
基于聚类的中医临床术语语义关系的研究*
2017-03-27 08:05:41刘亮亮张晓如曹馨宇
世界科学技术-中医药现代化 2017年12期
陈 璟,刘亮亮,张晓如,曹馨宇
(1.江苏科技大学计算机学院 镇江 212000;2.上海对外经贸大学统计与信息学院 上海201620;3.中国中医科学院中医临床基础医学研究所 北京 100190)
1 引言
对于拥有悠久历史的中医文化,如何有效的与现代学科结合并促进发展是近年来备受关注的一项研究。中医临床知识的研究是中医学信息化研究中的一个重要课题,其中又可分为对中医临床术语实体的研究和中医临床语义关系的研究。语义类型是语义网中的重要节点,也是语义网的重要部分[1]。一个完整,准确的语言系统能有效解决中医学领域中存在的词义模糊,一词多义等复杂的语言现象,可以解决长期困扰中医学信息化信息检索效率低等问题[2]。
2 相关工作
中医临床术语的规范化工作自2005年开始[3],通过借鉴了SNOMED CT,搭建了“中医临床标准术语集”,奠定了研究基础,并在接下来的持续研究中,对术语的内容和分类框架进行了完善和补充,获取了其他研究成果[4,5]。
在语义关系的研究上,中医科学院已构建了“中医药学语言系统”(TCMLS)[6],形成了 58 条语义关系[7,8],其中包括UMLS原有的54条语义关系,并补充4条具有中医特色的语义关系。但是,目前TCMLS的语义关系网还存在许多发展不够完善的地方。如贾李蓉等[1]对 TCMLS中语义类型的使用情况进行分析,找出不合理的语义类型并建议删去。杨阳[9]在研究中医临床术语之间的语义关系时,为了完善现有的语义关系体系,提出了三种新的具有中医特色的语义关系,分别是“感受……之邪”,“侵袭”,“对……的功效”,虽然未加入到TCMLS系统中,但是为中医临床语义关系的研究提供的参考。李莎莎[10]指出TCMLS分类框架存在问题,提出了分类指导原则以及改进的分类框架,使TCMLS词库分类更加合理。
TCMLS沿用了西医语言系统中的语义框架,虽然中医和西医拥有相近的学科属性,却是不同的理论体系和实践,中医具有自己独特的文化底蕴和医疗手段,虽然新增了四条具有中医特色的语义关系,但是在表达临床语义关系存在着自身的局限性[11]。比如语义关系定义存在交叉,定义的模糊等问题,因此中医临床语义关系的研究有待进一步深入。
本文尝试利用机器学习和基于模式结合的方法,以生成句法模式为特征,利用聚类方法对中医临床概念实体之间的语义关系辨清语义关系类型。基于语料库,通过对术语相似性的分析和聚类方法,总结相关的表达语义关系的模式,针对获取的语义关系,对语义关系重新进行划分,形成新的语义关系分类。
3 方法
3.1 基本概念
本文基于已有的中医临床语义关系实例,通过机器学习与模板结合的方法,自动对关系实例进行聚类,对语义关系进行深入的分析研究。
研究中所使用的句法模式是指:能表达出语义关系的有序的词序列,简称句式,表示为synst=[unit1]…[uniti],其中的[uniti]表示句式的一个单元。句式之中的每个单元不要求接连出现,但是在出现顺序要一致。我们假定蕴含同样语义关系的语句具有同样的表达方式,即表示同样语义关系的语句具有同样的句式。从具有同一种语义关系和同一种表达方式的语句中,可以提取两个句子的最长公共子序列,即为初始句式。比如,“燕口疮是因心脾积热,或虚火上炎所致”和“转胞多因肾虚或气虚,胎气下坠,压迫膀胱,水道不利所致”提取出的最长公共子序列是“[因][所致]”,也就是初始句式。根据句式所表示的语义含义,基于同义词对初始句式进行扩充,使其可以覆盖更多的语句。如可将“[因][所致]”扩充为“[因/由][所致]”,以适用于更多的语句。
3.2 总体方法
