWmin算法。区别于现有的BEB算法,通过利用Q学习,网络节点(Agent)能够不断地与周围环境进行交互学习,根据学习结果动态地调整竞争窗口(CW),使节点总能以最佳的CW(从周围环境中获得奖赏值最大时所选的CW大小)接入信道,以减少数据帧碰撞、降低端到端传输时延。仿真结果表明,采用QL-CWmin算法的通信节点能快速适应车联网的未知环境,数据包接收率和数据包传输时延得到了有效改善,同时该算法能为节点接入信道提供更高的公平性,适用于各种不同负载程度的网络环境。
车载网络;BEB算法;竞争窗口;Q学习算法;分布式协调功能
0 引 言
近年来,随着交通运输行业的迅速发展,汽车数量急剧增加。汽车为人们日常出行带来了便利,但也出现了安全和交通拥堵等各种问题。20世纪80年代,美国加利福尼亚大学首次提出了智能交通系统(ITS)的概念,用以提高交通运输效率、缓解交通拥塞、减少交通事故。在智能交通系统和无线通信技术高速发展的今天,车联网应运而生,它是继互联网、物联网之后的另一个未来智慧城市的标志。车联网中,道路车辆和路边基础设施都安装有短程无线收发器,具有无线通信功能,所以可形成一个无线网络,即车载自组织网(VANET)。VANET是移动自组织网的子类,没有固定的拓扑结构,车辆可通过V2V(车与车)通信或V2I(车与路边基础设施)通信获取信息和服务。VANET通过车-车通信和车-路通信实现人-车-路的协同,有效改善了交通安全,提高了交通效率,为用户提供娱乐和Internet接入服务等。
IEEE802.11p又称WAVE(WirelessAccessintheVehicularEnvironment),主要用于车载通信,是由IEEE802.11标准扩充的通信协议。IEEE802.11p针对车载环境对IEEE802.11的物理层和MAC层的相关参数做了些许调整,因而能更适用于车载环境中的无线通信。IEEE802.11p是WAVE协议栈的底层协议,已广泛应用于V2V通信。在任一网络环境中,通信协议栈的重要因素之一就是MAC层,而IEEE802.11pMAC层主要解决的是车辆对信道接入的竞争问题,它决定了某一时刻允许哪一节点接入无线信道。由于节点的高速移动性、通信环境的快速变化性及节点密度和节点分布的多变性等,对VANETs共享无线信道的接入控制提出了挑战。因此,设计高可靠性的MAC协议对VANETs尤为重要。为VANET环境设计MAC协议所面临的挑战主要有:在车辆位置和信道特征不断变化的VANET中,实现既高效又公平的信道接入;对不同密度的交通流具有可扩展性;能满足各种不同的应用需求。
1 相关文献
