
基于Map Reduce海量教学资源存储模型研究
2017-03-25 10:53方禹润蔺兵兵齐浩亮白旭峰
价值工程 2017年8期
方禹润++蔺兵兵++齐浩亮++白旭峰
摘要: 本文在研究了 Map Reduce 算法基本原理及应用的基础上,针对当前海量教学资源存储的需求,应用了一种基于云计算环境下优化的Map Reduce计算模型,通过测试比较改进前后的 Map Reduce 算法模型数据处理性能,实验证明了改进型 Map Reduce 算法模型提高了海量教学资源数据存储模型的存储能力和计算性能。
Abstract: Based on the study of the basic principle and application of Map Reduce algorithm, in view of the current storage requirements of massive teaching resources, an optimized Map Reduce computing model based on cloud computing environment is presented. Through test comparison of data processing performance of the improved Map Reduce algorithm, the experimental results show that the improved Map Reduce algorithm improves the storage capacity and computing performance of the storage model of massive teaching resources.
关键词: 教学资源;存储;Map Reduce
Key words: teaching resources;storage;Map Reduce
中图分类号:TP391.3 文献标识码:A 文章编号:1006-4311(2017)08-0247-02
1 教学资源
教学资源是指高校在教学信息化过程中为教学活动的必要电子材料。一般来说,教学资源是指在教学过程中教学的所有元素,这些主要包括支持教学的信息化数据以及在教学和服务教学的,资金,素材,信息等等。在本文中,教学资源主要是指教学或学习材料,包括媒体资源、试题库、试卷、课件、在线课程等,可以帮助教师和学习者更好的利用教学以及学习知识的信息化数据。
2 Map Reduce的优化
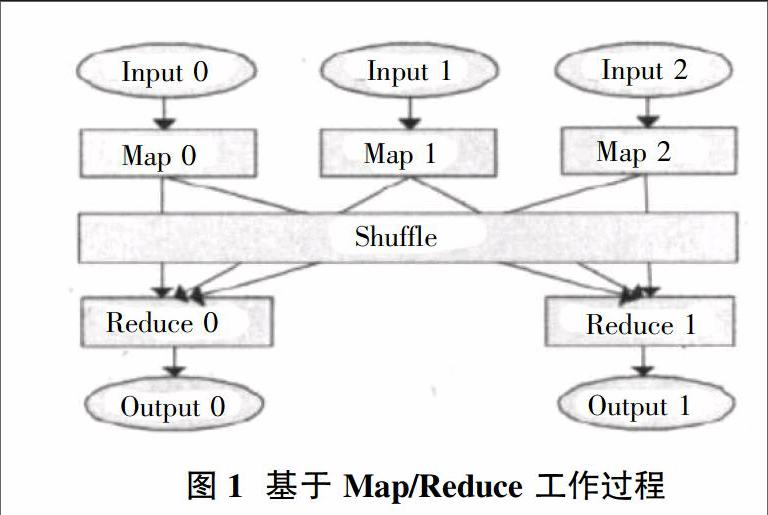
Map Reduce 算法框架首先是由Google 提出来的一个分布式计算体系结构,它能够支持大型分布式海量数据处理和分析。这种架构最初起源于两个函数的map 和 reduce 函数式编程模式,但他们的应用程序在最初的算法架构以及原始模型当中进行使用。一个典型的 Map/Reduce 过程一般有下列几个阶段,如图1所示。
虽然 Map Reduce 算法对海量数据存储以及处理方面的优势很大,但是针对高校的海量数据存储的特点,以及当前海量数据存储的需求,Map Reduce 在处理数据的时候过于繁琐,例如自动并行化数据处理、负载均衡以及设备资源的管理等都得占用计算機资源。
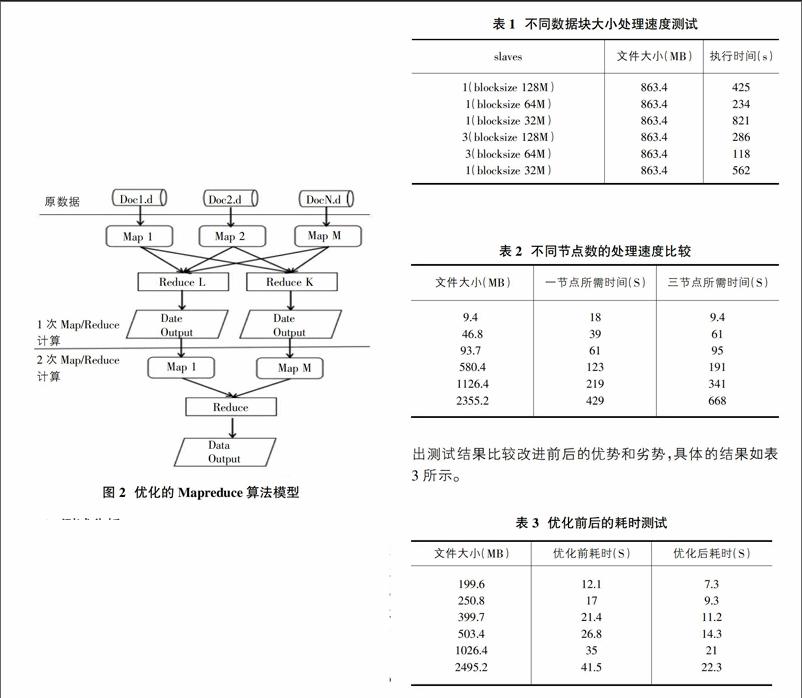
优化的 Map Reduce 的生成方案中可以分为两个部分,分别是第一次的 Map Reduce 算法计算以及第二次的 Map Reduce 分类存储计算。在第一次的 Map Reduce 算法计算当中,首先是把要上传的数据通过 Map 函数的这个阶段数据的索引词频率计算出来,然后输出对应的数据流当中去,然后再通过 Reduce 函数来对相应的数据流进行输入,最后再来把计算好的数据记录生成最终的数据记录集合。这样,在第二次Map Reduce计算的过程中,再通过对每个数据进行设计相应的权重阈值作为权值,最后再来通过这个权值阀值来进行二次分类,从而提升数据的存储能力以及大大提升访问的速度。优化的Map Reduce 算法模型如图2所示。