本文为了便于针对中医临床语义关系的研究,根据多种百科结合的方法[12]建立适用于语义关系研究的中医临床语义关系语料库。该语料库的特点是,已知语料中的中医临床术语实体,在不需要考虑命名实体识别的基础上专注于语义关系,并且获取的句子具有完整语法结构、适合语义关系的分析。
本文的方法总体上分为以下几个步骤:
(1)特征词聚类:对语料库Corpus中每一条语句sen(sen∈Corpus),分别选取该句中的概念实体ex,ey附近三个词距的动词,名词,连词,介词作为特征词chars,使用Kmeans算法进行聚类。
(2)合成句法模式:在第一轮聚类的基础上,在同一簇里,以某两条语句的最长公共子序列作为初始句式,并利用同一簇中的其它语句对初始句式进行扩充。
(3)句式聚类:以句式为特征进行第二轮聚类。
3.3 具体步骤
3.3.1 语料库处理
对语料库Corpus中每一条语句sen,替换其中的临床概念实体ex,ey为X,Y,为防止概念被分词误分开,记录实体在语句中的位置loc(X)和loc(Y)。本文使用中科院的NLPIR(原名ICTCLAS)对语料进行分词,得到语句的分词结果sen=w1…wj。
3.3.2 特征词聚类
基于语料库中每条语句的分词结果,建立该句的特征词集chars。如果wi(i∈[0,j])可以满足式(1),则将wi加入特征词集chars中。wi(i∈[0,j])为一句语料中的一个词,其词性表示为pos(wi),在句子中所在位置表示为loc(wi)。
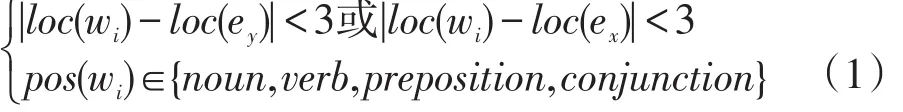
处理计算完每一句语料的特征词集chars之后,使用TF-IDF算法,将特征词转化为特征向量,并使用Kmeans的聚类算法对语料实施聚类,得到第一轮聚类结果。
3.3.3 合成句式模式
根据第一轮聚类产生的N个簇clusteri(i∈[1,N]),N值取越大,簇数越多,聚类的结果会越精细,更适合产生初始句式;但是当N值过于大时,则聚类结果信息颗粒会太过细腻,难以抽象。根据多次测试,令N=50时,可以取得较为适中的结果。
在clusteri(i∈[1,N])中的语句过多时,计算任意两条语句的初始句式会导致计算时间过长,且会产生大量不符合语言表达习惯的无用句式。故首先人工人工挑选出clusteri中具有相同语义关系表达模式的两句语句计算最长公共子序列,作为初始句式i_synst;然后求初始句式i_synst与clusteri中的其他语句的最长公共子序列,将与初始句式相似度高的用于扩充初始句式,相似度低的则滤过不用。方法如下:
Step1:对N个簇中的每个簇clusteri(i∈[1,N]),人工挑选出用于合成初始句式i_synst的语句sen1=w1…wm和 sen2=w1…wn。
Step2:对 sen1和sen2中的每一个词wi(i∈[1,m])和wj(l∈[1,n])建立二维矩阵 f[m+1,n+1],其求解公式为式(2):

其中max()为求最大值函数,same()的求解公式如式(3):

sim(wi,wj)为根据基于同义词词林的词语相似度计算方法[13],该方法计算的相似度满足具有较高相似度的词语在原句中进行替换后仍能表达原句的含义,为扩充句式垫下基础。
Step3:求出的数组f[m+1,n+1]中的最大值即为最长公共字串的长度,根据长度对数组回溯,求出最长公共子序列。由于sen1和sen2句子中都包括替换过实体ey的Y字符,所以最长公共子序列中长度最少为1。并且长度大于1的时候,回溯得到的子序列也必须包括Y字符,因此对数组f[m+1,n+1]回溯时,根据sen1和sen2中的Y点,将 f[m+1,n+1]以 f[loc(Y)1,loc(Y)2]点分为四个区间,然后对右下和左上求最长公共子序列并以Y点进行合并得到最终包含Y的最长公共子序列对应两个句子中的 loc1=[…,i,…]和 loc2=[…,j,…]序列。