文献[1]提出一种基于邻居节点数估计的最小竞争窗口调整算法-AdaptiveCWmin。算法改变了CW的调整规则,并根据网络信道的使用情况动态地调整CWmin。通过估计车载网中的竞争节点数来动态地选择合适的CWmin,若数据传输成功,则根据竞争节点数确定CWmin;若失败,则通过估计车辆密度来控制竞争窗口的增加。同时还推导出最大退避阶数、信道由于碰撞被检测为繁忙的平均时间和竞争节点数这三个参数与最优CWmin的函数关系,节点成功发送数据后,根据函数计算出适应车载网络状况的最优CWmin值。利用文中提出的算法在数据包重传之后选择合理的CW,缩短了竞争节点等待重传的时间,增加了网络吞吐量。
文献[2]提出了基于统计次数的退避算法-newBEB和基于相对距离的退避算法-RBA。newBEB算法中设定了一个门限值,即发送节点传输成功和传输失败的最大次数。当节点连续发送成功的次数超过传输成功的最大次数时,就增加竞争窗口值,降低其竞争信道的能力;而当节点连续发送失败的次数超过传输失败的最大次数时,就减少竞争窗口值,增强其竞争信道的能力。通过仿真对比分析,newBEB算法有效提高了节点接入信道的公平性。RBA算法中,每个节点根据自己与邻居节点距离的平均值动态地调整竞争窗口的大小,仿真结果表明RBA算法提高了节点接入信道的公平性,降低了丢包率,在一定程度上提高了网络吞吐量。
文献[3]提出一种CW的控制方法-DBM-ACW方法(基于密度调整CW的方法)。根据信道拥塞的严重程度,选择不同的CW值倍乘系数,或重设为CWmin。信道十分拥塞时,CW值的倍乘系数选择上限值,可减少节点选择相同退避数的概率;当信道密度降低时,CW值的倍乘系数选择下限值或重设为CWmin,避免节点在信道占用率较低时等待较长的时间接入信道。经仿真对比分析,文中提出方法在网络密度较大时,性能优势尤为突出。
文献[4]提出一种基于距离动态调整CW值的方法,适用于在网络负载较重的车载自组织网中广播实时性紧急消息。文中推导出某节点和前一节点之间的距离d和动态竞争窗口CWd之间的关系,利用这一关系为不断移动的车辆节点动态地分配不同的CW值,可减少由于碰撞需要重传数据包的次数。此外,还能降低数据包碰撞概率、端到端时延及网络负载等,最终使带宽得到有效利用。仿真结果表明,此方法在高速公路交通流中就吞吐量、端到端时延和网络负载而言,网络性能得到有效改善。
传统的退避算法虽然解决了信道竞争的问题,但同时也存在一定的缺陷。节点每成功发送一次数据,就把当前的CW降到最小值,使节点误以为一次发送成功就表示当前信道竞争情况不激烈,同样,一次发送失败就认为当前信道竞争激烈,碰撞增加,相应的竞争窗口成倍增加[5]。这种方式并没有真正反映信道上的竞争情况。尤其是节点个数较多网络负载变严重时,成功发送完数据的节点把CW调为最小值,多个节点又有相同的CW值(CWmin),会引起更多的碰撞。且碰撞和退避会浪费时间,严重影响网络的整体吞吐量。另外,数据发送成功的节点立刻将CW值置为最小,而数据发送失败的节点的CW值成倍增加。