3 测试分析
3.1 测试环境
所搭建环境具体需求如下:
①硬件环境:
Master(主节点)1 台、Slave(子节点)3 台。
②软件环境:
操作系统:Cent OS6.5,集群的主要软件:Hadoop1.2.1、DK1.6.0_22、Vmwareworkstation 和 Eclipse3.2。
3.2 hadoop平台搭建
采用四台服务器来搭建 hadoop 集群并部署存储模型进行功能、性能等测试,主节点服务器(master)的 IP 地址为:192.168.1.2(下面简称 master), 子节点 1:192.168.1.3(下面简称 slave1), 子节点 2:192.168.1.4 (下面简称 slave2),子节点 3:192.168.1.188 (下面简称 slave3),架构规化如下:
master 作为 Name Node,Secondary Name Node,Job Tracker;
slave1、slave2 以及 slave3 用来作为 Data Node,Task Tracker。
3.3 实验结果
由于实验条件限制,在搭建 Hadoop 分布式集群的时候,选用一台 PC 机用来作为 Name Node 主服务器,剩余 3 台 PC 机用来作为子节点服务器,通过对 Linux 集群环境进行相关验证。本次测试所用数据为 50G 的教学资源。实验的内容是:
3.3.1 不同数据块大小处理速度测试
把所要测试文件按分割成不同大小的 Block 进行存储,然后测试对于不同节点处理速度有什么影响,结果如表1所示。
3.3.2 应用优化Map Reduce算法的性能测试
在做这个测试之前,首先得对原始测试数据文件设置好相应的文件权值,同时还要设置集群中的 Name Node 主节点数为 1 个,Data Node 数据节点为 3个,Job 子任务数为 10 个,然后运行并通过测试对应用 Map Reduce 算法改进前后的执行速度进行比较并记录,然后通过分析得出测试结果比较改进前后的优势和劣势,具体的结果如表3所示。
从表3的测试结果可以说明,在 Hadoop 集群当中,应用基于改进型的Map Reduce 算法模型可以明显提升数据访问的速度以及处理性能。通过这个测试可以说明,基于改进型的 Map Reduce 算法在基于云计算环境下的高校海量数据存储模型中的应用是成功的,使用这种改进型的算法可以提升存储模型的访问速度以及数据处理性能。
4 结束语
本文主要针对分布式存储模型和关键技术进行了研究,利用Hadoop的HDFS有效解决了当前高校对于海量教学资源存储的难题,通过对Map Reduce算法的优化有效地提高海量数据处理速度,以及对规则计算实验结果的分析证明了开始的设想,实现期待的目标。
参考文献:
[1]钟小彬.中国视频公开课发展现状、问题及对策[J].电子测试,2013(3):224-225.
[2]袁正午,等.云计算应用现状与趋势[J].数字通信,2010(3).
[3]谢桂兰,罗省贤.基于Hadoop MapReduce模型的应用研究[J].微型机与应用,2010(8):4-7.
猜你喜欢
科学与财富(2016年26期)2016-12-01
中国教育技术装备(2016年15期)2016-03-01
中国教育信息化(2015年22期)2015-08-22
中国教育技术装备(2015年6期)2015-03-01
当代教育实践与教学研究(2015年2期)2015-02-27
河南科技(2014年15期)2014-02-27