Step4:通过Step2和Step3得到的两个句式的最长公共子序列lcs,将最长公共子序列中位置上对应原句的wi,wj进行合并,得到初始句式i_synst。
Step5:对clusteri中剩下的语句sen3的每一句跟初始句式i_synst重复Step2和Step3,得到的最长公共子序列的长度等于初始句式的长度len(lcs)=len(i_synst),则将sen3中对应的原词合并到i_synst中对应的单元上。
Step6:每一个通过人工挑选初始句式后并经过扩充的句式synst写入到输出结果文件内。

表1 原语义关系分布表
3.3.4 句式聚类
根据最终生成的所有句式,逐一对分词前的句子sen进行处理,将每个符合sen的synst加入到该句的句式集合synstSet中。如果一个句子的synstSet中只有一个句式则该句式作为此句的特征,若存在多个句式,则根据算法2的最近词优先原则挑选更能表达语义的最佳句式。算法2如下:
Step1:用分词前的原句sen,获取实体ey的替代字符Y的位置loc(Y)。
Step2:取出synstSet中的一个句式,计算synst中的每个单元在原句sen中的位置与loc(Y)的差值,并保存最小的的值min。
Step3:计算synstSet中所有句式的min值,并取min最小的句式作为最佳句式。
Step4:如果存在两个或多个min同样最小的句式,则取句式长度最长的作为最佳句式。
对所有语料标注好句式特征后,再次使用Kmeans算法进行第二次聚类,且该次聚类结果为最终聚类结果。
4 实验分析
4.1 实验结果
本文实验语料库共有425条语句,包含了11种常见的临床语义关系,每种语义关系的数量如下表1。
根据当前语料中表达的语义关系,人工对语义关系重新进行划分,形成新的语义关系分类。本文在重新划分语义关系是根据语料中表达出的临床术语实体之间的语义关系为准,使用句式作为中间传导工具,实现由语料到句式,从句式到语义关系的定义过程。根据本文提出的半监督的句式生成方式,从语料中获取句式,然后对句式进行人工的语义关系判断,手工聚合成一个语义关系类。并且在标注语料中语义关系含义时根据中医临床术语实体的类型(如:症状/体征,中医疾病,病原/病因诱因等)作为定义语义关系的参考条件。本文实验所进行的两轮聚类,分别利用特征词和句式作为特征,两轮的实验结果的准确率如表2。

表2 两轮聚类实验准确率

表3 新语义关系分类
聚类后得到的语义关系与原语义关系的映射关系如表3。
4.2 结果分析
本文的实验获取了较好的准确率,通过分析实验结果得知,导致没有正确聚类的原因有两种,第一种语料中没有匹配到已定义的句式,识别结果为“无类别”,这种类型的语料会作为一个独立的簇与其他簇分开,在语料的存在4%的语句,随着语料的扩充可能会增大这种类型的存在比例,同时也可以通过扩展定义更多句式来降低这个比例;第二种是根据一个语料匹配到的多个句式,采用的最近原则挑选的最佳句式所代表的语义不符合语料中的原语义,这部分所占比例为7.81%。
通过以上实验结果可以发现,使用句式作为特征能够比单使用语句中的词作为特征更具有区分度。本文使用的半自动半手工的方法提取句式,使自动获取的句式更加符合语料及日常用语习惯,利用最长公共子序列和词语相似度的方法来泛化句式获取更加通用的句式。进一步对方法进行改进,则需要让这个方案逐渐由半监督转为无监督的实现,在不降低准确度的情况下减少人工的参与度。此外,在挑选最优句式时使用的最近原则在一些句子成分较多的情况下会被影响导致误选,为了避免这些失误,可以考虑的改进方法有两种思路。第一种是定义更加复杂的挑选原则,比如句式中不同的词赋予不同的权重,挑选句式以权重为准。第二种则是对语料的进一步预处理,剔除一些修饰句子主干的无关语,避免在挑选时被影响。这个方法结合了句法模式和机器学习的特点,还具有更多的改进空间。