之后的一段时间内,CW值小的节点再次成功接入信道的概率增加,而CW值大的节点CW值会继续增加,若CW值小的节点连续发送数据的话,就会一直占用信道,而其他节点的数据就无法发送出去,最终造成严重的信道接入不公平现象。除了接入信道不公平的问题,在时延方面也存在一定的缺陷。IEEE802.11p在MAC层中规定,初始竞争窗口值为15(aCWmin)[6]。但是,数据流量负载过高(网络密度较高)时,成功发送数据帧后恢复为初始竞争窗口会使碰撞率增加,若节点在预定义时间段内无法成功发送数据帧对应的ACK消息,发送节点就会增加竞争窗口,重传数据帧,这样会使时延增加。即使在初次尝试发送数据时设定最佳的竞争窗口可避免增加时延,但节点成功发送数据后,竞争窗口又恢复为15,尤其是在网络负载过高时,极其不宜采用这种方法。
2 基于Q学习的CW动态调整算法
针对上述问题,文中在传统信道接入机制的基础上,引入强化学习,基于强化学习中的Q-Learning算法提出了新的信道接入方法-QL-CWmin方法。
2.1Q学习的基本原理
强化学习是机器学习中尤为重要的一种,它是智能系统从环境状态到行为映射的学习过程,是解决智能系统寻优问题的有效工具。能够感知环境的Agent不断在环境中学习,根据环境给予的反馈信号,总选择执行能达到目标的最优动作。在强化学习中,Agent在环境中的学习过程是一种试探评价过程,它的基本原理是[7]:Agent在环境中学习时,选择一个动作作用于环境,环境状态受该动作影响而发生变化,同时会产生一个强化信号(奖或惩),并将此信号反馈给Agent,Agent会根据强化信号和环境的当前状态再选择执行下一个动作,如果Agent的某一动作策略会使Agent从环境中获得正的奖赏(强化信号),那么Agent此后选择执行这个动作策略的趋势就会加强,它的最终目的是Agent总选择执行能从环境中得到最大累积奖赏值的动作。
Q-Learning算法是强化学习算法中最典型的一种,也是目前应用最为广泛的一种。Q-Learning算法在环境条件未知的情况下最为有效,对环境的先验知识要求不高,它使Agent在马尔可夫决策过程中具备利用经历过的动作序列总选择最优动作的能力。它不需要环境模型,Agent在动态环境中通过交互试错不断调整行为。Agent不断探索环境,在每一环境状态和可能的动作之间建立一个Q值列表(Q表),它学习的是每个状态-动作对的评价值-Q值(Q(st,at)),Q(st,at)是Agent在状态st下根据策略选择执行动作at,并循环执行所得到的累积奖赏值。Q-Learning算法的最优策略是使Q(st,at)的累积奖赏值最大化,所以Q学习的最优策略表达式为[8]:
(1)
即Agent只需考虑当前状态和当前可选的动作,按照策略选择执行使Q(st,at)最大化的动作。
文中所提出的信道接入方法-QL-CWmin,通过动态调整竞争窗口来解决碰撞率和时延的问题,利用Q-Learning算法学习最佳的竞争窗口。由于邻近节点之间互换信标消息可获得邻居节点的位置信息,所以假设每个节点已知其一跳邻居节点的位置信息,在节点成功发送数据帧后,环境给予节点一个正的奖赏,若发送失败,则给予负的奖赏。在网络负载较低时,使节点利用学习所得的最佳CW选择以较小的CW接入信道避免增加时延;网络负载较高时,则利用较大的CW接入信道防止碰撞。QL-CWmin算法可动态地调整竞争窗口,能以较低的时延发送数据,提高了数据包接收率和竞争效率,减少了信道接入时延。
2.2 QL-CWmin算法的状态-动作对映射
整个车载自组织网络即Agent学习的环境,网络中的每个车辆节点即Agent,车辆节点在网络中接入信道时所采用的竞争窗口即Agent学习环境的环境状态,由此车辆节点可能采用的所有竞争窗口集即Agent学习环境的状态空间。由于节点在网络中接入信道的竞争窗口通常为2的指数幂减1,因此竞争窗口集为{15,31,63,127,255,511,1 023},竞争窗口初始值CWmin为15,最大值CWmax为1 023[9]。每一Agent可执行的动作有:增加(I)、保持(K)、减少(R)。“增加”即增大竞争窗口,“保持”和“减少”则分别是保持竞争窗口大小不变和减小竞争窗口。节点每执行一个动作后,环境状态就发生状态转移。在网络环境中不断探索学习的过程中,每一节点在状态-动作对之间都维护一个Q表,Q表中包含Q值Q(st,at),Q值的变化范围为-1到1。其中,st为当前竞争窗口的大小,at为节点可能执行的动作。每发送完一个MAC帧后,节点根据发送状态从网络环境中获得一个奖赏值。若发送成功,节点得到一个正的奖赏,若发送失败(本协议中定义MAC层重传次数不超过4,即数据重传4次后,发送节点还是接收不到数据帧对应的ACK消息,则定义此次发送失败),节点则得到一个负的奖赏。丢包主要是由于其他数据包发生碰撞造成的,通过对奖赏值进行评估,节点自适应地调整其竞争窗口大小,总选择执行能使累积奖赏值Q值最大化的最优动作。
2.3 QL-CWmin算法Q值函数更新
在Agent与环境不断交互学习的过程中,节点接入信道可能执行的动作有:增加(I)、保持(K)、减少(R)。状态空间为{15,31,63,127,255,511,1 023}。当竞争窗口为最小值时,竞争窗口无法继续减少;同样地,当竞争窗口为最大值时,竞争窗口无法继续增加[10]。图1为节点在网络环境中学习的状态转移图。
VANETs中,节点采用QL-CWmin算法发送MAC数据帧的过程中,利用状态-动作对的值函数Q(st,at)进行迭代,并利用奖赏作为估计函数来选择下一动作,对Q函数进行优化,通过多步迭代学习逼近最优值函数。节点每发送一次数据帧,就更新一次Q表,更新Q值的表达式即Q学习的迭代公式为:

图1 状态转移图
α)×Q(st,at)