本文实验的目的是通过聚类实现关系实例的重新分类,重新分类后的语义关系体系与原来相比,最大的不同时根据语料中表达的语义来定义语义关系,摆脱了西方语义体系框架的限制,更加符合中医学领域中语义关系的表达。与此同时,由于语料库收集的语义类型的限制,本文整理的是中医临床语义关系的常用语义,对语义关系的分类更多的是粗化语义信息颗粒,存在的两个缺点是,一是对当前语义关系的覆盖不够全面,不能成为整体语义关系框架的指导;二是分类较为粗滤,没有进一步的细化分类框架。所以还需要进一步根据这两个不足进行下一步研究。
5 结束语
在中医临床领域中,对于现有的语义关系存在的定义模糊,存在交叉等问题,还需要进一步研究和讨论。沿用西方的语义框架虽然加速了中医学信息化的建设,但是同时也埋下了根基不牢的隐患,需要对现有的语义体系根据中医领域的具体情况做调整。本文根据语料中抽取日常常用句式,根据句式所传达的语义关系为基础,对语义关系进行了重新划分,尝试建立更符合中医特点的语义分类体系。本文通过使用机器学习和句法模式结合的方法,使用常用的特征词进行第一轮聚类,在其基础上使用半监督的方法生成句式,然后重新计算语料符合的各种句式,并自动选择最能表达语料语义关系的最佳句式,以此为特征进行第二轮聚类。通过聚类的方法粗化信息所含的粒度,以语料中所表达的实际语义为准,重新划分定义了新的语义关系,并且实现了在新语义关系的下识别语义关系的准确率达到88.23%。
1 贾李蓉,董燕,田野,等.中医药学语言系统中的语义类型分析.世界中医药,2013,8(5):563-565.
2 于彤,贾李蓉,刘静,等.中医药学语言系统研究综述.中国中医药图书情报杂志,2015,39(6):56-60.
3 杨阳,崔蒙.中医临床标准术语集的研究概况.首届中医药信息发展大会.2006.
4 董燕,朱玲,于彤,等.中医临床术语研究现状与系统构建方法探讨.国际中医中药杂志,2014,(11):965-968.
5 周霞继,谢琪,刘保延,等.中医医疗与临床科研信息共享系统——《中医临床术语字典》的构建.中国数字医学,2016,11(1):103-105.
6 贾李蓉.中医药学语言系统语义关系初探.庆祝中国中医研究院成立50周年首届中医药发展国际论坛暨首届中医药防治艾滋病国际研讨会论文集.2005:180-183.
7 于彤,崔蒙,李海燕,等.中医药学语言系统的语义网络框架:一个面向中医药领域的规范化顶层本体.中国数字医学,2014(1):44-47.
8 贾李蓉,于彤,李海燕,等.中医药语义网络的顶层框架研究.中国数字医学,2015(3):54-57.
9 杨阳.中医临床术语集语义关系的示范研究.北京:中国中医科学院硕士学位论文,2007.
10 李莎莎.中医药学语言系统超级叙词表分类原则和构架的探讨.北京:中国中医科学院硕士学位论文,2011
11 杨阳,崔蒙,李园白.语义关系在语言系统中的作用及现状分析.世界科学技术:中医药现代化,2009,11(4):604-607.
12 Chen J,Wang H,Liu L,et al.A Construction Method for the Semantic Relation Corpus of Traditional Chinese Medicine.Emerging Technologies for Education,2017.
13 田久乐,赵蔚.基于同义词词林的词语相似度计算方法.吉林大学学报(信息科学版),2010,28(6):602-608.
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
语文知识(2014年4期)2014-02-28 21:59:52
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
小雪花·初中高分作文(2009年8期)2009-11-16 05:40:24