(2)
其中,α为学习率,是Agent在环境中的学习步长,用于控制学习速度。α值越大,Q值收敛越快。由于MAC数据帧发送较为频繁,0.6足以反映网络拓扑的变化程度,所以文中取α为0.6。γ为折扣因子,γ∈[0,1],体现了Agent对以后环境所给予奖励的重视程度,取值越大表示越重视以后的奖励,反之,则只在乎眼前的奖励。文中取γ为0.9。
车辆节点在VANETs中初次接入信道发送数据时,会首先初始化Q(st,at)的值,然后根据探索策略在状态st时选择执行动作at,得到下一状态st+1及其奖赏值R,之后根据奖赏值通过式(2)更新Q值,一直循环执行直到实现目标状态或达到限制的迭代次数。其中奖赏值R计算如下:
(3)
其中,RCW表示选择当前的CW值接入信道成功发送数据所获得的正奖赏。发送失败,奖赏值为-1,若当前状态正在发送数据,奖赏值为0。
表1中定义了选择各不同大小的CW值成功发送数据所获得的不同奖赏值。成功发送数据所选的CW值越小,得到的奖赏值就越大,而网络负载过高时,节点从环境中获得负的奖赏从而增加竞争窗口,这样能使节点充分利用信道资源。
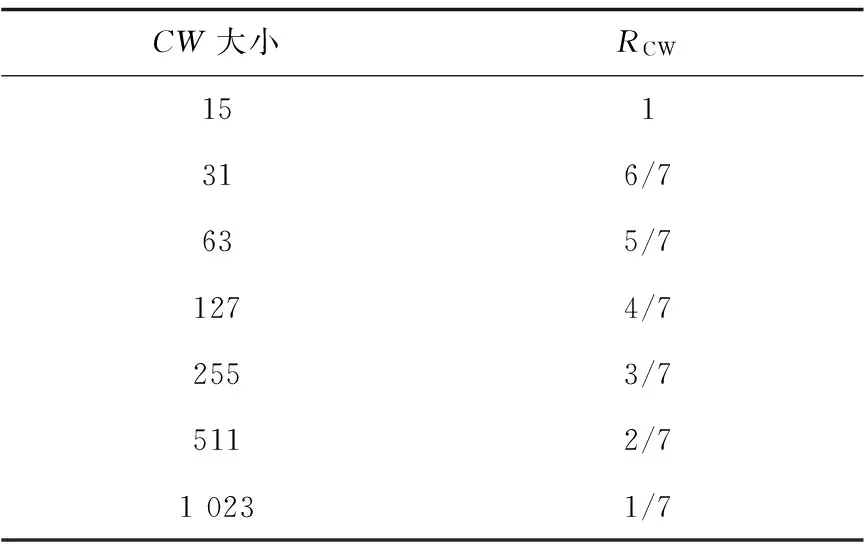
表1 不同CW对应的奖赏值
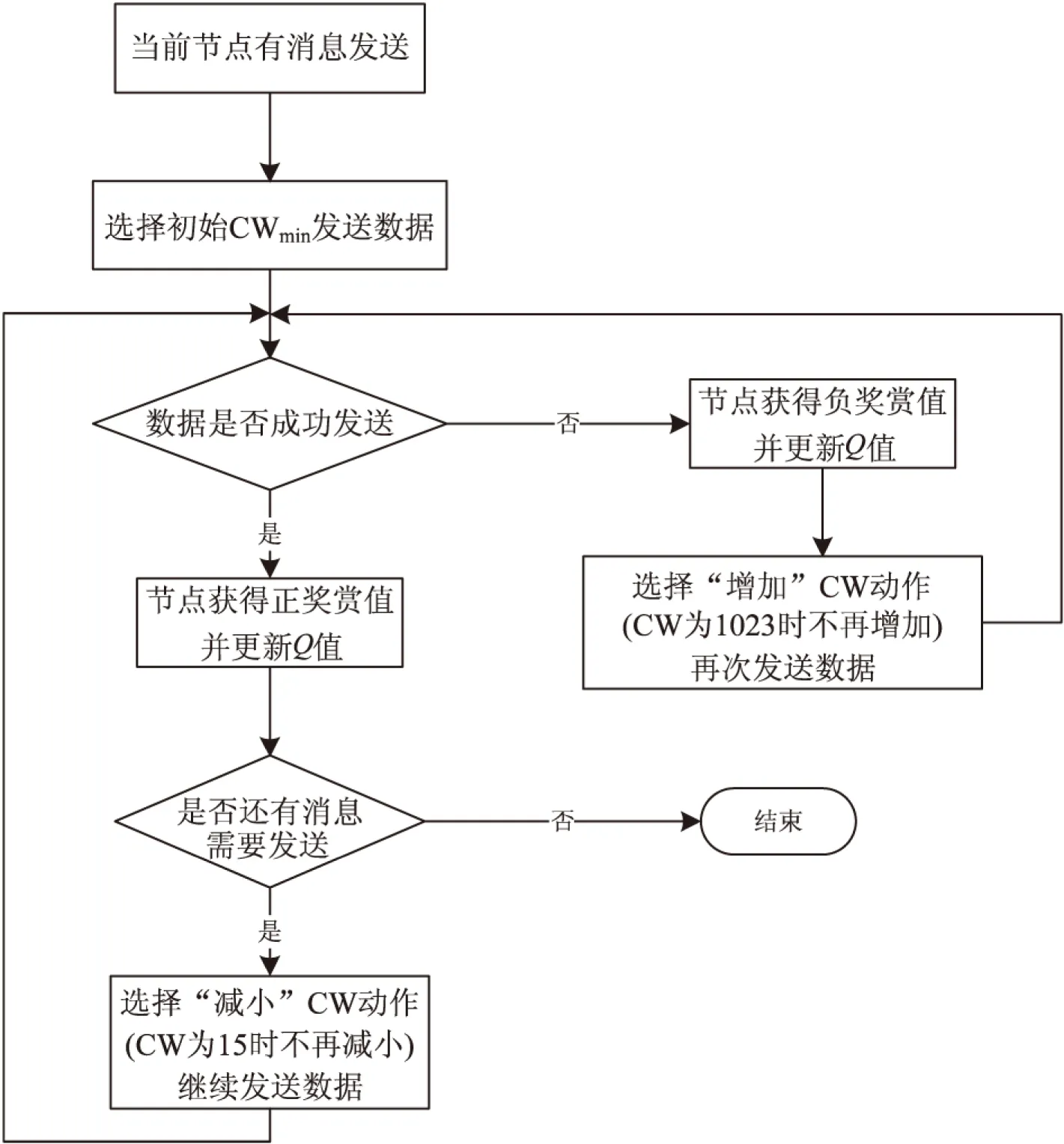
图2 基本流程图
2.4 QL-CWmin算法的收敛性
强化学习中,“探索”是指Agent要尽可能地经历所有的状态-动作对,从而获得全面充分的经验知识,保证学习过程能收敛到最优的Q值函数,但是过度“探索”会引入冗余信息,浪费存储资源和计算资源,最终影响学习速度。“利用”则是Agent为了从环境中获得较高的奖赏值,总是根据当前的Q表选择执行可以获得高奖赏值的动作,而不愿冒险去尝试可能会产生更高奖赏值但也可能产生低奖赏值的动作[12]。所以寻求“探索”和“利用”间的平衡对保证学习过程能快速收敛到最优Q值函数非常重要,Agent需要不断“探索”次优动作从而使“利用”趋向全局最优。
QL-CWmin算法中,节点在网络环境中学习所用的探索策略为强化学习算法中应用较为广泛ε-greedy动作选取机制,每个Agent节点要执行的第一个动作是将其CW值初始化为15,当Agent对自己所处的网络环境一无所知时,采用最小的CW值是最佳选择。此后节点以概率ε进行探索,寻求新的可能会产生更高奖赏值但也可能产生低奖赏值的动作,以概率1-ε选择当前Q值最高的动作(利用)。由于节点接入信道并成功发送数据所选用的CW越小,Agent得到的奖赏就越多,只要当前所选的CW能成功发送数据,节点就绝不会再增加CW。当CW大于15,而网络负载降低时,QL-CWmin算法也会通过探索将CW重设为15,即QL-CWmin算法总能使节点在网络环境中通过“探索”和“利用”将CW调整为最佳值。
收敛问题也是强化学习算法所研究的一个重要问题[13],Watkins与Dayan利用随机过程和不动点理论给出:
(1)学习过程具有Markov性;
(2)所有的状态-动作对能被无限次访问;
(3)Q表中能存储所有状态-动作对的Q值函数,每个元素分别对应于一个状态-动作对;
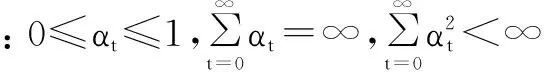
以上四个条件都满足时,Q学习过程可收敛到最优状态-动作对值函数Q*。由此可见,QL-CWmin满足收敛的所有条件。
3 仿真结果
文中对高速公路场景进行仿真,仿真环境如表2所示。

表2 仿真参数
文中通过仿真从VANET的广播帧接收率、端到端传输时延和数据帧碰撞率等方面对CWmin-15算法、CWmin-31算法、AdaptiveCWmin算法和提出的QL-CWmin算法进行了对比分析。
图3分别为VANET中采用四种退避算法的广播帧接收率随车辆密度的变化趋势。
从图中可以看出,车辆密度较小时,由于车辆节点总会以最小的竞争窗口接入信道,且数据帧发生碰撞的概率很小,所以广播帧接收率都较接近1。但随着车辆密度的增加,广播帧接收率都呈下降趋势,而采用文中所提出的QL-CWmin算法的广播帧接收率不仅优于其他算法,且下降趋势较为平稳。因为车辆节点在VANET环境中不断交互试错,总选择Q值最高的竞争窗口即最佳窗口接入信道,所以其广播帧接收率不会随着车辆密度的增加而呈急剧下降的趋势。
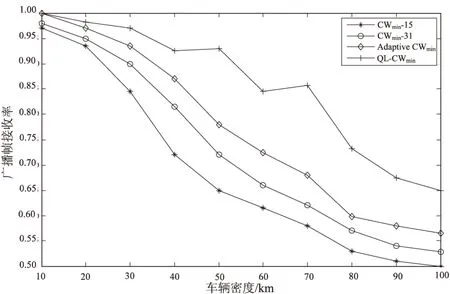
图3 广播帧接收率与车辆密度的关系曲线
图4和图5分别是采用四种退避算法后VANET中的端到端传输时延和数据帧碰撞率随车辆密度的变化趋势。
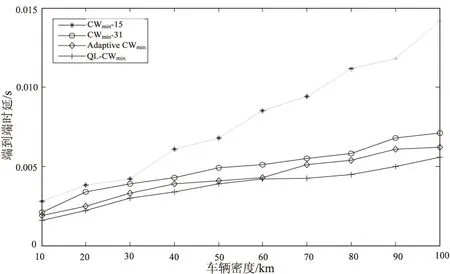
图4 端到端时延与车辆密度的关系曲线
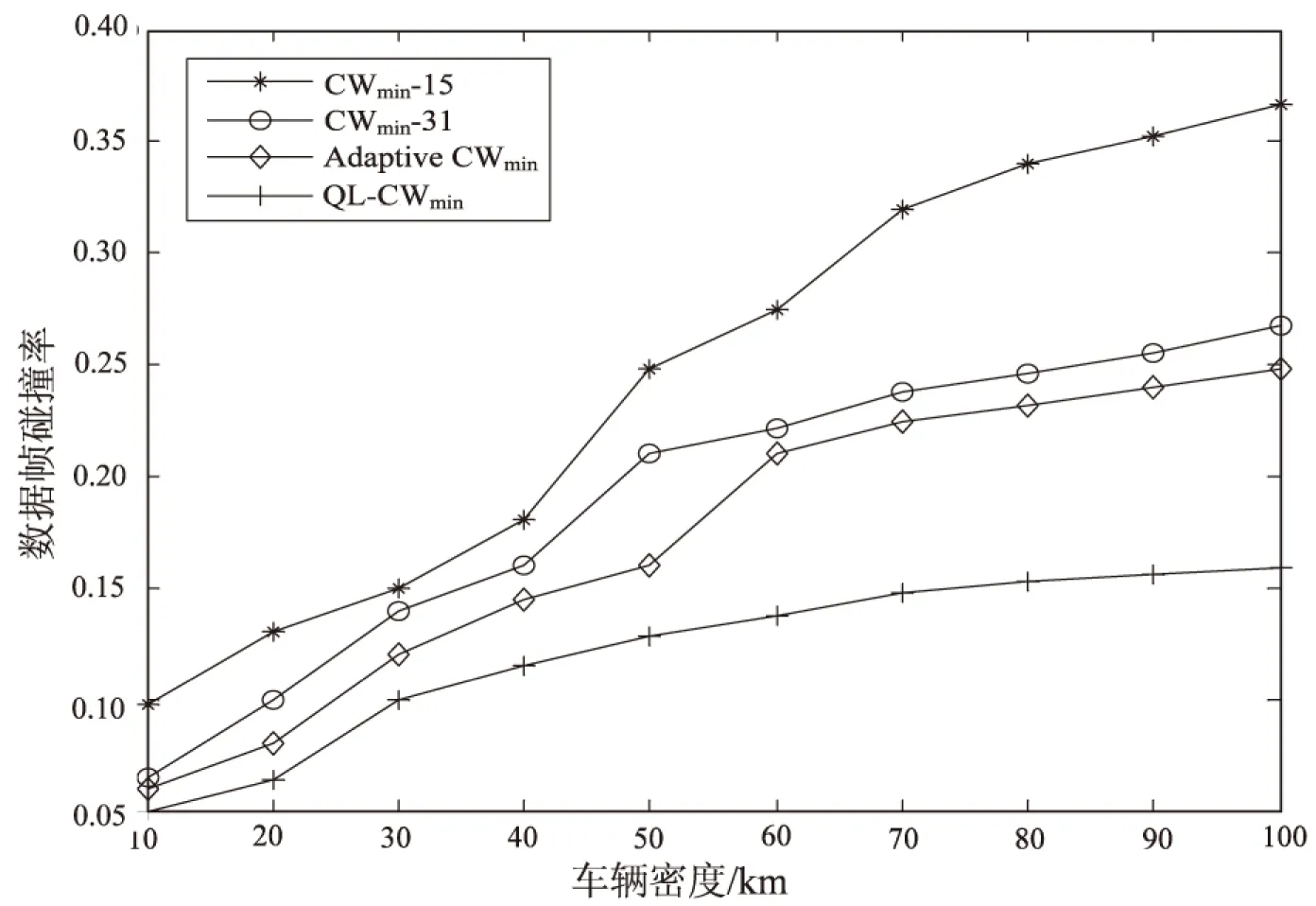
图5 数据帧碰撞率与车辆密度的关系曲线
从图中可见,文中提出的QL-CWmin算法与其他三种退避算法相比,端到端传输时延和数据帧碰撞率都较小,因此采用QL-CWmin算法能为节点接入信道提供更高的公平性,从而能适用于各种不同负载程度的车载网络。
总的来说,在节点接入信道发送数据发生碰撞需要进行退避的过程中,车辆节点利用Q学习算法与周围环境不断交互,根据网络环境反馈的奖赏信号,动态地调整竞争窗口,使节点下次发送数据时总能以最佳的CW值接入信道,提高了数据成功发送的概率,减少了退避次数。就数据包接收率及端到端传输时延,QL-CWmin算法性能与其他传统的退避算法相比都得到有效改善,尤其是QL-CWmin算法完全不同于以往传统的退避算法[14]在节点成功发送完数据后就将CW值恢复为15,从不考虑网络负载情况,而是使节点能经历所有的状态-动作对,根据奖赏值总以较大的概率选择能成功发送数据且能获得较高奖赏值的CW。因此,QL-CWmin算法显著提高了节点接入信道的公平性,且还能适用于不同负载程度的网络环境。
4 结束语
文中将强化学习中的Q学习算法引入到VANETsMAC层中,详细设计了车辆节点与车载网络环境交互学习时所处的状态和可执行的动作,以及状态-动作对的映射关系和动作策略,提出了QL-CWmin退避算法,并通过仿真对该算法和现有的其他退避算法进行了对比分析。QL-CWmin算法就广播帧接收率、端到端时延、数据帧碰撞率、节点公平性及可扩展性而言,性能得到显著改善。在ε-greedy动作选取机制中ε值固定的情况下,节点在环境中探索新动作时,选择执行各个动作的概率一样,这样选择最坏动作的概率也很大。后续研究中,为了有效地平衡“探索”和“利用”,将会尝试动态调整ε值,当前Q值最高的动作赋予最高的概率,而探索的新动作要根据其奖赏值大小赋予不同的概率,从而使研究结果更精确,考虑因素更全面。另外,已提出的基于Q学习的信道接入退避方法是针对单智能体的学习过程的,单智能体的学习方法存在一些问题。例如,智能体对环境仅部分感知、学习搜索空间太大、学习效率低等。因此,针对这些问题,将进一步研究基于多智能体Q学习的接入信道退避方法,有效改善节点接入信道的各方面性能。
[1]ReindersR,EenennaamM,KaragiannisG,etal.ContentionwindowanalysisforbeaconinginVANETs[C]//2011 7thinternationalwirelesscommunicationsandmobilecomputingconference.[s.l.]:[s.n.],2011:1481-1487.
[2]AlasmaryW,ZhuangW.MobilityimpactinIEEE802.11pinfrastructurelessvehicularnetworks[J].AdHocNetworks,2012,10(2):222-230.
[3]BaladorA,CalafateCT,CanoJC,etal.Reducingchannelcontentioninvehicularenvironmentsthroughanadaptivecontentionwindowsolution[J].WirelessDays,2013,30(12):1-4.
[4]LeeGil-Won,AhnSeung-Pyo,KimDong-Seong.ContentionwindowallocationschemeforV2V[C]//2013internationalconferenceonadvancedtechnologiesforcommunications.[s.l.]:[s.n.],2013:501-505.
[5]BooysenMJ,ZeadallyS,vanRooyenGJ.Surveyofmediaaccesscontrolprotocolsforvehicularadhocnetworks[J].IETCommunications,2011,5(11):1619-1631.
[6]ShiC,DaiX,LiangP,etal.Adaptiveaccessmechanismwithoptimalcontentionwindowbasedonnodenumberestimationusingmultiplethresholds[J].IEEETransactionsonWirelessCommunications,2012,11(11):2046-2055.
[7]LamptonA,ValasekJ.Multiresolutionstate-spacediscretizationmethodforQ-Learning[C]//Americancontrolconference.[s.l.]:[s.n.],2009:10-12.
[8] 赵 昀,陈庆伟,胡维礼.一种基于信息熵的强化学习算法[J].系统工程与电子技术,2010,32(5):1043-1046.
[9]WangQ,LengS,FuH,etal.AnIEEE802.11p-basedmultichannelMACschemewithchannelcoordinationforvehicularadhocnetworks[J].IEEETransactionsonIntelligentTransportationSystem,2012,13(2):449-458.
[10] 魏李琦,肖晓强,陈颖文,等.基于相对速度的802.11p车载网络自适应退避算法[J].计算机应用研究,2011,28(10):3878-3880.
[11] 杜春侠,高 云,张 文.多智能体系统中具有先验知识的Q学习算法[J].清华大学学报:自然科学版,2005,45(7):981-984.
[12] 陈学松,杨宜民.强化学习研究综述[J].计算机应用研究,2010,27(8):2834-2838.
[13] 黄玉清,王英伦.支持服务区分的多智能体Q学习MAC算法[J].计算机工程,2013,39(8):112-116.
[14]vanEenennaamM,RemkeA,HeijenkG.AnanalyticalmodelforbeaconinginVANETs[C]//Vehicularnetworkingconference.[s.l.]:IEEE,2012:9-16.
Research on Technology of Channel Access Based onQ-Learning Algorithm for Vehicular Communication
DU Ai-qian1,2,ZHAO Hai-tao1,2,LIU Nan-jie1,2
(1.College of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.Institute of Network DNA Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
AQ-Learningbasedback-offalgorithmisproposedbecausethetraditionalDCFapproachusedforIEEE802.11pMACprotocoltoaccessthechannelhassomeproblemsofthelowpacketdeliveryrate,highdelayandthepoorscalabilityinVANETs.Theproposedalgorithm,whichisquitedifferentfromthetraditionalBEBalgorithm,isadoptedbythenodes(Agents)tointeractwithsurroundingscontinuouslyandlearnfromeachother.ThevehiclenodesadjustthesizeofCW(ContentionWindow)dynamicallyaccordingtotheresultslearnedfromthesurroundingssothatthenodescanaccessthechannelwiththeoptimalCWeventuallyminimizingthepacketcollisionsandend-to-enddelay.Thesimulationresultsshowthatthecommunicationnodesusingtheproposedalgorithmcanadapttotheunknownvehicularenvironmentrapidly,andsimultaneouslythehighpacketdeliveryratio,lowend-to-enddelayandhighfairnesscanbeachievedforvehicularnetworkwithvariouslevelload.
vehicular network;BEB algorithm;contention window;Q-Learningalgorithm;DCF
2016-03-29
2016-08-02
时间:2017-01-10
国家“973”重点基础研究发展计划项目(2013CB329005);国家自然科学基金资助项目(61302100,61101105,61201162);江苏省基础研究计划-重点研究专项基金(BK2011027,BK2012434);江苏省高校自然科学研究基金(12KJB510022,12KJB510020)
杜艾芊(1991-),女,硕士研究生,研究方向为移动通信与无线技术、车联网车载通信;赵海涛,博士,副教授,研究方向为无线多媒体通信;刘南杰,博士,教授,研究方向为泛在通信、车联网、智能交通。
http://www.cnki.net/kcms/detail/61.1450.TP.20170110.1019.044.html
TP
A
1673-629X(2017)03-0085-06
10.3969/j.issn.1673-629X.2017.03.018
猜你喜欢
电脑知识与技术(2021年22期)2021-09-14
火控雷达技术(2021年2期)2021-07-21
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
雷达与对抗(2018年3期)2018-10-12
宇航计测技术(2018年3期)2018-09-08
北京航空航天大学学报(2017年3期)2017-11-23
现代企业文化·综合版(2017年5期)2017-06-14
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
人生十六七(2015年26期)2015-08-22
